사전 정보
- 모든 대용량 레이터 웨어하우스는 SQL 기반
- Redshift, Snowflake, BigQuery
- hive/Presto
- Spark도 SQL이 지원됨.
Spark SQL
- Spark SQL은 구조화된 데이터 처리를 위한 Spark 모듈
- 데이터 프레임 작업을 SQL로 처리 가능.
- 데이터 프레임에 테이블 이름 지정 후, SQL 함수 사용 가능
- 판다스에도 pandassql 모듈의 sqldf 함수를 이용한 동일한 패턴 존재
- HQL(Hive Query Language)과 호환 제공
- hive 테이블들을 읽고 쓸 수 있음 (Hive Metasotre)
- 데이터 프레임에 테이블 이름 지정 후, SQL 함수 사용 가능
Spark SQL vs DataFrame
- SQL로 가능한 작업이면 굳이 DataFrame을 쓸 필요는 없음
-Familiartiy/Readability- SQL이 가독성이 더 좋고 친숙함
- Optimization
- spark SQL 엔진이 최적화하기 더 좋음.
- Interoperability/Data Management
- SQL이 포팅도 쉽고 접근권한 체크도 쉬움
Spark SQL 사용법
- 데이터 프레임을 기반으로 table view 생성
createOrReplaceTempView: spark Session이 살아있는 동안 존재createOrReplaceGlobalTempView: spark 드라이버가 살아있는 동안 존재
- Spark Session의 sql 함수로 SQL 결과를 데이터 프레임으로 받음.
namegender_df.createOrReplaceTempView("namegender")
namegender_group_df = spark.sql("""
SELECT gender, count(1) FROM namegender GROUP BY 1
""")
print(namegender_group_df.collect())
SparkSession 사용 외부 데이터베이스 연결
df_user_session_channel = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", "jdbc:redshift://HOST:PORT/DB?user=ID&password=PASSWORD") \
.option("dbtable", "raw_data.user_session_channel") \
.load()
- spark session의 read 함수를 호출(login info와 읽어오고자 하는 table 혹은 sql 지정), 결과가 데이터 프레임으로 리턴
Aggregation
- group by, window, rank 등이 있음
공통사항
!pip install pyspark==3.3.1 py4j==0.10.9.5
# 버전이 맞지 않아 특정 버전으로 다시 참조해야함.
!wget https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/2.1.0.28/redshift-jdbc42-2.1.0.28.jar -P /usr/local/lib/python3.10/dist-packages/pyspark/jars/
# 찾은 JDBC 바탕으로 세션 생성
from pyspark.sql import SparkSession
# SparkSession 생성
spark = SparkSession.builder \
.appName("Python Spark SQL #1") \
.config("spark.jars", "/usr/local/lib/python3.10/dist-packages/pyspark/jars/redshift-jdbc42-2.1.0.28.jar") \
.getOrCreate()사전 테이블 정보
-
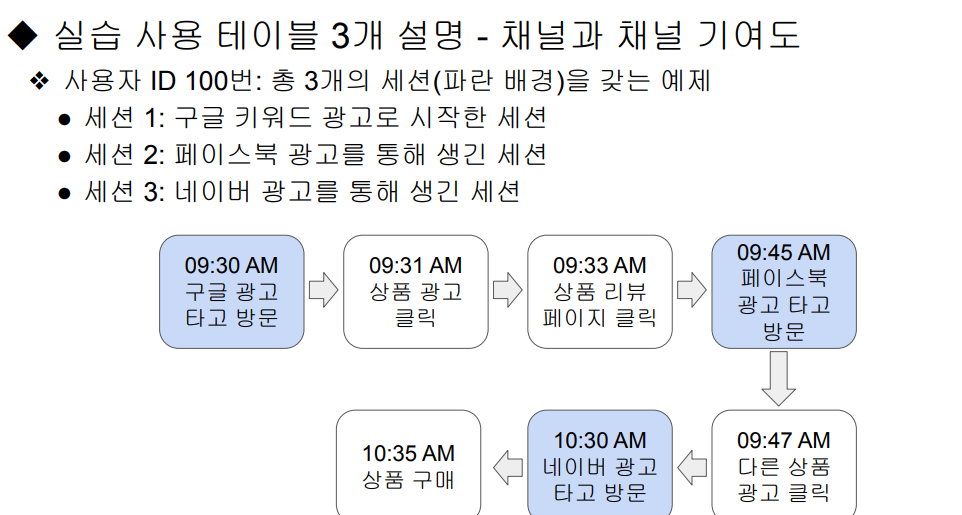
사용자 ID:
- 각 웹서비스 사용자는 고유한 ID를 부여받음.
- 이 고유 ID는 사용자 식별에 사용됨.
-
세션 ID:
- 사용자가 외부 링크(광고 등)나 직접 방문하여 웹사이트에 접속할 때 생성됨.
- 하나의 사용자 ID는 여러 개의 세션 ID를 가질 수 있음.
- 세션에는 세션 생성 원천(채널)과 생성 시간이 기록됨.
- 주로 마케팅 기여도 분석을 위해 사용됨.
활용
- 마케팅 분석: 채널별 기여도 평가.
- 사용자 트래픽 분석: 방문 시간 및 경로 분석.

테스트 : 매출 사용자 10명 알아내기
- 3개의 테이블을 각기 데이터프레임으로 로딩
- 데이터 프레임별로 테이블 이름 지정
- Spark SQL로 처리
- 조인 방식 결정
# Redshift와 연결해서 DataFrame으로 로딩하기
url = "jdbc:redshift://le666666edshift.amazonaws.com:5439/dev?user=66666&password=666666"
df_user_session_channel = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.user_session_channel") \
.load()
df_session_timestamp = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.session_timestamp") \
.load()
df_session_transaction = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.session_transaction") \
.load()- 데이터 프레임 형태로 불러오기
df_user_session_channel.createOrReplaceTempView("user_session_channel")
df_session_timestamp.createOrReplaceTempView("session_timestamp")
df_session_transaction.createOrReplaceTempView("session_transaction")createOrReplaceTempView로 데이터프레임을 View로 생성
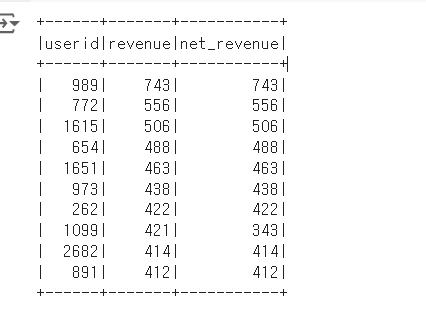
top_rev_user_df = spark.sql("""
SELECT userid,
SUM(str.amount) revenue,
SUM(CASE WHEN str.refunded = False THEN str.amount END) net_revenue
FROM user_session_channel usc
JOIN session_transaction str ON usc.sessionid = str.sessionid
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10""")
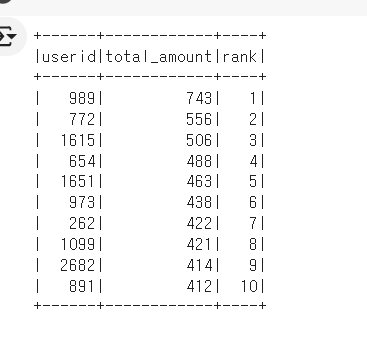
top_rev_user_df2 = spark.sql("""
SELECT
userid,
SUM(amount) total_amount,
RANK() OVER (ORDER BY SUM(amount) DESC) rank
FROM session_transaction st
JOIN user_session_channel usc ON st.sessionid = usc.sessionid
GROUP BY userid
ORDER BY rank
LIMIT 10""")- 이런 식으로 랭크를 생성 가능.
테스트 : 월별 채널별 매출과 방문자 정보 계산
!wget https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/2.1.0.28/redshift-jdbc42-2.1.0.28.jar -P /usr/local/lib/python3.10/dist-packages/pyspark/jars/
- jdbc 설정
from pyspark.sql import SparkSession
# SparkSession 생성
spark = SparkSession.builder \
.appName("Python Spark SQL #3") \
.config("spark.jars", "/usr/local/lib/python3.10/dist-packages/pyspark/jars/redshift-jdbc42-2.1.0.28.jar") \
.getOrCreate()
- 세션 설정
# Redshift와 연결해서 DataFrame으로 로딩하기
url = "jdbc:redshift://l-svt.ap-northeast-2.re-9/dev?user=gues-34"
df_user_session_channel = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.user_session_channel") \
.load()
df_session_timestamp = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.session_timestamp") \
.load()
df_session_transaction = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.session_transaction") \
.load()- 데이터프레임 생성
df_user_session_channel.createOrReplaceTempView("user_session_channel")
df_session_timestamp.createOrReplaceTempView("session_timestamp")
df_session_transaction.createOrReplaceTempView("session_transaction")- 뷰 생성
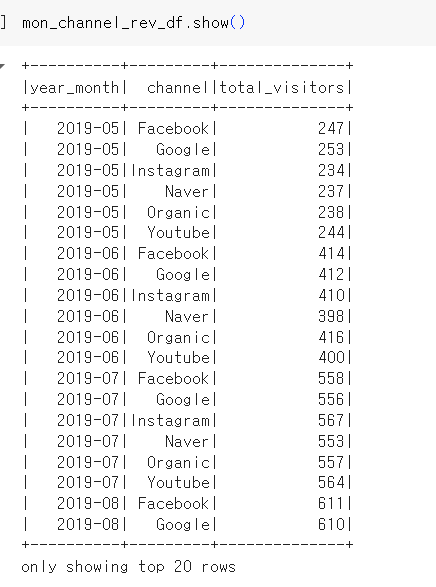
mon_channel_rev_df = spark.sql("""
SELECT LEFT(sti.ts, 7) year_month,
usc.channel channel,
COUNT(DISTINCT userid) total_visitors
FROM user_session_channel usc
LEFT JOIN session_timestamp sti ON usc.sessionid = sti.sessionid
GROUP BY 1 ,2
ORDER BY 1, 2""")- 월별 채널별 총 방문자 계산
mon_channel_rev_df = spark.sql("""
SELECT LEFT(sti.ts, 7) year_month,
usc.channel channel,
COUNT(DISTINCT userid) total_visitors,
COUNT(DISTINCT CASE WHEN amount is not NULL THEN userid END) paid_visitors
FROM user_session_channel usc
LEFT JOIN session_timestamp sti ON usc.sessionid = sti.sessionid
LEFT JOIN session_transaction str ON usc.sessionid = str.sessionid
GROUP BY 1 ,2
ORDER BY 1, 2""")- 월별 채널별 총 방문자와 구매 방문자 계산
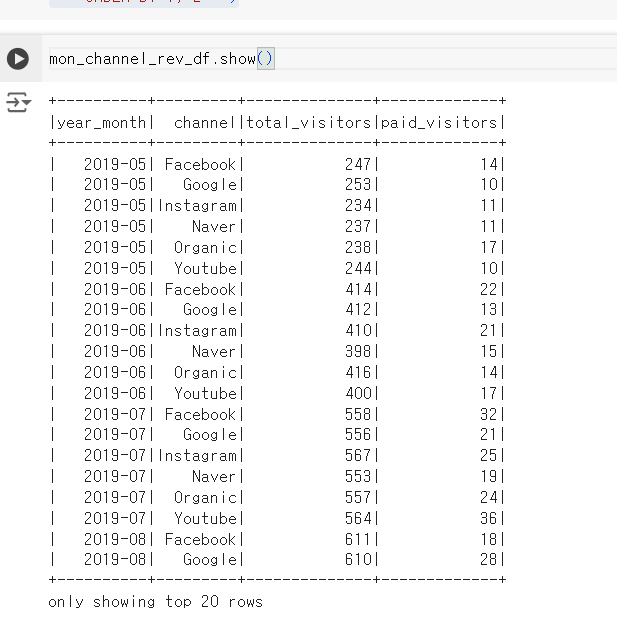
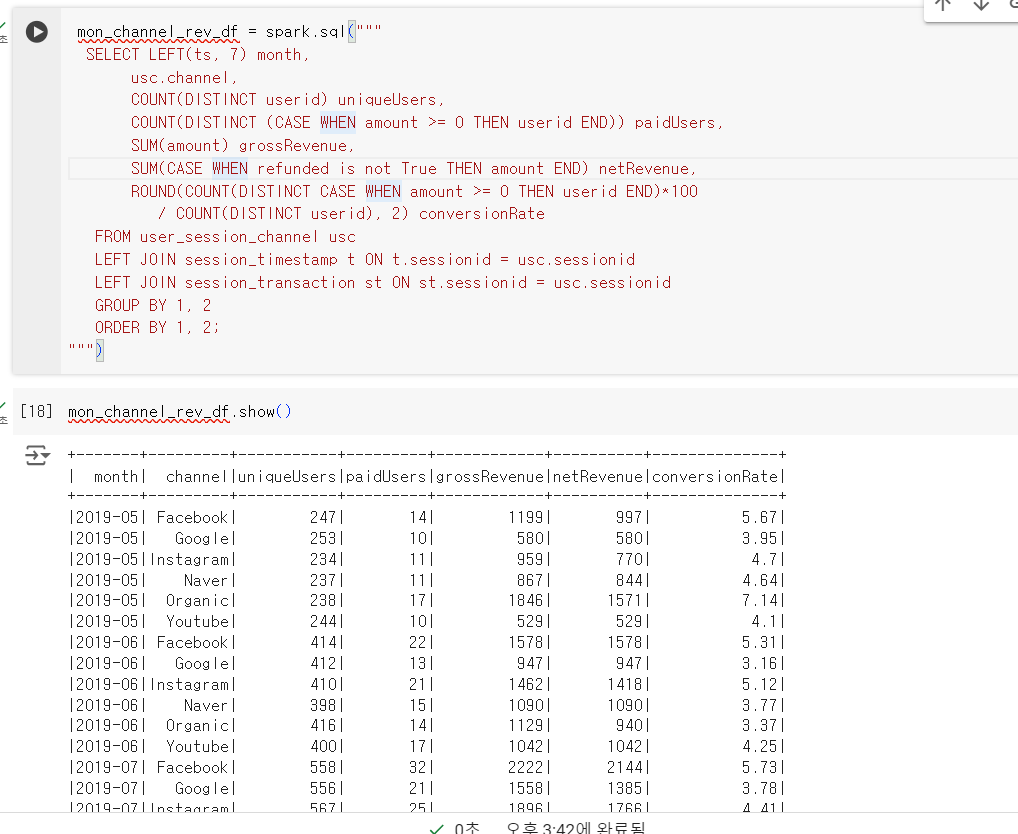
mon_channel_rev_df = spark.sql("""
SELECT LEFT(ts, 7) month,
usc.channel,
COUNT(DISTINCT userid) uniqueUsers,
COUNT(DISTINCT (CASE WHEN amount >= 0 THEN userid END)) paidUsers,
SUM(amount) grossRevenue,
SUM(CASE WHEN refunded is not True THEN amount END) netRevenue,
ROUND(COUNT(DISTINCT CASE WHEN amount >= 0 THEN userid END)*100
/ COUNT(DISTINCT userid), 2) conversionRate
FROM user_session_channel usc
LEFT JOIN session_timestamp t ON t.sessionid = usc.sessionid
LEFT JOIN session_transaction st ON st.sessionid = usc.sessionid
GROUP BY 1, 2
ORDER BY 1, 2;
""")- 월별 채널별 총 매출액 (리펀드 포함), 총 방문자, 매출 발생 방문자, 전환률 계산
테스트 : 사용자별로 처음 채널과 마지막 채널 알아내기


#세션 설정
from pyspark.sql import SparkSession
# SparkSession 생성
spark = SparkSession.builder \
.appName("Python Spark SQL #2") \
.config("spark.jars", "/usr/local/lib/python3.10/dist-packages/pyspark/jars/redshift-jdbc42-2.1.0.28.jar") \
.getOrCreate()
- 세션 설정
# Redshift와 연결해서 DataFrame으로 로딩하기
url = "jdbc:redshift://learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev?user=guest&password=Guest1234"
df_user_session_channel = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.user_session_channel") \
.load()
df_session_timestamp = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.session_timestamp") \
.load()
df_session_transaction = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.session_transaction") \
.load()- 이름이 들어간 데이터프레임 생성
df_user_session_channel.createOrReplaceTempView("user_session_channel")
df_session_timestamp.createOrReplaceTempView("session_timestamp")
df_session_transaction.createOrReplaceTempView("session_transaction")- 뷰 생성
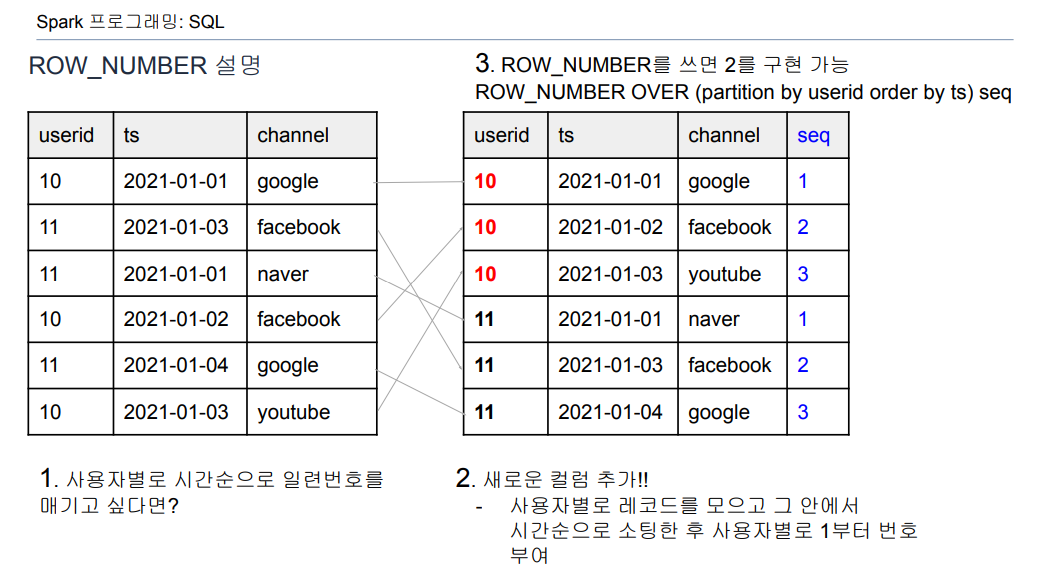
first_last_channel_df = spark.sql("""
WITH RECORD AS (
SELECT /*사용자의 유입에 따른, 채널 순서 매기는 쿼리*/
userid,
channel,
ROW_NUMBER() OVER (PARTITION BY userid ORDER BY ts ASC) AS seq_first,
ROW_NUMBER() OVER (PARTITION BY userid ORDER BY ts DESC) AS seq_last
FROM user_session_channel u
LEFT JOIN session_timestamp t
ON u.sessionid = t.sessionid
)
SELECT /*유저의 첫번째 유입채널, 마지막 유입 채널 구하기*/
f.userid,
f.channel first_channel,
l.channel last_channel
FROM RECORD f
INNER JOIN RECORD l ON f.userid = l.userid
WHERE f.seq_first = 1 and l.seq_last = 1
ORDER BY userid
""")- 테이블을 이용해서 사용자별로 처음 채널과 마지막 채널 알아내기
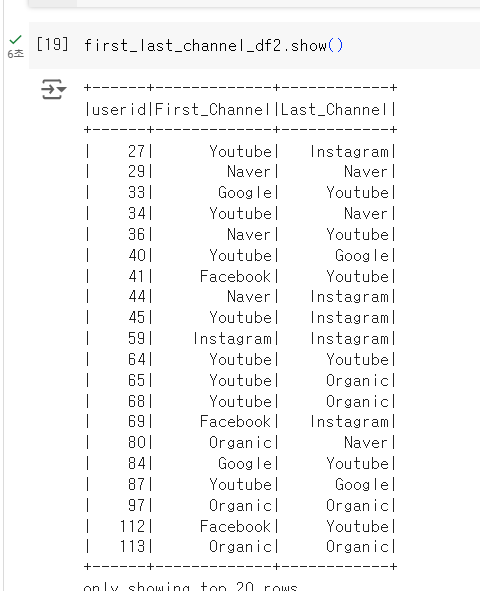
first_last_channel_df2 = spark.sql("""
SELECT DISTINCT A.userid,
FIRST_VALUE(A.channel) over(partition by A.userid order by B.ts
rows between unbounded preceding and unbounded following) AS First_Channel,
LAST_VALUE(A.channel) over(partition by A.userid order by B.ts
rows between unbounded preceding and unbounded following) AS Last_Channel
FROM user_session_channel A
LEFT JOIN session_timestamp B
ON A.sessionid = B.sessionid""")-
이런식으로도 같은 결과를 얻을 수 있음
join
- sql 조인은 2 개 이상의 혹은 그 이상의 테이블들의 공통 필드를 가지고 merge
- star schema 로 구성된 table들로 부터 분산되어 있던 정보를 통합하는데 사용
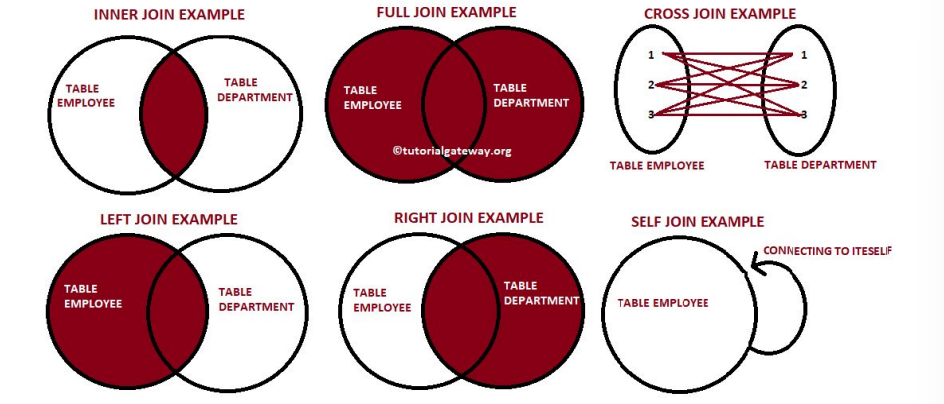
- 그냥 전체적으로 sql과 비슷
예제 데이터
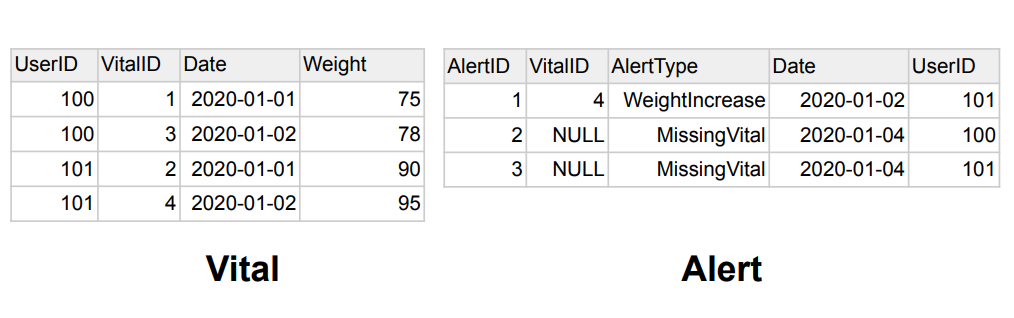
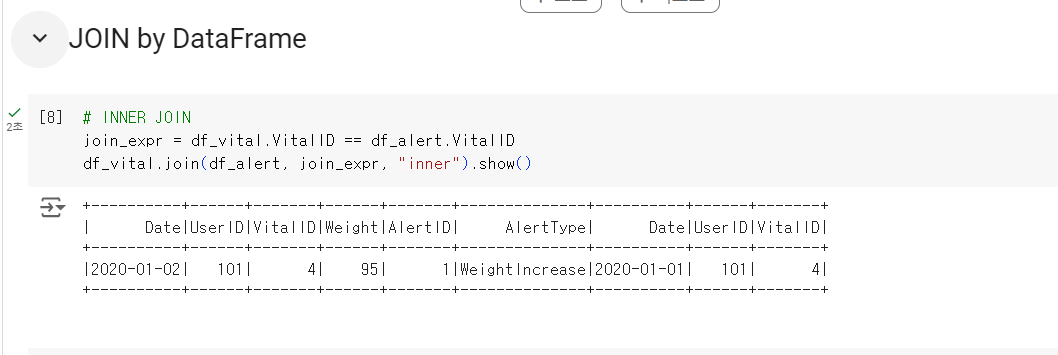
1. inner join
- 양쪽 테이블에서 매치가 되는 레코드만 리턴
- 필드가 모두 채워짐
select * from Vital v
join Alert a ON v.vitalID = a.vitalID;
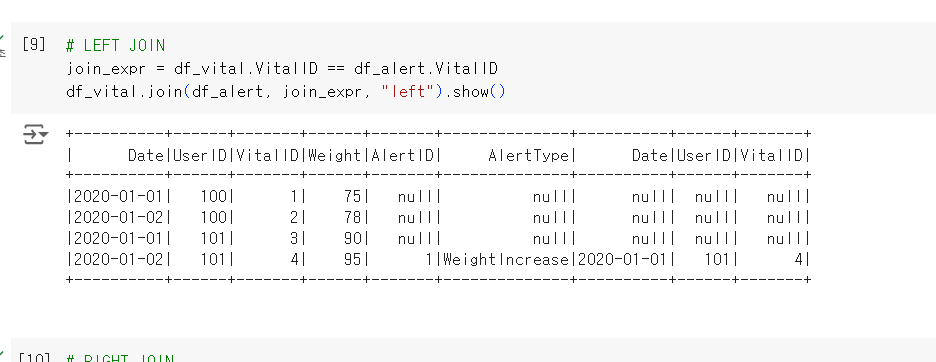
2. left join
- 왼쪽 베이스 테이블 기준으로 레코드 리턴
- 왼쪽 레코드와 매칭되는 경우만 채워진 상태로 리턴(나머진 NULL)
select *
from raw_data.Vital v LEFT JOIN raw_data.Alert a ON v.vitalID = a.vitalID;
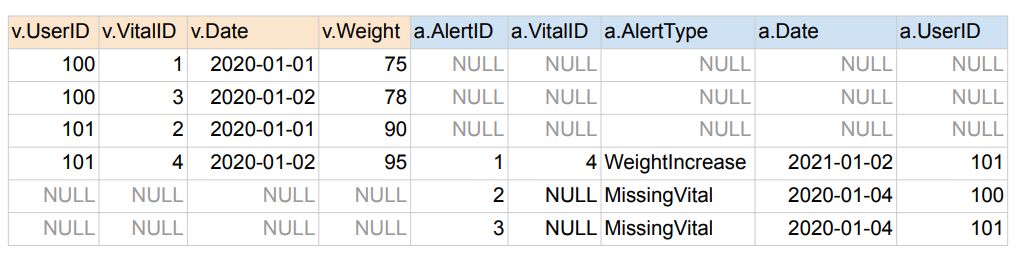
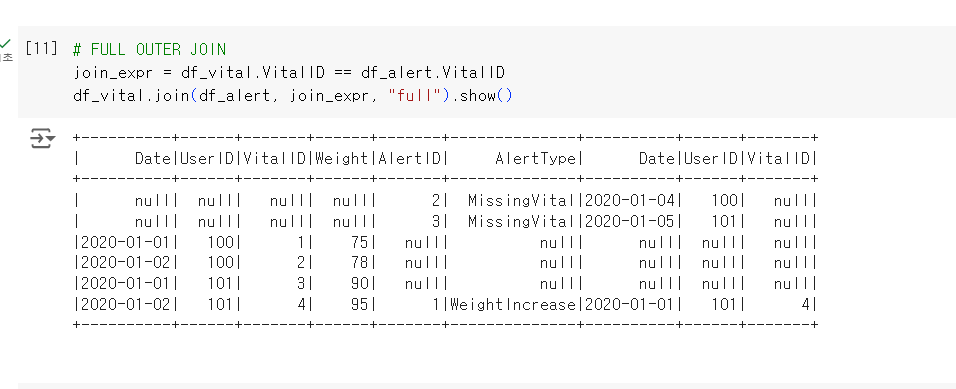
3. FULL join
SELECT * FROM raw_data.Vital v
FULL JOIN raw_data.Alert a ON v.vitalID = a.vitalID;
- 왼쪽 테이블과 오른쪽 테이블 모든 레코드 리턴
- 매칭되는 경우에만 양쪽 테이블이 모두 채워짐
4. CROSS JOIN
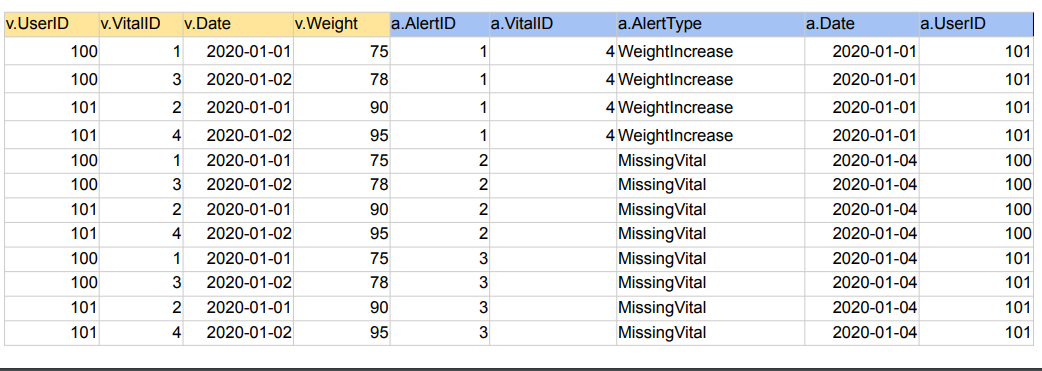
SELECT * FROM raw_data.Vital v CROSS JOIN raw_data.Alert a;
-
왼쪽 테이블과 오른쪽 테이블의 모든 레코드들의 조합을 리턴
-
경우의 수를 생각하면 쉬운데 n개와 m개의 테이블이 있으면 cross join을 하면 n * m 개의 레코드가 나옴
5. SELF JOIN
- 동일한 테이블을 alias를 달리해서 자기 자신과 조인
SELECT * FROM raw_data.Vital v1
JOIN raw_data.Vital v2 ON v1.vitalID = v2.vitalID;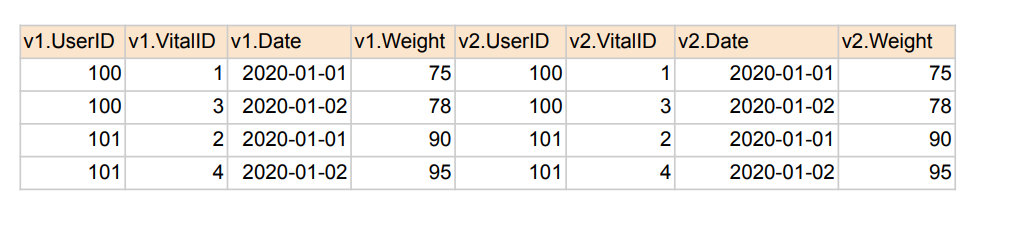
최적화 관점에서 본 조인 종류
- Shuffle join
- 일반 조인 방식
- Bucket join : 조인 키를 바탕으로 새로 파티션을 만들고 조인하는 방식
- BroadCast join
- 큰 데이터와 작은 데이터 간의 조인
- 데이터 프레임 하나가 충분히 작으면 작은 데이터 프레임을 다른 데이터프레임이 있는 서버들로 뿌리는 것(네트워크 계층의 Broadcasting과 비슷)
spark.sql.autoBroadcastjoinThreshold파라미터로 충분히 작은지 여부 결정
UDF
- dataframe의 경우
.withColumn함수와 같이 사용하는 것이 일반적이고, spark sql에서도 사용 가능 - Aggregation용 UDFA(User Defined Aggregation Function)도 존재
- group by에서 사용되는 sum,avg와 같은 함수를 만드는 것
- Pyspark에서는 지원 X, Scala,java 사용해야함
UDF - DataFrame test
import pyspark.sql.functions as F
from pyspark.sql.types import *
#입력값 z를 대문자로 변환하는 간단한 함수
upperUDF = F.udf(lambda z:z.upper())
#Curated Name이라는 새로운 열을 추가하고 이 열의 값은 Name을 통해 기존 Name을 대문자로 바꾸는 것
df.withColumn("Curated Name", upperUDF("Name"))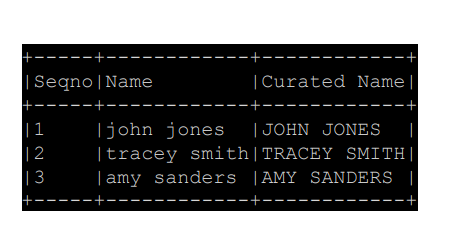
UDF - SQL test
def upper(s):
return s.upper()
# 먼저 테스트
upperUDF = spark.udf.register("upper", upper)
spark.sql("SELECT upper('aBcD')").show()
# DataFrame 기반 SQL에 적용
df.createOrReplaceTempView("test")
spark.sql("""SELECT name, upper(name) "Curated Name" FROM test""").show()UDF - Dataframe test 2
data = [
{"a": 1, "b": 2},
{"a": 5, "b": 5}
]
df = spark.createDataFrame(data)
df.withColumn("c", F.udf(lambda x, y: x + y)("a", "b"))- a컬럼의 값이 x, b컬럼의 값이 y
- 이 둘을 더해 c라는 컬럼을
.withColums로 추가
UDF - SQL - test 2
def plus(x, y):
return x + y
#spark.udf.register를 사용하여 정의한 upper함수를 upper라는 이름으로 UDF에 등록
plusUDF = spark.udf.register("plus", plus)
spark.sql("SELECT plus(1, 2)").show()
df.createOrReplaceTempView("test")
spark.sql("SELECT a, b, plus(a, b) c FROM test").show()UDF 실습
- 하나의 레코드로부터 다수의 레코드 만들어내기
- order data의 items 필드에서 다수의 order item 레코드를 만들기
!wget https://s3-geospatial.s3.us-west-2.amazonaws.com/orders.csv- csv 파일 다운
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark UDF") \
.getOrCreate()- spark session 생성

- 정보 체크
from pyspark.sql.functions import *
from pyspark.sql.types import StructType, StructField, StringType, ArrayType, LongType
order = spark.read.options(delimiter='\t').option("header","true").csv("orders.csv")- spark.read는 DataFrameReader 객체, 파일을 읽어와 데이터 프레임으로 생성
options(delimiter='\t'는 csv 파일 필드 구분자- header true는 csv 파일의 첫 번째 행을 헤더로 구분
struct = ArrayType(
StructType([
StructField("name", StringType()),
StructField("id", StringType()),
StructField("quantity", LongType())
])
)
- 이제 분할을 위해 json 배열의 구조를 정의
order.withColumn("item", explode(from_json("items", struct))).show(truncate=False)
from_json("items", struct)은item열의 json 데이터를 정의한 스키마struct를 사용하여 구조화된 데이터로 변환- exploade 함수느 배열 또는 맵 타입의 열을 개별 레코드로 변환
truncate=False은 긴 문자열도 잘리지 않고 모두 표시
order_items = order.withColumn("item", explode(from_json("items", struct))).drop("items")
- order 데이터 프레임에 새로운 item 열을 추가하고, 원래 items 열을 삭제하여 order_items 데이터 프레임 생성
order_items.show(5)
order_items.printSchema()
-
스키마 구조와 상위 5개 레코드 확인하는 쿼리
order_items.createOrReplaceTempView("order_items") spark.sql("""SELECT item.quantity FROM order_items WHERE order_id = '1816674631892'""").show() -
생성한 데이터 프레임을 임시 뷰로 등록
-
쿼리문
spark.catalog.listTables()
for f in spark.catalog.listFunctions():
print(f[0])
spark.catalog.listTables()현재 세션에 등록된 테이블의 목록을 반환spark.catalog.listFunctions()현재 세션에 등록된 함수 목록 반환
HIVE 메타 스토어
카탈로그 : 테이블과 뷰에 관한 메타 데이터 처리
- 기본적으로 메모리 기반 카탈로그 제공 - session이 끝나면 종료
- hive와 호환되는 카탈로그 제공 - persistent
테이블 관리 방식
-
테이블들은 데이터베이스라 부르는 폴더와 같은 구조로 관리
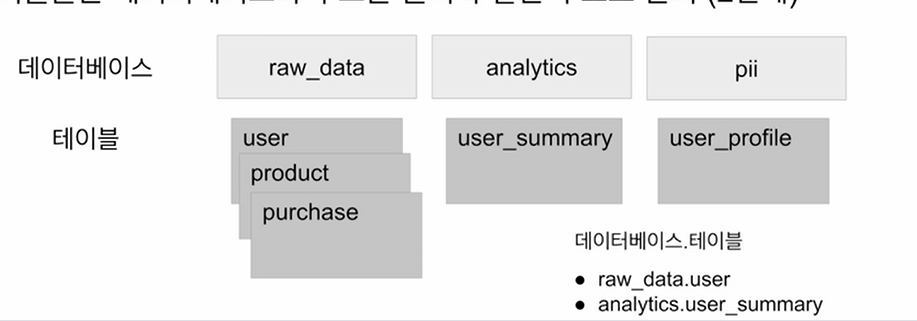
-
DB로 치면 스키마 - 테이블 느낌
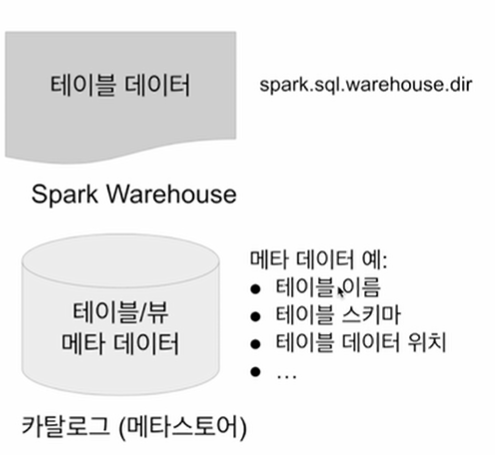
- 메모리 기반 테이블/뷰
- 스토리지 기반 테이블
- 기본적으로 HDFS와 Parquet 포맷을 사용
- hive와 호환되는 메타스토어 사용
- 두 종류의 테이블이 존재 (Hive와 동일한 개념)
- Managed Table
- spark의 실제 데이터와 메타 데이터 모두 관리
- Unmanaged Table
- spark의 메타 데이터만 관리
- Managed Table
Spark SQL - 스토리지 기반 카탈로그 사용 방법
-
Hive와 호환되는 메타스토어 사용:
- Spark는 Hive 메타스토어와 호환됨.
- 이를 통해 데이터를 관리하고 쿼리할 수 있음.
-
SparkSession 생성 시 enableHiveSupport() 호출:
- Hive 메타스토어와의 통합을 위해 SparkSession 생성 시
enableHiveSupport()를 호출함. - 기본적으로 “default”라는 이름의 데이터베이스가 생성됨.
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("Python Spark Hive") \ .enableHiveSupport() \ .getOrCreate() - Hive 메타스토어와의 통합을 위해 SparkSession 생성 시
Managed Table 사용 방법
-
테이블 생성 방법:
dataframe.saveAsTable("테이블이름")을 사용하여 데이터 프레임을 테이블로 저장할 수 있음.- SQL 문법 (
CREATE TABLE,CTAS)을 사용하여 테이블을 생성할 수 있음.
-
데이터 저장 위치:
- 테이블의 데이터는
spark.sql.warehouse.dir가 가리키는 위치에 저장됨. - 기본 데이터 포맷은 PARQUET임.
- 테이블의 데이터는
-
테이블 타입의 선호:
- Spark 테이블을 사용하는 것의 장점은 JDBC/ODBC 등을 통해 Spark에 연결하여 접근할 수 있다는 점임. 이는 태블로, 파워BI 등에서 유용함.
External Table 사용 방법
-
HDFS에 존재하는 데이터 사용:
- 이미 HDFS에 존재하는 데이터에 대해 스키마를 정의하여 사용할 수 있음.
- 이때
LOCATION이라는 프로퍼티를 사용함.
-
메타데이터 관리:
- External Table의 경우 메타데이터만 카탈로그에 기록되고 데이터는 기존 위치에 그대로 존재함.
- External Table이 삭제되더라도 실제 데이터는 삭제되지 않음.
-
테이블 생성 예시:
CREATE TABLE table_name ( column1 type1, column2 type2, column3 type3, … ) USING PARQUET LOCATION 'hdfs_path';
요약
- Managed Table은 데이터를 Spark가 관리하는 위치에 저장하며, 쉽게 쿼리하고 관리할 수 있음.
- External Table은 이미 존재하는 데이터를 참조만 하여 사용하며, 데이터 삭제 위험이 없음.
- SparkSession을 생성할 때
enableHiveSupport()를 사용하여 Hive 메타스토어와 통합함. - Spark SQL을 통해 데이터를 효율적으로 관리하고 다양한 BI 도구와 통합할 수 있음.
Hive 메타스토어란?
-
메타데이터 저장:
- Hive 메타스토어는 데이터베이스, 테이블, 파티션 등의 메타데이터를 저장함.
- 데이터베이스를 논리적으로 구분하여 테이블의 스키마 및 위치 정보를 저장함.
- 테이블을 파티션으로 나누어 각 파티션의 정보를 메타데이터로 관리함.
- 테이블의 구조(열 이름, 데이터 타입 등)를 정의하고 저장함.
-
데이터 접근 관리:
- 각 테이블과 파티션의 실제 데이터 파일 위치(HDFS 경로 등)를 관리함.
- 쿼리 실행 시 테이블 스키마 및 데이터 타입을 검증함.
-
통합 및 호환성:
- Hive 메타스토어는 다양한 빅 데이터 툴 및 애플리케이션과 통합되어 사용될 수 있음.
- Apache Spark, Presto, Apache Impala 등에서 Hive 메타스토어를 사용하여 메타데이터를 공유함으로써 동일한 데이터 소스를 쉽게 쿼리할 수 있음.
Spark와 Hive 메타스토어 통합
-
SparkSession 생성 시 enableHiveSupport() 호출:
- Spark는 Hive 메타스토어와 통합하여 데이터 프레임 및 SQL 쿼리 작업을 수행할 수 있음.
enableHiveSupport()를 호출하여 Hive 메타스토어를 사용하게 함.
from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .appName("Python Spark Hive") \ .enableHiveSupport() \ .getOrCreate() -
중앙 집중화 및 데이터 관리:
- 메타데이터를 중앙에서 관리함으로써 여러 애플리케이션에서 동일한 메타데이터를 참조할 수 있음.
- 메타데이터를 체계적으로 관리하여 데이터 탐색과 관리가 용이해짐.
-
호환성:
- 다양한 빅 데이터 처리 엔진과 호환되어 데이터 통합 및 분석 작업을 용이하게 함.
Hive 메타스토어는 빅 데이터 환경에서 데이터 관리와 접근성을 높이기 위해 중요한 역할을 함.
hive 메타 응용
SparkSession을 생성하여 Hive 메타스토어와 통합하는 방법은 Spark SQL을 사용하여 Hive 테이블과 메타데이터를 관리하고 쿼리하는 데 유용합니다. 이를 활용하여 다양한 데이터 작업을 수행할 수 있습니다. 다음은 SparkSession을 활용하는 몇 가지 방법입니다:
1. Hive 테이블 생성 및 데이터 삽입
Hive 메타스토어를 사용하여 새로운 테이블을 생성하고 데이터를 삽입할 수 있습니다.
# 테이블 생성
spark.sql("CREATE TABLE IF NOT EXISTS test_table (id INT, name STRING)")
# 데이터 삽입
spark.sql("INSERT INTO test_table VALUES (1, 'Alice'), (2, 'Bob')")2. 기존 Hive 테이블 조회
기존에 Hive에 저장된 테이블을 조회할 수 있습니다.
# 테이블 조회
df = spark.sql("SELECT * FROM test_table")
df.show()3. DataFrame을 사용하여 테이블 저장
DataFrame을 생성하여 Hive 테이블로 저장할 수 있습니다.
# DataFrame 생성
data = [(3, 'Charlie'), (4, 'David')]
columns = ["id", "name"]
df = spark.createDataFrame(data, columns)
# DataFrame을 테이블로 저장
df.write.saveAsTable("test_table")4. External Table 생성
이미 HDFS에 존재하는 데이터를 External Table로 정의할 수 있습니다.
# External Table 생성
spark.sql("""
CREATE EXTERNAL TABLE IF NOT EXISTS external_table (
id INT,
name STRING
)
STORED AS PARQUET
LOCATION 'hdfs://path/to/data'
""")5. 테이블을 이용한 데이터 분석
Hive 메타스토어와 통합된 SparkSession을 사용하여 다양한 데이터 분석 작업을 수행할 수 있습니다.
# 데이터 분석 쿼리 실행
result = spark.sql("SELECT name, COUNT(*) as count FROM test_table GROUP BY name")
result.show()6. 메타데이터 관리
Hive 메타스토어를 통해 데이터베이스와 테이블의 메타데이터를 관리할 수 있습니다.
# 데이터베이스 목록 조회
databases = spark.sql("SHOW DATABASES")
databases.show()
# 테이블 목록 조회
tables = spark.sql("SHOW TABLES IN default")
tables.show()활용 장점
- 중앙 집중화된 메타데이터 관리: 데이터베이스와 테이블의 메타데이터를 중앙에서 관리하여 일관성 유지.
- 확장성: 대용량 데이터 처리에 적합하며, 다양한 데이터 소스와 통합 가능.
- 유연한 쿼리 수행: SQL 문법을 사용하여 복잡한 데이터 쿼리와 분석을 수행할 수 있음.
- 다양한 BI 도구와 호환성: JDBC/ODBC를 통해 태블로, 파워BI 등 다양한 BI 도구와 통합 가능.
