손실 함수란?
모델이 예측한 “예측값”과 “실제값” 차이를 측정하는 함수
즉, “틀림의 정도”를 알려준다.
이 차이가 얼만큼인지 봄으로써 모델의 성능을 평가할 수 있고, 모델의 개선점도 계산할 수 있다.
당연히 예측값과 실제값의 차이가 없을 수록 좋은 모델이라는 뜻이므로 이 손실함수의 값을 최소화하는 것이 모델 학습의 목표다.
목차
손실 함수 종류
회귀에서의 손실 함수
1. MSE(Mean Squared Error) : 평균 제곱 오차
예측값과 실제값의 차이를 “제곱”하여 평균을 낸 것.
→ 큰 오차에 더 큰 벌칙을 부여한다는 뜻이다.
예를 들어,
오차가 10, 10, 10 이렇게 나는 것과 1, 20, 1 이렇게 나는 것이 있을 때 평균적으로 봤을 땐 전자가 더 오차가 적어 보이지만,
MSE로 계산해봤을 땐 10^2 + 10^2 + 10^2의 평균 100보다 1^2 + 20^2 + 1^2의 평균 134가 더 큰 값이 나온다.
2. MAE(Mean Absolute Error) : 평균 절대 오차
예측값과 실제값의 차이의 “절댓값”을 평균 내어서 모든 오차를 동등하게 취급
3. RMSE(Root Mean Squared Error) : MSE에 제곱근을 씌운 값
각 오차를 제곱한 MSE의 루트MSE로써, MSE의 단위를 실제값과 같게 맞춘 값.
분류에서의 손실 함수
1. 교차엔트로피(Cross-Entropy)
실제 정답 분포와 모델의 예측 분포가 얼마나 다른지를 측정. 달라질수록 손실값이 크다
- 로지스틱 회귀에서 쓰이는 함수다.
- 엔트로피(불확실성)가 높다 : 다양한 사건들이 거의 동일한 확률로 발생할 수 있어서 결과를 예측하기 매우 어렵다는 것.
- 모델에게 정답이 하나여야 하니 원-핫 인코딩 방식이라고도 한다.
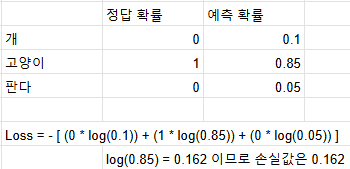
- 모델에게 고양이 사진을 주고 개, 고양이, 판다 중에서 무엇인지 봐달라고 했을 때 손실값 계산은 다음과 같다
2. Hinge Loss
- SVM(Support Vector Machine)알고리즘에서 주로 사용되는 손실 함수
- 데이터들을 분류하는 경계선을 중심으로 마진을 최대화하는 것이 목표 (마진을 최대화할수록 분류를 잘한 것이기 때문)
→ 그래서 마진 내에 있는 데이터를 집중해서 봄.
손실함수 중요도
모델을 반복적으로 학습시키는 이유는 모델의 정확도와 성능을 올리기 위해서다.
그리므로 올바르게 학습시켜야 하는데, 그 뱡향을 잡아주기 위해 필요한 것이 손실함수 값이다.
손실함수의 종류가 이렇게 다양하니 반드시 손실함수가 무엇인지 알아야 하겠고, 상황에 따라 적합한 손실함수를 사용해야 한다.

개발에 애정을 쏟는 연구자입니다