오늘 리뷰할 논문은 Facebook의 DETR 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- DETR 논문(End-to-End Object Detection with Transformers) 리뷰
- [논문리뷰] DETR: End-to-End Object Detection with Transformers
- [논문 리뷰] End-to-end object detection with transformers
Summary
object detection을 direct set prediction problem으로 보는 새로운 방법을 소개한다. 논문의 방법은 detection pipeline을 간소화하여(streamline) task에 대한 prior knowledge를 명시적으로 encode하는 non-maximum suppression procedure나 anchor generation 같은 많은 hand-designed components의 필요를 효과적으로 제거한다. DETR (DEtection TRansformer)은 bipartite matching을 통해 unique predictions을 강요하는 set-based global loss이며 transformer encoder-decoder architecture이다. fixed small set of learned object queries이 주어졌을 때, DETR은 병렬로 final set of predictions을 직접 output하기 위해 objects와 global image context의 관계를 사고한다(reason). 모델은 개념적으로 간단하고 다른 많은 modern detectors와 달리 specialized library을 요구하지 않는다. COCO object detection dataset에 DETR은 Faster R-CNN과 동등한 accuracy와 run-time performance을 입증한다. 또 DETR은 panoptic segmentation을 생성하기 위해 unified manner로 쉽게 일반화될 수 있다.
object detection의 목표는 각 관심 사물에 대해 bounding boxes와 category labels의 집합을 예측하는 것이다. 최신 detectors는 이 set prediction task를 간접적으로 다루는데, proposals, anchors, window centers 등에 surrogate regression과 classification problems을 정의하는 식이다. 이들의 성능은 postprocessing steps, anchor sets의 디자인, target boxes를 anchors에 할당하는 heuristics 등에 크게 영향을 받는다. 이 pipelines를 간단화하기 위해 이런 대리의(surrogate) tasks를 우회하는 direct set prediction approach을 제안한다.
object detection을 direct set prediction problem으로 보아 training pipeline을 간소화한다. sequence prediction으로 유명한 transformers에 기반한 encoder-decoder architecture을 적용한다. sequence 내 elements 간 모든 pairwise interactions을 명시적으로 model하는 self-attention mechanism은 모델이 duplicate predictions 제거 같은 set prediction의 특정 제약에 적합하게 해준다.
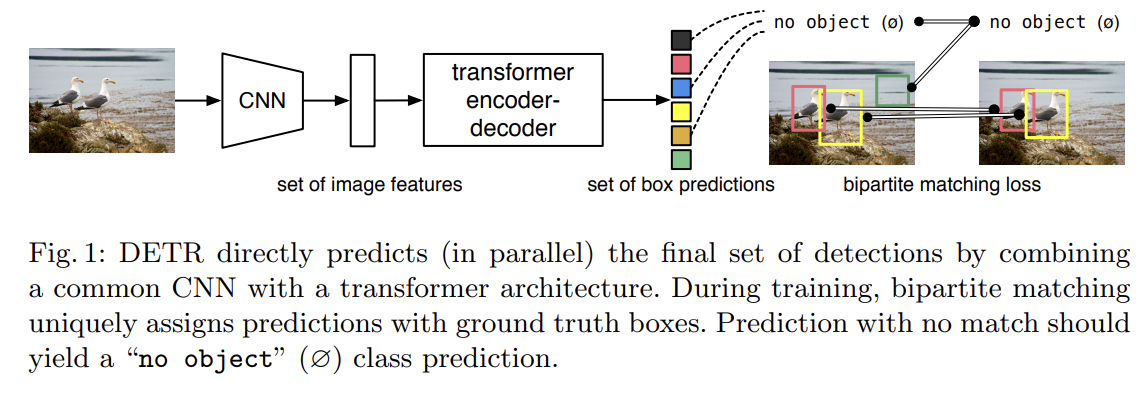
Fig 1에서 볼 수 있듯 DETR은 모든 objects를 한번에 예측하며 predicted objects와 ground-truth objects 사이 bipartite matching을 수행하는 set loss function을 가지고 end-to-end로 학습된다. DETR은 spatial anchors나 non-maximal suppression처럼 prior knowledge를 encode하는 여러 hand-designed components을 없앰으로써 detection pipeline을 간단화한다. 다른 대부분 detection methods와 달리 DETR은 customized layers을 요구하지 않으므로 일반적인 CNN과 tranformer를 가진 아무 framework에서나 쉽게 재생산할 수 있다.
direct set prediction에 대한 기존 연구와 비교했을 때 DETR의 주요 특징은 bipartite matching loss와 (non-autoregressive) parallel decoding을 가진 transformers의 결합니다. 반면 기존 연구들은 RNN을 가지고 autoregressive decoding에 집중했다. 논문의 matching loss function은 ground truth object에 prediction을 유일하게(uniquely) 할당하며 predicted objects의 순서(permutation)에 불변해서(invariant) 그들을 병렬으로 출력할(emit) 수 있다.
direct set predictions에 2가지 요소가 필수적이다. (1) predicted boxes와 ground-truth boxes 사이 unique matching을 강요하는 set prediction loss와 (2) (single pass로) set of objects를 예측하고 그들의 관계를 model하는 architecture다.
- Object detection set prediction loss
DETR은 decoder를 통한 single pass로 (고정된 크기의) N predictions 집합을 추론한다. N은 image 내 objects 수보다 상당히 크게 설정된다. training의 한 가지 주요 난점은 ground truth에 관해 predicted objects (class, position, size)을 score하는 것이다. 논문의 loss는 predicted objects와 ground truth objects 사이 optimal bipartite matching을 생성하고 object-specific (bounding box) losses을 최적화한다. y를 ground truth set of objects, 를 set of N predictions으로 표기한다. N이 image 내 objects 수보다 많다는 크다는 가정 하에 y도 ∅ (no object)로 패딩된 size N의 집합으로 생각한다. 두 집합 간 bipartite matching을 찾기 위해 lowest cost를 가진 N elements의 순열 을 탐색한다.
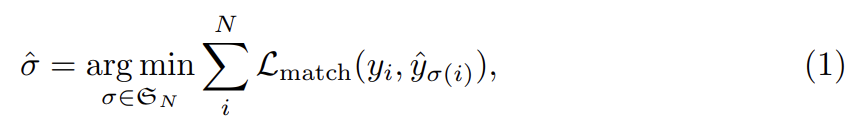
는 ground truth 와 index σ(i)를 가진 prediction 사이 pair-wise matching cost이다. 이 optimal assignment은 (선행 연구를 따라) Hungarian algorithm로 효과적으로 계산된다.
matching cost는 class prediction과 predicted & ground truth boxes의 similarity를 둘 다 고려한다. ground truth set의 각 element i는 로 볼 수 있고, 는 (∅일 수도 있는) target class label이고 는 ground truth box center coordinates와 image size에 상대적인 height과 width을 정의하는 vector다. index σ(i)인 prediction에 대해 class 의 probability를 로 정의하고 predicted box를 로 정의한다. 를 로 정의한다.
matching을 찾는 이 절차는 최신 detectors에서 proposal이나 anchors을 ground truth objects에 match할 때 사용하는 heuristic assignment rules와 같은 역할을 한다. 주요 차이점은 우리는 direct set prediction을 위해 duplicates 없이 one-to-one matching을 찾아야 한다는 것이다.
두 번째 단계는 이전 단계에서 match된 모든 pairs에 loss function인 Hungarian loss을 계산하는 것이다. loss는 일반적인 object detectors의 loss와 비슷하게 정의한다. 즉, class prediction에 대한 negative log-likelihood와 나중에 정의된 box loss의 linear combination이다.
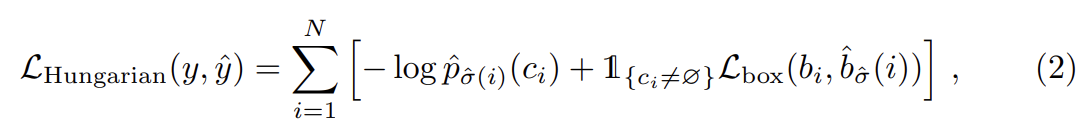
은 첫 단계에서 계산한 optimal assignment이다. 실제로는 class imbalance를 고려하기 위해 일 때 log-probability 항을 factor 10만큼 down-weight한다. 이는 Faster R-CNN training procedure가 subsampling을 통해 positive/negative proposals을 balance하는 것과 비슷하다. object와 ∅ 사이 matching cost가 prediction에 의존하지 않는다는 것을, 즉 이 경우 cost가 constant라는 것에 주의하라. matching cost에서 논문은 log-probabilities 대신 probabilities 을 사용한다. 이는 class prediction 항이 로 약분 가능하게(commensurable) 하며 경험적으로 더 좋은 성능을 관찰했다.
- Bounding box loss
matching cost와 Hungarian loss의 두 번째 부분은 bounding boxes를 score하는 이다. box prediction을 initial guesses와 관련해 예측하는 많은 detectors와 달리 논문은 box predictions을 직접 한다. 이 방식이 구현을 간단화하지만 loss의 relative scaling이라는 문제를 낳는다. 가장 흔히 사용되는 L1 loss는 작고 큰 boxes에 (상대적 errors가 비슷하더라도) 서로 다른 scales을 가질 것이다. 이를 완화하기 위해 L1 loss와 scale-invariant한 generalized IoU loss 의 선형 결합을 사용할 것이다. 전체적으로 box loss 는
로 정의된다. 는 hyperparameters다. 이 두 loss는 batch 내 objects의 수로 normalize된다.
- DETR architecture
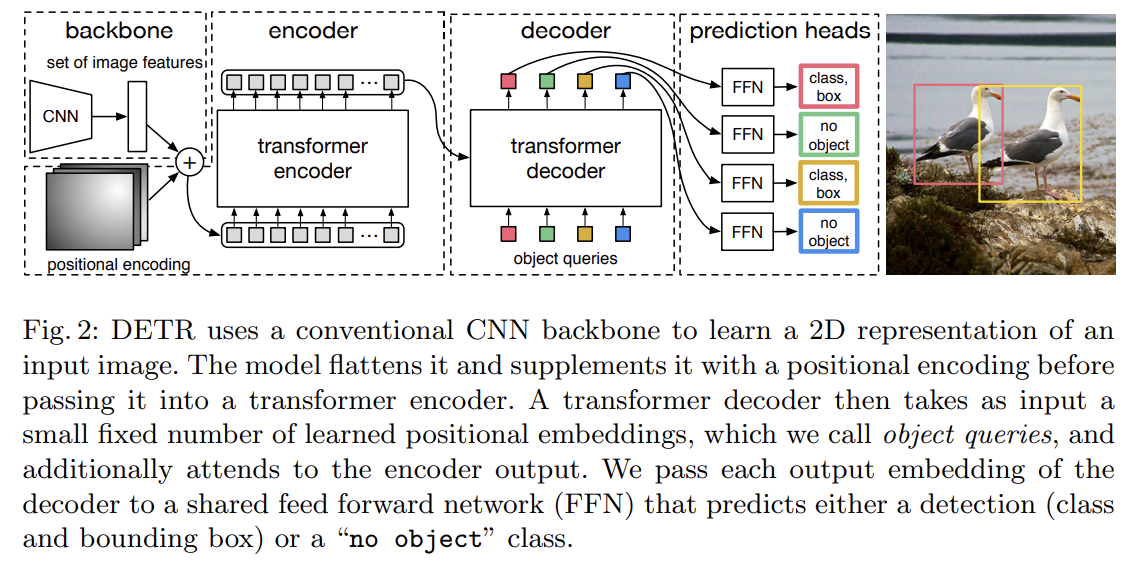
DETR architecture은 3가지 주요 요소로 이루어진다. compact feature representation을 추출하기 위한 CNN backbone, encoder-decoder transformer, final detection prediction을 만들기 위한 simple feed forward network (FFN)이다.
- Backbone
(3 color channels를 가진) initial image 에서 시작해 conventional CNN backbone은 lower-resolution activation map 을 생성한다. 논문에서 일반적으로 사용하는 값은 C = 2048과 다.
- Transformer encoder
먼저 1x1 convolution이 high-level activation map f의 channel dimension을 C에서 더 작은 차원 d로 줄여 새로운 feature map 를 생성한다. encoder는 input으로 sequence를 기대하므로 의 spatial dimensions을 1차원으로 붕괴시켜 d×HW feature map으로 만든다. 각 encoder layer은 standard architecture을 가지며 multi-head self-attention module과 feed forward network (FFN)로 구성된다. transformer architecture가 permutation-invariant하기 때문에 이를 각 attention layer의 input에 더하는 fixed positional encodings로 보충한다.
- Transformer decoder
decoder는 transformer의 standard architecture을 따르며 multi-headed self-attention과 encoder-decoder attention mechanisms을 사용해 size d의 N embeddings을 변환한다(transform). original transformer와의 차이는 (Attention is all you need에선 output sequence를 한 번에 한 element씩 예측하는 autoregressive model을 사용하지만) 각 decoder layer에서 N objects을 평행하게 decode한다는 것이다. decoder도 permutation-invariant하기 때문에 다른 결과를 만들기 위해 N input embeddings도 달라야 한다. 이 input embeddings은 object queries라고 이름붙인 learnt positional encodings이며, encoder와 비슷하게 이들을 각 attention layer의 input에 더한다. N object queries는 decoder에 의해 output embedding으로 변환된다. 그 다음 그들은 독립적으로 feed forward network를 통해 box coordinates와 class labels로 decode되어 N final predictions을 낳는다. 이 embeddings에 self-attention과 encoder-decoder attention을 사용해 모델은 (전체 image를 context로 사용하면서) 모든 objects 간 pair-wise relations를 사용해 모든 objects를 함께 사고할 수 있다.
- Prediction feed-forward networks (FFNs)
final prediction은 ReLU activation function과 hidden dimension d와 linear projection layer를 가진 3-layer perceptron으로 계산된다. FFN은 input image에 상대적으로 box의 normalized center coordinates, height, width을 예측하고 linear layer은 softmax function을 사용해 class label을 예측한다. fixed-size set of N bounding boxes을 예측하기 때문에 slot 내에 object가 감지되지 않으면 additional special class label ∅가 사용된다. 이 class는 일반적인 object detection 방식에서 “background” class와 비슷한 역할을 한다.
- Auxiliary decoding losses
training 중 decoder에 auxiliary losses [1]를 사용하는 것이 (특히 모델이 각 class의 objects의 정확한 수를 output하는 '데) 도움이 된다는 것을 발견했다. 각 decoder layer 이후에 prediction FFNs와 Hungarian loss을 추가한다. 모든 prediction FFNs가 그들의 parameters를 공유한다. 서로 다른 decoder layers에서 prediction FFNs로의 input을 normalize하기 위해 추가적인 shared layer-norm을 사용한다.
실험은 COCO 2017 detection과 panoptic segmentation datasets에 평가한다. (이하 implementation detail 설명 생략)
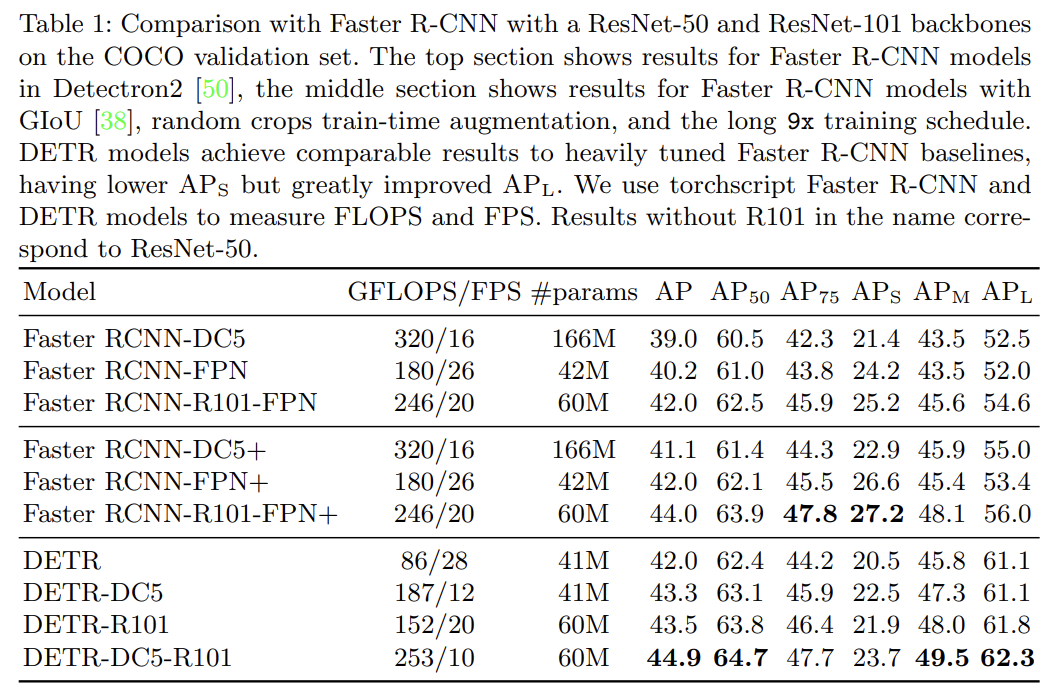
Faster R-CNN과 비교했을 때 경쟁적인 성능을 보인다.
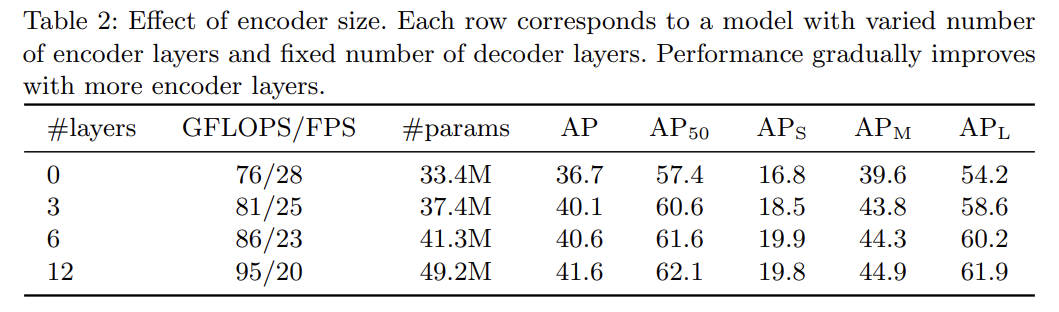

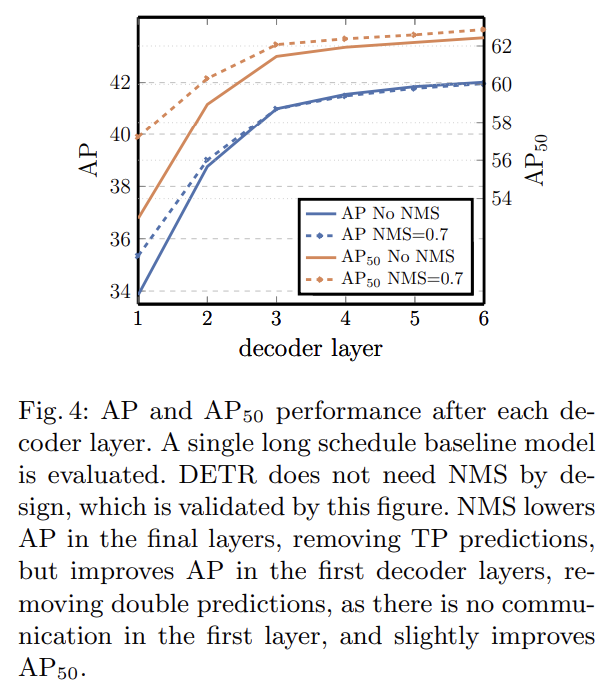

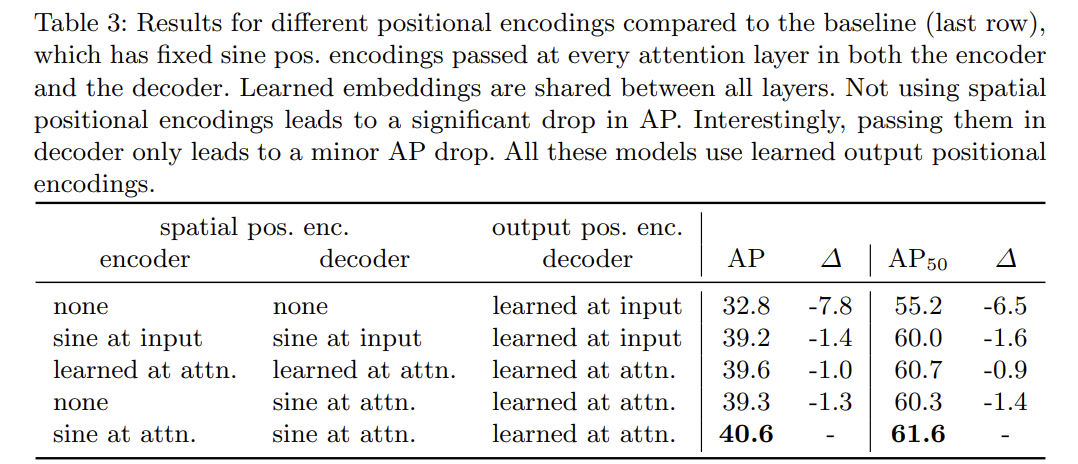
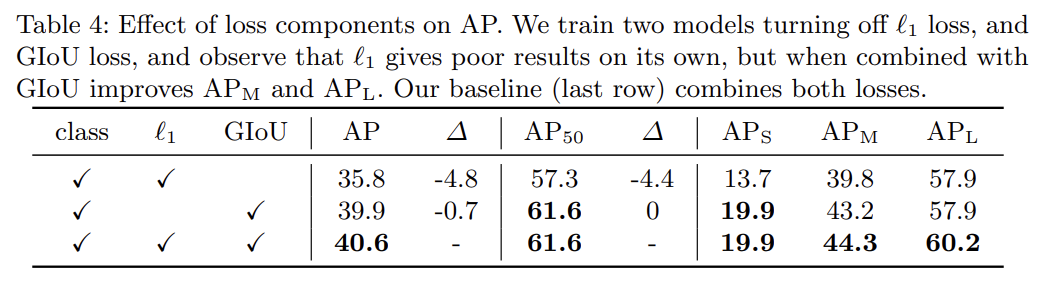
여러 ablation study를 한다. 설명은 생략한다.

Decoder output slot analysis
Fig 7에서 COCO 2017 val set 내 모든 image에 대한 다양한 slots이 예측한 boxes를 시각화한다. DETR은 각 query slot에 대해 서로 다른 specialization을 학습한다. 각 slot이 서로 다른 areas와 box sizes에 집중하는 여러 modes를 가짐을 관찰할 수 있다. 특히 모든 slot이 image-wide boxes를(중앙의 빨간 선) 예측하는 mode를 가지고 있다. 이는 COCO objects의 distribution에 관련된 것으로 추측된다.

Generalization to unseen numbers of instances
COCO 내 몇 classes는 한 image 내에서 동일 class의 많은 instances가 표현되지 않는다. 예를 들어 training set에는 기린 13마리 이상을 가진 사진이 없다. Fig 5처럼 DETR의 일반화 능력을 확인하기 위해 synthetic image을 만들었다. DETR은 기린 24마리를 모두 발견할 수 있었다. 이 실험은 각 object query에 강한 class-specialization이 없다는 사실을 보여준다.

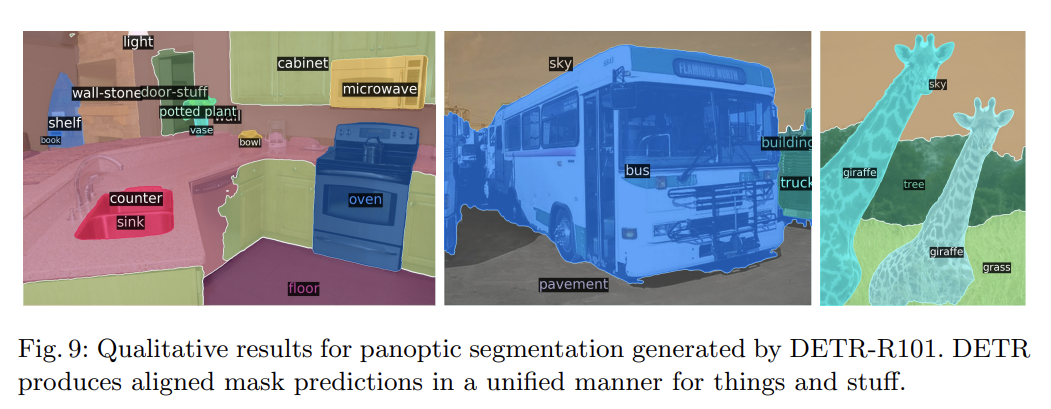
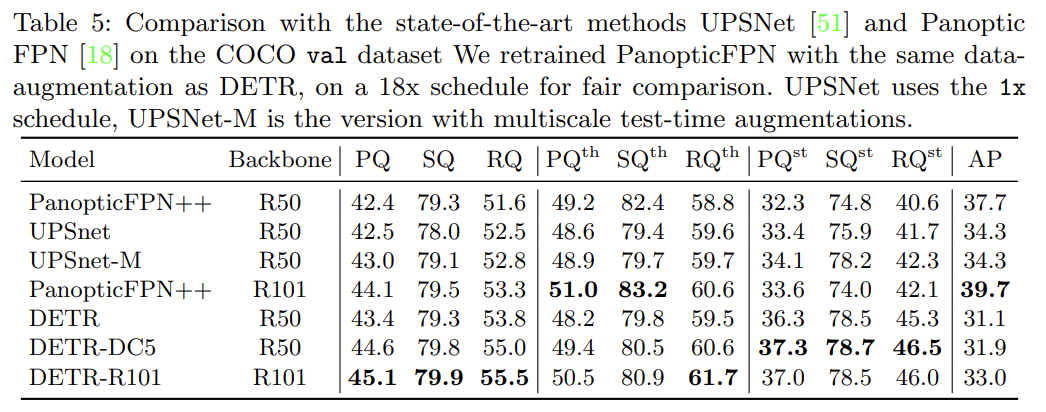
panoptic segmentation 실험도 한다. Faster R-CNN을 Mask R-CNN으로 확장하는 것처럼 DETR도 decoder output 꼭대기에 mask head를 붙여 자연스럽게 확장할 수 있다. DETR이 COCO-val 2017의 결과와 강력한 PanopticFPN baseline을 능가했다. 이는 DETR가 특히 stuff class에 강력하다는 사실을 보여주며, 논문은 이것이 encoder attention에 의한 global reasoning 덕분이라고 추측한다. things class에서도 경쟁적인 성능을 보인다.
Strengths
- 이때까지 내가 본 detector들과 달리 transformer을 사용했다.
- 여러 사물에 대한 box 결과들을 순차적으로가 아니라 한 번에 병렬로 받고, 그걸 (여러 순열 중에서) Hungarian 알고리즘으로 ground truth와 matching하고 IoU와 L1 loss로 box를 회귀시키는 아이디어가 신선했다.
Weaknesses
- hand-designed components를 제거한다고 했는데 Fig 7을 보니 object queries가 anchor box 등을 대체한 것일 뿐으로 생각된다. 감지 가능한 사물 수의 상한선을 인위적으로 정한 것이라 마음에 들지 않는다.
