Bag of Freebies 1: Visually Coherent Image Mixup
모델의 연산량을 유지하면서 성능을 올리는 것은 힘든 일이다. 그만큼 이와 관련해서 많은 연구가 이뤄지고 있는데, object detection 분야에서 자주 활용되는 방법론 중 하나가 Bag of Freebies이다. 이름에서도 알 수 있듯이 다양한 기법들을 한데 묶어서 가리키는 용어이며, 해당 기법들을 소개한 논문은 여기서 확인할 수 있다.
논문의 저자들은 해당 기법들을 'object detection 모델의 추론 과정에서 연산량을 유지하면서 성능을 향상'시키기 위한 기법들이라고 소개한다. YOLOv4에는 해당 기법들이 적용되어 있지만, YOLOv5의 개발자 Glenn Jocher의 Github comment를 보면 v5에는 적용되어 있지 않은 것으로 보인다. Image Source
Image Source
논문은 본격적으로 Bag of Freebies에 대해 설명하기 전에, 기존에 image classification에서 활용되던 기법들부터 소개한다.
- Learning rate warmup heuristic: Mini-batch size가 굉장히 큰 경우에서 좋은 효과를 보이는 기법이다. 비록 image classification과 관련하여 소개된 기법이지만, object detection task에서 anchor size가 30,000 이상으로 큰 경우에 활용될 여지가 있다고 소개되어 있다.
- Label smoothing: Cross-entropy loss에서 ground truth labeling 값에 조정을 가하는 방법이다. 이는 bag of freebies에서도 활용되는데, 해당 파트에서 좀 더 자세히 다루겠다.
- 그 외에도 mixup for alleviating adversarial perturbation, cosine annealing strategy for learning rate decay 등의 기법들이 존재한다.
그 후 본격적으로 Bag of Freebies에 대한 설명이 이뤄지는데, 이번 글에서는 첫 번째 기법인 visually coherent image mixup 기법을 간략하게 정리해보고자 한다.
Visually Coherent Image Mixup
이름에서 유추할 수 있듯, 서로 다른 이미지를 mixup하는 방법이다. 이 방법은 기존에 활용되던 두 기법을 혼합한 기법으로 볼 수 있다. 하나는 <mixup: Beyond Empirical Risk Minimization>에서 소개된 기법으로, 다음 사진을 보면 이해하기 쉬울 것이다.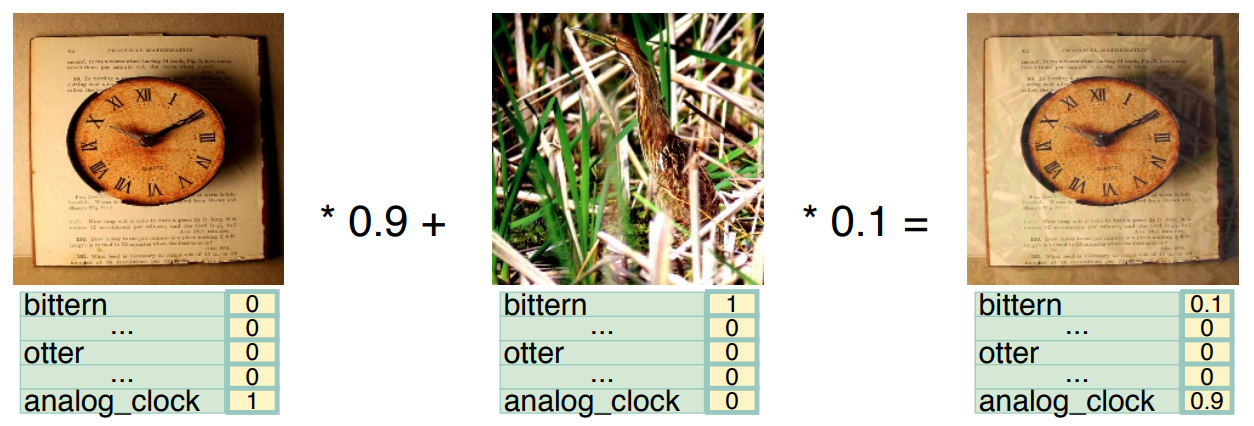 Image Source
Image Source
두 이미지를 겹친다고 이해하면 된다. Blending ratio의 경우 의 beta distribution을 따른다고 가정하는데, 이러한 가정 하에서는 0 또는 1에 치우친 ratio가 나올 확률이 크므로 대부분의 mixup들이 noise가 낀 이미지처럼 보여지게 된다.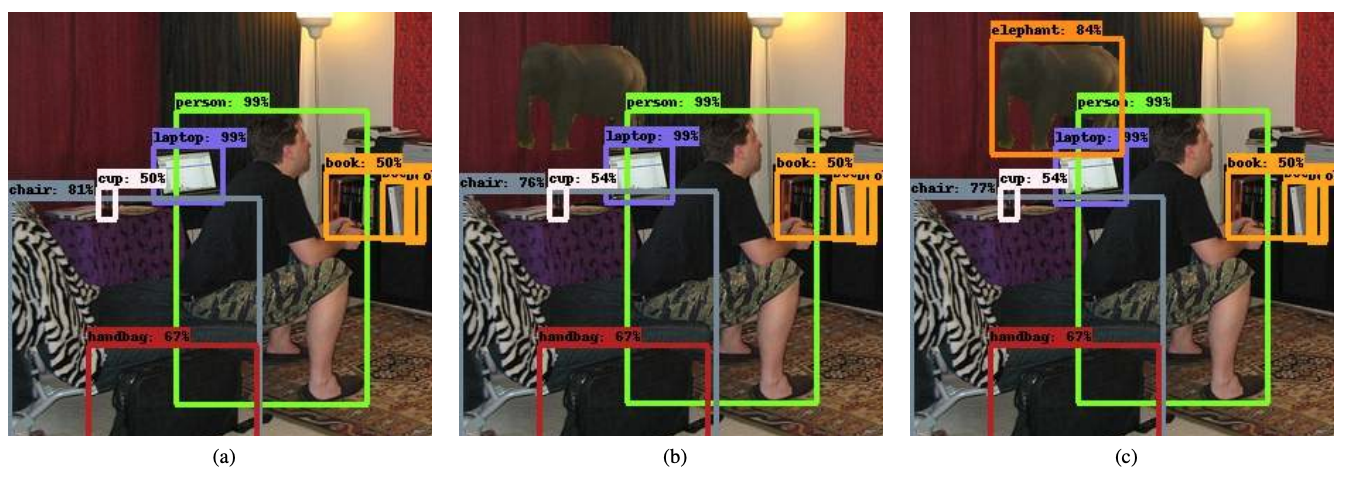 Image Source
Image Source
두 번째 기법은 <The Elephant in the Room>에서 소개된 기법으로, 이미지에 작은 patch를 랜덤한 위치에 넣어서 detection task에 challenge를 가하는 방법이다.
논문이 제시하는 visually coherent image mixup 기법에서는 blending ratio를 다르게 설정하는데, 아래 사진을 보면서 이해해보도록 하자.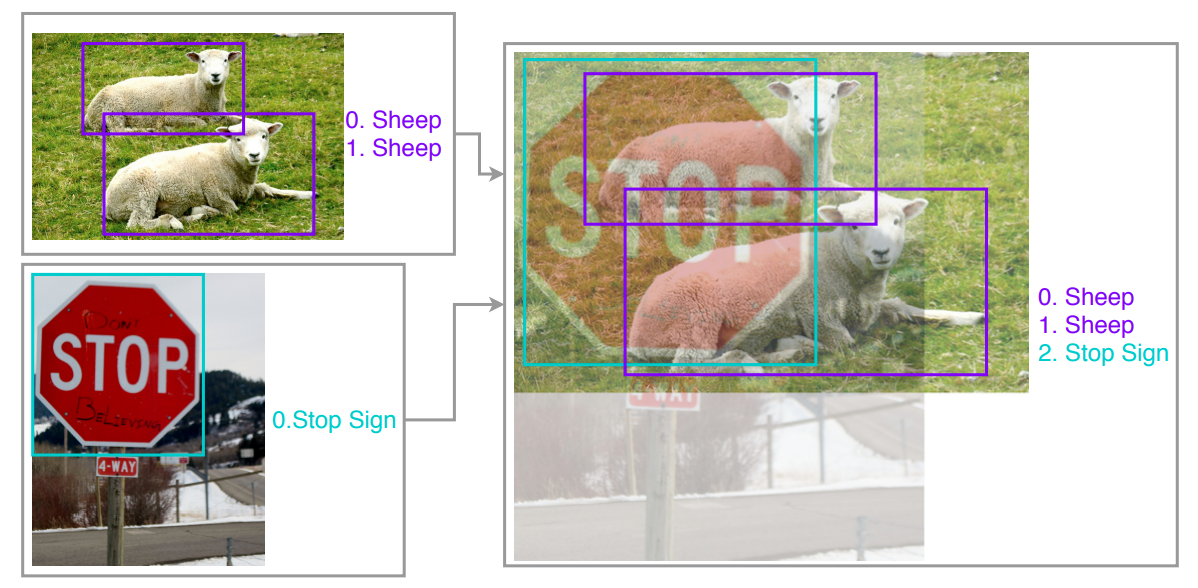 Image Source
Image Source
위에서 언급한 두 기법 중 첫 번째 기법의 경우 beta distribution에서 와 값을 모두 0.2로 설정했는데, visually coherent image mixup에서는 각각을 1 이상의 값으로 설정한다. 이렇게 될 경우 blending ratio가 0.5에 가까운 값으로 설정될 확률이 높아지고, 위 사진과 같이 두 이미지가 비슷한 수준으로 mixup된다. (논문의 저자들은 위 원리를 설명하면서 화질이 낮은 영상(ex. CCTV 영상)에서 물체가 흐릿하게 보이는 것을 언급하는데, 화질이 낮은 영상에서 해당 기법이 효과적이라고 주장하기 위해 언급한 것인지는 불확실하다)
 Image Source
Image Source
실험을 진행한 결과 와 의 값을 1.5로 설정한 경우에서 성능이 가장 좋았는데, Elephant in the Room 실험에서 특히 흥미로운 결과가 도출되었다. COCO 2017 dataset에 대해 YOLOv3 모델 두 개를 train시키되 하나에 대해서만 위 방법론을 적용하였다. 그 결과 위 방법론을 적용하지 않은 vanilla 모델은 elephant patch가 적용되었을 때 제대로 된 detection을 수행하지 못하였다. 논문은 patch로 인해 occlusion이 발생했다는 점과 elephant patch가 맥락없이(데이터셋에서 전혀 볼 수 없는 방식으로) 등장했다는 점을 그 이유로 들었다.
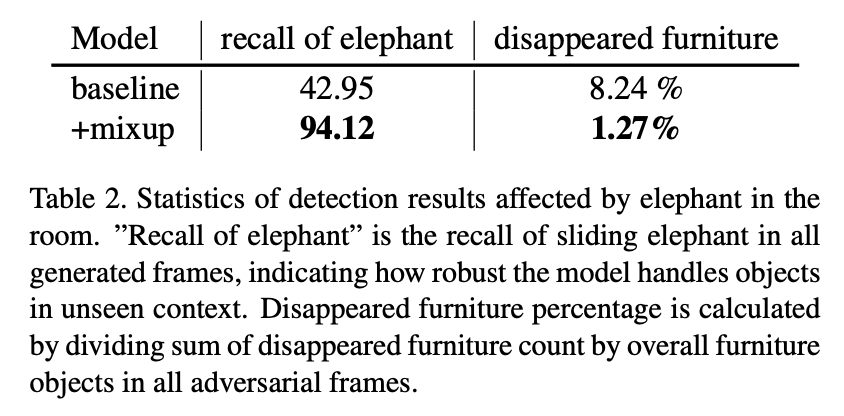 Image Source
Image Source
반면 위 mixup 방법론을 적용한 경우 elephant patch를 제대로 detect했을 뿐만 아니라 patch로 인해 가려진 furniture에 대해서도 꽤 나쁘지 않게 detection을 수행하였다. 처음부터 input image에 대해서 mixup 처리를 가한 상태에서 train을 진행했기 때문에 낯선 image patch가 등장한다고 하더라도 robust하게 대처할 수 있는 것이다. 논문은 모델이 score를 산출해내는 데에 있어 baseline 모델보다 약간 더 낮은 값을 결과로 내놓는다고도 언급하는데(논문에서는 모델이 'humble'하다고 표현하는데 나름 괜찮은 표현인 것 같다), 그렇다고 해서 결과에 부정적인 영향을 주지는 않는다고 설명한다.
Object detection 분야에서 골치 아픈 문제로 자주 언급되는 occlusion을 효과적으로 해결한다는 점에서 visually coherent image mixup 기법은 큰 의의가 있다고 볼 수 있다. 특히 구현 방법이 그리 까다롭지 않다는 점에서도 해당 기법은 주목할 만하다. 다음 글에서는 논문에서 소개된 두 번째 기법인 classification head label smoothing과 세 번째 기법인 data processing에 대해 소개해보고자 한다.
