양자화로 로드하는 방법을 공부하던 중 torch.float16과 bfloat16의 차이가 궁금해져서 공부해보았다.
torch.float16 과 bfloat16의 차이
이들은 모두 데이터 사이즈를 줄이는 방식이다. 기존 32-bit로 표현하던 숫자들을
torch.float16과 bfloat16와 같은 저정밀도 부동 소수점 데이터 형식으로 변형 시키는 것이다. 이들은 결론적으로 딥러닝 연산에서 메모리 사용량을 줄이고, 계산 속도를 향상시키기 위해 사용됩니다. 대신 정확도는 기존 32-bit보다 떨어질 수 있다.
아래는 FP16, FP32, 그리고 BF16을 표현한 그림이다.
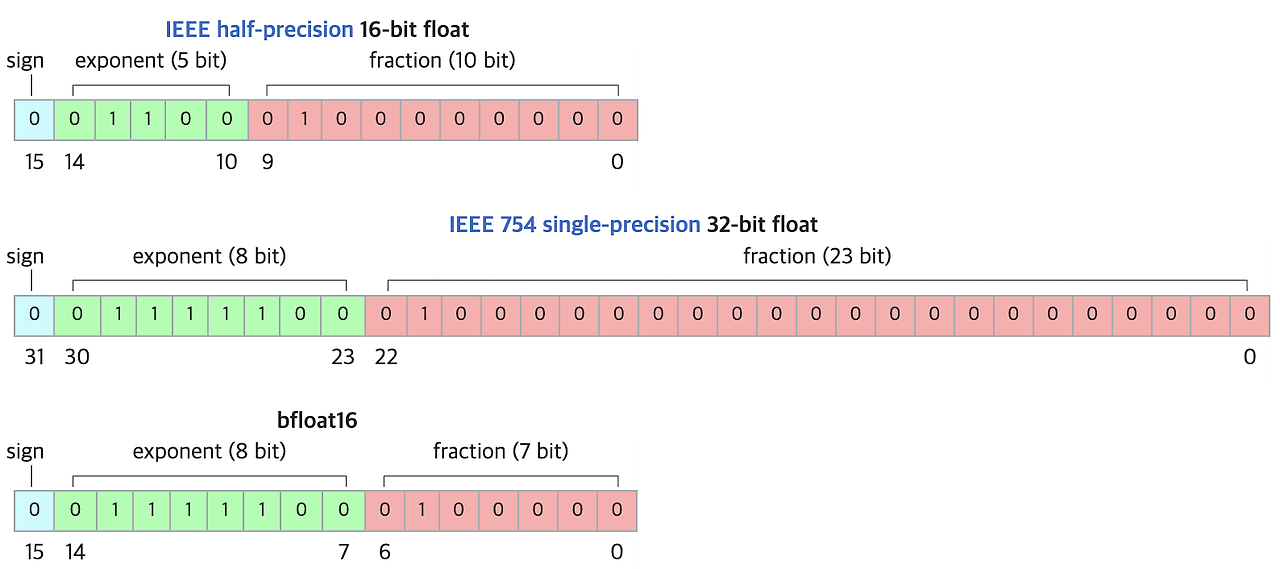
사진을 보면 bfloat16은 32-bit 와 자릿수를 대표하는 exponent(지수 자릿수)의 수가 8개로 같다. 따라서 16-bit 보다 더 넓은 수의 표현을 할 수 있다. 대신 수의 정밀도는 떨어진다.
표현 정밀도가 떨어진다는 말의 예는 다음과 같다.
ex) 0에 가까운 수가 모조리 0으로 표현될 수 있음
이는 단순히 숫자가 0이 되는 것보다 계산을 하다 숫자를 0으로 나눌 가능성이 생길 확률을 높여서 문제인 것이다.
BF16 vs FP16 활용 상황
결국에 정답은 없고 상황을 고려해서 사용해야한다
BF16가 좋은 상황
-
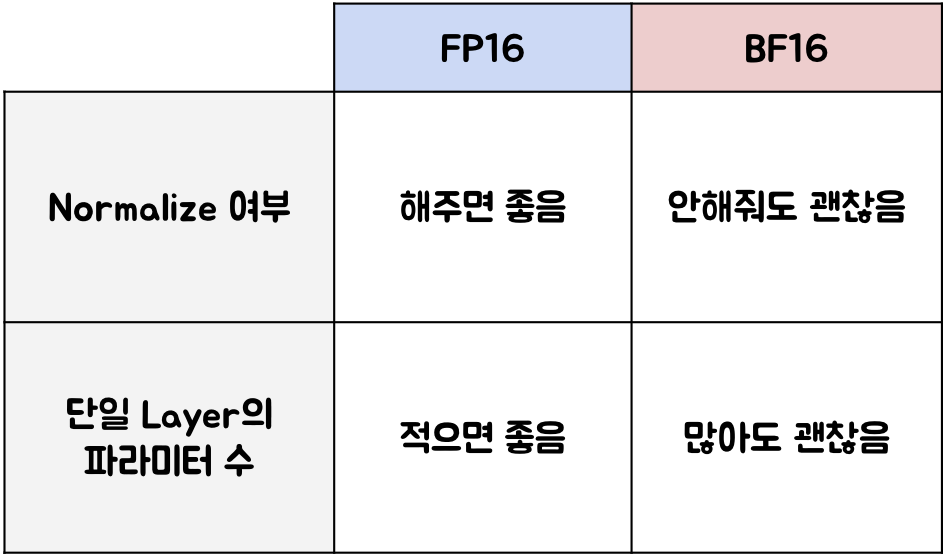
Normalize를 하지 않는 경우
Normalize를 하지 않을 때 상대적으로 수의 절댓값이 커지기 때문에 수의 표현 범위를 넓히는 게 에러를 줄이기 좋을 수 있다. -
Layer의 파라미터가 많을 수록
nn.Linear(10,10)보다 nn.Linear(1000,1000)에서 한 번에 많은 수를 곱하고 더하기 때문에 수의 절댓값이 커질 가능성이 높습니다. 따라서 파라미터가 많을 수록 bfloat이 좋다.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=bfloat16
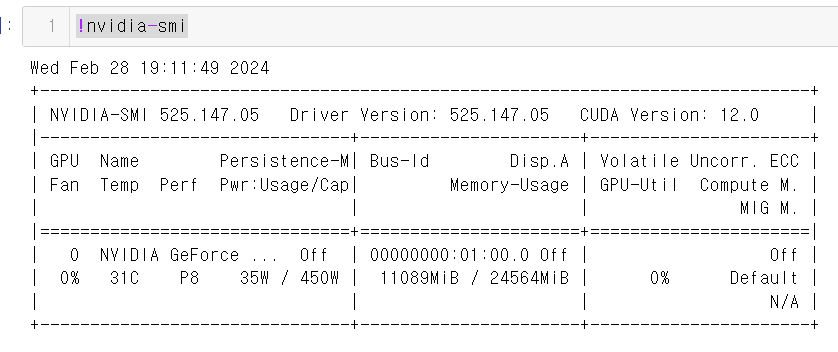
)torch.float16으로 설정했을 때
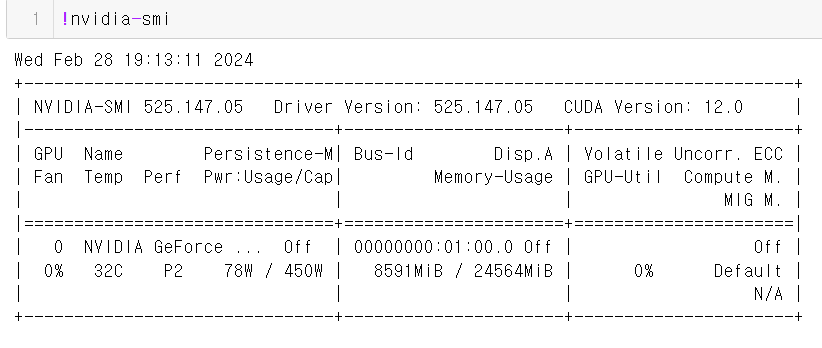
bfloat16으로 설정했을 때
요즘 Transformer 기반의 모델이 대부분이라 BF16도 좋은 선택이 될 수 있다. 또 대부분의 모델을 bf16에 최적화 시키는 경우가 많기는 하지만 모델마다 상이하기 때문에 테스트를 한번 해보는걸 추천한다.
