spark 파일 포맷
파일포맷
파일 포맷의 역할
데이터 저장: 파일 포맷은 데이터를 저장하는 표준화된 방법을 제공데이터 교환: 서로 다른 시스템이나 응용 프로그램 간에 데이터를 주고받을 때 고통의 포맷이 필요, 이를 통해 호환성 보장데이터 해석: 특정 파일 포맷을 사용하면 해당 포맷을 이해하는 소프트웨어가 데이터를 올바르게 읽고 처리
파일 포맷의 분류
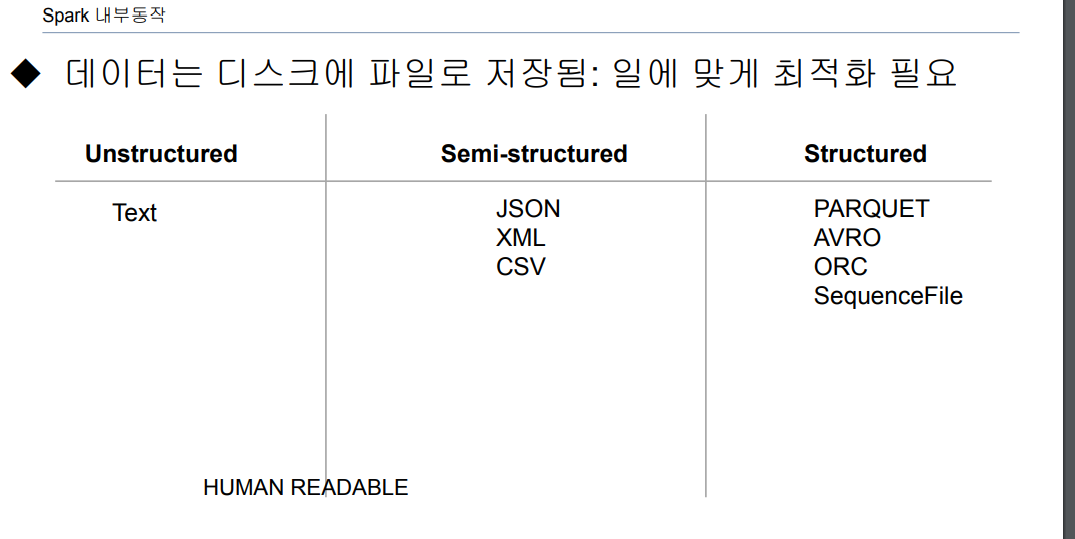
text file format: 사람이 읽을 수 있는 형식으로 예시로txt,csv,jsonbinary file format: 컴퓨터가 직접 해석하는 것 예시로.bin,.exe,.avro가 있음- 이미지 파일 포맷 우리가 아는 .jpg.. png..
- 비디오 파일 포맷 오디오 파일 포맷 등은 우리가 이미 앎
spark에서의 파일 포맷
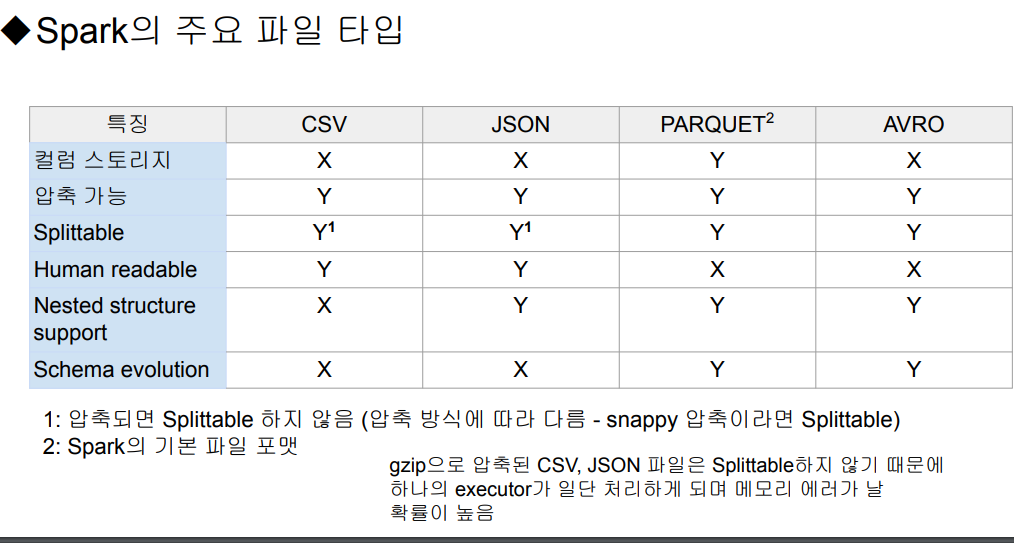
- spark는 대규모 데이터 처리를 위해 다양한 파일 포맷을 지원.
ORC,Parquet과 같은컬럼 지향 포맷은 분석 쿼리 성능을 극대화json,Avro는 유연한 데이터 모델링과 호환성 제공
Parquet
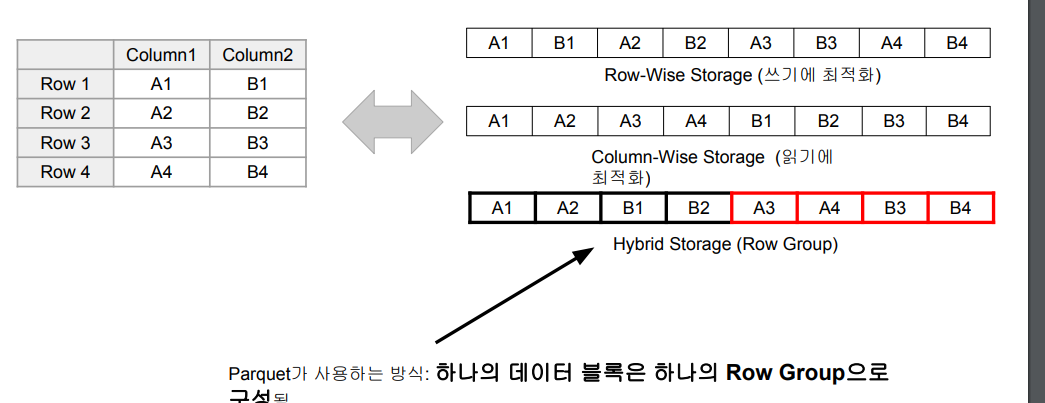
Parquet이 Spark의 기본 파일 포맷임.
용어
Splittable : 쪼갤 수 있는, 데이터 파일을 여러 부분으로 나누어 병럴로 처리할 수 있는 능력
Human readable : 사람이 읽을 수 있는 데이터 파일이 사람이 읽기 쉽게 작성된 형태
Nested structure support : 중첩된 구조 지원. 데이터 파일이 중첩된(계층적인) 구조를 지원하는지 여부
Schema evolution : 스키마 진화, 데이터 파일의 스키마를 변경해도 호환되도록 지원하는 능력
예시
df.write \
.format("avro") \
.mode("overwrite") \
.option("path", "dataOutput/avro/") \
.save()
df2.write \
.format("parquet") \
.mode("overwrite") \
.option("path", "dataOutput/parquet/") \
.save()
df3.write \
.format("json") \
.mode("overwrite") \
.option("path", "dataOutput/json/") \
.save()예시 2
!wget https://s3-geospatial.s3.us-west-2.amazonaws.com/schema1.parquet
!wget https://s3-geospatial.s3.us-west-2.amazonaws.com/schema2.parquet
!wget https://s3-geospatial.s3.us-west-2.amazonaws.com/schema3.parquet- 자료 다운로드(세션은 이미 생성됐다고 가정)
df1 = spark.read. \
parquet("schema1.parquet")
df1.printSchema()
df1.show()
df = spark.read. \
option("mergeSchema", True). \
parquet("*.parquet")
df.printSchema()
- 전부 통합.

Spark 내부동작
Spark 내부 동작에 관한 설명
실행 계획(Execution Plan)
Spark의 실행 계획은 사용자가 작성한 코드를 어떻게 변환하여 실행할지를 정의함. 실행 계획은 주로 Transformations와 Actions로 구성됨.
-
Transformations: 데이터 프레임을 변환하는 연산. 지연 실행(Lazy Execution) 방식으로, 실제로 Action이 호출될 때까지 실행되지 않음.
- Narrow Dependencies: 각 파티션이 독립적으로 처리됨. 예:
select,filter,map - Wide Dependencies: 셔플링이 필요하며, 파티션 간의 의존성이 발생함. 예:
groupby,reduceby,repartition
- Narrow Dependencies: 각 파티션이 독립적으로 처리됨. 예:
-
Actions: 데이터를 실제로 처리하는 연산. Transformations을 적용하여 결과를 반환함.
- 예:
show,collect,count,write
- 예:
Jobs, Stages, Tasks
Spark는 Action이 호출될 때 Job을 생성함. 각 Job은 여러 Stage로 나뉘고, 각 Stage는 여러 Task로 구성됨.
Action -> job -> 1+Stages -> 1+Tasks
- Job: Action에 의해 생성되며, 하나 혹은 기 이상의 Stage로 나뉨,
- Stage: 파티션 간 셔플링이 발생할 때마다 새로운 Stage가 생성됨. DAG(Directed Acyclic Graph) 형태로 구성됨.
- Task: Stage를 구성하는 가장 작은 실행 단위. Executor에 의해 병렬로 실행됨.
최적화 기법
Spark는 다양한 최적화 기법을 사용하여 데이터 처리 성능을 향상시킴. 주요 기법은 다음과 같음:
- Catalyst Optimizer: Spark SQL의 쿼리 최적화 엔진으로, 논리적 계획을 최적화하고 물리적 계획을 생성함.
- Tungsten Execution Engine: Spark의 실행 엔진으로, CPU 및 메모리 사용을 최적화함.
- Project Tungsten: 메모리 관리, 코드 생성, 스케줄링을 개선하여 성능을 극대화함.
예제 코드
아래는 Spark에서 데이터 프레임을 생성하고, Transformations와 Actions을 사용하는 예제임.
from pyspark.sql import SparkSession
# Spark 세션 생성
spark = SparkSession.builder \
.appName("Spark Example") \
.master("local[3]") \
.getOrCreate()
# 데이터 프레임 생성
df = spark.read.option("header", True).csv("data.csv")
# Transformation 예제
df_filtered = df.where("gender <> 'F'")
df_selected = df_filtered.select("name", "gender")
df_grouped = df_selected.groupby("gender").count()
# Action 예제
df_grouped.show()이 코드는 다음과 같은 단계를 포함함:
1. CSV 파일을 읽어 데이터 프레임 생성
2. where 연산을 통해 필터링 (Narrow Dependency)
3. select 연산을 통해 특정 컬럼 선택 (Narrow Dependency)
4. groupby 연산을 통해 그룹화 및 집계 (Wide Dependency)
5. show 연산을 통해 결과 출력 (Action)
결론
Spark의 내부 동작은 복잡하지만, 다양한 최적화 기법과 효율적인 실행 계획을 통해 대규모 데이터 처리와 분석을 효과적으로 수행할 수 있음. 각 단계에서의 최적화와 병렬 처리를 통해 높은 성능을 제공하며, 사용자는 이를 이해하고 적절히 활용하여 데이터 처리 작업을 최적화할 수 있음.
Spark test
WordCount 코드의 Spark 내부 동작 설명
1. SparkSession 생성
먼저, SparkSession을 생성하여 Spark 애플리케이션을 시작함. SparkSession.builder를 사용하여 세 개의 CPU 코어를 사용하는 로컬 모드에서 실행됨. spark.sql.adaptive.enabled 옵션은 False로 설정되고, spark.sql.shuffle.partitions는 3으로 설정됨.
spark = SparkSession \
.builder \
.master("local[3]") \
.appName("SparkSchemaDemo") \
.config("spark.sql.adaptive.enabled", False) \
.getOrCreate()
spark.conf.set("spark.sql.shuffle.partitions", 3)2. 데이터 로드 및 스키마 출력
Shakespeare의 텍스트 파일을 읽어 데이터 프레임으로 로드함. 이 데이터 프레임은 하나의 컬럼(value)만을 가짐.
df = spark.read.text("shakespeare.txt")
df.printSchema()출력되는 스키마는 다음과 같음:
root
|-- value: string (nullable = true)3. 단어 분리 및 카운트
텍스트 데이터를 공백(" ")을 기준으로 분리하여 단어별로 분할하고, 각 단어의 발생 횟수를 세는 데이터 프레임을 생성함.
df_count = df.select(explode(split(df.value, " ")).alias("word")).groupBy("word").count()여기서 explode와 split 함수를 사용하여 문자열을 단어로 분할하고, 각 단어의 발생 횟수를 그룹화하여 계산함.
4. 결과 출력
최종적으로 df_count.show()를 호출하여 각 단어와 그 발생 횟수를 출력함.
df_count.show()내부 동작 분석
Transformations와 Actions
- Transformations:
read.text("shakespeare.txt"): 텍스트 파일을 읽어 데이터 프레임 생성.select(explode(split(df.value, " ")).alias("word")): 공백을 기준으로 텍스트를 분리하여 단어 단위로 변환.groupBy("word").count(): 각 단어를 그룹화하여 발생 횟수를 셈.
이들 Transformation은 Lazy Execution 방식으로 실행 계획에 추가되지만, 즉시 실행되지는 않음.
- Actions:
show(): 실제로 데이터를 실행하고 결과를 출력하는 Action.
Jobs, Stages, Tasks
show() 메서드를 호출함으로써 Spark는 전체 실행 계획을 실행함. 이는 다음과 같은 단계를 포함함:
- Job 생성:
show()메서드 호출로 인해 Job이 생성됨. - Stage 나누기:
- 첫 번째 Stage:
text파일을 읽고, 데이터를split하고explode하여 단어 단위로 변환하는 작업. - 두 번째 Stage: 단어를
groupBy하여 카운트하는 작업. 이 단계에서 셔플링이 발생함.
- 첫 번째 Stage:
각 Stage는 여러 Task로 나뉘어 병렬로 실행됨.
- Tasks: 각 Task는 Executor에 의해 병렬로 실행됨. 첫 번째 Stage는 텍스트 파일의 각 파티션을 처리하고, 두 번째 Stage는 각 파티션의 단어들을 그룹화하여 셔플링된 데이터를 처리함.
최종 결과
결과적으로, 이 코드는 하나의 Job을 생성하며, 두 개의 Stage로 나뉘어 실행됨. 각 Stage는 여러 Task로 병렬로 처리되어 최종적으로 각 단어의 발생 횟수가 계산되고 출력됨. show() 메서드가 없다면, Transformations는 실행되지 않고 지연된 상태로 남게 됨.
이를 통해 Spark의 내부 동작을 이해할 수 있으며, Transformations와 Actions의 구분, Job과 Stage, Task의 관계를 명확히 알 수 있음.
Boradcast
Broadcast Join 코드의 Spark 내부 동작 설명
이 코드는 PySpark를 사용하여 두 개의 데이터 프레임을 브로드캐스트 조인(broadcast join)하는 예제입니다. 브로드캐스트 조인은 작은 데이터 프레임을 클러스터의 모든 워커 노드에 복제하여 조인 작업을 최적화합니다. 이를 통해 셔플링(shuffling) 과정을 피할 수 있어 성능이 향상됩니다.
1. SparkSession 생성
먼저, SparkSession을 생성하여 Spark 애플리케이션을 시작합니다. SparkSession.builder를 사용하여 로컬 모드에서 세 개의 CPU 코어를 사용하는 세션을 생성합니다.
from pyspark.sql import SparkSession
from pyspark.sql.functions import broadcast
spark = SparkSession \
.builder \
.appName("Broadcast Join Demo") \
.master("local[3]") \
.config("spark.sql.shuffle.partitions", 3) \
.config("spark.sql.adaptive.enabled", False) \
.getOrCreate()2. 데이터 로드
두 개의 JSON 파일을 읽어 각각 df_large와 df_small 데이터 프레임을 생성합니다.
df_large = spark.read.json("large_data/")
df_small = spark.read.json("small_data")3. 브로드캐스트 조인
조인 조건(join_expr)을 정의하고, 작은 데이터 프레임(df_small)을 브로드캐스트하여 두 데이터 프레임을 조인합니다.
join_expr = df_large.id == df_small.id
join_df = df_large.join(broadcast(df_small), join_expr, "inner")- broadcast(df_small): 작은 데이터 프레임을 클러스터의 모든 워커 노드에 복제합니다.
- join_expr:
df_large와df_small의id컬럼을 기준으로 내부 조인(inner join)을 수행합니다.
4. 결과 수집 및 출력
조인의 결과를 수집하여 드라이버 프로그램으로 가져옵니다.
join_df.collect()
input("Waiting ...")5. 세션 종료
작업이 완료된 후 Spark 세션을 종료합니다.
spark.stop()내부 동작 분석
Transformations와 Actions
- Transformations:
read.json("large_data/"): JSON 파일을 읽어 데이터 프레임 생성.read.json("small_data"): JSON 파일을 읽어 데이터 프레임 생성.df_large.join(broadcast(df_small), join_expr, "inner"): 브로드캐스트 조인을 수행하여 데이터 프레임 결합.
이들 Transformation은 Lazy Execution 방식으로 실행 계획에 추가되지만, 즉시 실행되지는 않음.
- Actions:
collect(): 모든 데이터를 드라이버로 수집하는 Action. 이로 인해 Job이 실행됨.
Jobs, Stages, Tasks
collect() 메서드를 호출함으로써 Spark는 전체 실행 계획을 실행합니다. 이는 다음과 같은 단계를 포함합니다:
- Job 생성:
collect()메서드 호출로 인해 Job이 생성됩니다. - Stage 나누기:
- 첫 번째 Stage:
df_large와df_small데이터 프레임을 읽어오는 작업. - 두 번째 Stage: 브로드캐스트 조인을 수행하는 작업. 작은 데이터 프레임(
df_small)이 모든 노드에 브로드캐스트되어 셔플링 없이 조인이 수행됩니다.
- 첫 번째 Stage:
각 Stage는 여러 Task로 나뉘어 병렬로 실행됩니다.
- Tasks: 각 Task는 Executor에 의해 병렬로 실행됩니다. 첫 번째 Stage는 JSON 파일의 각 파티션을 처리하고, 두 번째 Stage는 브로드캐스트된 데이터를 사용하여 조인 작업을 수행합니다.
=
해야할 것
해당 코드를 spark web ui에서 확인해보기
Bucketing과 Partitioning
1. Bucketing과 Partitioning이 필요한 이유
-
데이터 접근 및 검색 속도 향상:
- Partitioning은 데이터를 특정 컬럼 값을 기준으로 물리적으로 분할하여 저장함으로써 필요하지 않은 데이터를 읽는 시간을 줄임. 예를 들어, 날짜 컬럼을 기준으로 파티셔닝하면 특정 날짜의 데이터를 조회할 때 해당 파티션만 읽으면 되므로 속도가 빨라짐.
- Bucketing은 데이터를 지정된 수의 버킷으로 나누어 저장함으로써 조인이나 집계 연산 시 동일한 버킷에 있는 데이터를 빠르게 찾을 수 있음. 해시 함수로 계산된 버킷 번호를 기준으로 데이터를 나누어 저장함.
-
리소스 사용 최적화:
- Partitioning은 읽어야 할 데이터 양을 줄여 I/O 작업을 최소화함으로써 메모리와 CPU 사용을 최적화함. 데이터가 고르게 분포된 경우 효과가 큼.
- Bucketing은 버킷 단위로 작업을 분산하여 실행할 수 있어 병렬 처리 효율을 높임. 특히, 조인 작업에서 두 테이블을 동일한 컬럼 기준으로 버킷화하면 셔플링(shuffling)을 줄일 수 있음.
-
조인 성능 향상:
- Partitioning은 파티션 키가 조인 조건에 포함되면 파티션 프루닝(partition pruning)을 통해 조인에 필요한 데이터만 읽어옴으로써 성능을 향상시킴.
- Bucketing은 동일한 컬럼을 기준으로 버킷화된 두 테이블을 조인할 때 각 버킷 내에서 조인이 수행되므로 셔플 오버헤드를 줄일 수 있음.
2. Bucketing과 Partitioning의 사용 사례
-
Partitioning 사용 사례:
- 날짜 기반 로그 데이터는 로그 데이터를 날짜별로 파티셔닝하여 특정 날짜의 로그를 빠르게 조회할 수 있음.
- 지역 기반 데이터는 국가나 지역 코드를 기준으로 파티셔닝하여 특정 지역의 데이터를 빠르게 처리할 수 있음.
- 분기별 보고서 데이터는 금융 데이터를 분기별로 파티셔닝하여 특정 분기의 보고서를 빠르게 생성할 수 있음.
-
Bucketing 사용 사례:
- 대규모 데이터 조인은 두 개 이상의 큰 테이블을 조인할 때 조인 키를 기준으로 버킷화하여 셔플링을 최소화하고 성능을 향상시킬 수 있음.
- 고빈도 조회 컬럼은 특정 컬럼의 값이 자주 조회되거나 집계되는 경우 해당 컬럼을 기준으로 버킷화하여 검색 및 집계 성능을 향상시킬 수 있음.
- 데이터 스큐 해결은 데이터가 특정 값에 치우쳐 있는 경우 버킷화를 통해 데이터 분포를 고르게 하여 병렬 처리 효율을 높일 수 있음.
코드 예제
전체 코드
# -*- coding: utf-8 -*-
from pyspark.sql import SparkSession
# Redshift JDBC 드라이버 다운로드
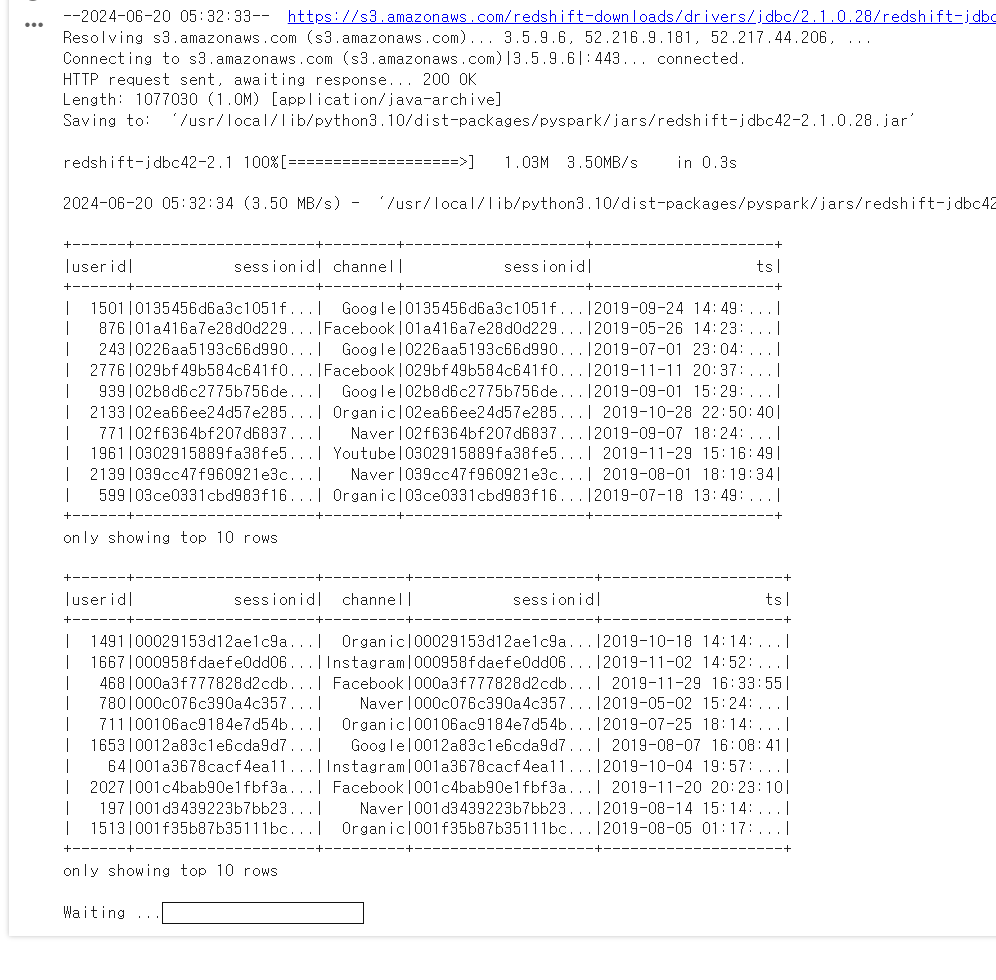
!wget https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/2.1.0.28/redshift-jdbc42-2.1.0.28.jar -P /usr/local/lib/python3.10/dist-packages/pyspark/jars/
# SparkSession 생성
spark = SparkSession.builder \
.appName("Python Spark SQL 저장하기") \
.config("spark.sql.autoBroadcastJoinThreshold", -1) \
.config("spark.sql.adaptive.enabled", False) \
.config("spark.jars", "/usr/local/lib/python3.10/dist-packages/pyspark/jars/redshift-jdbc42-2.1.0.28.jar") \
.enableHiveSupport() \
.getOrCreate()
# Redshift와 연결해서 DataFrame으로 로딩함
url = "jdbc:redshift://learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev?user=guest&password=Guest1234"
df_user_session_channel = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.user_session_channel") \
.load()
df_session_timestamp = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.session_timestamp") \
.load()
# 데이터 조인 및 출력함
join_expr = df_user_session_channel.sessionid == df_session_timestamp.sessionid
df_join = df_user_session_channel.join(df_session_timestamp, join_expr, "inner")
df_join.show(10)
# 기존 테이블 삭제 및 버킷화된 테이블 저장함
spark.sql("DROP TABLE IF EXISTS bk_usc")
spark.sql("DROP TABLE IF EXISTS bk_st")
df_user_session_channel.write.mode("overwrite").bucketBy(3, "sessionid").saveAsTable("bk_usc")
df_session_timestamp.write.mode("overwrite").bucketBy(3, "sessionid").saveAsTable("bk_st")
# 버킷화된 테이블 로드 및 조인함
df_bk_usc = spark.read.table("bk_usc")
df_bk_st = spark.read.table("bk_st")
join_expr2 = df_bk_usc.sessionid == df_bk_st.sessionid
df_join2 = df_bk_usc.join(df_bk_st, join_expr2, "inner")
df_join2.show(10)
input("Waiting ...")코드 설명
-
Redshift JDBC 드라이버 다운로드:
- 최신 버전의 Redshift JDBC 드라이버를 다운로드하여 지정된 디렉토리에 저장함.
!wget https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/2.1.0.28/redshift-jdbc42-2.1.0.28.jar -P /usr/local/lib/python3.10/dist-packages/pyspark/jars/ -
SparkSession 생성:
- SparkSession을 생성할 때, 다운로드한 Redshift JDBC 드라이버를 포함시키도록 설정함.
spark = SparkSession.builder \ .appName("Python Spark SQL 저장하기") \ .config("spark.sql.autoBroadcastJoinThreshold", -1) \ .config("spark.sql.adaptive.enabled", False) \ .config("spark.jars", "/usr/local/lib/python3.10/dist-packages/pyspark/jars/redshift-jdbc42-2.1.0.28.jar") \ .enableHiveSupport() \ .getOrCreate() -
Redshift와 연결해서 DataFrame으로 로딩:
- Redshift에서 데이터 로드하여 DataFrame으로 변환함.
url = "jdbc:redshift://learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev?user=guest&password=Guest1234" df_user_session_channel = spark.read \ .format("jdbc") \ .option("driver", "com.amazon.redshift.jdbc42.Driver") \ .option("url", url) \ .option("dbtable", "raw_data.user_session_channel") \ .load() df_session_timestamp = spark.read \ .format("jdbc") \ .option("driver", "com.amazon.redshift.jdbc42.Driver") \ .option("url", url) \ .option("dbtable", "raw_data.session_timestamp") \ .load() -
데이터 조인 및 출력:
- 두 DataFrame을 조인하고 결과를 출력함.
join_expr = df_user_session_channel.sessionid == df_session_timestamp.sessionid df_join = df_user_session_channel.join(df_session_timestamp, join_expr, "inner") df_join.show(10) -
기존 테이블 삭제 및 버킷화된 테이블 저장:
- 기존 테이블을 삭제하고, 버킷화된 테이블로 데이터를 저장함.
spark.sql("DROP TABLE IF EXISTS bk_usc") spark.sql("DROP TABLE IF EXISTS bk_st") df_user_session_channel.write.mode("overwrite").bucketBy(3, "sessionid").saveAsTable("bk_usc") df_session_timestamp.write.mode("overwrite").bucketBy(3, "sessionid").saveAsTable("bk_st") -
버킷화된 테이블 로드 및 조인:
- 버킷화된 테이블을 로드하고 다시 조인한 후 결과를 출력함.
df_bk_usc = spark.read.table("bk_usc") df_bk_st = spark.read.table("bk_st") join_expr2 = df_bk_usc.sessionid == df_bk_st.sessionid df_join2 = df_bk_usc.join(df_bk_st, join_expr2, "inner") df_join2.show(10) -
종료 대기:
- 프로그램이 종료되지 않도록 대기함.
input("Waiting ...")
Partitioning 코드 설명
1. SparkSession 생성
SparkSession을 생성하여 Spark 애플리케이션을 시작함.
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Spark FS Partition Demo") \
.master("local[3]") \
.enableHiveSupport() \
.getOrCreate()2. 데이터 다운로드 및 로드
CSV 파일을 다운로드하고, 이를 DataFrame으로 로드함.
!wget https://pyspark-test-sj.s3.us-west-2.amazonaws.com/appl_stock.csv
df = spark.read.csv("appl_stock.csv", header=True, inferSchema=True)
df.printSchema()
df.show(10)3. 추가 컬럼 생성
데이터 프레임에 연도(year)와 월(month) 컬럼을 추가함.
df = df.withColumn("year", year(df.Date)) \
.withColumn("month", month(df.Date))4. 기존 테이블 삭제 및 파티셔닝된 테이블 저장
기존 테이블이 존재할 경우 삭제하고, year와 month 컬럼을 기준으로 파티셔닝하여 새로운 테이블로 저장함.
spark.sql("DROP TABLE IF EXISTS appl_stock")
df.write.partitionBy("year", "month").saveAsTable("appl_stock")5. 파티셔닝된 데이터 확인
파티셔닝된 데이터 구조를 확인하고, 특정 파티션의 데이터를 읽어옴.
df = spark.read.table("appl_stock").where("year = 2016 and month = 12")
df.show(10)
spark.sql("SELECT * FROM appl_stock WHERE year = 2016 and month = 12").show(10)
결과 분석
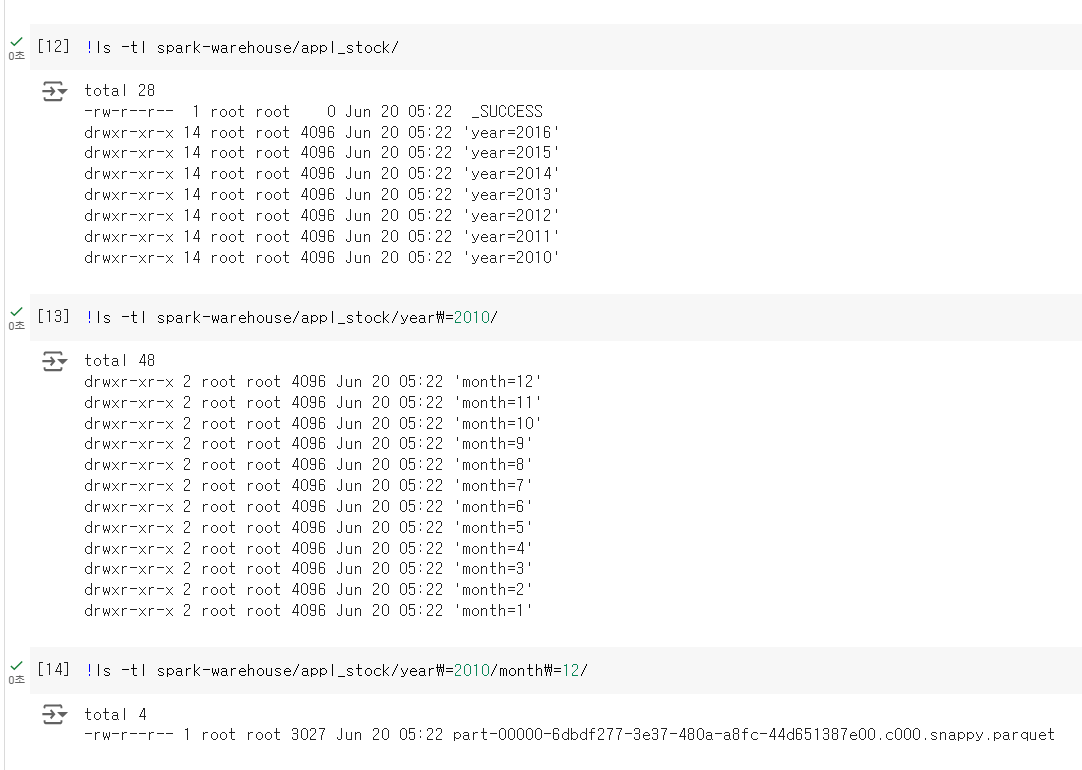
디렉토리 구조 및 내용
이미지에 나타난 디렉토리 구조는 파티셔닝된 데이터의 저장 구조를 보여줍니다. 각 명령어와 그 출력 결과를 분석하면 다음과 같습니다.
-
ls -tl spark-warehouse/total 4 drwxr-xr-x 9 root root 4096 Jun 20 05:22 appl_stock- 분석:
spark-warehouse디렉토리 내에appl_stock이라는 디렉토리가 생성되었음을 알 수 있음. 이는 파티셔닝된 테이블이 저장된 위치임.
- 분석:
-
ls -tl spark-warehouse/appl_stock/total 28 -rw-r--r-- 1 root root 0 Jun 20 05:22 _SUCCESS drwxr-xr-x 14 root root 4096 Jun 20 05:22 'year=2016' drwxr-xr-x 14 root root 4096 Jun 20 05:22 'year=2015' drwxr-xr-x 14 root root 4096 Jun 20 05:22 'year=2014' drwxr-xr-x 14 root root 4096 Jun 20 05:22 'year=2013' drwxr-xr-x 14 root root 4096 Jun 20 05:22 'year=2012' drwxr-xr-x 14 root root 4096 Jun 20 05:22 'year=2011' drwxr-xr-x 14 root root 4096 Jun 20 05:22 'year=2010'- 분석:
appl_stock디렉토리 내에는year컬럼을 기준으로 파티셔닝된 여러 디렉토리가 생성되었음. 각 디렉토리는 해당 연도의 데이터를 포함함._SUCCESS파일은 작업이 성공적으로 완료되었음을 나타냄.
- 분석:
-
ls -tl spark-warehouse/appl_stock/year=2010/total 48 drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=12' drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=11' drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=10' drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=9' drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=8' drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=7' drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=6' drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=5' drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=4' drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=3' drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=2' drwxr-xr-x 2 root root 4096 Jun 20 05:22 'month=1'- 분석:
year=2010디렉토리 내에는month컬럼을 기준으로 다시 파티셔닝된 디렉토리들이 생성되었음. 각 디렉토리는 해당 연도의 해당 월 데이터를 포함함.
- 분석:
-
ls -tl spark-warehouse/appl_stock/year=2010/month=12/total 4 -rw-r--r-- 1 root root 3027 Jun 20 05:22 part-00000-6dbdf277-3e37-480a-a8fc-44d651387e00.c000.snappy.parquet- 분석:
year=2010/month=12디렉토리 내에는 파케이(Parquet) 파일이 저장되어 있음. 이 파일은 해당 연도와 월의 데이터를 포함하는 파케이 파일임.
- 분석:
파티셔닝 결론
이 분석을 통해 다음과 같은 사항을 알 수 있음:
-
파티셔닝 구조:
appl_stock테이블은year와month컬럼을 기준으로 파티셔닝되었음. 이는 데이터를 연도와 월 단위로 나누어 저장하는 것으로, 특정 연도나 월의 데이터를 빠르게 검색할 수 있도록 최적화됨. -
디렉토리 계층:
appl_stock디렉토리 하위에year디렉토리가 생성되고, 그 하위에month디렉토리가 생성됨. 이러한 계층 구조는 파티셔닝된 데이터를 효율적으로 관리하고 접근할 수 있도록 돕는 역할을 함. -
파일 저장 방식: 각 최종 디렉토리(
year와month로 파티셔닝된 디렉토리) 내에는 파케이 파일 형식으로 데이터가 저장되어 있음. 파케이 파일 형식은 컬럼 저장 방식으로, 데이터 분석 작업에서 효율적인 입출력을 제공함.
이러한 파티셔닝 구조를 사용하면 대규모 데이터를 보다 효율적으로 저장하고 접근할 수 있으며, 쿼리 성능을 향상시킬 수 있음.
결론
Bucketing
- 왜 필요한지: 데이터 조인 시 셔플링을 최소화하여 성능을 최적화하기 위함. 특히, 조인 키를 기준으로 데이터 분할하여 병렬 처리 성능을 향상시킴.
- 어디에 사용하는지: 대규모 데이터 조인, 고빈도 조회 컬럼, 데이터 스큐 해결 등에 사용됨.
Partitioning
- 왜 필요한지: 데이터를 특정 기준으로 물리적으로 분할하여 검색 성능을 향상시키고, I/O 작업을 줄여 리소스를 최적화하기 위함.
- 어디에 사용하는지: 날짜 기반 로그 데이터, 지역 기반 데이터, 분기별 보고서 데이터 등 특정 조건의 데이터를 빠르게 조회할 때 사용됨.
이 두 가지 기법을 적절히 활용하면 대규모 데이터 처리 성능을 크게 향상시킬 수 있음.
