Support Vector Machine(SVM)은 AT&T 벨 연구소에서 Vapnik과 그 동료들이 개발한 지도학습 모델입니다.(Boser et al., 1992, Guyon et al., 1993, Vapnik et al., 1997) SVM 아직까지도 강력한 학습 모델 중 하나로 일컬어 집니다.
SVM은 회귀, 분류 모델 모두 사용될 수 있는 모델이지만, 이 글에서는 설명을 단순하게 하기위해 분류 모델을 기준으로 설명하도록 하겠습니다.
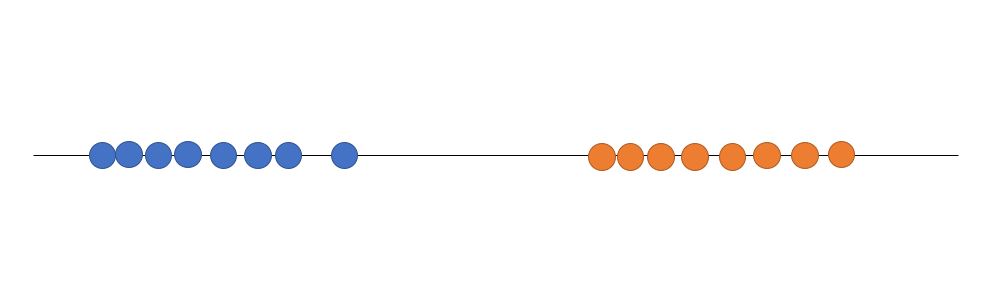
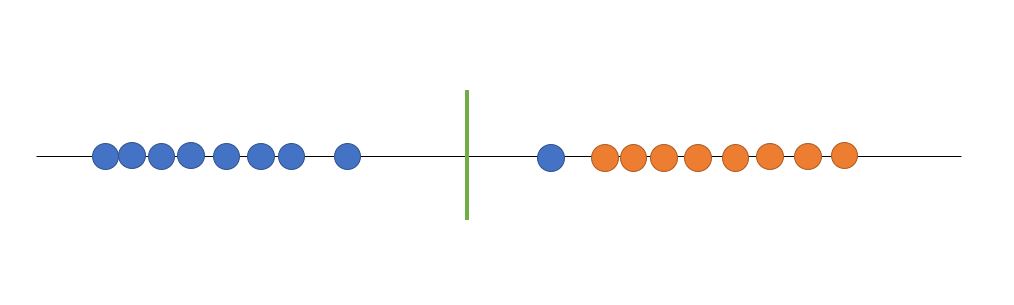
SVM을 설명하기위해 간단한 1차원 데이터를 이용하겠습니다. 아래와 같이 데이터가 있을 때, 어떻게 하면 데이터를 잘 분류 할 수 있을지에 대한 고민으로 부터 SVM은 시작합니다.
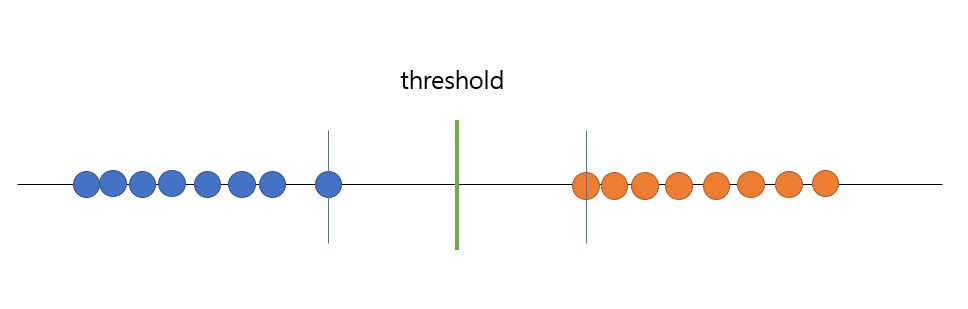
왼쪽에 파란색이 있고 오른쪽에 빨간색이 있습니다. 직관적으로 보자면 빨간색과 파란색 가운데에 threshold를 찍기만 하면 될 것 같습니다. 그러면 threshold 왼쪽에 새로운 점이 찍이면 파란색으로 예측하고, 반대의 경우에는 빨간색으로 예측하면 되기 때문입니다.
하지만 컴퓨터 입장에서는 어떤 값이 적절한 중앙값인지 직관적으로 알 수 없습니다. 컴퓨터는 직관이 없기 때문입니다. 그래서 수식으로 적절한 threshold를 찾지만, 수식적인 설명은 추후에 하도록 하겠습니다. 간단하게 방법은 파란색의 가장 오른쪽에 있는 점과, 빨간색점들의 가장 왼쪽에 있는 점의 중앙에 threshold를 찍는 것입니다.
여기서 잠깐 용어 정리를 하겠습니다.
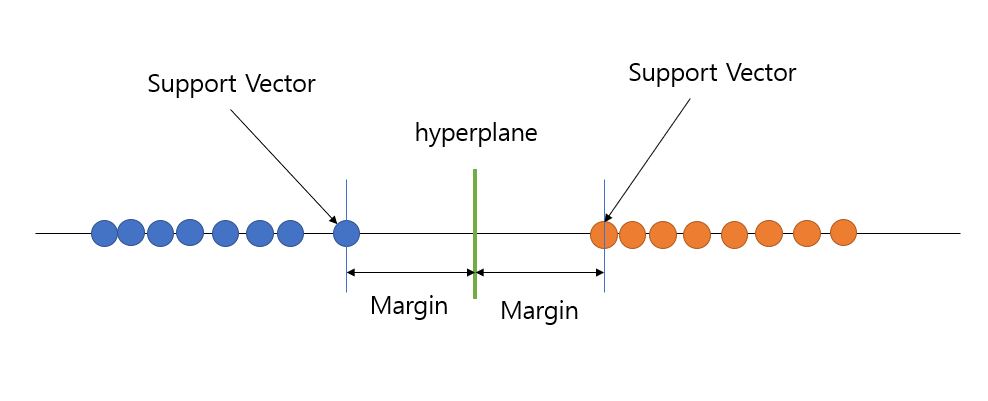
Hyperplane : threshold가 되는 부분 공간을 의미합니다.
Support Vector : Hyperplane으로부터 가장 가까운 데이터 포인트
Margin : Support Vector로부터 Hyperplane까지의 거리
위에서 내용을 용어를 사용하여 다시 정리하자면 이진 분류가 가능한 데이터셋에서 Support Vector로부터 가장 큰 Margin을 가지는 hyperplane을 찾는 것이 SVM의 목적이 됩니다.
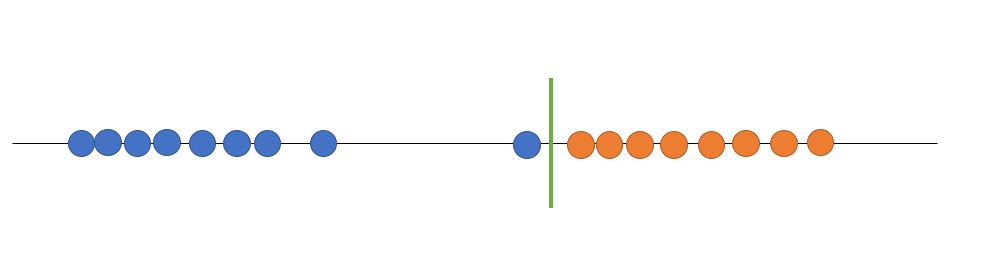
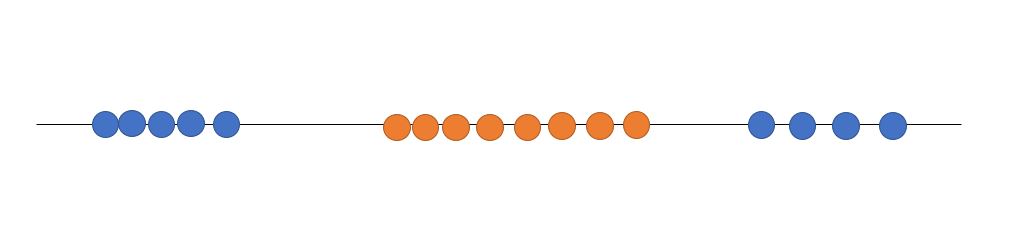
지금까지 본 데이터는 가장 간단히 분류되는 데이터를 가지고 설명하였습니다. 만일 데이터가 아래와 같이 되어 있다면 어떻게 해야 할까요?
파란색 데이터 포인트가 한쪽으로 치우쳐져 있습니다. 만일 지금까지와 같이 파란색의 가장 오른쪽의 데이터 포인트를 Support Vector로 잡는다면 Hyperplane이 오른쪽으로 치우치게 될 것입니다. 그렇게 빨간색 값들이 새로 들어왔을때, 치우친 hyperplane 밖으로 조금만 빠져나가도 파란색 판정을 받게 될 것입니다. 이와 같이 오차를 허용하지 않는 hyperplane을 만드는 전략을 hard-margin 이라고 합니다. hard-margin은 그림에서 보는 바와 같이 이상치에 매우 민감하게 작동합니다. 그러므로 모델이 오차를 허용하지 못하여 정확도가 떨어집니다. 그렇다면 모델이 이상치를 극복하기 위해서는 hyperplane을 더 유연하게 세워야 할 것입니다.
이렇게 오차를 극복할 수 있는 전략을 soft-margin이라고 합니다. hard-margin과는 다르게 soft-margin은 문제가 복잡해 졌습니다. 이를 해결 할 수 있는 방법은 cross-fold validation과 같은 방식으로 해결할 수 있습니다만, 더 자세한 방법은 Margin 파트에서 설명하도록 하겠습니다.
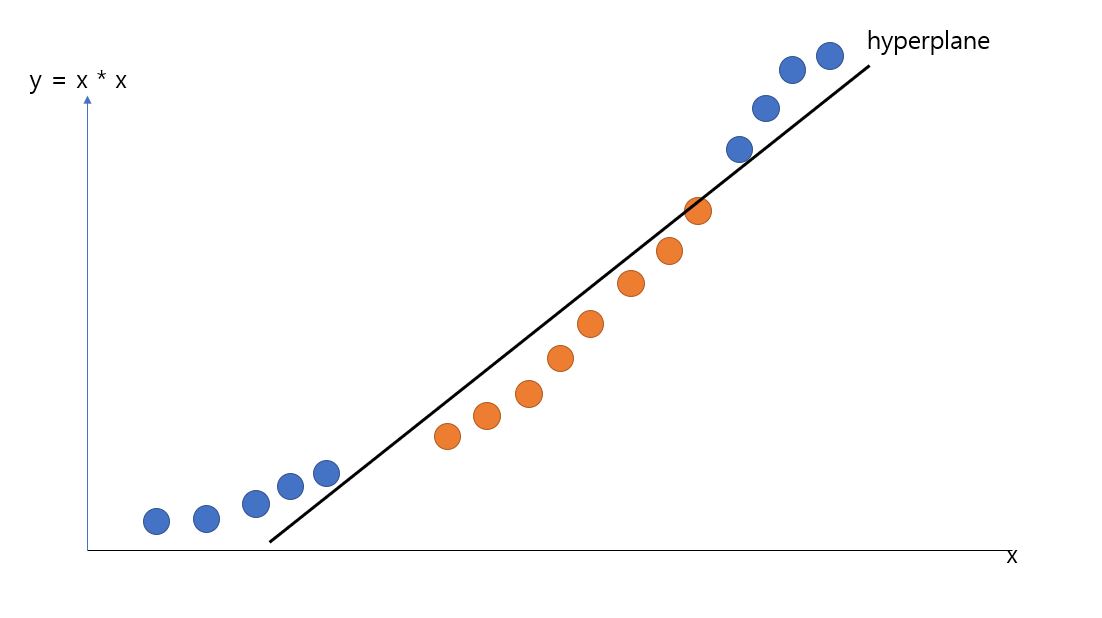
여기까지는 그래도 어느정도 해볼만 한 것 같습니다. 하지만 SVM의 진정한 힘은 아래와 같은 데이터를 분류 할때 발휘됩니다.
이 데이터의 어떤 데이터에서 어떤 데이터를 Support Vector로 할까요? 또, hyperplane을 어디에 세워야 할까요? hyperplane을 세운다 하더라도 어떻게하면 Margin을 최대한 크게 만들 수 있을까요? 단적으로 말해, 이상태에서는 soft, hard-margin을 사용한 모델의 정확도는 형편없어질 것입니다.
막다른 길에 도달한 것 같습니다. 하지만 여기서 데이터를 변형을 시켜서 1차원 데이터를 2차원 데이터로 만들면 어떨까요? 예를 들어 데이터에 제곱을 하는 것입니다. a ▶ (a,a2) 으로, 원래데이터를 x축으로 y값을 a2으로 만들면 1차원 데이터가 2차원 데이터로 변형이 됩니다.
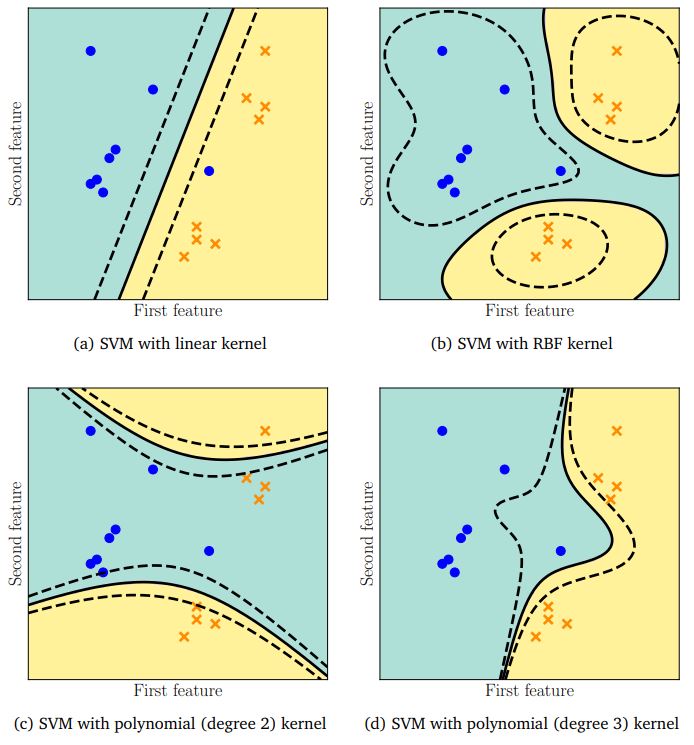
완벽하진 않아도 그럴 듯하게 분류가 되는 것을 볼수 있습니다. 이처럼, 데이터를 저차원에서 다차원으로 올려 최적의 hyperplane을 찾는 여러가지 방법이 있습니다. SVM의 실제 구현에서는 실제로는 데이터를 다차원으로 올리지 않고서도 다차원인 것 처럼 데이터를 표현 할 수 있도록 하는 Kernel Trick이라는 것을 사용합니다. 여러가지 kernel Trick들 중에 Polynomial kernel과 Radial Basis Function(RBF) kernel을 추후 설명해 드리겠습니다. 이런 방법들을 이용하면 아래와 같은 비선형적인 분류가 가능해집니다.
[사진 출처 : Mathematics for Machine Learning(Deisenroth et al.)]
요약하면 SVM이란 선형, 비선형적 데이터를 분류하기 위해 Support Vector로부터 가장 Margin이 커지는 hyperplane을 찾아 내는 것을 의미합니다. 여기까지는 매우 추상적인 SVM에 대한 설명이었습니다. 다음 목차부터는 더 구체적으로 SVM이 어떻게 작동하는지에 대해 설명하겠습니다.
Margin
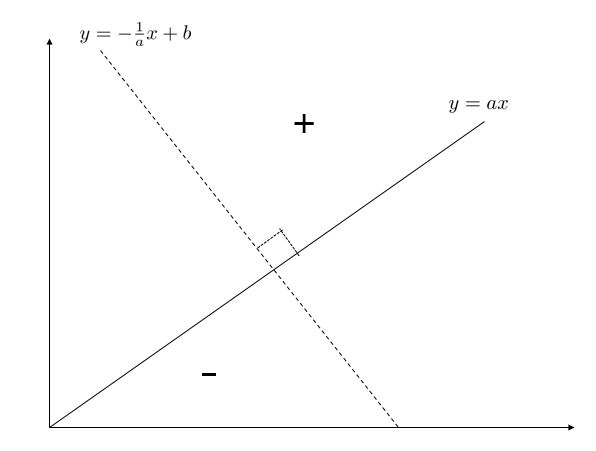
SVM은 위에서 언급했듯이 공간을 둘로 쪼갤 수 있는 적절한 hyperplane을 구해야 합니다. 이 하이퍼 플레인은 다음과 같이 정의 됩니다.
x,w∈RDf:RD→Rf(x)=<w,x>+b=0
정의만 따지자면 어렵지만 2차원 그래프로 보면 이해가 쉽습니다.
w가 y=ax 를 나타내는 vector이고 hyperplane은 y=ax 에 수직인 선 y=a1x+b 를 나타냅니다. 이 하이퍼 플레인을 기준으로 어떤 xtest∈R2에 대해 f(xtest)>0 이면 positive(+) 사이드에 있는 것이고, 반대면 negative(-)사이드에 있기 되는 것입니다. yn∈{−1,1}가 xn에 대한 정답일때 아래와 같이 표기할 수 있습니다.
yn(⟨w,xn⟩+b)≧0 (1)
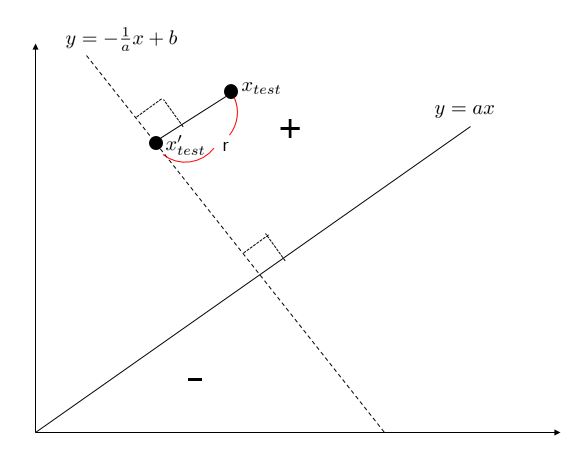
위에서 언급했듯이 SVM의 목적은 Margin을 최대화 하는 것입니다. 그렇기 때문에 어떤 xtest를 놓았을때, 하이퍼플레인까지의 거리를 먼저 정의해야 할 것입니다. 아래의 그림과 어떤 xtest를 넣었다고 합시다.
이 xtest는 hyperplane 위에 존재하는 직교하는 점 xtest′이 존재 하게 됩니다. 그러면 xtest와 xtest′과의 거리( r )를 구할 수 있게 됩니다. 만약 xtest가 다른 데이터 포인터들 중 hyperplane에서 가장 가까운 거리에였다면, 거리를 margin이라 부를 수 있습니다.
(1)번 공식은 이에 따라, hyperplane으로부터의 margin보다 더 큰 값에 대한 예측 모델을 다음과 같이 표현 할 수 있습니다.
으로 목적을 동일하게 쓸 수 있습니다. 그리고 (6)식이 바로 hard margin SVM입니다.
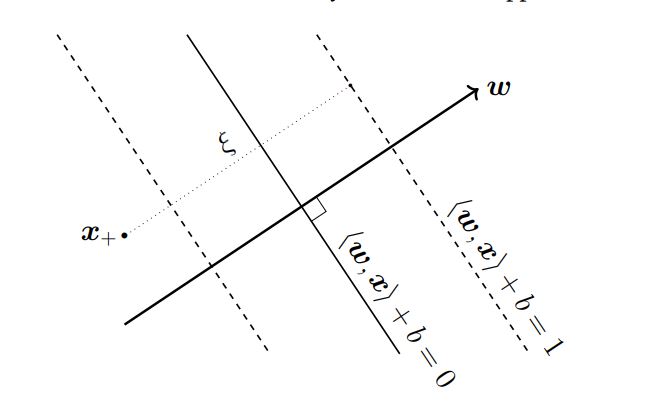
What is Support Vector Machine에서 언급했듯이, hard-margin은 모든 xn이 margin r 조건에 부합할 때만 적용 가능합니다. 반면에 soft-margin은 margin 조건을 벗어나더라도 유연하게 대응 할 수있습니다.
soft-margin 의 원리는 위의 그림과 같이 x+가 마진 밑으로 넘어가는 것과 같이, xn이 마진을 넘어가는 것을 허용합니다.
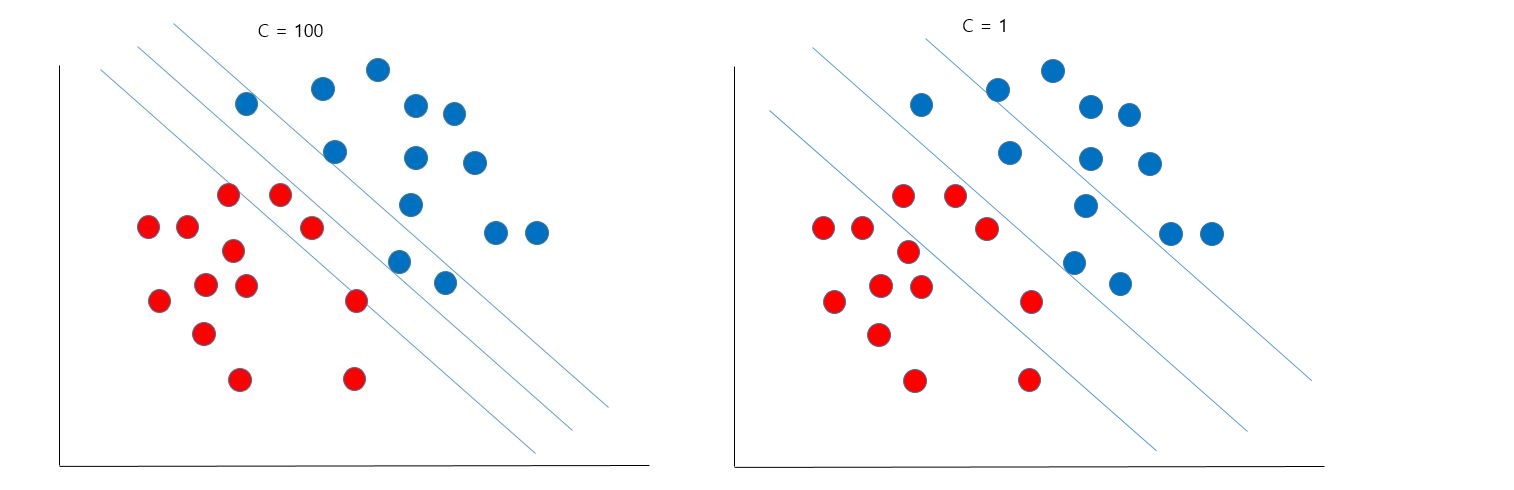
soft-margin 목적식은 다음과 같습니다. minw,b,ξ21∥w∥2+C∑n=1Nξn,Subjecttoyn(<w,xn>+b)≧1−ξn,ξn≧0 (7)
목적식은 hard margin때와 크게 다르지 않지만, margin에서 ξn값을 뺀 값까지 허용한다는 점이 다릅니다. 그리고 margin 값이 너무 커지지 않도록 Regularization parameter인 C값을 줄 수가 있습니다. 이 c 값에 따라 모델이 허용하는 margin의 크기가 달라질 수 있습니다.
Optimization
목적식을 최적화 하려면 라그랑주 승수법을 이용합니다. 라그랑주 승수법이란 제약이 있는 최적화문제를 푸는 방법입니다. f(x,y) 를 g(x,y)=c 라는 제약 조건이 있는 상황에서 f를 최적화 하기 위해, 라그랑주 승수법은 보조함수 (8)을 사용합니다.
L(x,y,λ)=f(x,y)−λ(g(x,y)−c) (8)
(8) 함수를 미분하여 0이 될 때, f가 최적점이 되는 것이 됩니다.
∇f(x,y)=λ∇(g(x,y)−c) (9)
(9)를 계산하면 f가 최적이 되는 조건을 얻을 수가 있습니다.
soft-margin의 목적 함수 (7)은 라그랑주 승수를 이용해 아래 (10)과 같이 표현 할 수 있습니다.
(11b) 에 따라 b는 0으로 사라지고, 마찬가지로 i=1∑Nyiαi⟨j=1∑Nyjαjxj,xi⟩=0으로 사라지며 (11c)에 따라 Ci=1∑Nξi−i=1∑Nαiξi−i=1∑Nγiξi=i=1∑Nξi(C−αi−γi)=0이 됩니다
결과적으로 문제는 라그랑주 승수 αi를 구하는 문제로 귀결됩니다.
αmin21i=1∑Nj=1∑Nyiyjαiαj⟨xi,xj⟩−i=1∑Nαi,subjecttoi=1∑Nyiαi=0,0⩽αi⩽C,for all i=1,...,N (14)
적절 한 α값을 구한다면 (12)번 공식에 α 값을 대입하여 w∗ 값을 회복 시킬 수가 있습니다.
마지막으로 사라진 인터셉트 b를 구하는 방법은 median({yn−⟨w∗,xn⟩∣n=1,...,N})를 구하는 것 입니다.
Kernel
위의 모델은 선형적인 모델에 대해서만 분류가 가능한 모델입니다. 비선형적인 데이터는 kernel trick 이라는 것을 사용해야 합니다. kernel 이란 k:χ×χ→R로 두 백터간의 유사성을 나타내는 함수입니다. kernel은 xi,xj가 non-linear feature map, ϕ(x)로 변형된 vector의 내적을 반환합니다.
즉슨, 1차원 이었던 데이터 a, b를 (a,a2,21)⋅(b,b2,21) 3차원 데이터의 dot product로 변환시켜주었습니다. (21는 값이 같음으로 생략 가능) 그러므로 Polynomial Kernel(degree=2)는 기존 데이터를 2차 다항식으로 변형하여 dot product 한 값과 같은 값이 됩니다.
Radial Basis Function Kernel
Radial Basis Function Kernel(RBF)은 Polynomial Kernel의 Degree를 무한으로 확장시킬 수 있습니다. RBF 은 공식은 (18)과 같습니다.
e−γ(a−b)2 (18)
γ는 a와 b 간의 관계정도를 스케일링하는 hyperparameter 입니다. 공식 (18)을 풀어보면 (19)가 됩니다.(편의를 위해 γ=1/2로 하겠습니다.)
e−21(a−b)2=e−21(a2+b2−2ab)=e−21a2+b2eab (19)
e−21a2+b2eab 에서 eab는 Taylor Series Expansion으로 변형할 수가 있습니다. Taylor Series Expansion 이란 어떤 함수를 근사하기 위해 사용하며, 공식 (20)과 같이 함수를 무한한 합으로 분해하는 것을 의미합니다.
eab는 무한 차원에 대한 dot product를 수행한 결과와 같다는 것을 알 수 있습니다. 그러므로 RBF는 데이터를 무한차원을 변형하여 dot product를 수행한 것과 같다고 할 수 있습니다.
Application
SVM은 microbiome 분야에서 활발히 사용되고 있습니다.[1], [2], [3] microbiome 데이터를 통해 질병을 분류하는 문제에서 SVM이 사용할 수 있습니다. 하지만 microbiome 데이터가 수천개의 feature를 가지고 있기 때문에 분류에 영향을 끼치는 중요한 feature들이 무엇이 있는지 알아내는 것을 목적으로 합니다. 그래서 Recursive Feature Elimiation(RFE) 방식을 사용합니다.
RFE는 어떤 알고리즘이 주어졌을 때, 반복적으로 중요하지 않은 feature들을 쳐내는 방식입니다. 그리고 정해진 숫자의 feature가 남았을 때 중지하며, 남은 feature가 분류에 가장 중요한 역할을 한다고 볼 수 있습니다.
RFE는 2가지 인자를 인수로 받습니다.
분류 알고리즘
feature 숫자
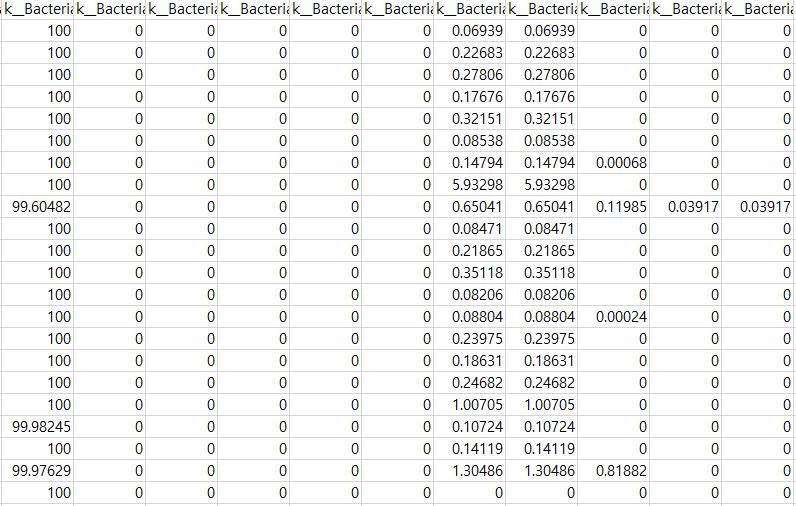
RFE-SVM은 RFE의 첫번째 인자인 분류 알고리즘에 SVM을 넣는 것 입니다. microbiome abundance table이 있을 때,
이 table의 크기는 200*3000 정도로 feature만 3000개가 넘어 갑니다. 컬럼은 각각 microbiota를 의미하고 row는 하나의 샘플을 의미합니다. 이 때,분류에 영향을 끼치는 10개의 가장 중요한 microbiota를 찾아야 할 때 RFE-SVM을 사용할 수 있습니다.
[1] Cui, H., Zhang, X. Alignment-free supervised classification of metagenomes by recursive SVM. BMC Genomics 14, 641 (2013). https://doi.org/10.1186/1471-2164-14-641
[2] Liu, Y., Guo, J., Hu, G. et al. Gene prediction in metagenomic fragments based on the SVM algorithm. BMC Bioinformatics 14, S12 (2013). https://doi.org/10.1186/1471-2105-14-S5-S12
[3] Ning, J., Beiko, R.G. Phylogenetic approaches to microbial community classification. Microbiome 3, 47 (2015). https://doi.org/10.1186/s40168-015-0114-5