오늘은 Transformer 모델의 구조를 이해하기 위해, 실제로 각 레이어에서 발생하는 파라미터 수를 하나하나 계산해보는 시간을 가져보려고 합니다.
from torchinfo import summary
# 모델 정보 출력
summary(model, input_size=(batch_size, max_len), dtypes=[torch.int64])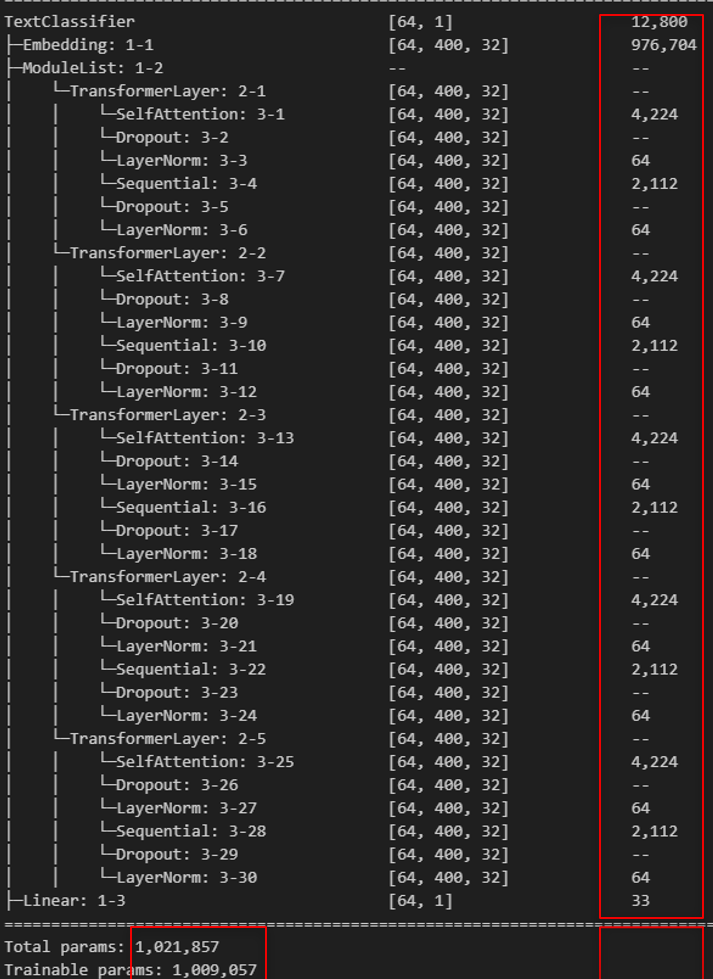
목표: 복잡한 트랜스포머 구조를 단순히 '이해'하는 것을 넘어, 실제로 어떤 층에서 몇 개의 파라미터가 발생하는지를 '직접 계산'함으로써 구조를 몸에 익히는 데 있습니다.
1. Transformer의 장단점
1.1 장점
- Attention을 통해 토큰 간의 관계를 학습할 수 있음
- RNN과는 달리 positional_encoding으로 순차처리 하지 않으므로 병렬 처리가 가능함
1.2 단점
- 구조가 복잡하고 연산량이 많아 모델 파라미터 수가 많음
1.3 환경 가정
- Batch Size: 1 (한 개의 샘플만 다루어 최대 3차원 행렬로만 계산할 수 있도록 합니다.)
- Vocab Size: 30,522
- Max Sequence Length: 400
- d_model: 32
- dff (Feed Forward 차원): 32
- Heads (어텐션 헤드 수): 4
- 레이어 수: 5
- 가중치 계산 기준: 빨간색으로 표시된 최초 생성 가중치만 셈 → 학습 가능한 파라미터만 계산
2. Embedding
2.1 Token Embedding
문장을 입력받으면, 각 단어는 원-핫 인코딩된 후 임베딩 레이어를 통해 d_model 차원으로 변환됩니다.
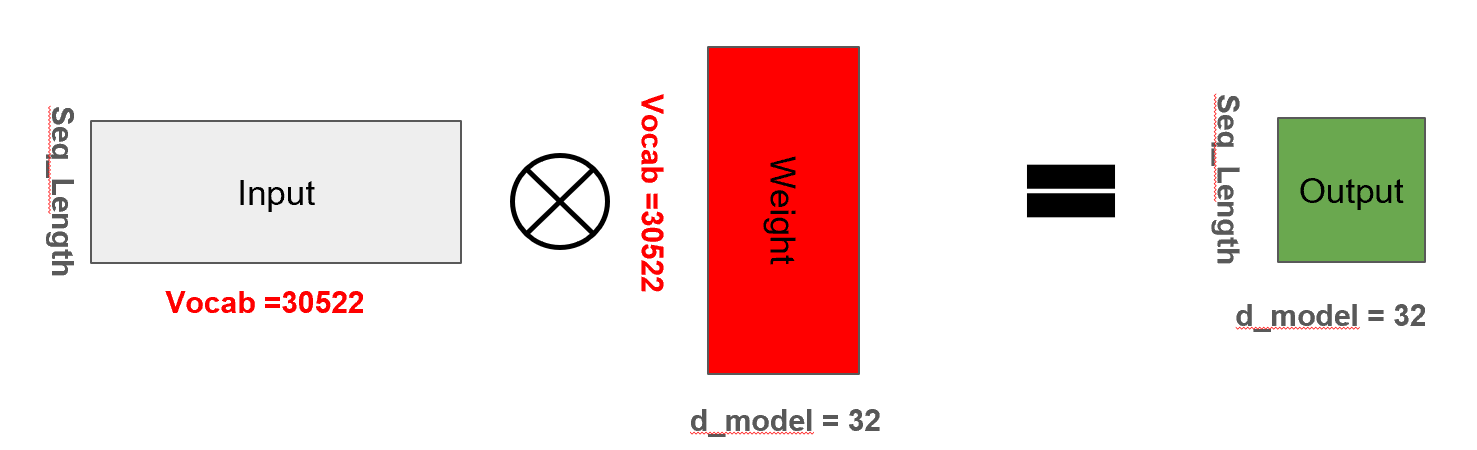
self.embedding = nn.Embedding(vocab_size, d_model)
x = self.embedding(x)2.2 파라미터 수
파라미터 수 = vocab_size × d_model = 30522 × 32 = 976,704
3. Positional Encoding
3.1 Positional Encoding
트랜스포머는 RNN처럼 순서를 보존하지 않기 때문에, 위치 정보를 임베딩 벡터에 추가해줘야 합니다. 이는 일반적으로 Sin/Cos 함수를 사용해 계산되며 학습 가능한 파라미터는 아닙니다.
import matplotlib.pyplot as plt
def positional_encoding(position, d_model):
# [:, None] (max_len,)shape을 (max_len,1)로 만들기 위한 장치입니다.
# [None, :] (1,embedding)으로 만드는 장치
# [None, ...] 가장 앞의 축에 1을 부여하는 장치, 후에 batch 차원을 위해 마련한 것것
angle_rads = get_angles(np.arange(position)[:, None], np.arange(d_model)[None, :], d_model)
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[None, ...]
return torch.FloatTensor(pos_encoding)
# 위치 인코딩 시각화
print(positional_encoding(position = example_length, d_model = example_dim).shape)
plt.pcolormesh(positional_encoding(position = example_length, d_model = example_dim).transpose(-1,-2).numpy()[0,:,:], cmap='RdBu') # 깊이에 따른 위치 인코딩 시각화
plt.ylabel('Dimension Position')
plt.xlabel('Token Position')
plt.title('Positional_encoding')
plt.colorbar() # 컬러바 추가
plt.show()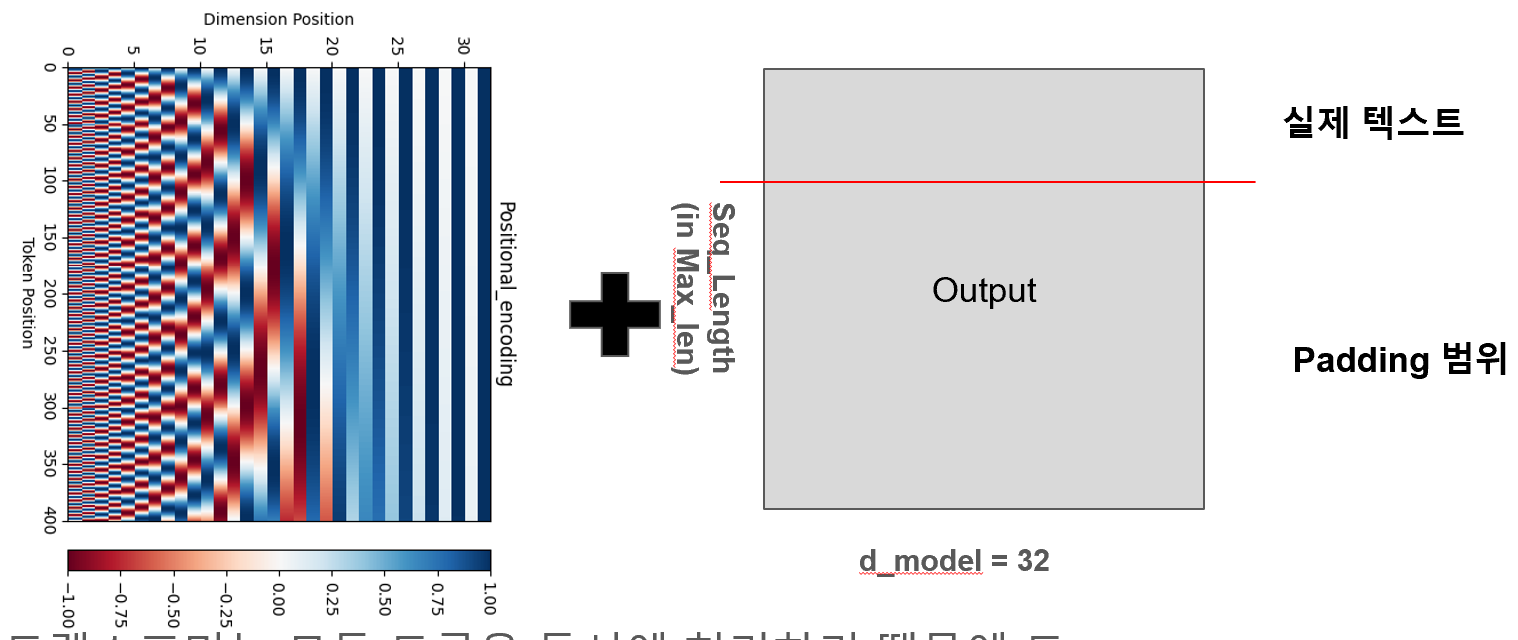
3.2 파라미터 수 : 12800개
따라서 실제 파라미터는 32 * 400 = 12800 이지만 학습 가능한 파라미터 수는 0으로 발생합니다.
4. MultiHead Attention 계산
멀티헤드 어텐션을 사용하는 이유는 단순히 하나의 시각으로 단어 간 관계를 파악하는 것에 그치지 않고, 여러 개의 독립적인 시선(head)을 통해 다양한 관점에서 문맥을 해석하기 위함입니다. 예를 들어, "나는 어제 영화관에서 영화를 봤다"라는 문장에서, 어떤 헤드는 '나는'과 '봤다' 사이의 주어-동사 관계에 집중할 수 있고, 또 다른 헤드는 '영화관'과 '영화' 사이의 장소-대상 관계에 주목할 수 있습니다. 이렇게 각 헤드가 서로 다른 의미적 연결에 주목하며 병렬적으로 학습함으로써, 모델은 단어와 단어 사이의 복잡한 의미적 관련성을 보다 정교하게 포착할 수 있게 됩니다. 결과적으로 이는 문장의 의미를 깊이 이해하고 다양한 자연어 처리 태스크에서 뛰어난 성능을 내는 기반이 됩니다.
4.1 Q, K, V 계산 (Query, Key, Value)
각 input은 Q, K, V로 변환되며, 각 변환은 선형 레이어 (Wq, Wk, Wv)를 통과합니다.
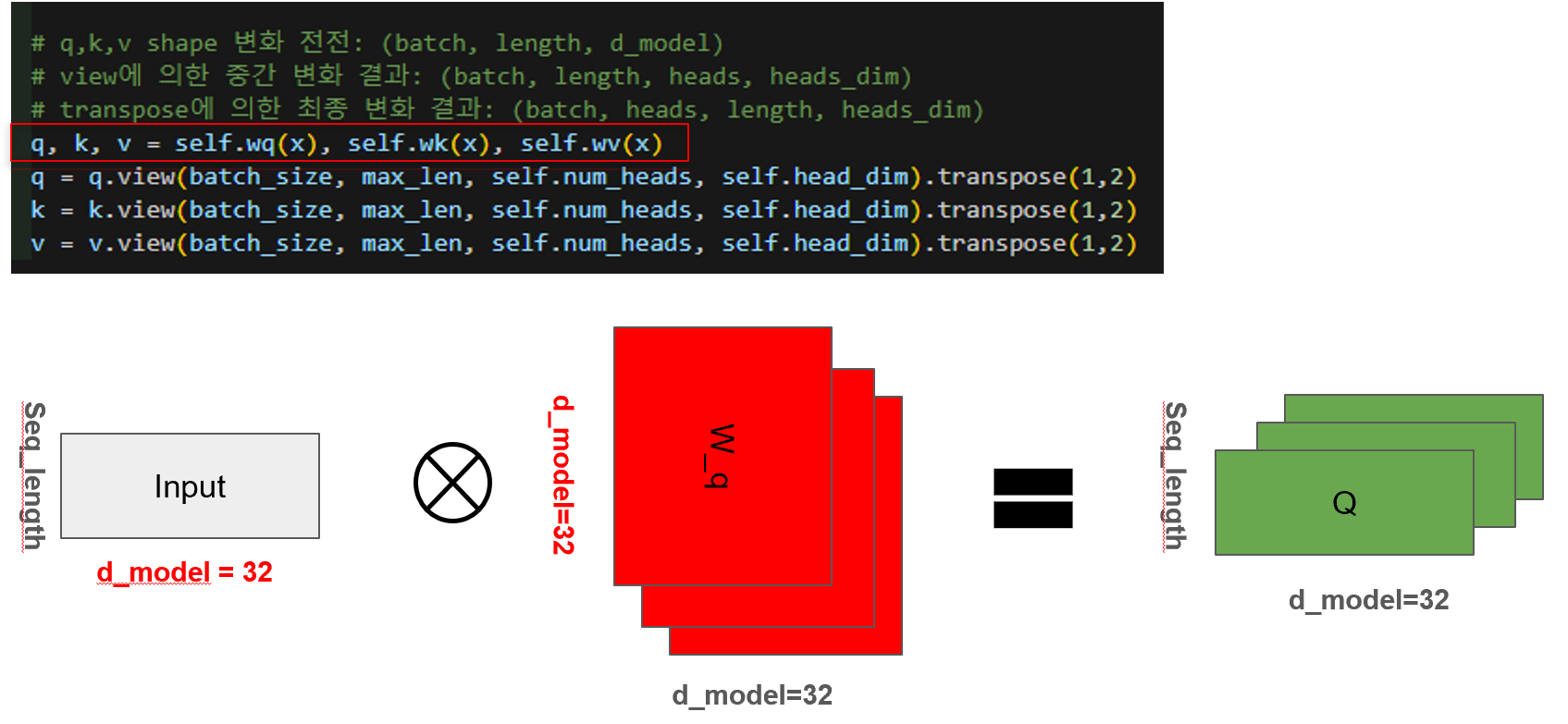
# q,k,v shape 변화 전전: (batch, length, d_model)
# view에 의한 중간 변화 결과: (batch, length, heads, heads_dim)
# transpose에 의한 최종 변화 결과: (batch, heads, length, heads_dim)
q, k, v = self.wq(x), self.wk(x), self.wv(x)
q = q.view(batch_size, max_len, self.num_heads, self.head_dim).transpose(1,2)
k = k.view(batch_size, max_len, self.num_heads, self.head_dim).transpose(1,2)
v = v.view(batch_size, max_len, self.num_heads, self.head_dim).transpose(1,2)4.2 View에 의한 shape 변화
멀티헤드 어텐션에서 사용하는 Q, K, V는 처음엔 2차원 행렬 (batch_size, seq_len, d_model)의 형태를 갖지만, 이후 view와 transpose 연산을 통해 3차원 행렬 (batch_size, num_heads, seq_len, head_dim)로 바뀌게 됩니다. 이는 원래 하나의 32차원 벡터로 표현되던 단어 임베딩을 8차원으로 나눈 뒤 4개의 헤드로 분할하여, 각 헤드가 독립적인 시선에서 attention을 계산할 수 있도록 구조를 바꾼 것입니다. 이렇게 하면 동일한 문장 내에서도 어떤 헤드는 문법적 관계에 주목하고, 다른 헤드는 의미적 유사성에 집중하는 등 다양한 관점에서 단어 간 관계를 학습할 수 있게 됩니다. 즉, 단일한 시선이 아닌 여러 개의 시선으로 문맥을 해석함으로써 트랜스포머는 더 풍부하고 정교한 의미 표현이 가능해집니다.

위의 과정을 좀 더 직관적으로 표현하면 아래와 같습니다.
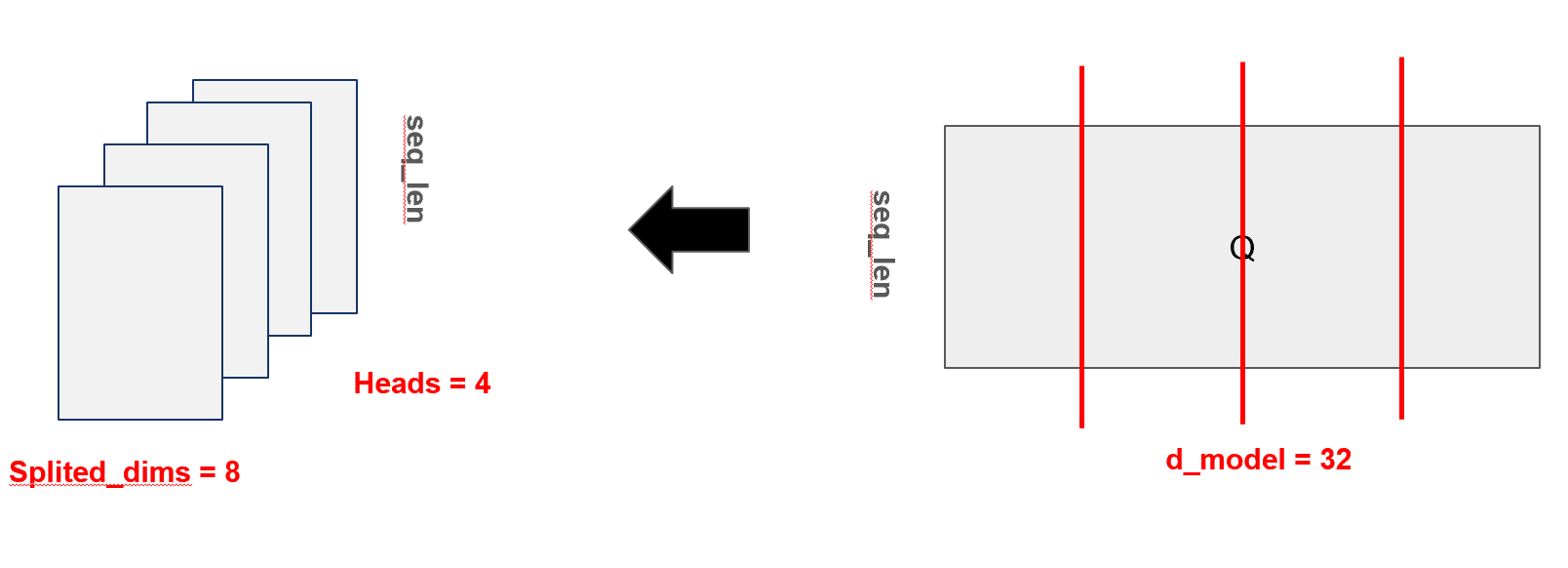
4.3 Transpose로 독립성 차원 변경
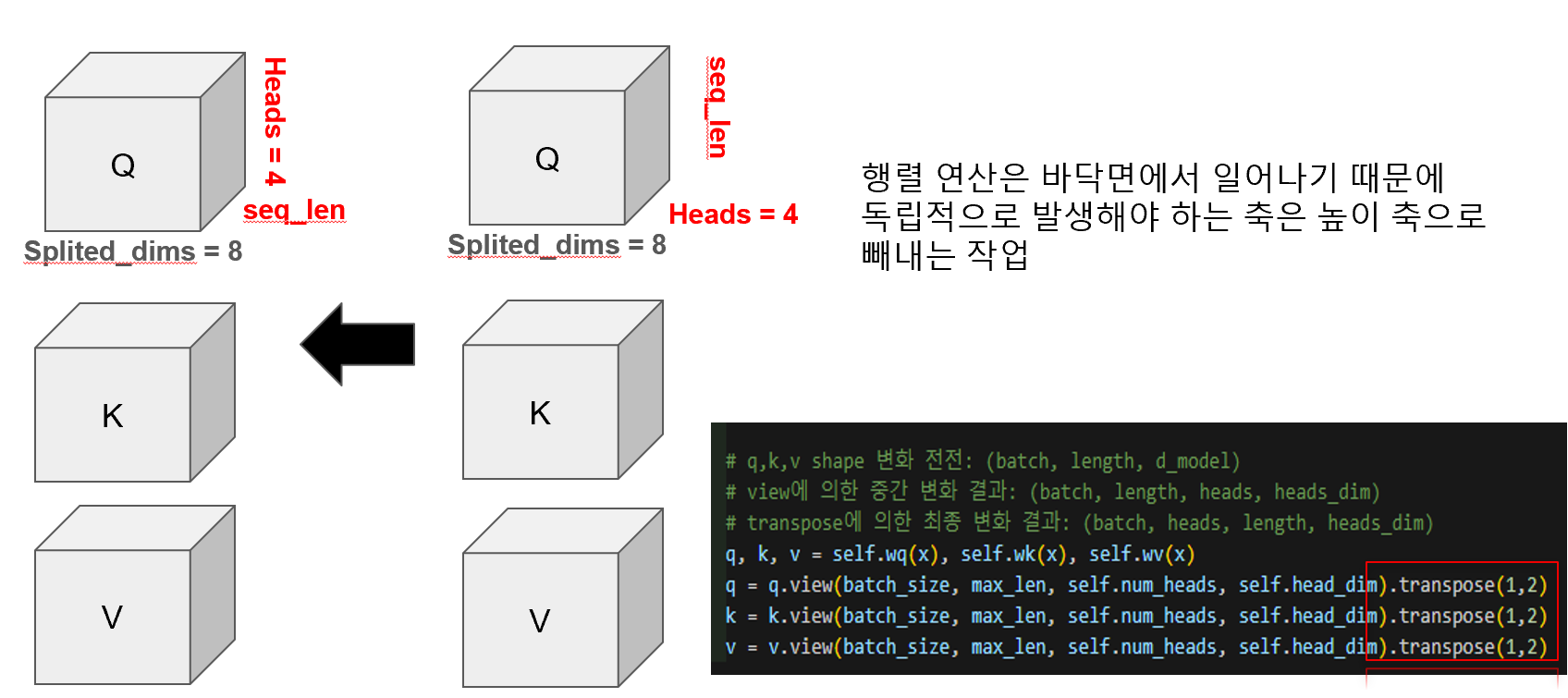
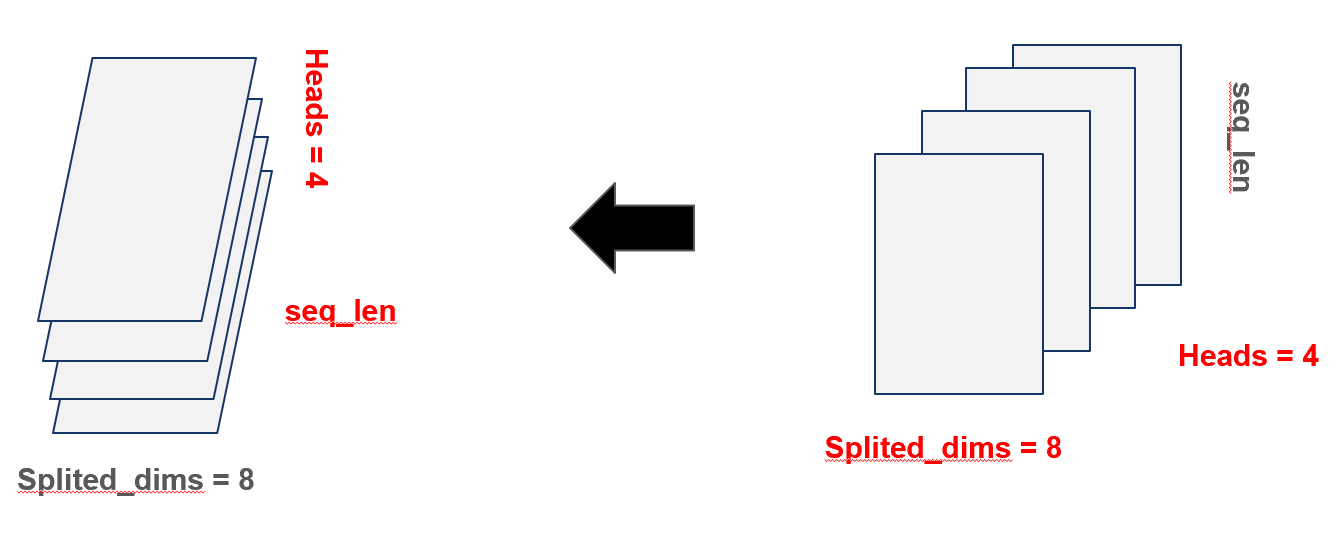
멀티헤드 어텐션에서 Query, Key, Value는 처음에 (batch_size, seq_len, d_model)이라는 2차원 구조의 행렬로 시작하지만, 이후 view 연산을 통해 (batch_size, seq_len, num_heads, head_dim)으로 차원이 늘어나고, 다시 transpose(1,2)를 통해 최종적으로 (batch_size, num_heads, seq_len, head_dim)이라는 3차원 텐서 구조로 변형됩니다. 이는 각 헤드마다 독립적으로 attention을 수행할 수 있도록 하기 위한 구조적 처리입니다. 그림에서 보듯이, 하나의 32차원 벡터를 8차원씩 4개의 헤드로 분할한 뒤, 연산이 이루어지는 바닥면(seq_len × head_dim)을 공유하되, 각 헤드는 연산을 분리하기 위해 높이 축(num_heads)으로 쌓습니다. 이 과정은 코드 상에서 .view(...).transpose(1,2)로 구현되어 있으며, 이러한 텐서 재배치는 멀티헤드 어텐션이 다양한 시선에서 단어 간 관계를 학습할 수 있도록 하는 핵심적인 단계입니다.
이를 직관적으로 표현하면 아래와 같이 됩니다.
4.4 Score 계산
어텐션 메커니즘은 단어와 단어 사이의 의미적 관계도를 수치화하는 핵심 과정입니다. 먼저, 쿼리(Query)와 키(Key)의 내적(dot product)을 통해 각 단어 쌍의 관련도를 계산하고, 이를 스케일링 및 소프트맥스를 거쳐 Score 행렬로 만듭니다. 이 스코어는 예를 들어 "나는 어제 영화관에 갔다"라는 문장에서 '나는'이라는 단어가 '갔다'와 얼마나 밀접한 의미적 관계를 갖는지를 수치로 나타냅니다. 이렇게 계산된 Score는 다시 각 단어의 의미 벡터인 Value와 곱해져 Score with Value, 즉 최종 어텐션 결과로 이어집니다. 이는 단어 간의 상호작용 정보를 단어의 임베딩에 반영하여, 단순한 단어 임베딩 이상의 풍부한 문맥 정보를 표현할 수 있게 만들어줍니다. 이 과정을 통해 트랜스포머는 문장 내 단어들의 관계를 정확하게 학습할 수 있는 것입니다.
아래는 그 과정을 도식화 한 것입니다.
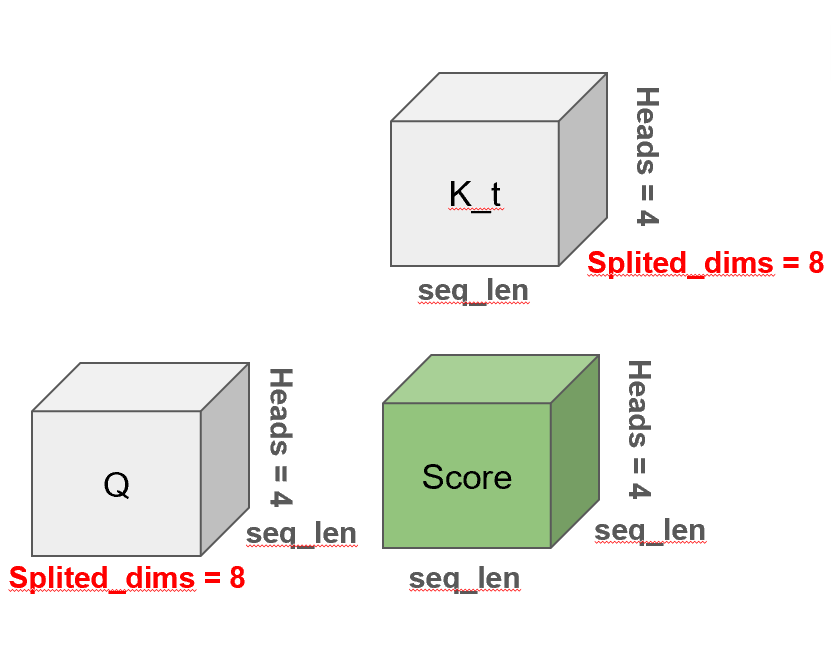
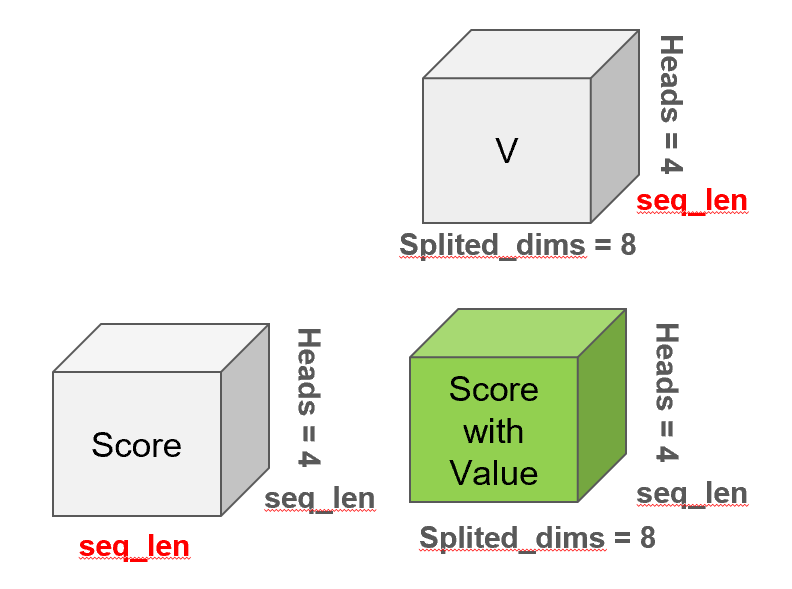
# score shape: (batch, heads, length, length)
# 왜냐하면 (batch, heads, length, heads_dim)과 (batch, heads, heads_dim, length) 행렬 연산
# 이 때, scaling은 멀티헤드 어텐션에선 head_dim으로 나눠야 합니다.
score = torch.matmul(q, k.transpose(-1,-2))
score = score / sqrt(self.head_dim)
if mask is not None:
# mask shape: (batch, 1, 1, length)
# softmax에 매우 작은 값이 마스킹에 들어가면 관련성이 없다고 판단하여
# 마스킹된 부분이 관련성 계산에서 배제되는 결과를 만듭니다.
score = score + (mask * -1e9)
score = self.softmax(score)4.5 shape 원상복구
멀티헤드 어텐션에서 각 헤드는 서로 다른 관점에서 시퀀스 내 단어들의 의미적 관계를 파악하게 됩니다. 이 과정을 통해 얻은 결과는 (batch, heads, seq_len, head_dim)의 3차원 텐서로 표현되며, 이는 여전히 head 별로 분리된 상태입니다. 하지만 최종 출력에서는 다시 이들을 하나의 통합된 시퀀스 표현으로 만들기 위해 head 축을 하나로 붙여야 합니다. 이를 위해 먼저 transpose(1,2) 연산을 통해 head 차원을 seq_len 아래로 이동시켜 (batch, seq_len, heads, head_dim) 형태로 만들고, 이어 view(batch_size, seq_len, d_model) 연산을 통해 2차원 행렬로 병합합니다. 여기서 d_model = heads × head_dim이기 때문에, 다시 원래의 임베딩 차원으로 복원됩니다. 즉, 다양한 헤드에서 얻어진 문맥 정보를 하나의 통합된 벡터로 이어붙여 풍부한 의미를 담은 최종 시퀀스 임베딩을 얻는 과정이라 할 수 있습니다.
아래는 위의 과정을 도식화 한 것입니다.
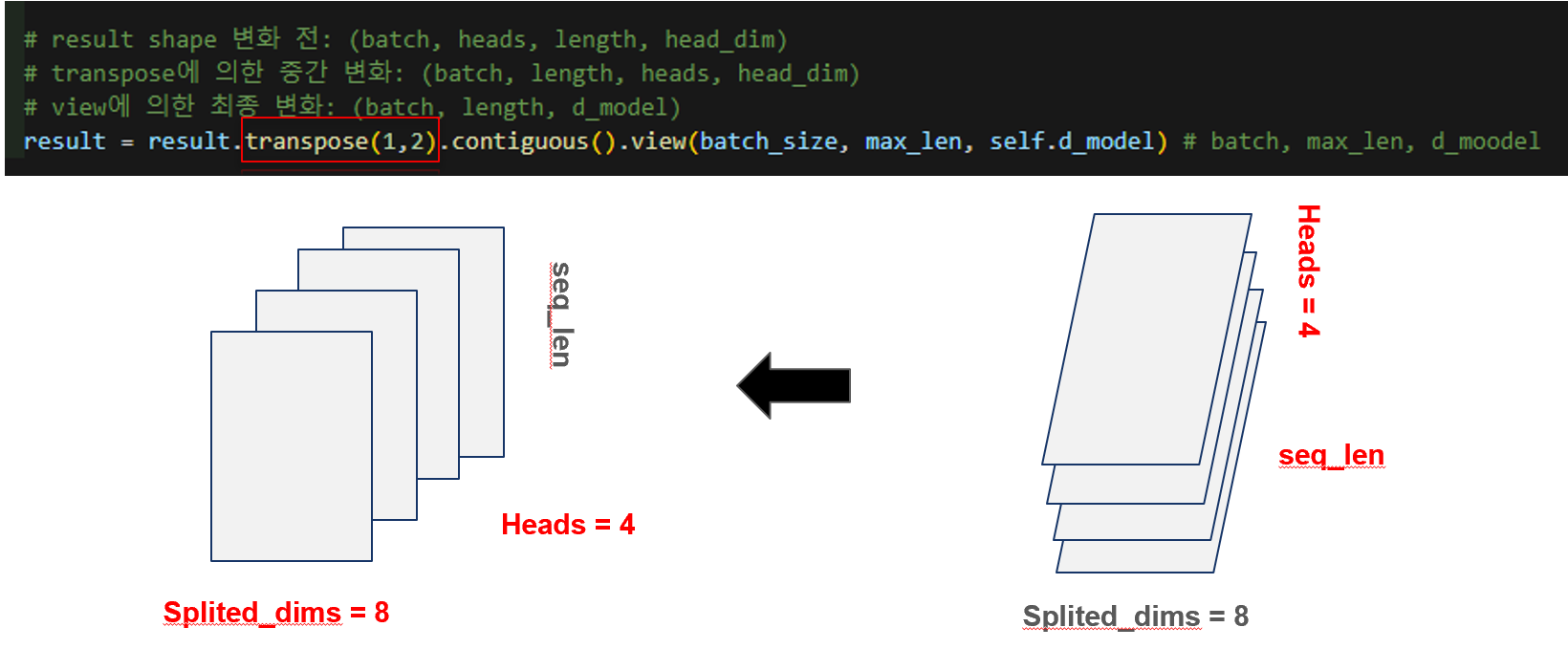
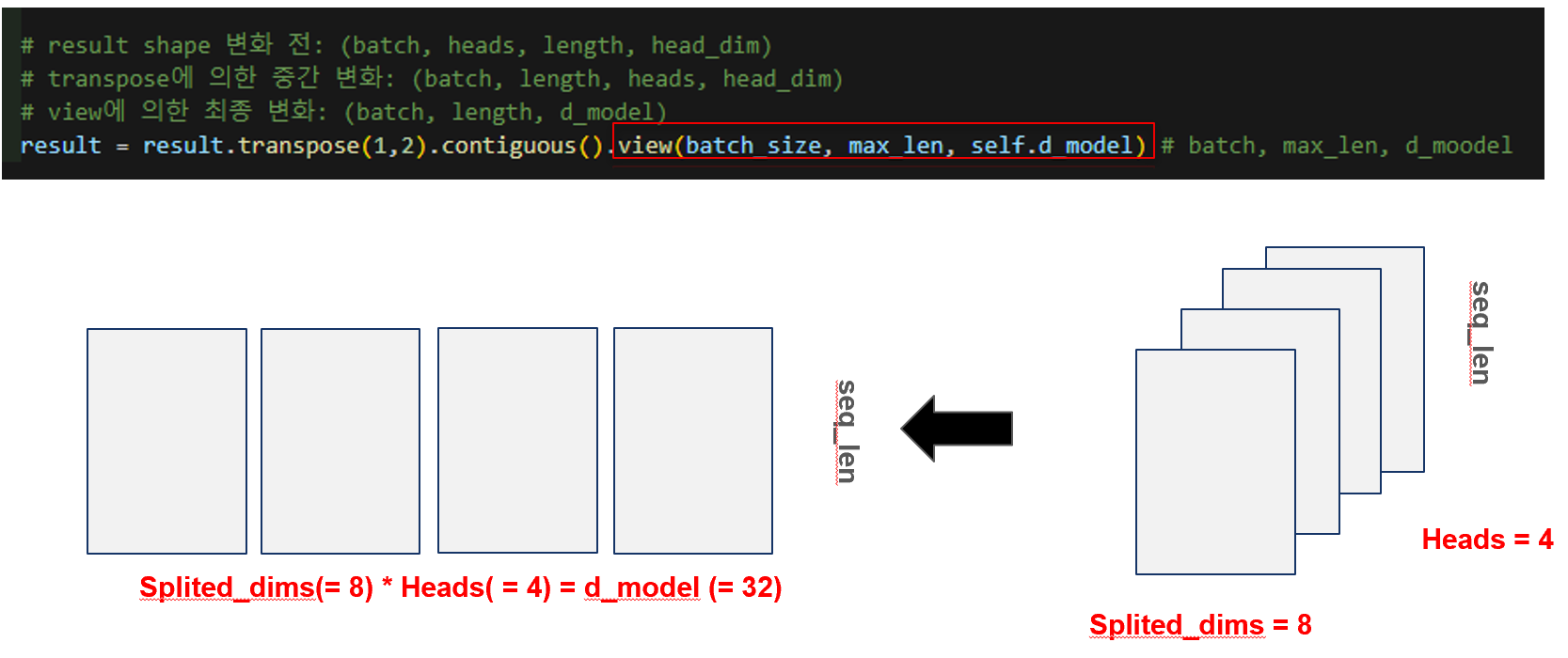
# result shape 변화 전: (batch, heads, length, head_dim)
# transpose에 의한 중간 변화: (batch, length, heads, head_dim)
# view에 의한 최종 변화: (batch, length, d_model)
result = result.transpose(1,2).contiguous().view(batch_size, max_len, self.d_model) # batch, max_len, d_moodel
4.6 마무리 dense
어텐션을 기반으로 단어간의 연관도가 단어의 의미에 잘 부여가 되었습니다. 여기서 한 번 더 복잡한 패턴을 학습하기 위하여 아래와 같은 dense layer를 한 번 더 부여합니다.
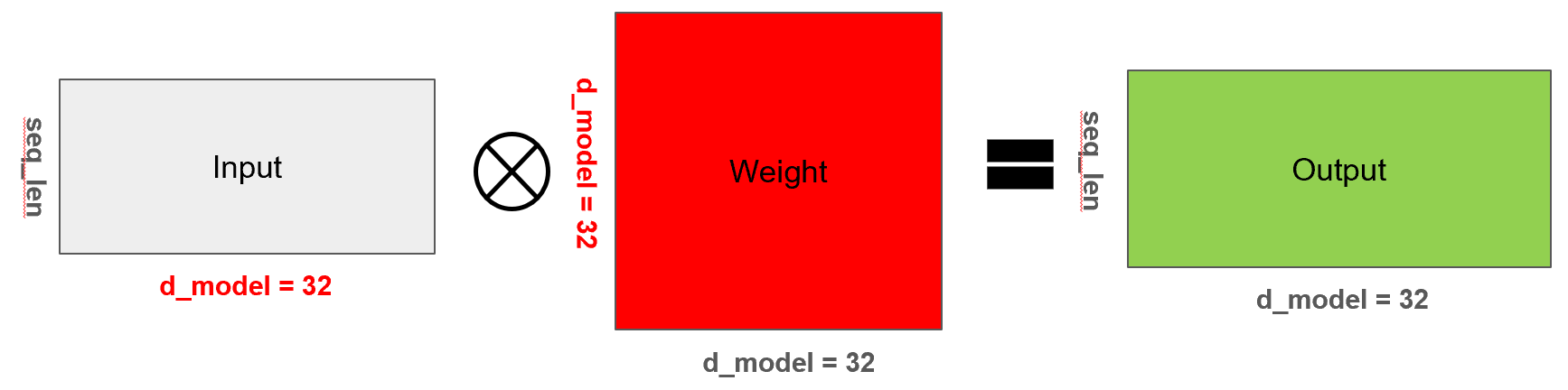
# 여기에서 dense layer를 통과시키는 것이 맞나요? attention score만 구하면 된 거 아닌가 싶었습니다.
result = self.dense(result)4.7 파라미터 수 계산: 4224
멀티헤드 어텐션에서 사용되는 주요 파라미터는 쿼리(Q), 키(K), 밸류(V)를 위한 세 개의 가중치 행렬과, 어텐션 결과를 다시 원래의 임베딩 차원으로 변환하기 위한 출력 가중치 행렬 총 네 개입니다. 각 가중치는 input_dim × d_model 형태이며, 바이어스까지 포함하면 (32 × 32) + 32 = 1056개의 파라미터가 하나의 가중치마다 존재합니다. Q, K, V 각각에 대해 1056개씩 3개 → 3168개, 그리고 최종 출력 가중치에서 1056개가 더해져 총 4224개의 파라미터가 self-attention 한 층에서 발생하게 됩니다. 이는 실제 모델 요약에서도 확인할 수 있으며, 그림 속 SelfAttention 레이어가 정확히 4,224개의 학습 가능한 파라미터를 포함하고 있는 것을 통해 검증됩니다.
5. Layer Normalization
Layer Normalization은 트랜스포머 구조에서 각 서브레이어(Multi-Head Attention이나 FFN)의 출력 값을 정규화하여 안정적인 학습을 유도하는 핵심 요소입니다. 이 정규화는 시퀀스 길이(seq_len)가 아닌 임베딩 차원(d_model)을 따라 수행되며, 평균과 분산으로 정규화한 뒤 학습 가능한 스케일링(γ)과 쉬프팅(β) 파라미터를 통해 조정됩니다. 이 γ와 β가 각각 d_model 차원만큼 존재하므로 한 LayerNorm에는 총 32 × 2 = 64개의 파라미터가 생성됩니다.
5.1 파라미터 수 : 32 * 2 = 64

6. FFN
Feed Forward Network(FFN)는 트랜스포머 인코더 블록에서 어텐션 이후 등장하는 비선형 변환 계층으로, 입력 벡터를 더 깊이 있고 복잡하게 변환해주는 역할을 합니다. 구조적으로는 두 개의 Linear 레이어로 구성되며, 첫 번째 레이어는 d_model(32) 차원을 dff(32)로 확장하고, ReLU 활성화를 거쳐 두 번째 레이어에서 다시 d_model로 축소합니다. 해당 글에서는 FFN에서 차원을 확장하지 않았지만 일반적으론 Dff > d_model 이란 경향성이 있기 때문에 차원을 쭉 늘려놓고 다시 줄여 나가는 과정이 보여집니다.
파라미터 수는 각각 (32 × 32 + 32)로 계산되며, 두 레이어를 합치면 총 2,112개의 파라미터가 생성됩니다. 그림에서도 Sequential 블록에서 해당 수치를 확인할 수 있고, 이는 FFN이 어텐션과 더불어 모델의 학습 용량을 결정짓는 중요한 구성 요소임을 보여줍니다.
6.1 도식화
self.ffn = nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(),
nn.Linear(dff, d_model)
)
ffn_output = self.ffn(x1) 6.2 파라미터 수: 2112개
7. Layernormalization
이는 5번과 동일합니다.
7.1 파라미터 수: 32 * 2 = 64개
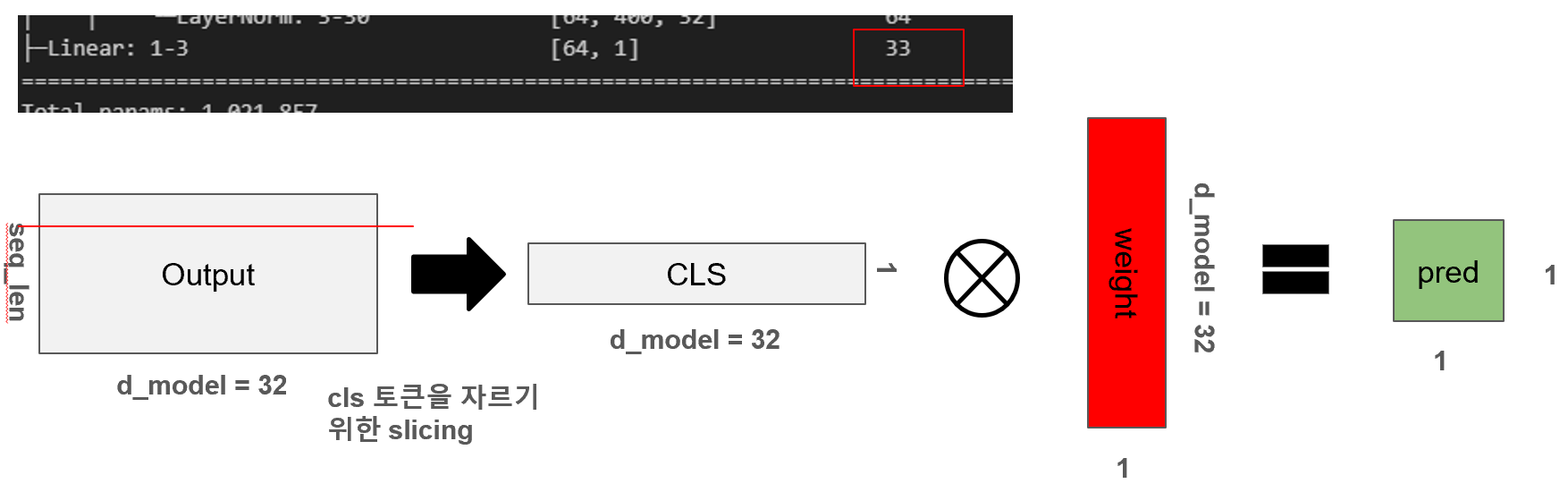
8. CLS 토큰을 통한 Classifier
트랜스포머 모델의 마지막 단계인 Classifier에서는 전체 시퀀스 중 첫 번째 위치, 즉 [CLS] 토큰에 해당하는 출력만을 선택하여 분류에 사용합니다. 이를 위해 x[:, 0]과 같은 슬라이싱 연산으로 CLS 토큰을 추출하고, 이 32차원의 벡터에 대해 선형 변환을 수행하여 1차원 출력값(예측값)을 생성합니다. 이때 필요한 파라미터 수는 (32 × 1 + 1) = 33개로, 하나의 weight 벡터와 bias로 구성되어 있습니다. 그림에서도 해당 연산이 어떻게 시각화되는지 보여주며, 실제 파라미터 수가 모델 요약 정보에 33개로 나타나는 것을 통해 정확히 일치함을 확인할 수 있습니다. 이처럼 Classifier는 트랜스포머의 풍부한 표현력을 바탕으로 최종적인 예측 결과를 도출하는 역할을 합니다.
8.1 도식화
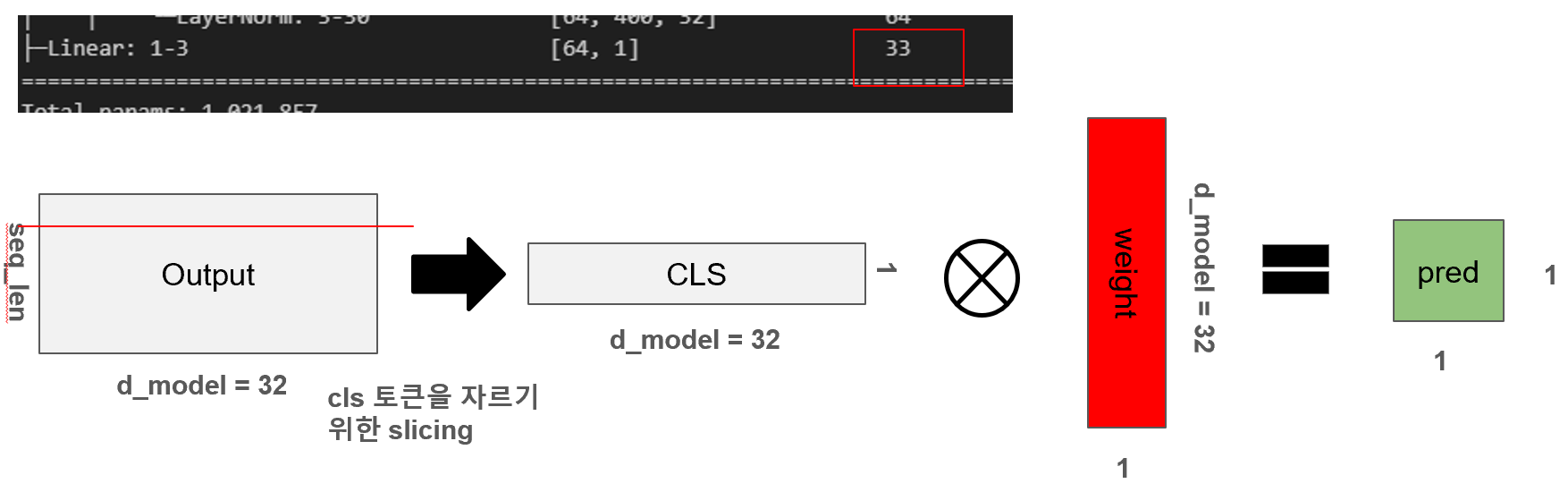
x = x[:, 0]
x = self.classification(x)8.2 파라미터 수: 33개
9. 결론
9.1 소결
이번 포스팅에서는 트랜스포머 모델의 전체 구조를 따라가며, 각 레이어에서 정확히 몇 개의 파라미터가 발생하는지를 직접 계산해보았습니다. 특히 Q, K, V를 분리하고 멀티헤드 어텐션을 통해 다양한 관점에서 문맥을 해석하는 구조, FFN을 통해 비선형적 의미를 확장하는 과정, Layer Normalization을 통한 안정적인 학습의 중요성 등 구조적 설계가 수치적으로도 어떻게 반영되는지를 파악할 수 있었습니다. 이를 통해 트랜스포머는 단순히 'attention만 하는 모델'이 아니라, 수많은 가중치와 연산 설계를 바탕으로 정교하게 의미를 추론하는 메커니즘임을 실감할 수 있었습니다.
9.2 질문
Q1. 왜 [CLS] 토큰을 분류기에 사용하는가? [SEP] 토큰이 아닌 이유는?
Q2. 왜 Batch Normalization이 아닌 Layer Normalization을 사용하는가?
