1. 개괄
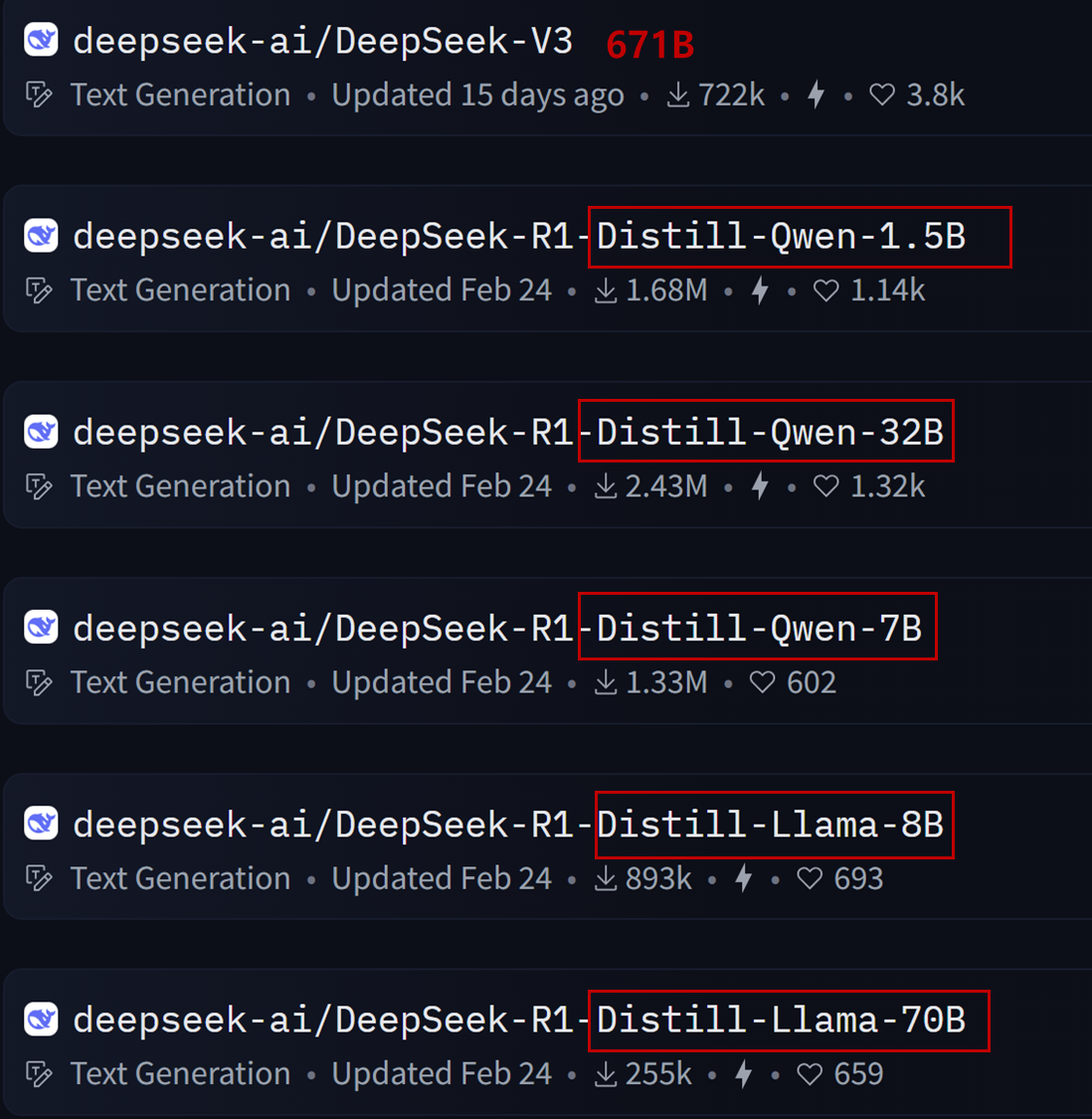
2025년 초 공개된 DeepSeek 모델에서 가장 주목할 만한 점은 첫째, R1이라는 고성능 추론 모델의 소스가 공개되었다는 점과 둘째, 671B 규모의 모델을 distillation 기법을 통해 효과적으로 경량화했다는 점이었습니다. 특히 LLM 시장의 경쟁이 치열해지는 상황에서 모델 경량화는 중요한 돌파구가 될 수 있다는 판단 아래, 이번 글에서는 Knowledge Distillation 개념을 다시 정리해보고자 합니다.
2 KD의 시작
Knowledge Distillation은 Geoffrey Hinton이 2014년 NIPS Deep Learning Workshop에서 제안한 개념으로, 복잡하고 큰 모델(또는 앙상블)의 지식을 더 작고 경량화된 모델로 전이시키기 위한 학습 방법입니다. 복잡한 모델이 훈련된 이후에는, 해당 모델이 가진 예측 능력을 활용하여 더 작고 배포에 적합한 모델이 그 지식을 모방하도록 학습시킬 수 있으며, 이를 통해 성능을 유지하면서도 연산 비용을 줄이는 효과를 얻을 수 있습니다.

복잡한 모델이 훈련된 후에는, 우리는 '지식 증류(distillation)'라고 부르는 다른 종류의 훈련을 사용하여, 그 복잡한 모델로부터 더 배포에 적합한 작은 모델로 지식을 전달할 수 있습니다.
2.1 KD의 이유
- 복잡하고 성능 좋은 모델은 추론 속도가 느리고 배포에 부적합
- 작은 모델은 추론이 빠르고 가볍지만 성능이 부족함
- KD는 성능과 효율성 간 트레이드오프를 해결하기 위한 전략으로 등장
2.2 예시
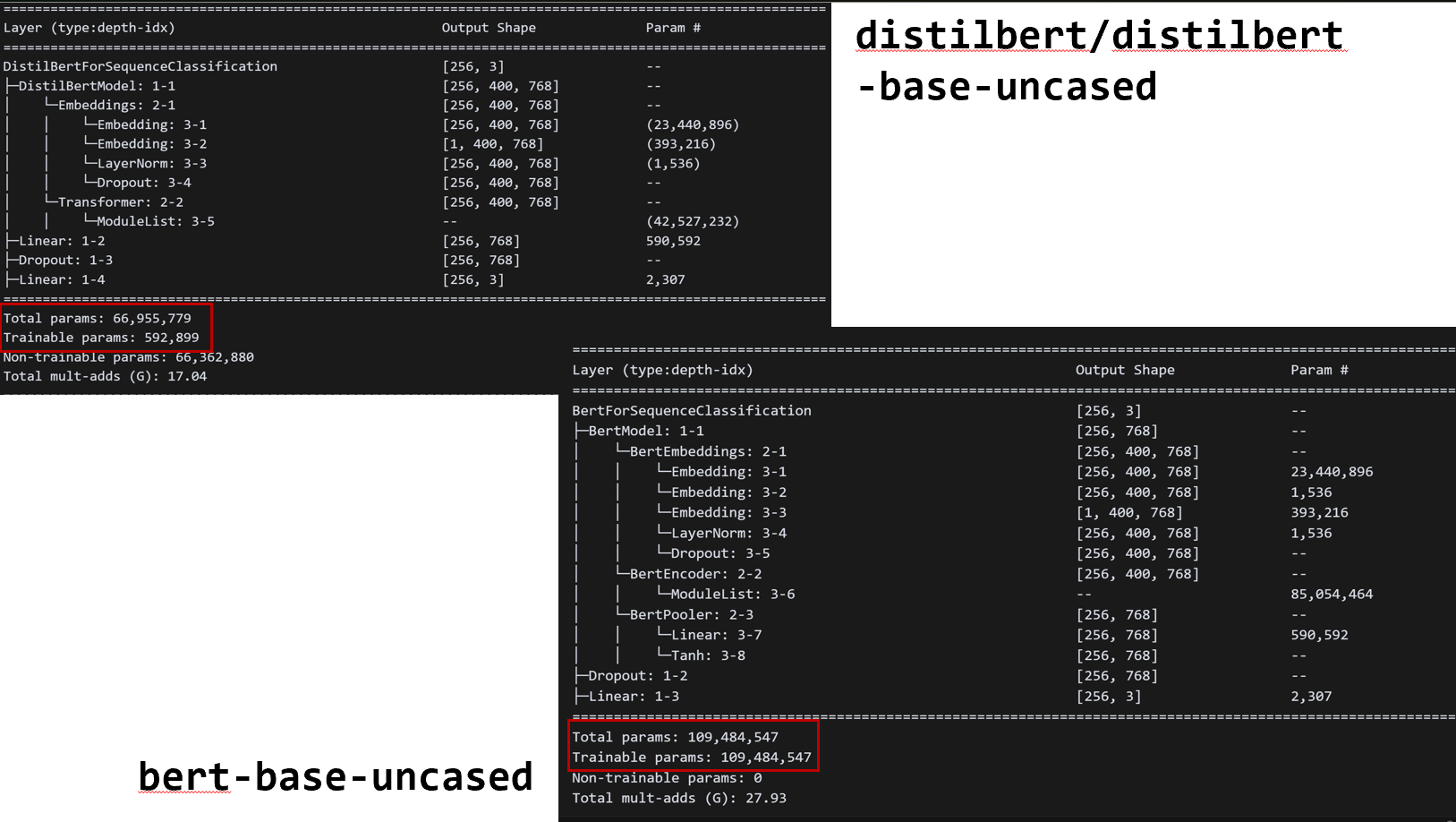
bert-base-uncased→distilbert-base-uncased
bert-base-uncased 모델은 총 약 1억 948만 개(109M) 의 학습 가능한 파라미터를 갖고 있는 반면, 이를 Knowledge Distillation을 통해 경량화한 distilbert-base-uncased 모델은 약 66.9M개의 전체 파라미터 중 오직 약 59만 개(0.59M) 만을 학습 대상으로 두고 있습니다. 이는 distillation을 통해 모델 성능은 유지하면서도 모델 크기와 학습 비용을 획기적으로 줄이는 데 성공했음을 보여줍니다.
3. 초기 이론
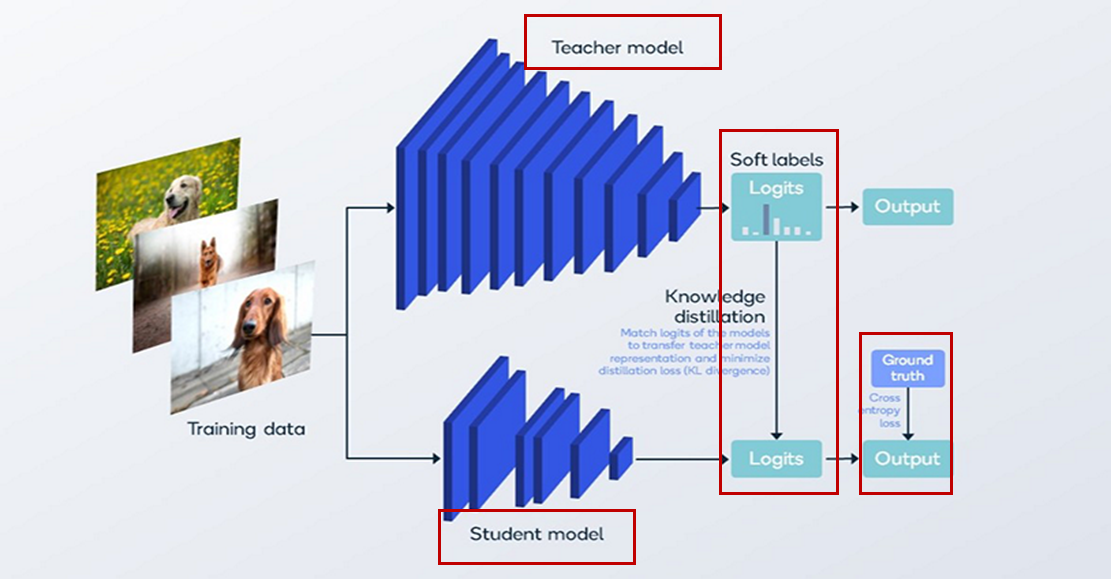
Knowledge Distillation에서는 성능이 뛰어난 Teacher 모델과 경량화된 Student 모델을 함께 사용합니다. Teacher 모델은 복잡하고 연산량이 많은 구조를 갖지만 높은 정확도를 보이는 반면, Student 모델은 연산 자원이 적게 드는 대신 성능이 상대적으로 낮습니다. 이때, Student 모델이 Teacher의 지식을 최대한 학습할 수 있도록 돕기 위해, 단순히 정답 레이블(ground truth)만 사용하는 것이 아니라 Teacher의 출력 분포(soft target)를 함께 학습에 사용합니다.
이 과정에서 사용되는 손실 함수는 두 가지로 구성됩니다. 첫 번째는 KL Divergence(Kullback-Leibler Divergence) 로, Teacher 모델과 Student 모델의 soft output 간의 차이를 줄이는 방향으로 학습을 유도합니다. 두 번째는 일반적인 Cross Entropy Loss로, 실제 ground truth와 Student 모델의 예측 간 차이를 줄이는 데 사용됩니다. 최종 손실은 이 두 손실의 가중합(weighted sum) 으로 정의되며, 이를 통해 Student 모델은 Teacher의 지식(출력 분포)을 모방하면서도 실제 정답과도 가까운 출력을 낼 수 있도록 훈련됩니다.

3.1 Temperature가 학습에 사용됨
우리의 일반화된 접근법(distillation)은 최종 softmax에 temperature를 올려서, 모델이 적절히 부드러운 확률 분포를 생성하도록 하는 것이다.”

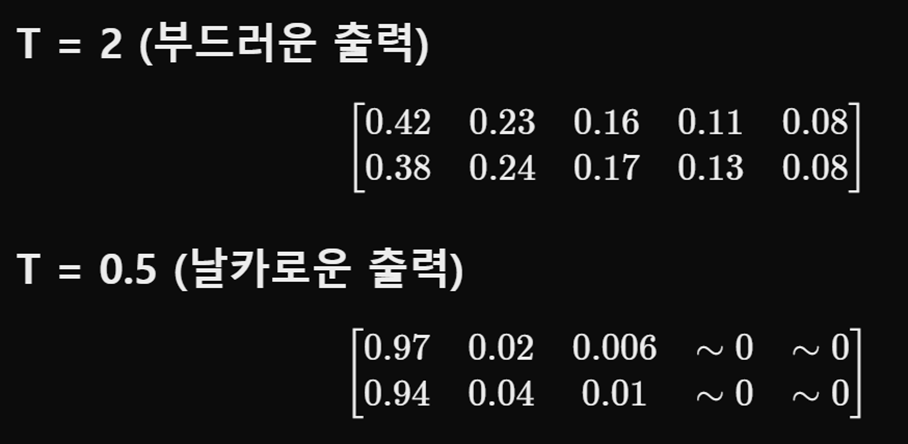
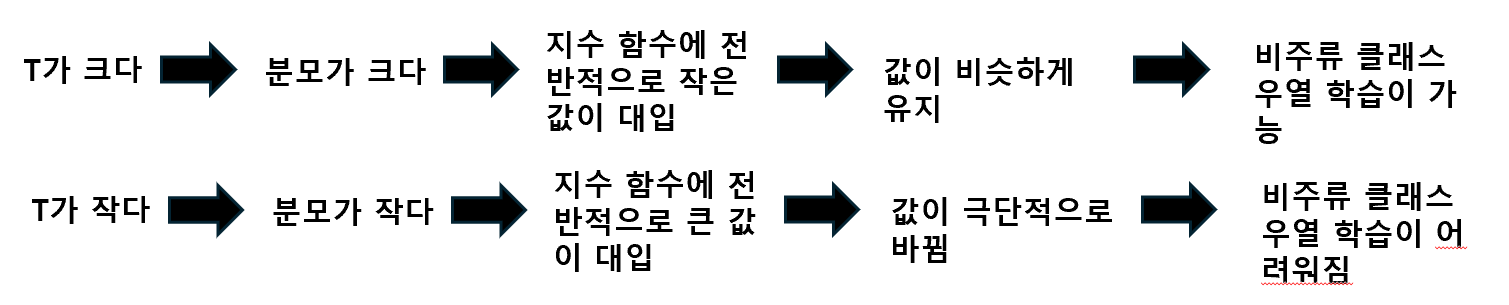
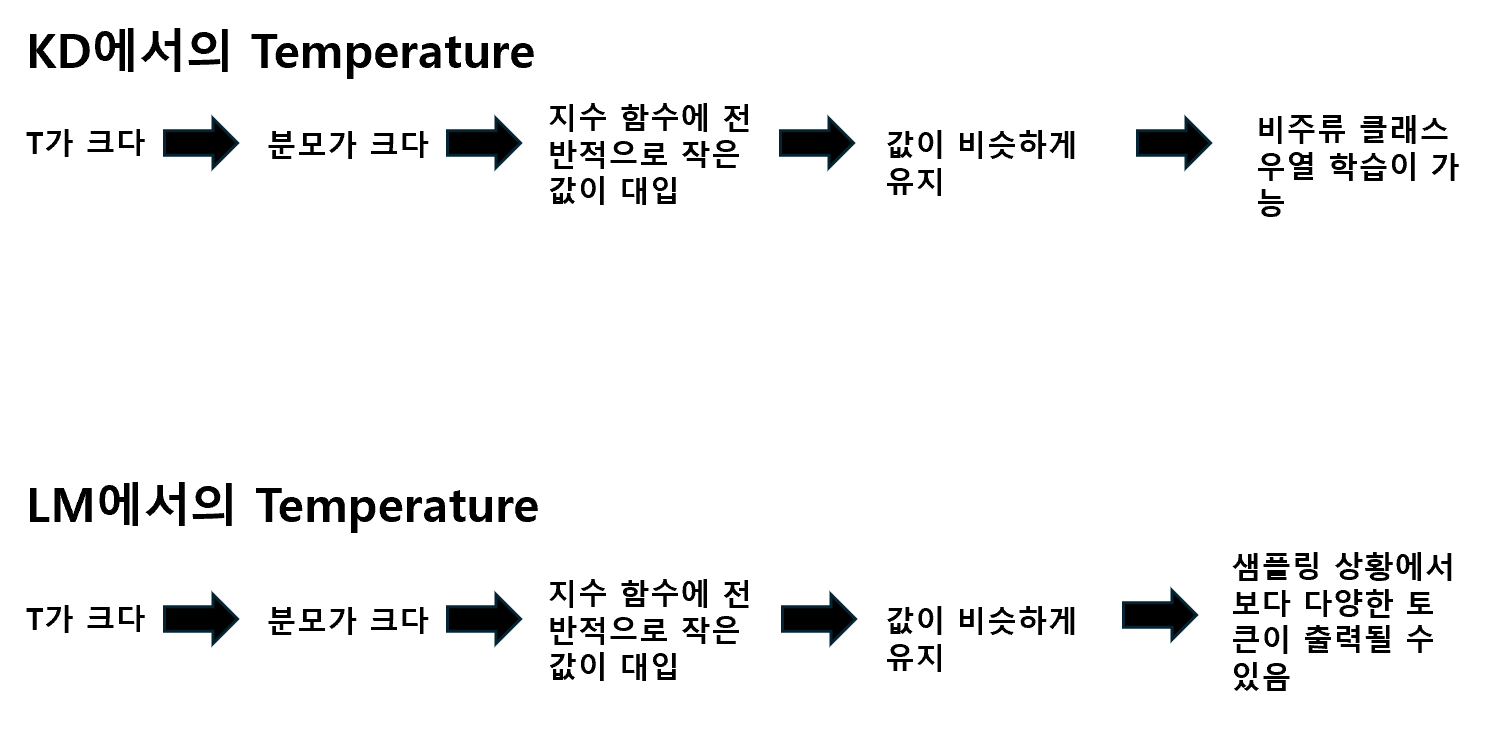
Knowledge Distillation에서 Softmax의 Temperature(T) 는 모델의 출력 확률 분포를 조절하는 중요한 하이퍼파라미터입니다. Temperature가 낮을수록 출력 분포는 날카로워져 정답 클래스의 확률만 높고 나머지는 거의 0에 가깝게 됩니다. 반대로 Temperature가 높아지면 확률 분포가 부드러워져, 여러 클래스에 대한 상대적인 확률이 좀 더 고르게 분포됩니다. 이로 인해 비주류 클래스에 대해서도 일정 수준의 확률이 분배되어 표현됩니다.
이러한 부드러운 확률 분포(Soft Target) 는 Knowledge Distillation에서 중요한 역할을 합니다. Teacher 모델이 정답 외의 다른 클래스에 부여한 확률은 그 클래스들이 얼마나 헷갈리는지를 의미합니다. Student 모델은 이 정보를 통해 단순히 정답만을 예측하는 것이 아니라, 비주류 클래스 간의 미묘한 관계도 함께 학습하게 됩니다. 따라서 높은 Temperature 설정은 더 풍부한 클래스 간 상호작용 정보를 전달해 Student 모델의 일반화 성능을 높이는 데 도움을 줍니다.
3.2 정리
| 구분 | 목적 |
|---|---|
| KD에서의 역할 | Soft target 분포 평탄화로 미세한 차이 학습 |
| LLM에서의 역할 | 다양한 출력 유도(top-k, sampling 등) |
T ↑: 확률 분포가 평탄해져 다양한 클래스 고려 가능T ↓: 높은 확률만 선택 → 결정적 결과
4. 언어모델에서의 Temperature
언어모델(Language Model, LM)에서 Temperature는 주로 추론 시점에서 사용되며, 모델이 생성할 확률 분포의 다양성을 조절하는 역할을 합니다. Temperature 값을 높이면 Softmax 함수의 분모가 커지면서 출력 확률 분포가 더 평탄해지고(부드러워짐), 여러 토큰에 대한 확률이 고르게 분포하게 됩니다. 이로 인해 특정 상위 토큰들에 확률이 몰리지 않고, 더 다양한 단어들이 선택될 수 있는 가능성이 생기게 됩니다.
이는 특히 Top-p 샘플링이나 Top-k 샘플링 기법과 함께 사용될 때 그 효과가 두드러집니다. Temperature가 높은 경우, 샘플링 과정에서 확률이 낮은 토큰들도 선택될 여지가 커지며, 결과적으로 더 창의적이고 다양한 문장 생성이 가능해집니다. 이는 Knowledge Distillation 초기 방식에서 학습 중 Temperature를 활용했던 것과 대조적으로, 언어모델에서는 학습이 아니라 추론에서 확률 분포를 조절하는 용도로 Temperature를 사용한다는 점에서 구분됩니다.
5. 언어모델에서의 Distillation
DeepSeek-R1과 같은 추론 능력을 더 작은 모델에 부여하기 위해, 우리는 DeepSeek-R1이 생성한 80만 개의 샘플을 활용하여 Qwen 및 Llama와 같은 오픈소스 모델들을 직접 SFT(fine-tuning)했다...”

DeepSeek-R1에서는 사전 학습이 완료된 대형 모델을 Teacher로, 상대적으로 경량화된 모델을 Student로 사용하여 Knowledge Distillation을 수행합니다. 이때 Teacher 모델은 입력에 대해 고유의 응답을 생성하고, 이 응답을 Student 모델이 학습할 pseudo-label로 간주합니다. Ground truth가 아닌 Teacher의 출력을 정답으로 사용하는 방식으로, Student는 정답뿐 아니라 Teacher가 예측한 확률 분포까지도 모방함으로써 더 정교한 패턴을 학습할 수 있습니다.
이러한 distillation 과정은 일반적인 지도학습과 달리, 라벨 없이도 고성능 모델로부터 학습할 수 있는 구조를 제공합니다. 특히 DeepSeek-R1에서는 Hugging Face의 SFTTrainer와 같은 도구를 이용하여 학습을 단순화하였고, LLaMA 또는 Qwen 기반의 Student 모델을 빠르게 수렴시켰습니다. 이 방식은 LLM 개발에서 최근 널리 사용되는 현대적인 지식 증류 전략의 대표적인 예로 볼 수 있습니다.

6. 현재의 KD 예시
최근의 Knowledge Distillation(KD)은 단순히 교사 모델의 확률 분포를 모방하는 전통적 방식에서 확장되어, GPT와 같은 대형 LLM의 응답을 정답 데이터로 간주하여 소형 모델을 파인튜닝하는 방식으로 활용되고 있습니다. 예를 들어, 특정 도메인의 query를 준비한 뒤 이를 GPT API에 입력해 얻은 응답을 정답처럼 사용하고, LLaMA와 같은 경량화된 오픈소스 모델(Student)을 SFT 방식으로 학습시키는 구조는 명백히 대형 모델의 지식을 소형 모델로 전이하는 현대적 KD의 형태라 할 수 있습니다.
DeepSeek 프로젝트는 이 개념을 대규모로 실현한 대표적인 사례입니다. 거대한 DeepSeek-R1 모델이 Teacher 역할을 하며, 이 모델의 응답을 수십억 파라미터 수준의 다양한 Student 모델(예: 1.5B, 7B 등)에 전달하여 훈련합니다. 이는 단순한 출력 복사 이상의 의미를 가지며, 실제 reasoning 능력이나 도메인 지식을 대형 모델로부터 효율적으로 압축·이식할 수 있다는 점에서, 현대 LLM 개발에서 매우 중요한 기술적 흐름으로 평가받고 있습니다.
7. 결론
Knowledge Distillation(KD)은 초기에 특수한 손실 함수와 Temperature 개념을 도입한 점에서 차별화되었습니다. 특히 KL Divergence와 Cross Entropy의 가중합 형태로 손실을 구성하여, student 모델이 정답뿐 아니라 teacher 모델의 확률 분포까지 학습하게 하였습니다. 이때 Temperature는 Softmax를 평탄화시켜 비주류 클래스 간의 미세한 확률 차이를 student가 학습하도록 유도하는 핵심 요소였습니다.
반면, 현재의 KD는 대형 LLM(GPT 등)의 추론 결과 자체를 정답으로 간주하고, 소형 오픈소스 모델을 SFT 방식으로 학습시키는 구조로 진화했습니다. 이처럼 SFT 자체가 지식 증류의 역할을 대체하는 현대적 접근 방식에서는 Temperature가 추론 시점에 활용되며, 확률 분포를 부드럽게 만들어 Top-k, Top-p 샘플링에서 더 다양한 출력이 나오도록 돕는 역할로 사용됩니다. 즉, 초기 KD는 학습을 위한 장치로 Temperature를 사용했고, 현재는 생성 다양성을 위한 추론 기법의 일부로 활용되고 있다는 점에서 의미 있는 변화가 있습니다.
🔗 참고 링크
