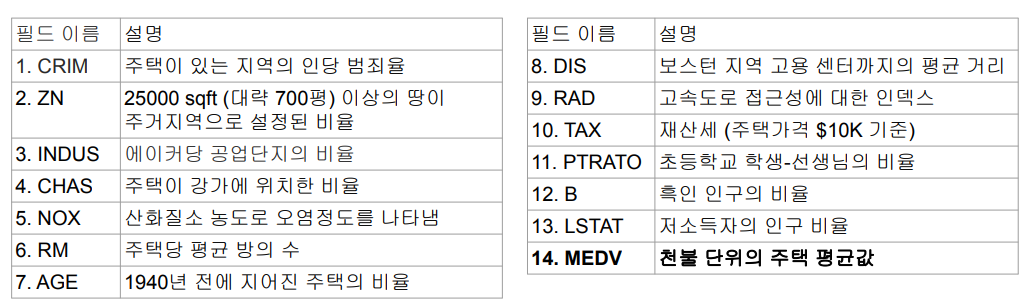
Spark ML
Spark ML - 이론
Spark ML - 소개
- 머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리
- Classification
- Regression
- Clusetering
- Collaborative Filtering
- Dimensionality Reduction
- 아직 딥러닝은 지원이 미약함(위 사항은 다 머신러닝)
- 여기에는 RDD 기반과 dataframe 기반의 두 버전이 존재.
Spark.mllib가 RDD 기반이고,spark.ml은 데이터 프레임 기반.spark.mllib는 RDD 위에서 동작하는 이전 라이브러리로 더이상 업데이트가 안됨.
- 항상
spark.ml을 사용할 것.import pyspark.ml
spark ML - 장점
- 원스톱 ML 프레임워크
- 데이터프레임과 SparkSQL 등을 이용해 전처리
- Spark MLlib를 이용해 모델 빌딩
- ML Pipeline을 통해 모델 빌딩 자동화
- MLFlow로 모델 관리하고 서빙
- 대용량 데이터도 처리 가능
Spark ML - MLflow
-
모델의 관리와 서빙을 위한 Ops 관련 기능 제공
-
MLflow
- 모델 개발과 테스트와 관리와 서빙까지 제공해주는 end to end 프레임워크
- MLflow는 파이썬,자바,R,API를 지원
- MLflow는 트래킹(Tracking),모델(Models),프로젝트(Projects)를 지원
서빙이 뭘까?
- Serving은 머신러닝 모델을 실질적인 환경에서 사용할 수 있도록 배포하고 운영하는 과정을 의미함.
- Serving의 주요 역할은 아래와 같음
Spark ML - 실습
보스턴 주택 가격 예측
https://velog.io/@papalio/big-data-spark-hadoop-5
타이타닉 생존 여부 예측
https://velog.io/@papalio/big-data-spark-hadoop-5
Spark ML 피쳐 변환
피쳐 추출과 변환
- 피쳐 값들을 모델 훈련에 적합한 형태로 바꾸는 것을 지칭
- 크게 2가지가 존재
- Feature Extractor
- Feature Transformer
Feature Transformer
- 먼저 피쳐 값들은 숫자 필드여야함
- 텍스트 필드(카테고리 값들)를 숫자 필드로 변환해야 함.
- 숫자 필드 값의 범위 표준화
- 숫자 필드라해도 가능한 값의 범위를 특정 범위로 변환 해야함. 이를 피쳐 스케일링 혹은 정규화라고 함.
Feature Extractor
- 기존 feature에서 새로운 feature를 추출.
Spark ML - Pipeline
모델 빌딩과 관련된 문제들
- 트레이닝 셋 관리가 안됨
- 모델 훈련 방법이 기록이 안됨
- 어떤 트레이닝 셋을 사용했나..
- 어떤 피쳐 썼나..
- 하이퍼 파라미터는 뭘 썼나..
- 모델 훈련에 많은 시간 소요
- 모델 훈련이 자동화가 안된 경우 매번 각 스텝들을 노트북 등에서 일일히 수행
- 에러가 발생할 여지가 많음(특정 스텝을 까먹거나 조금 다른 방식 적용)
ML Pipeline
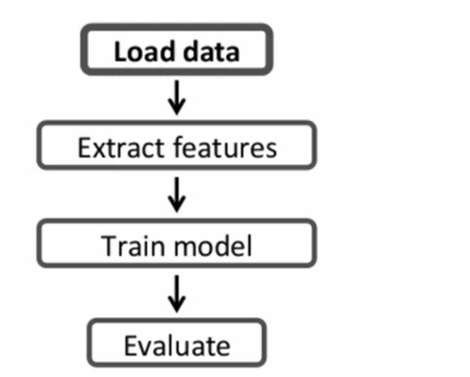
- 앞서 언급된 문제들 중 모델 훈련 방법, 모델 훈련 시간 소요를 해결함.
- 자동화를 통해 에러 소지를 줄이고, 반복을 빠르게 가능하게 해줌.
Spark ML - 관련 개념 정리
- ML 파이프라인이란?
- 데이터 과학자가 머신러닝 개발과 테스트를 쉽게 해주는 기능(데이터 프레임 기반)
- 머신러닝 알고리즘에 관계없이 일관된 형태의 API를 사용하여 모델링이 가능
- ML 모델개발과 테스트를 반복하게 해줌
- 4개의 요소로 구성
- 데이터 프레임
- 기본 데이터 포맷
- CSV JSON Parquet JDBC 지원
- ML 파이프라인은 2개 데이터 소스 지원
- 이미지 데이터 소스
- LIBSVM 데이터소스
- label과 features 두 개의 컬럼으로 구성되는 머신러닝 트레이닝셋 포맷
- feature 컬럼은 벡터 형태의 구조를 가짐
- Transformer
- 입력 데이터프레임을 다른 데이터프레임으로 변환
- 2종류의 transformer가 존재하며 transform이 메인 함수
feature Transformer와Learning Model
- feature Transformer
- 입력 데이터 프레임의 컬럼으로부터 새로운 컬럼을 만들어내 이를 추가한 새로운 데이터프레임을 출력으로 내줌.
- 예시로 imputer,StringIndexer,vectorAssembler 등이 있음.
- Learning Model
- 머신러닝 모델에 해당
- 피쳐 데이터프레임을 입력으로 받아 예측값이 새로운 컬럼으로 포함된 데이터프레임을 출력으로 내줌(prediction,probability)
- Estimator
- fit이 메인 함수
- 머신러닝 빌딩 과정을 의미.
- 예를 들어 Logisticregression은 Estimator이고,
logisticRegression.fit()을 호출하면 머신 러닝 모델(Transformer)을 만들어냄 - 입력 : 데이터 프레임
- 출력 : 머신러닝 모델
- fit이 메인 함수
- Parameter
- 두 종류의 파라미터가 존재
- Param(하나의 이름과 값)
- ParamMap (Param 리스트)
- 파라미터 예)
- 훈련 반복수 지정을 위해 setMaxlter()를 사용
- ParamMap(lr.maxlter -> 10)
- 파라미터는 fit 혹은 transform 인자로 지정 가능
- 두 종류의 파라미터가 존재
- 데이터 프레임

개인공부용(업데이트 중단)