오늘 리뷰할 논문은 최초로 GANs에 convolutional layer을 도입한 Deep Convolutional GANs, DCGAN 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문리뷰] UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS(DCGAN), ICLR, 2016
- DCGAN 논문 리뷰 - Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (ICLR 2016)
Summary
논문은 DCGANs를 제안해 CNN의 unsupervised learning이 효과적임을 보이고자 한다.
최근(당시) 유행하는 방식은 large unlabeled datasets에서 재사용 가능한 intermediate feature representations를 배워 이후 classification 같은 다른 supervised learning에 적용하는 방식이다. 논문은 좋은 image representations를 얻기 위해 처음엔 GANs를 학습하고 generator와 discriminator networks의 일부를 supervised task의 feature extractors로 재사용한다.
논문의 성과는 다음과 같다.
- (그냥 GANs과 달리) 대부분의 setting에서 학습이 안정적인 DCGANs을 제안한다.
- image classification tasks에서 discriminator을 사용해 다른 unsupervised algorithms에 비해 경쟁적인 성능을 보여준다.
- GANs에 의해 학습된 filters를 시각화해 특정 filter가 특정 object를 그리도록 학습했음을 경험적으로 보여준다.
- generator가 많은 semantic qualities of generated samples의 쉬운 조작을 가능하게 하는 흥미로운 vector arithmetic properties를 지녔음을 보여준다.
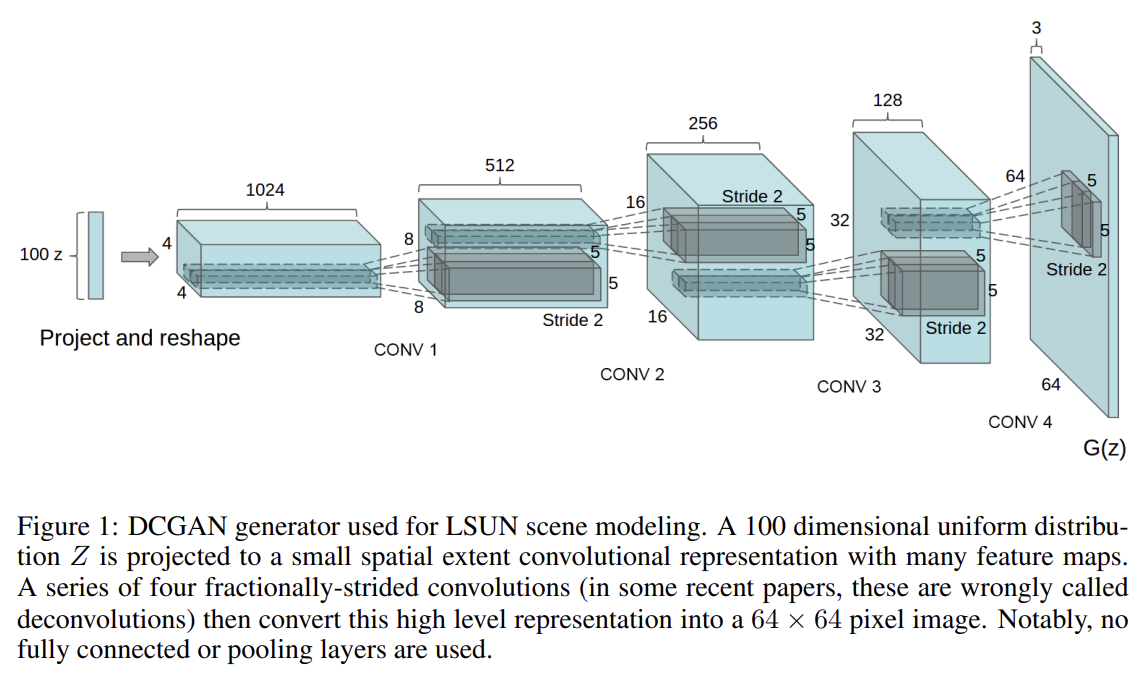
GANs에 CNN을 적용하여 low resolution generated images를 upscale하려는 기존의 방법들은 좋은 성과를 보이지 못했는데, 이 논문은 세 가지 변화를 CNN에 적용한다.
첫째는 all convolutional net (Springenberg et al., 2014)으로, 이는 maxpooling 같은 deterministic spatial pooling functions를 strided convolutions로 대체해 network가 고유한 spatial downsampling를 학습하게 하는 것이다. 논문은 이를 generator와 discriminator에 적용해 각자의 spatial upsampling를 학습하게 했다.
둘째는 convolutional features 꼭대기의 fully connected layers를 제거하는 것이다.
셋째는 각 unit으로 들어가는 input을 normalize하여 학습을 안정화하는 Batch Normalization (Ioffe & Szegedy, 2015)이다. 이는 poor initialization으로 인한 학습 문제를 막고 깊은 모델에서 gradient flow를 돕는다. 이는 수많은 GANs가 모든 samples을 하나의 point로 collapse하는 문제를 예방하는 중요한 효과가 있었다. 하지만 모든 layer에 batchnorm을 적용하면 sample oscillation과 model instability를 유발하였다. 그래서 generator output layer과 discriminator input layer에는 적용하지 않았다.
대충 요약은 아래와 같다.

학습에는 3가지 데이터셋, Large-scale Scene Understanding (LSUN), Imagenet-1k, newly assembled Faces dataset을 사용했다.
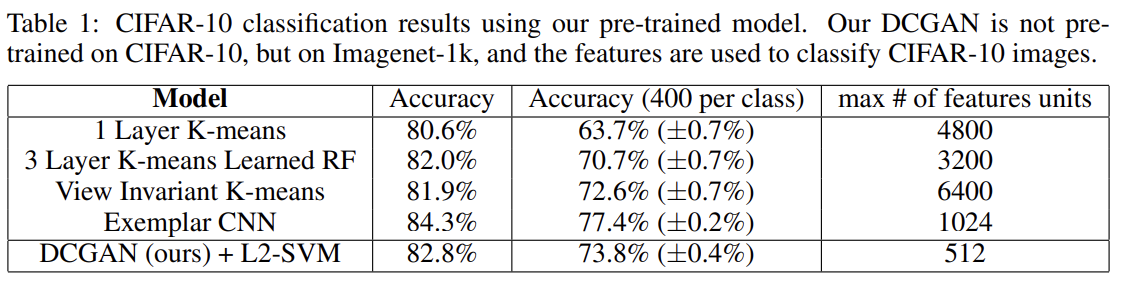
unsupervised representation learning algorithms의 quality를 평가하는 평가하는 일반적인 방법은 supervised datasets에 feature extractor로써 적용하여 이 feature에 fit된 linear models의 성능을 평가하는 것이다.
supervised task에의 성능 평가를 위해 DCGANs을 Imagenet-1k에 학습시키고 discriminator의 모든 layer에서 convolutional features를 사용해서 각 layer의 representation이 4 × 4 spatial grid를 만들도록 maxpooling했다. 이 feature들을 flatten, concatenate해서 28672 dimensional vector을 만들고 그것으로 regularized linear L2-SVM classifier를 학습시킨다. 이에 따른 정확도는 82.8%으로, baseline인 K-means based techniques(80.6%, 82.0%)보다 높다.
INVESTIGATING AND VISUALIZING THE INTERNALS OF THE NETWORKS

논문은 generator와 discriminator을 다양한 방법으로 조사한다. 첫번째 실험은 latent space의 landscape을 이해하는 것이었다. 학습된 manifold 위를 걸으면 일반적으로 (sharp tranisition이 있는 곳에서) memorization의 징후와 space가 hierarchically collapse된 형태를 알 수 있다. latent space walking이 image generation에 semantic changes를 야기한다면 model이 (training input을 memorize한 게 아니라) 적절한 representations을 학습했음을 알 수 있다.

논문은 unsupervised DCGAN도 feature의 hierarchy를 학습할 수 있음을 보인다. guided backpropagation를 사용한 결과 Fig 5는 침실의 전형적인 부분이 discriminator에 의해 학습된 features를 activate함을 알 수 있다.

논문은 generator이 배우는 representation도 이해하기 위해 실험을 한다. 논문에 따르면 generator는 major scene components에 대한 specific object representations를 학습한다. 이를 보이고자 논문은 generator의 이미지에서 창문을 없애는 실험을 수행한다. second highest convolution layer features에서 logistic regression 를 사용해 window에 feature activation가 있었는지 예측해 (training sample에서 window를 포착하는) bounding boxes 내의 activation을 positive으로 두었다. 이 간단한 모델을 사용해서 weight이 0보다 큰 모든 feature map을 모든 spatial location에서 drop하여 (feature map removal을 한 경우와 하지 않은 경우에서) sample을 생성했다. 그 결과 Fig 6과 같이 network가 침실에서 창문을 그리는 것을 잊고 대신 다른 object로 대체했다.
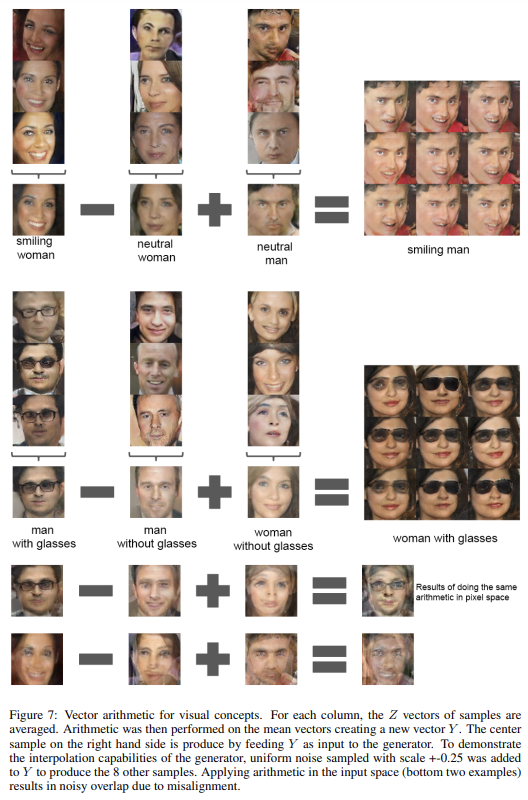

NLP의 word representation에서 vector(”King”) - vector(”Man”) + vector(”Woman”)가 vector("Queen")을 만든 예시처럼 논문도 generator의 Z representation에서 비슷한 구조가 나타나는지 실험한다. concept 당 single sample에 실험하면 unstable하지만 세 개의 examplars의 Z vector을 평균내어 arithmetic을 하면 semantically하게 arithmetic을 따르는 consistent, stable generation을 보였다. Fig 7은 object manipulation를, Fig 8은 Z space에서 face pose가 linearly model됨을 보여준다.
Strengths
- architecture에 독창적인 부분은 없는 거 같은데 실험 설계와 결과는 굉장히 흥미롭다. 특히 representation에 vector arithmetic를 수행해서 성공한 게 신기했다.
- GANs를 사용하는 방식이 다른 unsupervised learning 알고리즘에 비해 경쟁적인 성능을 낼 수 있음을 보였다.
- visualization, window 제거 등을 통해 GANs의 내부 작동에 이해하려는 시도가 좋았다.
Weaknesses
- training이 길어질수록 subset of filters가 single oscillating mode로 붕괴하는 model instability가 존재했다.
