코드스테이츠 46일차
자료구조 세번째 시간으로 그래프와 트리 구조에 대해 배우게 되었다.
그래도 어제 배웠던 해시 테이블보다는 조금 수월한듯 하다.
새로 배운 것들
Graph (그래프)
그래프는 vertex(버텍스 또는 노드)와 edge(엣지)로 구성된 자료 구조를 의미한다. 여기서 버텍스는 엣지로 연결되어 있다.
그래프의 특징
- 버텍스는 방향성이 있기도 하고 없기도 해 각각을
'무방향성 그래프', '방향성 그래프'라고 나뉘어 부른다. - 그래프에서는 모든 노드들이 관계를 가지고 있을 필요가 없어 비교적 자유로운 구조이다.
- 그래프는 비선형(non-linear)적이며, 네트워크 모델이라고도 불린다.
- 실생활에서의 그래프는 네비게이션의
최단거리 경로 알고리즘을 예로들 수 있다.
그래프의 구성
undirected graph(무방향성 그래프)
엣지를 통해 양방향으로 노드에 접근이 가능한 그래프로
구현 시 두개의 노드를 연결을 해줘야된다. (A ↔ B)
directed graph(방향성 그래프)
엣지에 방향성이 있는 그래프로 구현 시 한쪽 노드에서만 연결을 해주면 된다. (A → B)
weighted graph(가중치 그래프)
엣지의 비용이나 가중치가 할당된 그래프, 어떠한 경로를 탐색할 때 들여지는 시간이나 비용등을 나타낼 수 있다
self loop(재귀적 그래프)
엣지의 방향이 노드로 돌아오는 그래프로 구현 시 진행 방향이 자기 자신에게 있다.
cycle(써클)
시작과 끝이 서로 순환되는 그래프로 구현 시 마지막 노드의 방향이 처음의 노드를 가리키게 연결해주면 된다. (A → B → C → A)
degree(디그리)
노드간 방향이 없는 경우, 노드 하나에 연결된 엣지 수의 합
in-degree(인디그리)
노드간 방향이 있는 경우, 외부에서 자신의 노드쪽으로 향하는 엣지 수의 합
out-degree(아웃디그리)
노드간 방향이 있는 경우, 자신 노드로부터 외부로 향하는 엣지 수의 합
그래프의 구현방법
Adjacency matrix(인접 행렬)
배열을 이용해 2차원 배열에 모든 노드의 연결 관계를 담는 방식이다. 0과 1을 이용한 정수 행렬로 표현할 수 있다.
if(edge[a][b] === 1) // 연결됨
if(edge[a][b] !== 1) // 연결되지 않음간선의 수와 무관하게 O(n^2)의 메모리가 필요하다.
그래서 노드를 있는 엣지의 여부를 O(1)안에 찾을 수 있는 장점이 있지만, 순회를 해야될 때는 전부 돌아야하기 때문에 그래프에 엣지가 많은 밀집 그래프일 때 좋다.
Adjacency list(인접 리스트)
그래프를 표현할 때 일반적으로 표현하는 방법
노드 안에 인접 노드 리스트를 저장하는 방법으로
연결 리스트와 유사한 구조로 접근한다.
노드의 번호만 알게 된다면 이 번호를 배열의 인덱스로하여금
각 노드의 리스트에 쉽게 접근할 수 있다.
때문에 인접 노드를 쉽게 찾을 수 있고, 그래프에 존재하는 모든 엣지 수를 O(n+e)안에 확인할 수 있다.
인접 행렬보다 메모리를 많이 차지하기때문에 그래프에 적은양의 데이터를 가지는 그래프에 용이하다.
- 어떤 그래프를 어떤때에 사용하게 될까?
인접 행렬은 노드와 노드간 엣지를 자주 탐색할 때 주로 사용하며
인접 리스트는 하나의 노드를 기준으로 자주 탐색할 때 주로 사용한다.
무방향 그래프의 속성
node
그래프의 정점
edge
노드와 노드를 연결 시켜주는 값 노드의 속성으로 넣을 수 있다
무방향 그래프의 메소드
addNode()
그래프에 노드를 추가한다.
contains()
그래프에 해당 노드가 있는지 확인한다.
removeNode()
그래프에 해당 노드를 삭제한다.
hasEdge()
노드와 노드 사이에 엣지가 있는지 확인한다.
addEdge()
노드와 노드 사이에 엣지를 추가한다.
removeEdge()
노드와 노드 사이에 엣지를 삭제한다.
Tree (트리)
노드부터 시작되어 자식 노드들이 파생되는 자료 구조
일방향 그래프의 한 구조로도 볼 수 있다.
생긴것은 나무의 뿌리 부분으로 볼 수 있고 최상단의 노드를 root(뿌리)라고 한다.
트리와 그래프의 차이점
그래프는 2개 이상의 경로를 가져 무방향에서 양방향으로도 표현이 가능하고 자기 자신을 반복 순회할 수 있기도 하다.
또한, 부모 자식 개념이 없고 네트워크 모델이다.
트리는 그의 반대로 일방향 그래프이며 부모 자식 관계가 상하 관계로 되어있는 계층 모델이다.
트리의 구성
- node
트리의 구성요소를 노드라고 한다.
- root
시작하는 노드, 1개 뿐이고 root 외에는 시작이 될 수 없다.
- leaf
최하단에 있는 마지막 노드, 자식 노드가 없다.
- edge/branch
노드와 노드의 연결선
- parent & child
부모와 자식 노드, 자식 노드의 부모 노드는 1개 뿐이다.
- children & sibling
부모 노드 아래로 파생된 모든 노드를 children에 담고 있다.
같은 부모 노드를 가지고 있는 자식 노드들을 서로 sibling으로 본다.
- height
root로 부터 얼마나 내려와 있는지 확인한다.(root → node)
- depth
요소에서부터 root까지의 거리를 젠다.(node → root)
트리 안에서의 특정 노드의 깊이
트리의 속성
value
트리에 입력된 값(루트)
children
자식 트리의 값
트리의 메소드
insert()
자식 트리를 추가하는 메소드
remove()
자식 트리를 삭제하는 메소드
contains()
트리가 해당 노드값을 가지고 있는지 확인하는 메소드
traverse()
모든 트리의 값을 콜백 함수에 의해 변경하는 메소드
map()
콜백함수에 의해 변경된 새로운 트리를 반환하는 메소드
Binary Search Tree(이진 탐색 트리)
두가지 선택지밖에 없는 이진법을 이용해 검색하는 트리 구조이다. 이진 트리와 햇갈릴 수 있는데 둘은 서로 다른 구조이며
이진 탐색 트리는 이진 트리 자료구조 중 하나이다.
(트리 > 이진 트리 > 이진 탐색 트리)
- Binary Tree
각 노드가 최대 두개의 자식을 갖는 트리
- Binary Search Tree
모든 노드가 특정 순서를 따르는 속성이 있는 이진 트리
여기서 특정 순서란 모든 왼쪽 자식들은 root(또는 부모)보다 작은 값이며, 모든 오른쪽 자식들은 root(또는 부모)보다 큰 값이다.
이진 탐색 트리의 탐색 방법
Depth-First-Search(깊이 우선 탐색)
하나의 정점으로 시작해 다음 분기로 넘어가기 전에 해당 분기를 모두 탐색하고 넘어가는 방법
어떠한 방향으로 쭉 뻗어진 것을 끝까지 탐색 후 더는 길이 없다고 생각되면 다음으로 넘어간다.
이 방법은 모든 노드를 돌아보고 싶을 때 주로 사용하며
너비 우선 탐색보다 느리지만 간단하다는 장점이 있다.
이 방법은 재귀적으로 움직일 수 있고 자료구조의 스택에 가깝다.
또한 이진 트리의 전위, 중위, 후위 탐색에 사용된다.
Breadth-First-Search(너비 우선 탐색)
깊이 우선 탐색과는 반대로 하나의 정점에서 시작해 맞닿아있는 노드들을 우선적으로 탐색 후 그 다음 줄에 있는 노드들을 차례대로 탐색하는 방법
두 노드 사이의 최단 경로, 또는 임의의 경로를 찾을 때 이 방법을 사용한다.
이 방법은 재귀적으로 움직일 수 없고 자료구조의 큐에 가깝다.
이진 탐색 트리의 탐색 순서
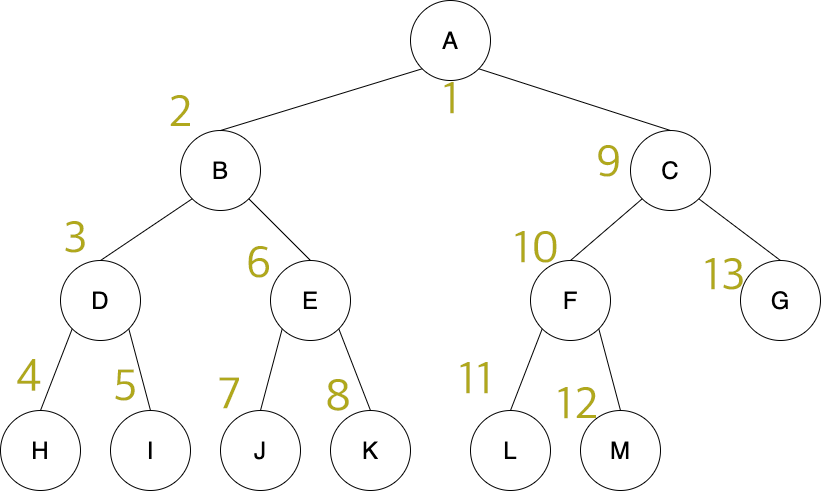
전위 순회
전위 순회는 현재 노드(루트) → 왼쪽 → 오른쪽 순서로 탐색한다
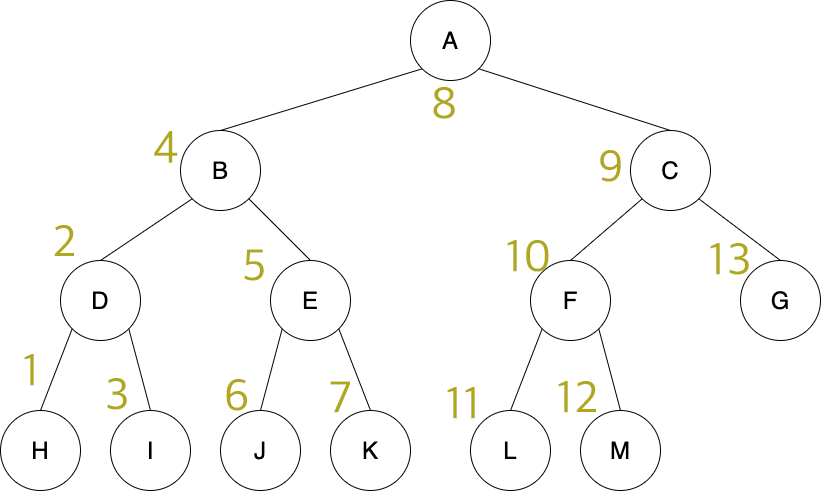
중위 순회
중위 순회는 왼쪽 → 루트 → 오른쪽 순서로 탐색한다.
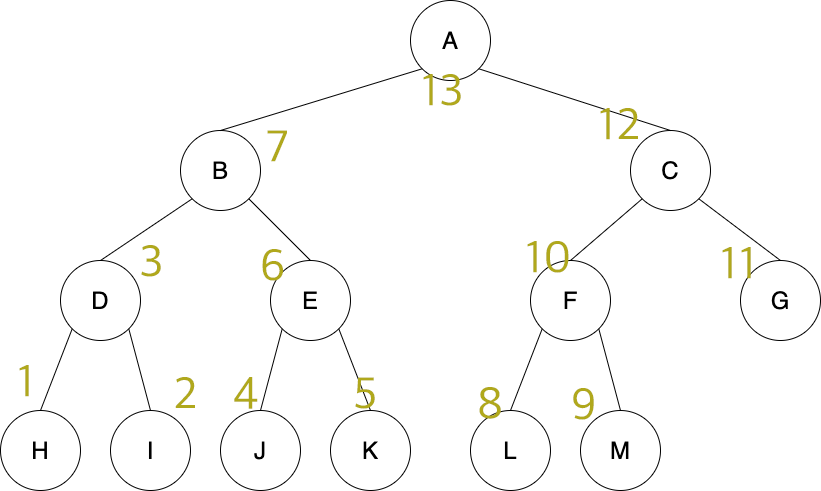
후위 순회
후위 순회는 왼쪽 → 오른쪽 → 루트 순서로 탐색한다.
현재 노드(루트)에 따라 탐색 순서가 바뀌는 구조이다.
이진 탐색 트리의 속성
node
노드(left, value, right로 구성)
subtree
자식 노드들의 값
level
노드의 깊이
height
노드의 높이
이진 탐색 트리의 메소드
insertNumberNode()
숫자로된 노드를 삽입하는 메소드
removeNumberNode()
숫자로된 노드를 삭제하는 메소드
contains()
해당 노드가 존재하는지 검색 (자식 노드를 찾기 때문에 재귀적으로 실행됨)
Depth-First-Search()(DFS)
루트에서부터 하단의 노드로 수직적으로 들어가면서 노드마다 콜백 함수에 의해 값을 변경하는 메소드
Breadth-First_search()(BFS)
루트에서부터 수평적인 레벨의 노드를 지나 하단의 노드들을 수평적으로 돌면서 콜백 함수에 의해 값을 변경하는 메소드
블로그 작성 시 참고한 문서
Graph wikipedia
Tree wikipedia
graph & tree (2)
그래프(graph)
TIL - Data Structure: Binary Search Tree, Hash Table
알아둬야할 것들
- Time Complexity(시간 복잡도)
