어느 덧 'Phase 3'의 마지막 단계인 'Phase 3-5'에 들어왔습니다.
본격적으로 설명 들어가기에 앞서 간단하게 'phase 3-5'에서 뭘 하는지 알아보도록 하겠습니다.
즉, 간단하게 말하자면,
'S3 버킷에 저장되어 있는 파일을 AWS Glue와 Athena를 통해서 바로 SQL 쿼리로 처리하는 작업'을 합니다.자세한 설명은 바로 뒤에서 이어서 하겠습니다.

※이번 게시글은 오류/에러 작업들이 상당히 많습니다.
제가 작업했던 순서 그대로 순차적으로 진행하면서 오류/에러를 다시 잡고 가는 방향으로 작성할 예정이오니 참고바랍니다.
제가 게시글에서 '뒷 부분에 설명이 나옵니다.' , '후반부에 나옵니다.' 이렇게 기술을 하는데, 그 해당 부분을 '앵커'로 표시해 쉽게 찾아볼 수 있도록 설정하겠습니다.
※cf.)벨로그에서 앵커 표현법

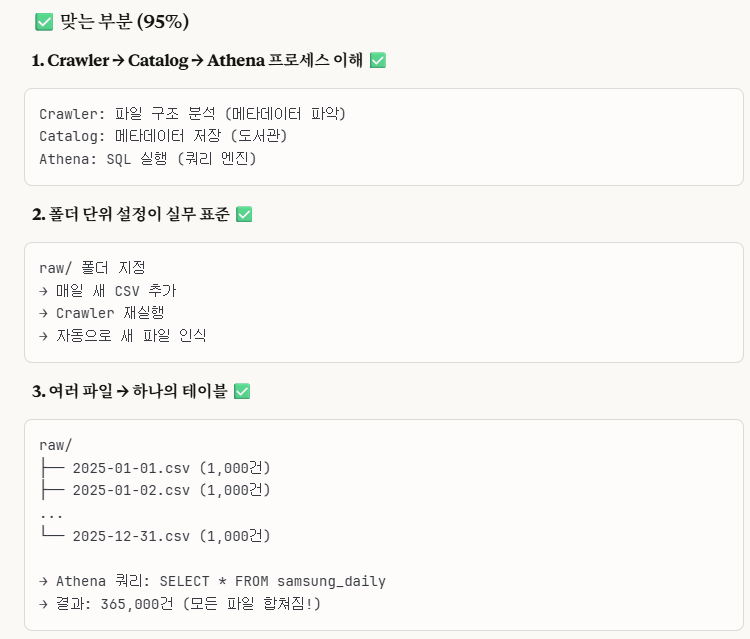
1. AWS Glue & Athena란?

우리는 바로 앞에서 'phase 3-5' 작업이 이렇다는 것을 간단하게 살펴보았습니다.
그렇다면 우리는 왜 이 작업이 필요한 것일까요?
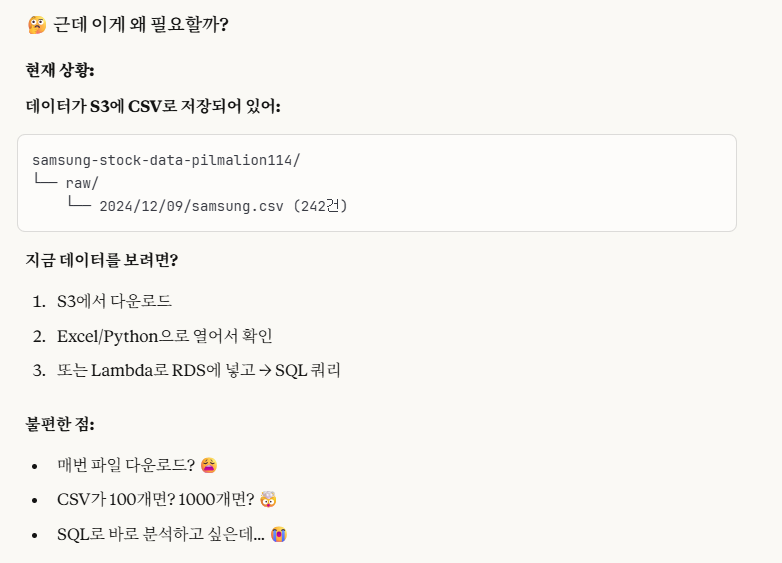
만약, 우리가 확인해야 할 csv 파일이 100개 혹은 1000개가 있다고 가정해봅시다.
일반적인 방법으로는,
우리는 하나하나 csv 파일을 읽어와서 데이터를 분석해야할 것입니다.
그렇다면 너무 오래걸리지 않을까요?
AWS Athena가 바로 이 문제점을 해결해줍니다.
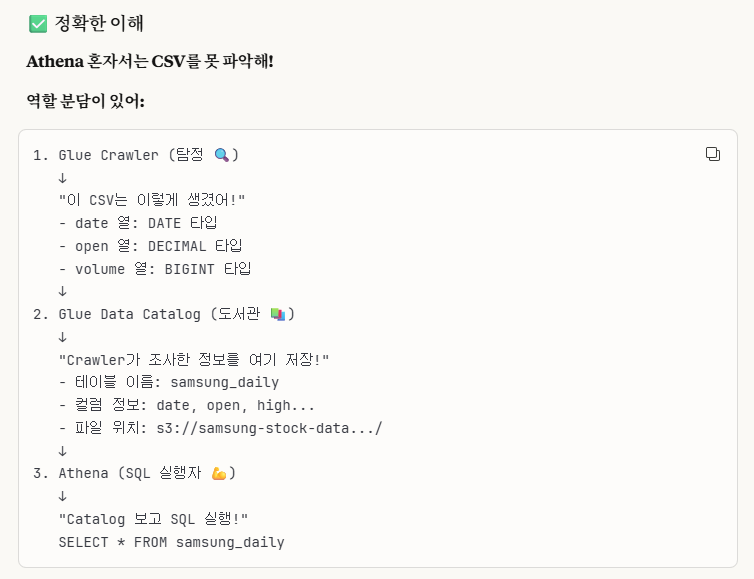

역할 분담을 세세하게 나누면 이렇게 3개로 나눌 수 있습니다.
*1. Glue Crawler: AWS Glue에 있는 crawler는 해당 파일의 메타데이터를 분석하는 역할을 합니다.
※메타데이터
'데이터에 의한 데이터', 즉, 데이터를 설명하는 정보(데이터)라고 이해하시면 됩니다.
데이터를 설명하는 정보는 configuration(구성) & setting(세팅)에 대한 정보입니다.
*2. Glue Data Catalog: Crawler가 분석한 메타데이터를 저장하는 도서관(보관소)라고 이해하면 됩니다.
*3. AWS Athena: Catalog를 보면서 SQL을 실행하는 주체입니다.
2. AWS Glue - Crawler 만들기
위 사진은 AWS Glue 메인화면입니다.
우리는 crawler를 만들어야 합니다.
왼쪽 사이드바에서 'Data Catalog' 토글을 클릭하면 하위 메뉴들이 펼쳐집니다.
거기서 Cralwers를 클릭합니다.
이렇게 나오면 잘 나온 겁니다.
'Create Crawler' 주황색 버튼을 누릅니다.
여기에는 이름만 작성하고 다음 단계로 갑니다.
여기에는 아직 우리는 Glue 테이블이 없으므로 'Not yet'으로 설정합니다.
그리고 'Data Source'를 선택해야합니다.
Data Source는 한 마디로 Crawler가 분석할 파일 경로를 말하는 것입니다.
'Add a data Source'를 클릭하면
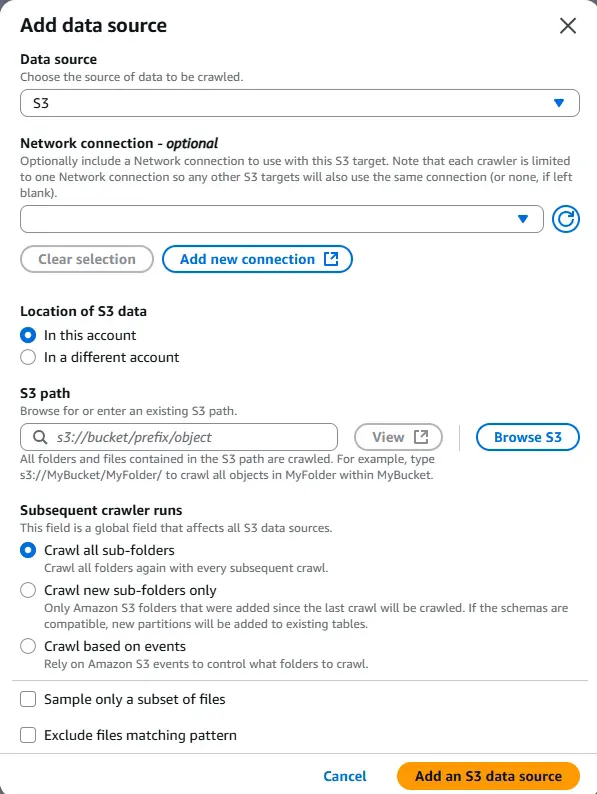
이런 화면이 뜹니다.
Data source는 우리는 S3 버킷에서 가져올 것이니 S3로 설정하고
Location of S3 data는 같은 계정에서 참고할 것이므로 'In this account'를
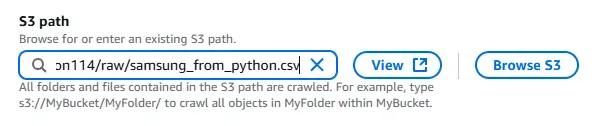
S3 path는 제가 가져오고 싶은 경로를 작성하면 됩니다.(또는 'Browse S3' 버튼으로 정하기)
※cf.) 해당 S3 Path에 관해서 후반부에 디테일하게 다룰 예정입니다.
이유는, 여기서 가장 중요한 에러가 자주 발생했기 때문입니다.




후반부에도 나오겠지만, 미리 잠깐 말하자면,
위 Claude가 답변한 것처럼 개별 파일이 아닌 폴더까지로 경로를 설정해야합니다.
아마 제 추측으로는, Glue & Athena 목적은 대용량 데이터를 처리하기 위함이라서 그렇게 설정한 거 같습니다.

근데 저는 이렇게 질문을 하며, 처음에는 개별 파일로 진행해보았습니다.

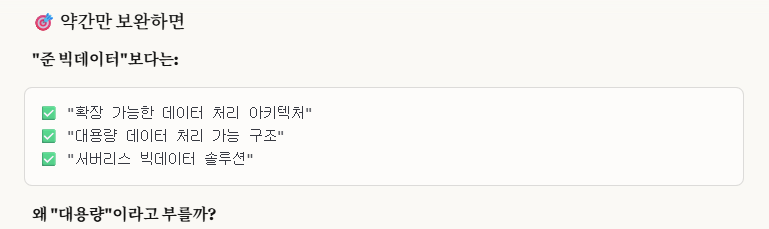
이것도 후반부에 보면 알겠지만, 폴더 안에 있는 csv들을 하나의 테이블에 합치는 경우와 그렇지 않고 개별적으로 나누는 기준이 있습니다.
무조건적으로 같은 폴더 하에 있다고 하나의 테이블에 모아서 생성하는 것이 아닙니다.
그 기준은, '같은 스키마로 작성된 파일들'이냐 입니다.
같은 스키마로 작성된 파일들은 하나의 테이블에 데이터들을 모아서 sql로 분석할 수 있게 해주고,
그렇지 않은 파일들은 개별적으로 테이블을 생성합니다.
스키마에 따른 테이블 생성
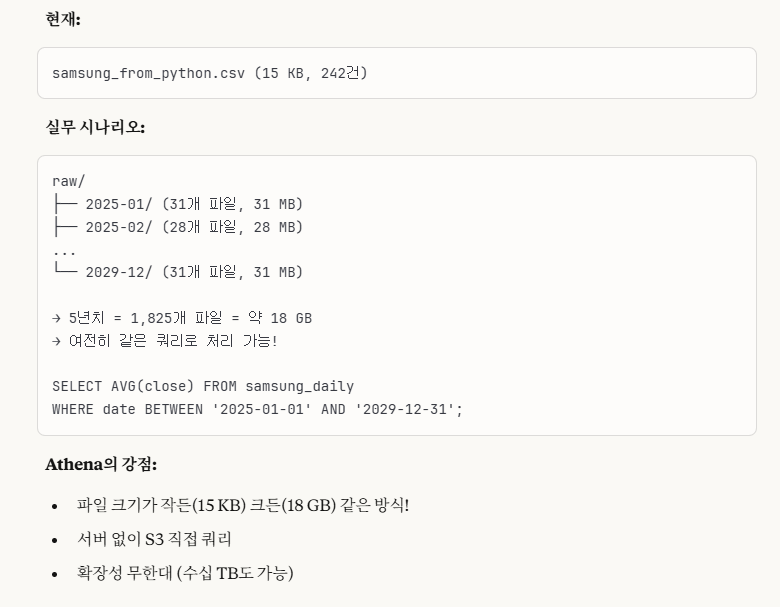
※cf.) phase 3-5가 왜 준 빅데이터를 다루는 파트인가?
Athena는 서버리스(서버 없이) 대용량 데이터 처리(SQL) 도구입니다.

cf.)만약에 S3 폴더내에 여러 형식의 파일들이 혼재되어 있다면?
Glue Crawler가 자동으로 파일 형식을 감지해서 구분하지만, 혹시나 하는 오류에 대비해서 확실하게 처리하는 것을 추천합니다.

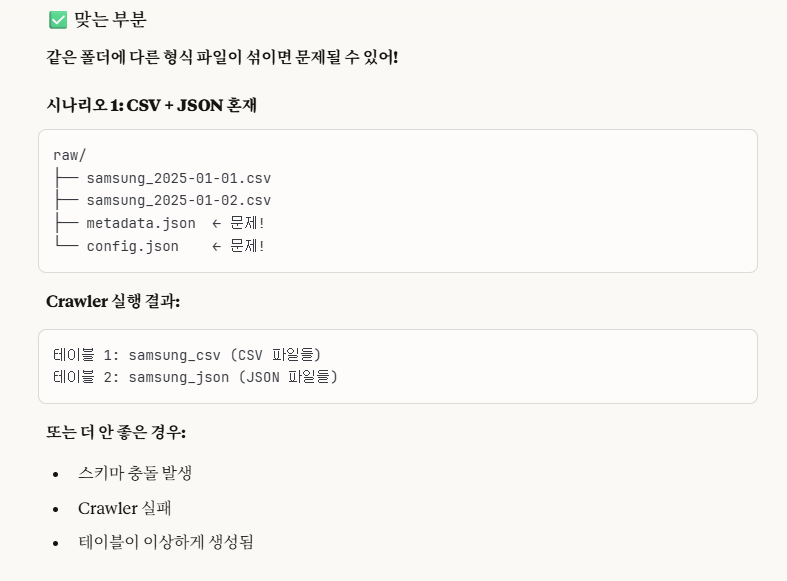
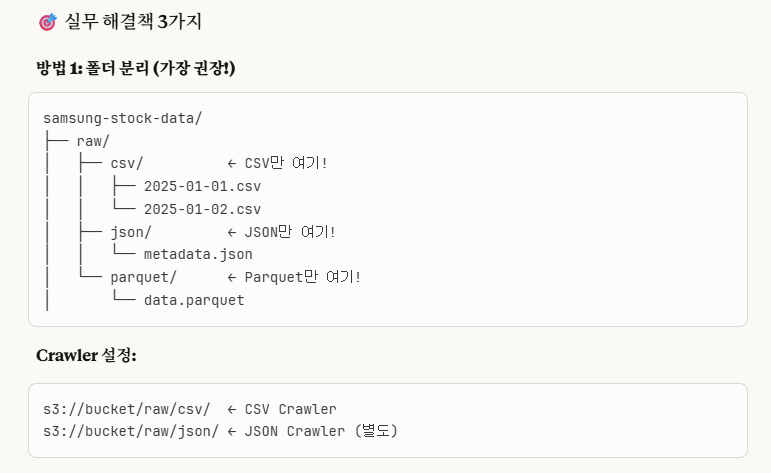

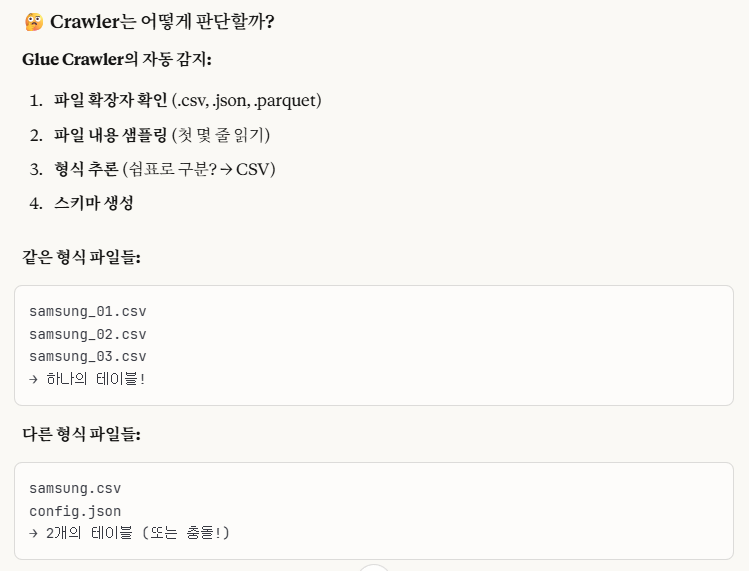
이렇게 진행해보았습니다.
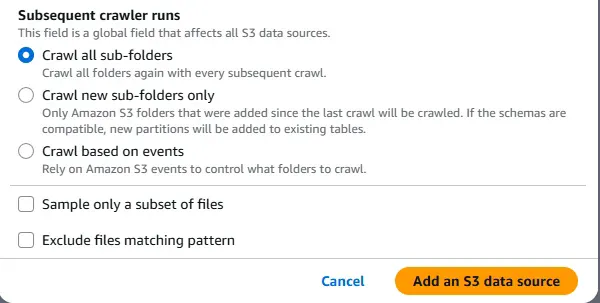
그 다음 설정은 우리가 지정한 S3 경로 안에 sub folder들을 어떻게 crawl할 것인지 설정하는 부분입니다.
사실 눈썰미가 좋으신 분들은 여기서 눈치 채셨을 수도 있습니다.
'왜 굳이 sub folder 설정이 있지?'
그리고 바로 위 S3 Path 경로 설정하는 부분에서 밑에 조그만한 글씨로 영어로 써져있는 부분을 확인하면,
'All folders and files contained in the S3 path are crawled.' 라는 말을 보면,
('S3 버킷 경로에 포함된 모든 폴더들(sub folders)과 파일들이 crawl(크롤링, 단어 자체의 의미는 '긁어내다.' 입니다. 즉, 데이터를 긁어오는 것입니다.)합니다.)
'음.. 이거 폴더 단위로 경로를 설정해야하나?'라는 생각이 드실 수 있습니다.

그럼에도 불구하고 저는 개별 파일로 진행하였습니다.
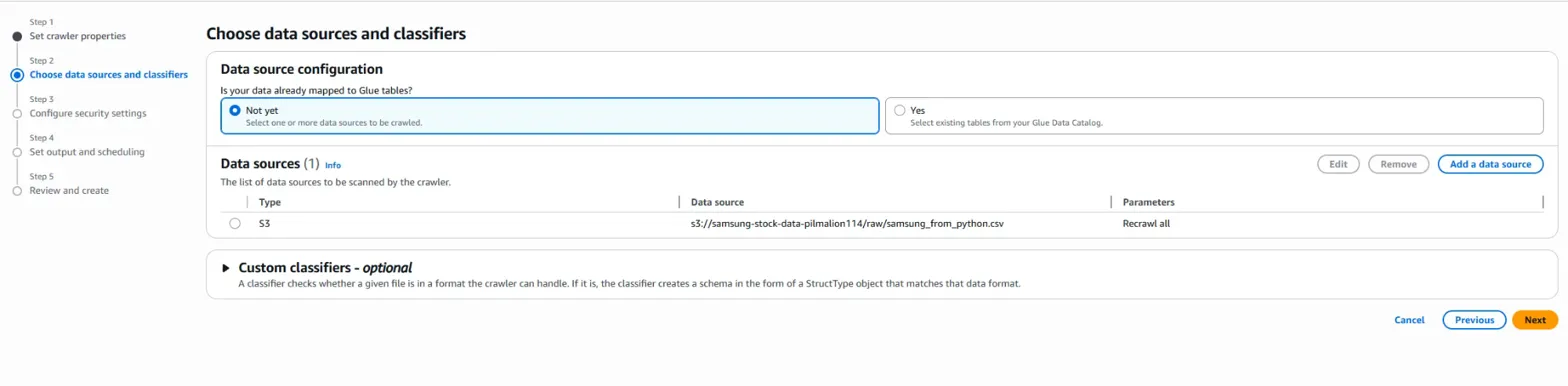
이제 step 2 설정이 끝나고 step 3 설정으로 넘어갑니다. -> 폴더로 경로 설정해서 본격적으로 문제 해결하기 -> 이 부분이 본격적으로 오늘 게시글의 key 문제점을 해결하는 부분입니다!
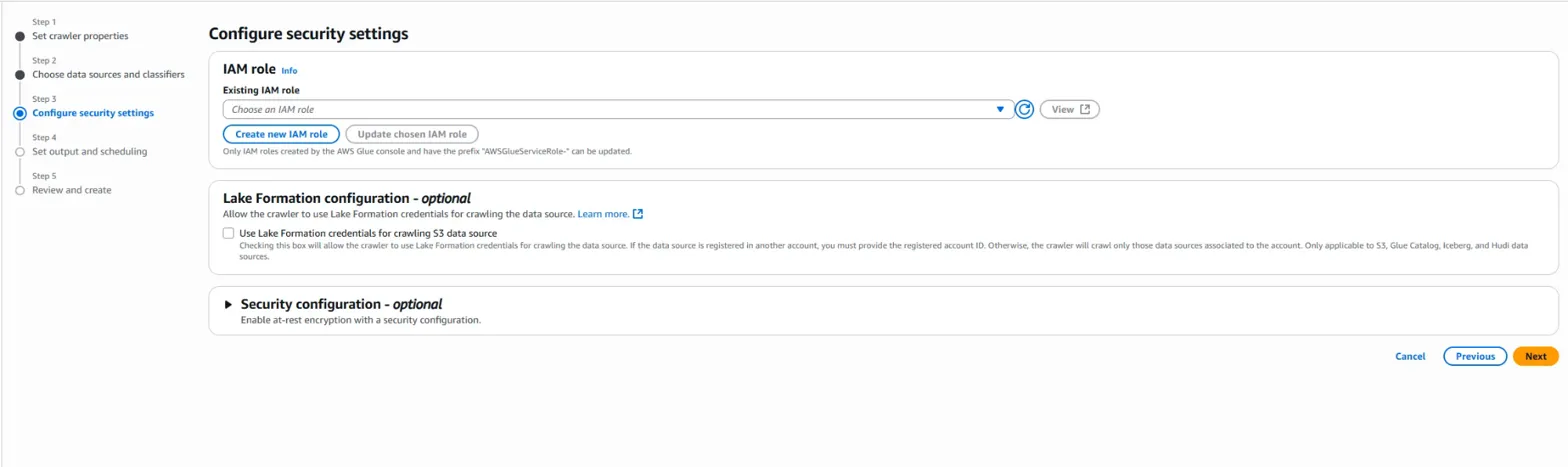
IAM 설정 부분입니다.
IAM은 전 게시글에서도 나왔었죠.
신원 권한 설정을 통해서 보안 설정을 하는 부분입니다. 한 마디로, 권한 설정입니다.
'Create New IAM role' 버튼을 누르면,
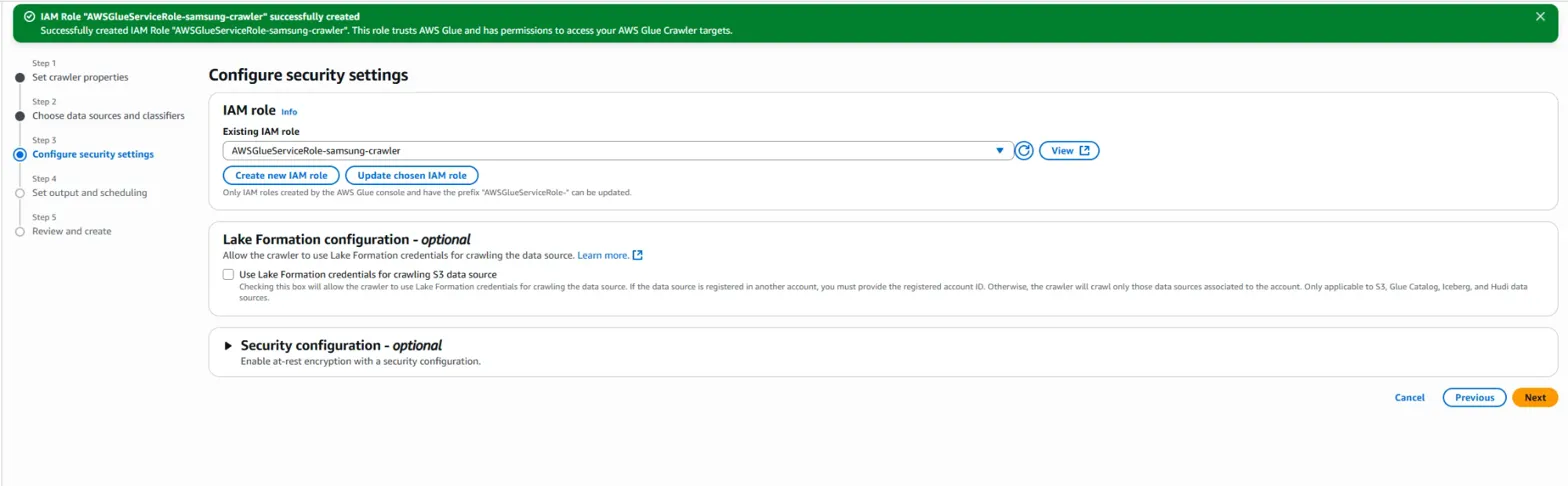
이렇게 이름을 짓고 설정 완료하면 됩니다.
(사실 이 부분에서도 제가 놓친 추가 권한 설정 부분이 있습니다. 뒷 부분에서 또한 설명을 하도록 하겠습니다.) - IAM Role 권한 추가하기
그 다음은 step 4로 넘어갑니다.
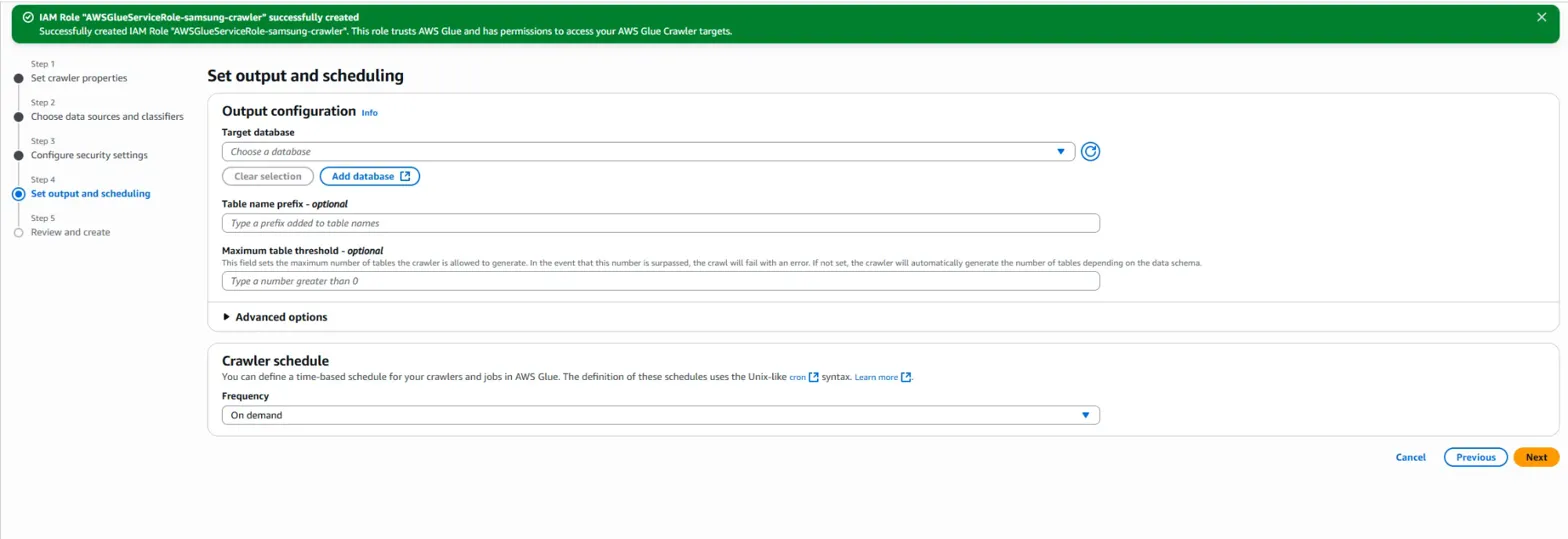
여기서는 'Target database' 설정이 중요합니다.
하지만 우리는 해당 Glue 서비스 내에는 데이터베이스를 생성한 것이 없죠.
그래서 새로운 database를 생성해야합니다.
'Add database' 버튼을 누르고,
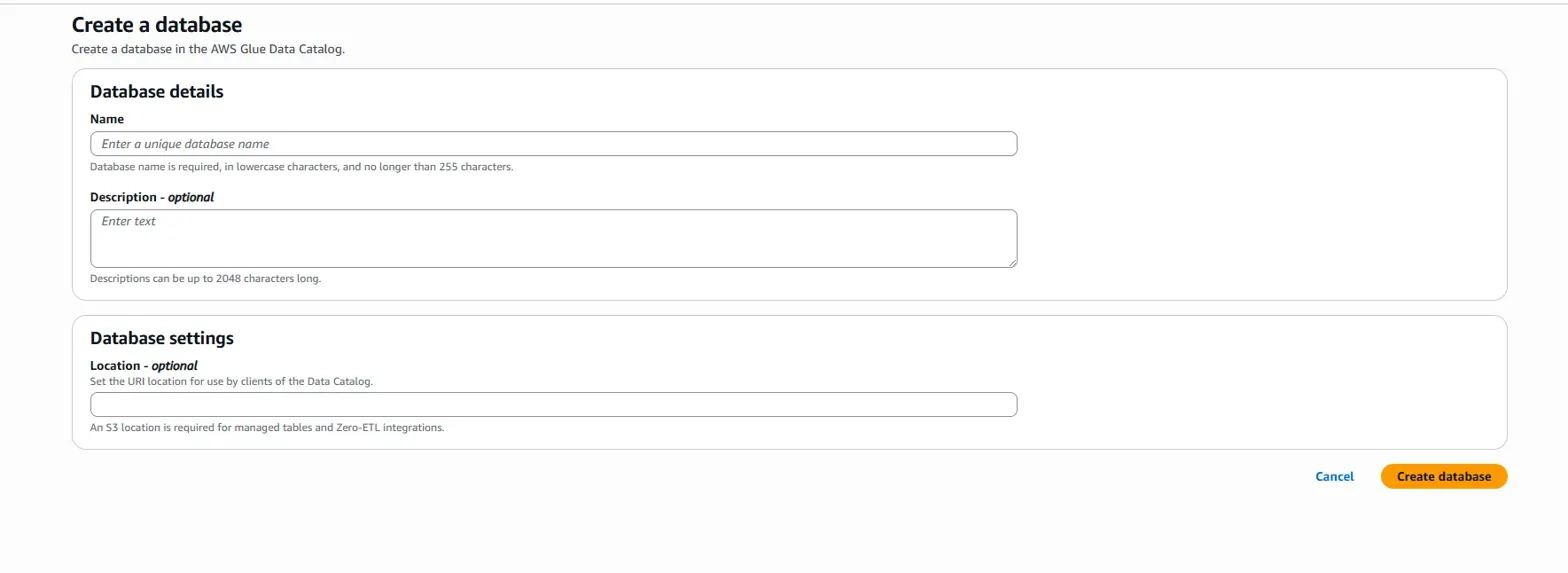
Name에 'samsung_athena_db'로 설정하고 데이터베이스를 생성합니다.
(예전에 만든 'samsung_stock_db'와 구분하기 위해 이름을 이렇게 설정함.)
나머지 설정 부분들은 기본값으로 그대로 두고 생성합니다.
그 다음은 step 5입니다.
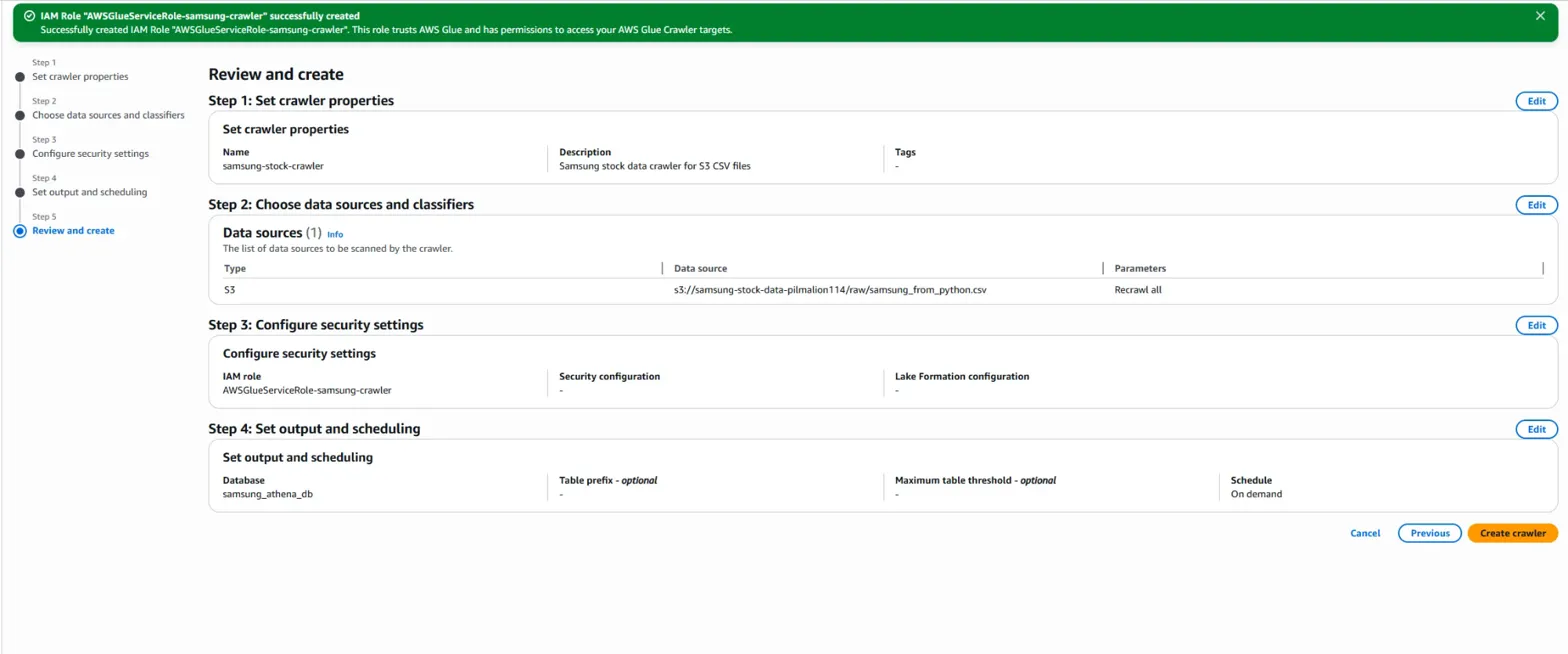
최종 설정 확인 부분입니다.
제대로 잘 설정되었는지 확인하고 'Create crawler' 주황색 버튼을 눌러 crawler를 생성합니다.
이렇게 나오면 잘 나온 것입니다.
3. AWS Glue - Run Crawler
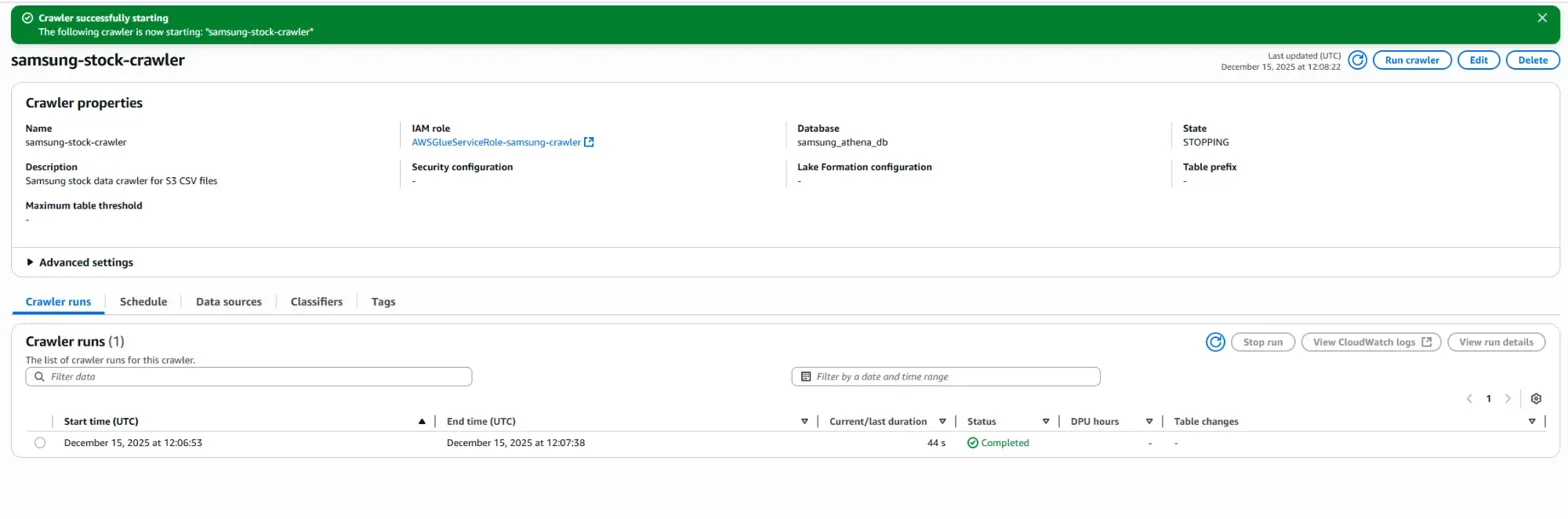
맨 위 오른쪽에 'run crawler' 버튼을 눌러 크롤링을 진행합니다.
밑에 Crawler runs에 진행상황 표시가 나옵니다.
새로고침을 통해 진행상황을 파악하는 것을 추천합니다.(자동으로 상태 업데이트가 잘 되지 않습니다.)
하지만 여기서 문제점이 발생했습니다.
바로, 'table changes'에 아무런 변화 정보가 없다는 것입니다.
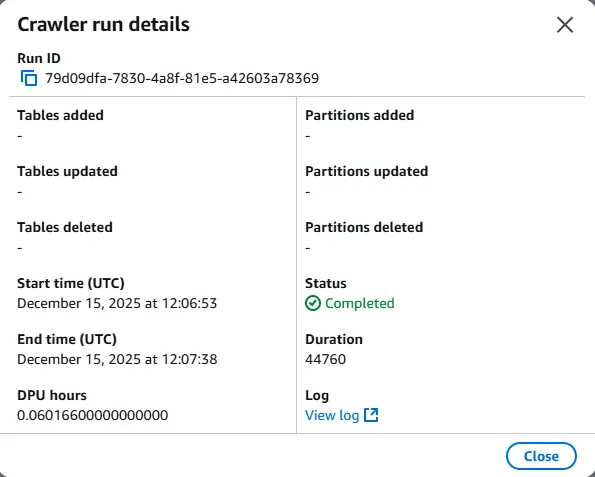
'View run details'를 통해 보더라도 tables added에 정보가 없음을 알 수 있습니다.

실제 왼쪽 사이드바의 tables 메뉴에 들어가도 생성이 안 됐음을 알 수 있습니다.
3-1. 문제 원인 찾기

이렇게 우리가 앞에서도 말했듯이, 개별 파일로 경로 설정한 게 문제라서 그런가 하고
경로 설정을 개별 파일 -> 폴더로 변경해보았습니다.
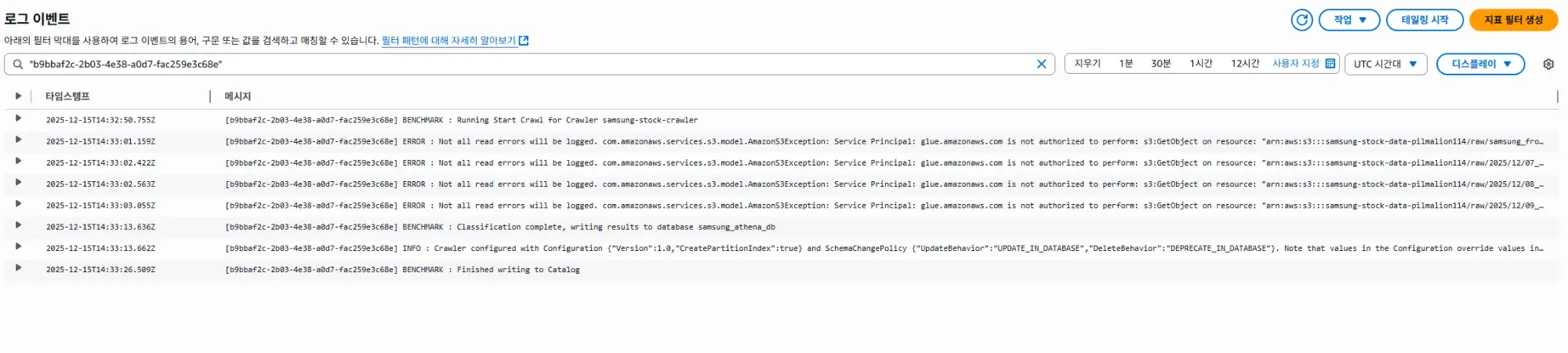
그러자 이렇게 에러가 나왔습니다.
[b9bbaf2c-2b03-4e38-a0d7-fac259e3c68e] ERROR : Not all read errors will be logged. com.amazonaws.services.s3.model.AmazonS3Exception: Service Principal: glue.amazonaws.com is not authorized to perform: s3:GetObject on resource: "arn:aws:s3:::samsung-stock-data-pilmalion114/raw/samsung_from_python.csv" because no identity-based policy allows the s3:GetObject action (Service: Amazon S3; Status Code: 403; Error Code: AccessDenied; Request ID: MAEJQE2Q8M44PKVE; S3 Extended Request ID: /eCdMdby+aUM9gsC+z6lKtXX2P2BU42knPkWav1OuESP2yuUNNY+zm9bslI8r8kTC3PiOEigFkLko0/tttioDRPMyOTngg26; Proxy: null), S3 Extended Request ID: /eCdMdby+aUM9gsC+z6lKtXX2P2BU42knPkWav1OuESP2yuUNNY+zm9bslI8r8kTC3PiOEigFkLko0/tttioDRPMyOTngg26위 문제는 IAM ROLE 권한 부족입니다.
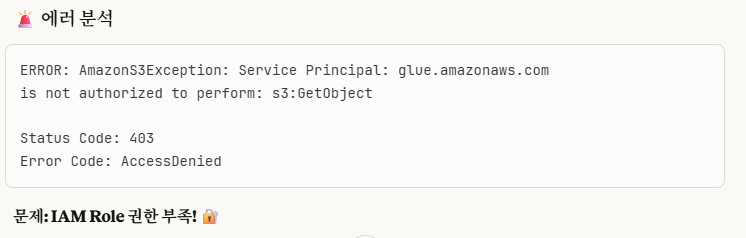
3-2. IAM 권한 추가하기


우리는 이렇게 IAM 콘솔로 이동해서 해당 Role에서 권한을 추가해야합니다.
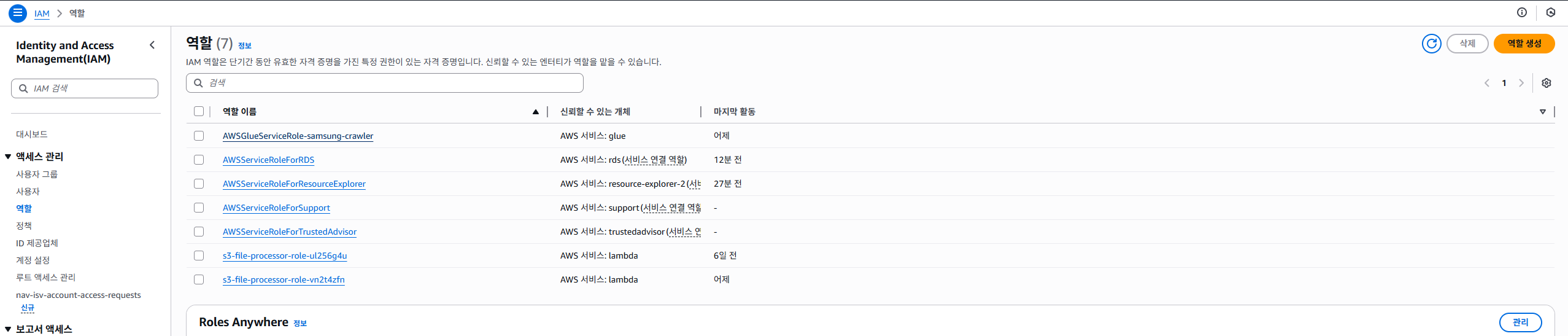
왼쪽 사이드바 메뉴에서 '역할' 버튼을 눌러서 우리의 Role(맨 위에 위치한 role)을 선택합니다.
그러면 다음과 같은 메인화면이 나옵니다.
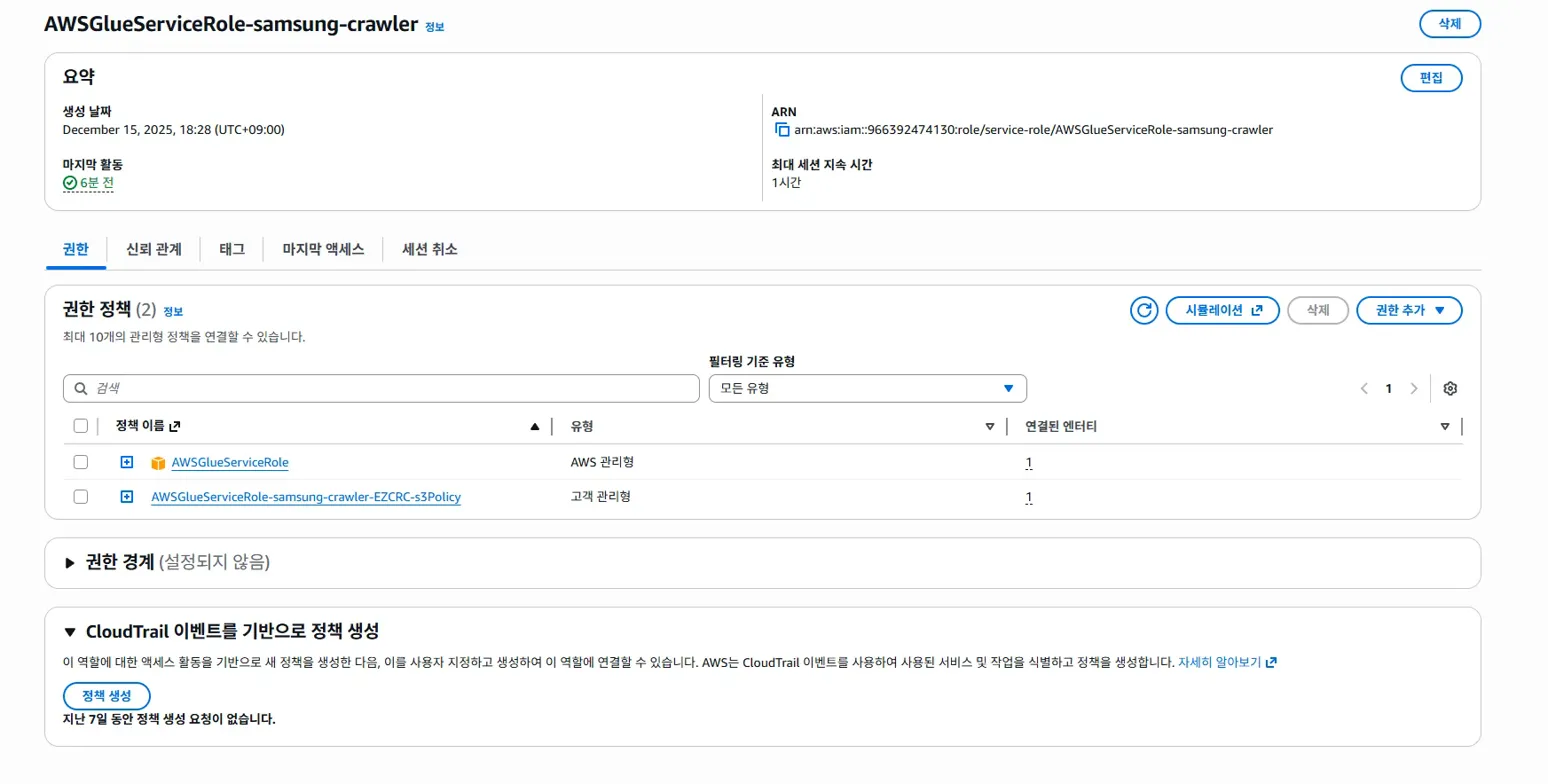
우리는 이미 만든 Role에 권한 추가를 해야합니다.
오른쪽 버튼인 '권한 추가'를 누르면 토글 형식으로 나오는데,
여기서 '인라인 정책 생성' 버튼을 누릅니다.
'서비스 선택'에서 S3를 선택합니다.
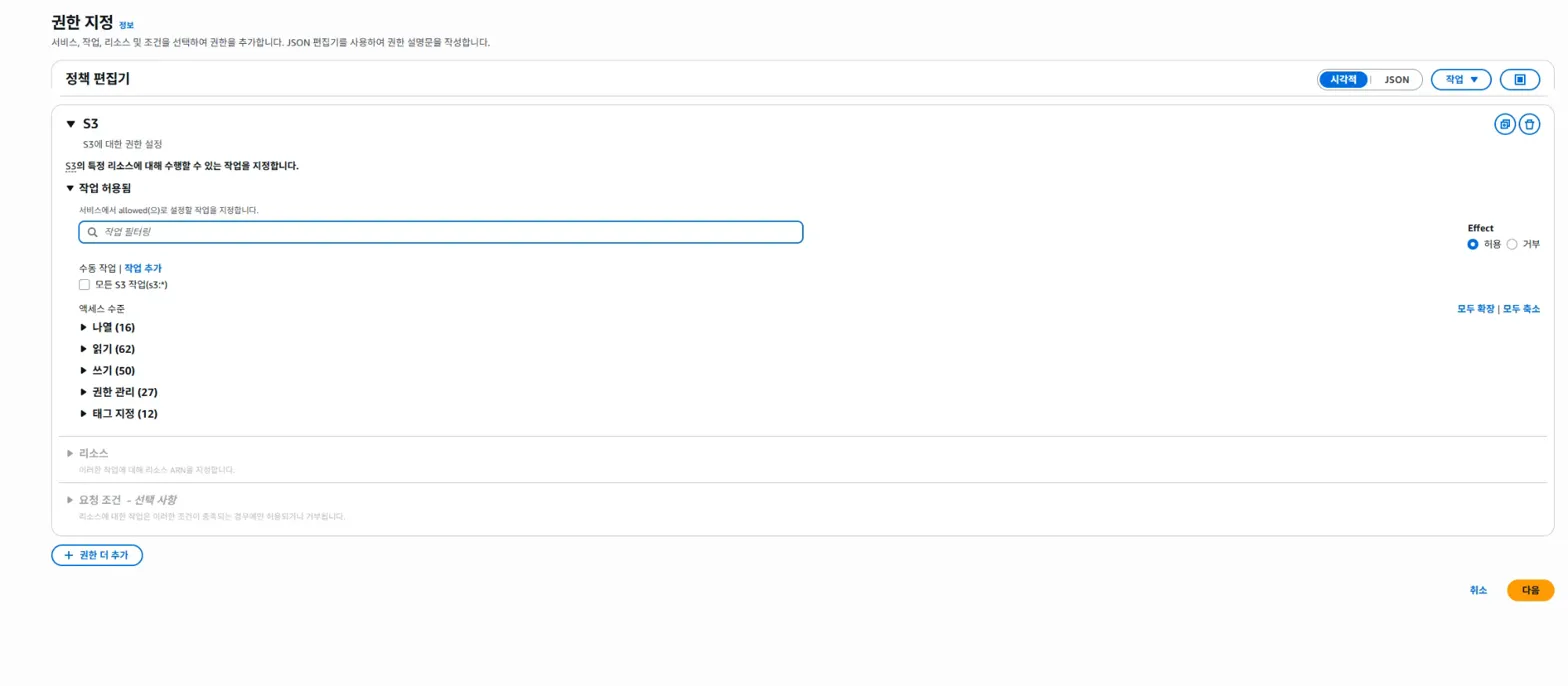

우리가 추가해야 할 권한은 2가지 입니다.
읽기 토글에서 'Getobject(파일 읽기)'를, 나열 토글에서 'ListBucket(버킷 안에 있는 파일 목록들 보기)'를 선택해서 활성화시켜줍니다.

그 다음은 '리소스' 탭에서 추가 설정을 해야합니다.
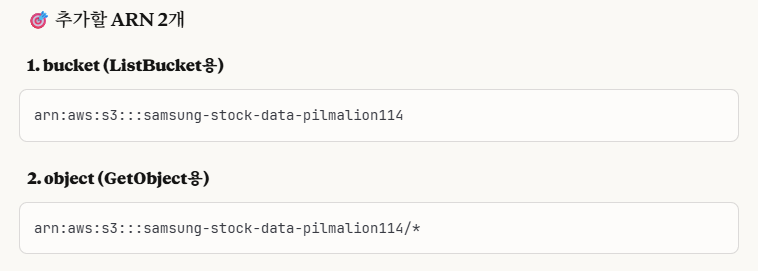
arn:aws:s3::: ...~ 이 경로에다가 해당 경로를 그대로 입력하면, 알아서 parsing해서 적용해줍니다.

그 다음은 정책 이름을 입력하면 완성입니다.
(정책 이름: samsung-s3-access-policy)
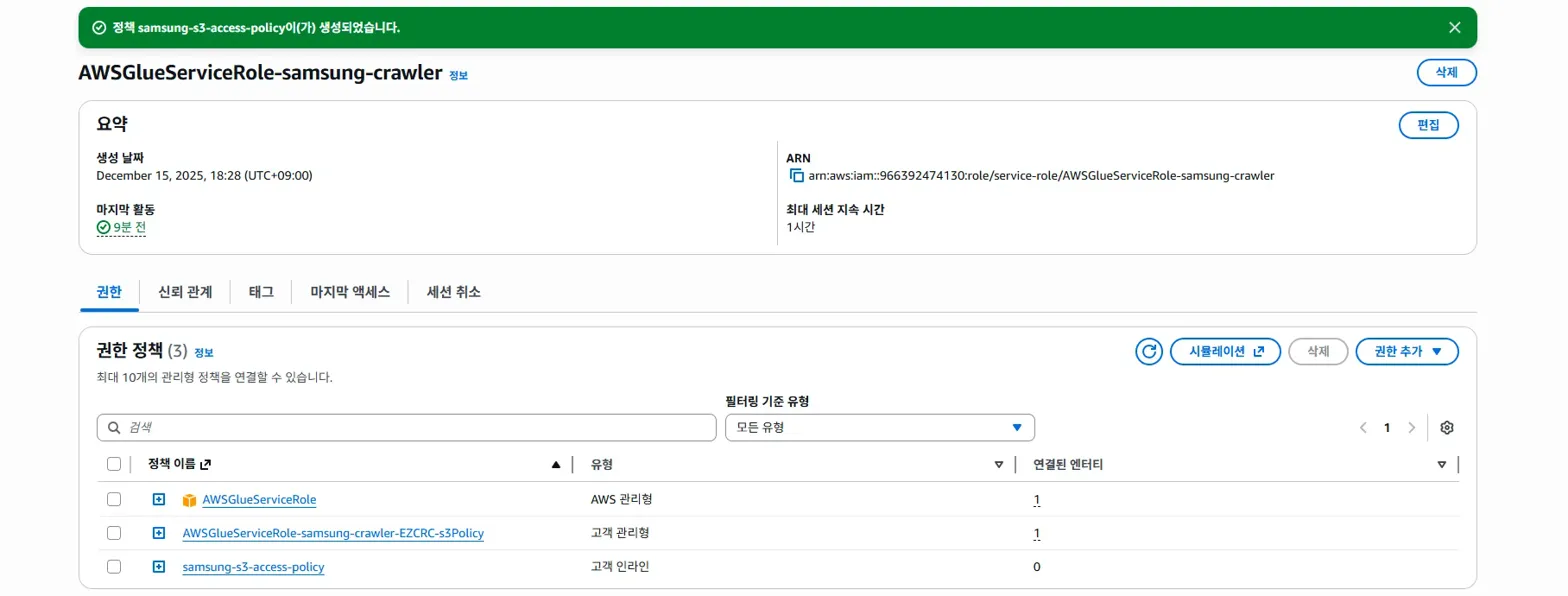
그럼 이렇게 '고객 인라인'으로 권한 추가가 되었음을 확인할 수 있습니다.
※인라인 정책(Inline Policy)란?
즉, 인라인 정책은 개별 맞춤 출입증(권한증)이라고 이해하면 됩니다.


3-3 다시 S3 경로를 폴더 -> 개별 파일로 진행.
저는 이 때는 인라인 정책 권한 설정이 문제인지 알고 다시 폴더 -> 개별 파일로 경로를 변경해 진행했습니다.

이렇게 1 table change라는 표시를 보고 정상 작동되는지 알았습니다.
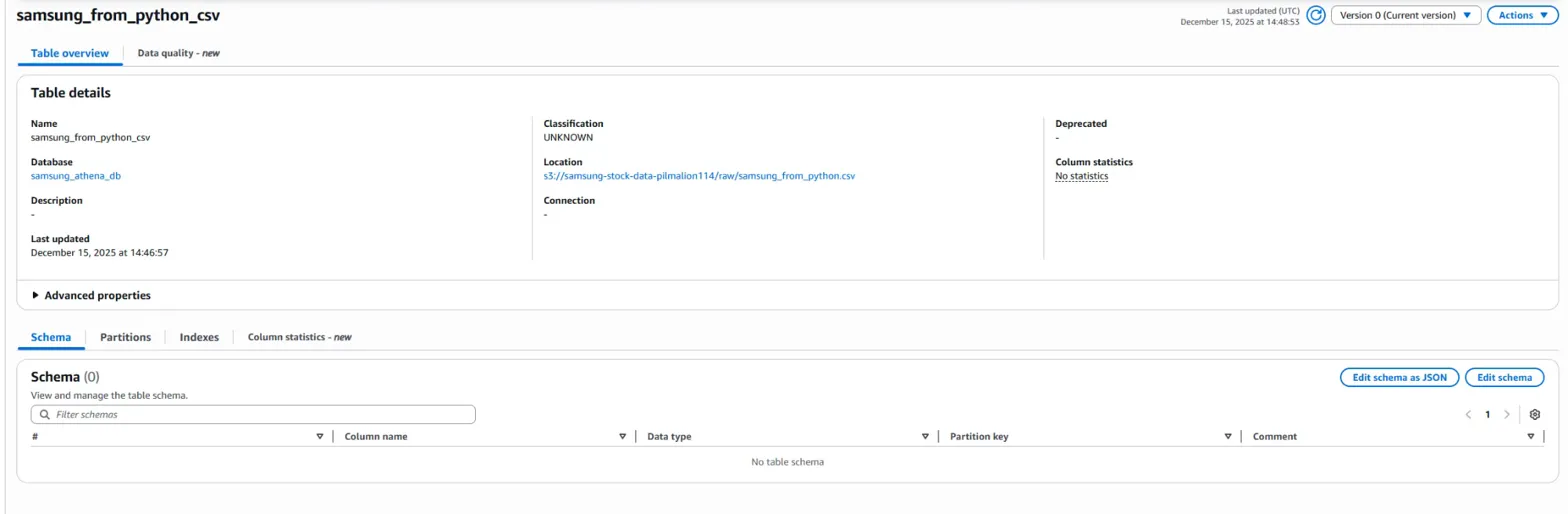
하지만 table 메뉴를 직접 클릭하여 해당 테이블을 확인해봤더니 Schema가 없었습니다.
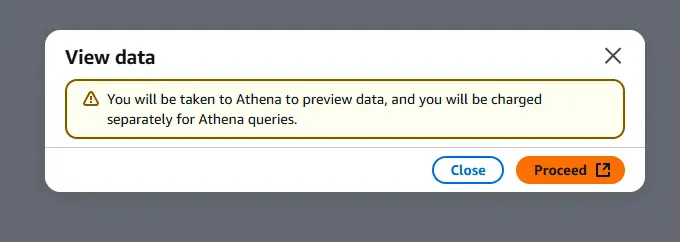
(과금될 수 있다는 문구인데, 우리 파일은 1개 밖에 없으므로 사실상 무료이니, 그냥 진행합니다.)
'View Data'에 있는 'Table Data' 파란색 링크를 눌러서 Athena에서 직접 확인을 해보았는데도 없었습니다.
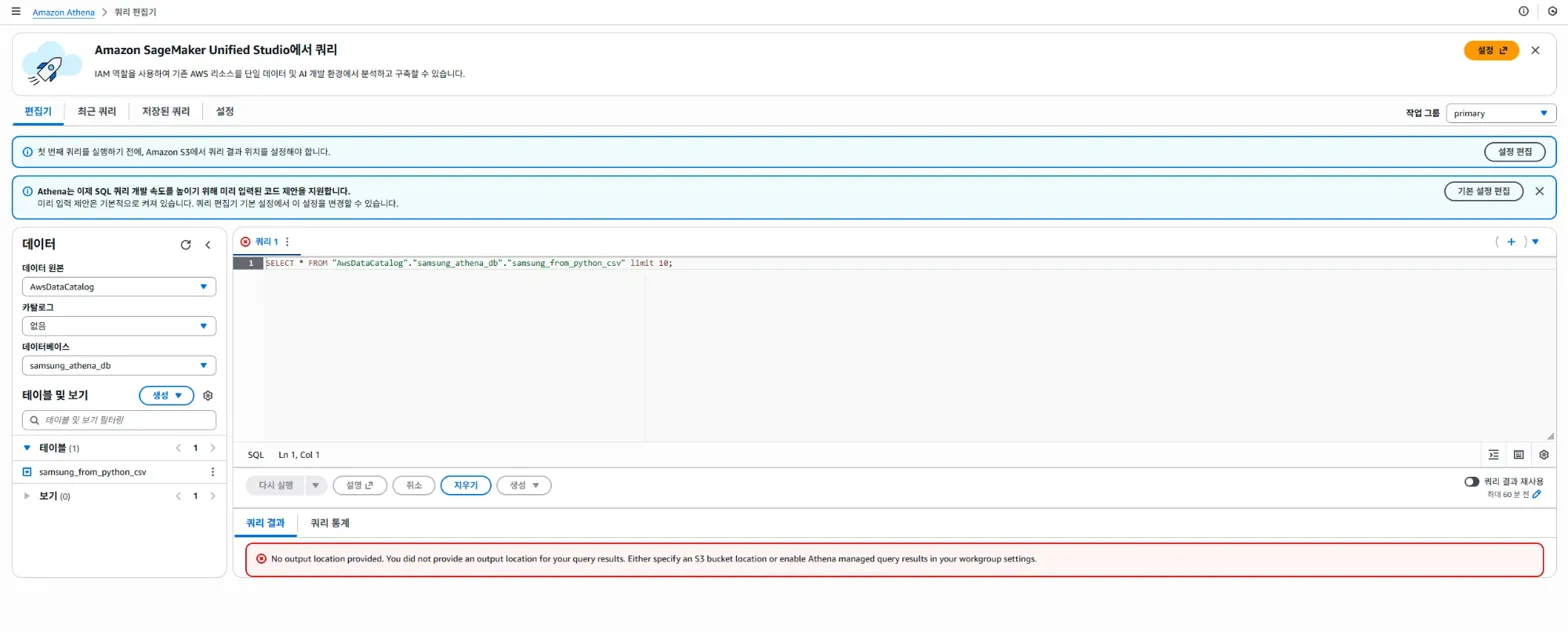
3-4. Athena 쿼리 에디터에서 문제 해결하기
바로 위 첨부한 사진을 참고하면,
맨 밑에 빨간색 표시로 에러가 뜬 것을 확인할 수 있습니다.


Athena는 쿼리 결과를 S3에 저장해야 하는데, 우리가 그 설정을 안 해서 이런 오류가 뜬 것입니다.

저는 Browse 모드로 진행하려했는데, 우리는 'athena-results/'라는 폴더가 없습니다.

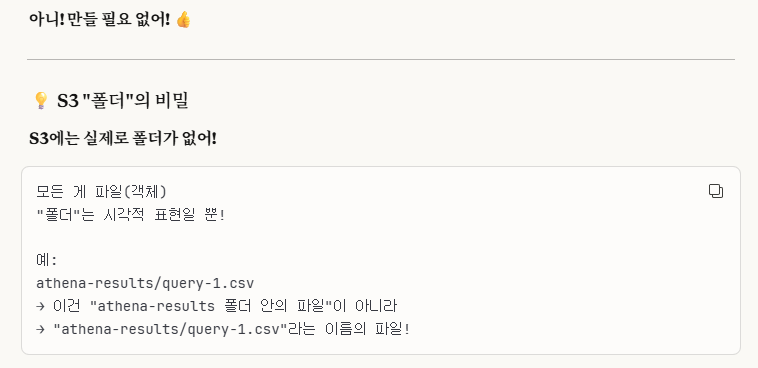
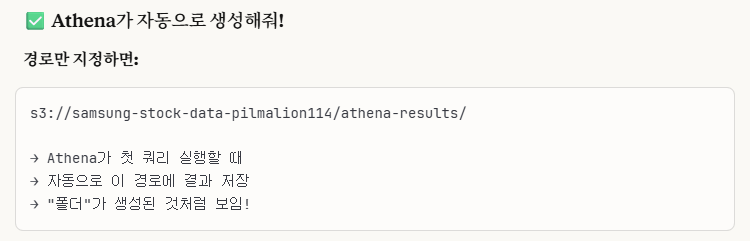
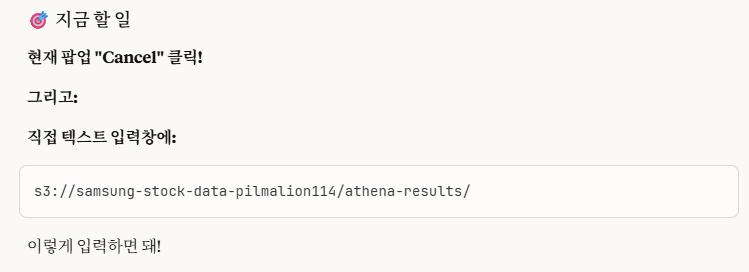
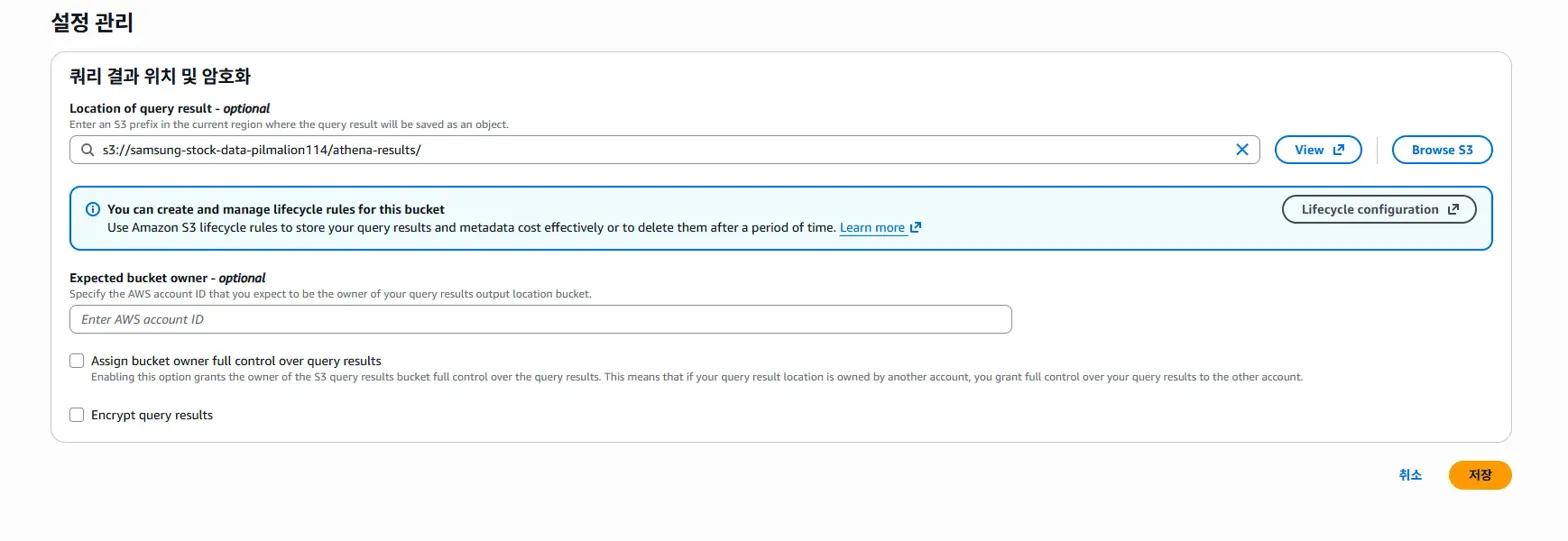
이렇게 경로를 직접 입력해주고, 나머지 설정값들은 default로 두고 저장합니다.
설정을 완료하고, 다시 athena 편집기로 돌아가서
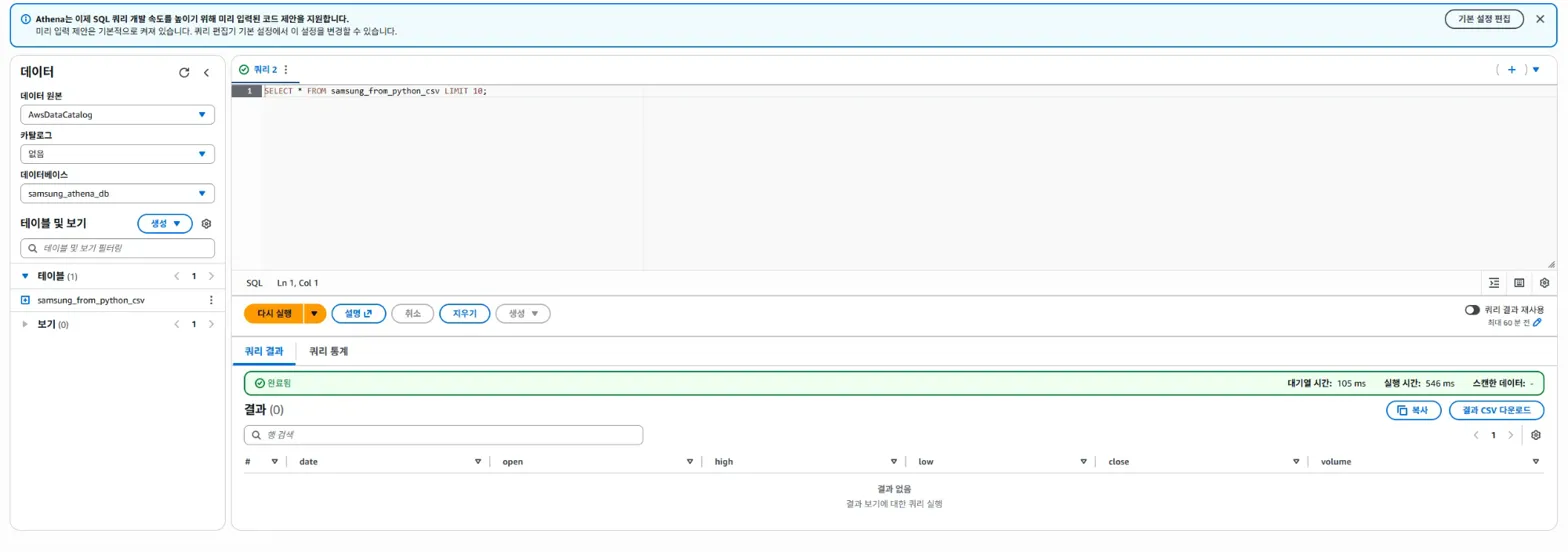
SELECT * FROM samsung_from_python_csv LIMIT 10;해당 쿼리를 다시 실행해보았으나,
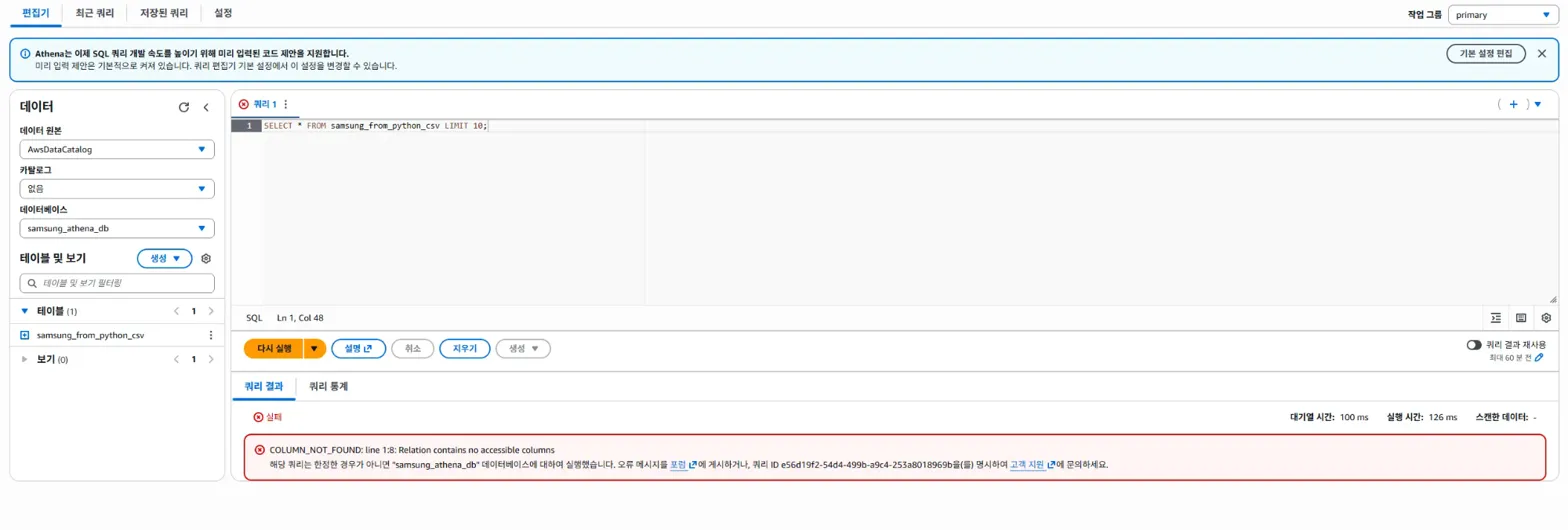
이런 오류가 또 발생했습니다.
3-5. No table Schema 문제
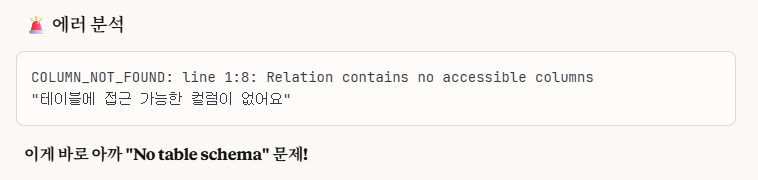
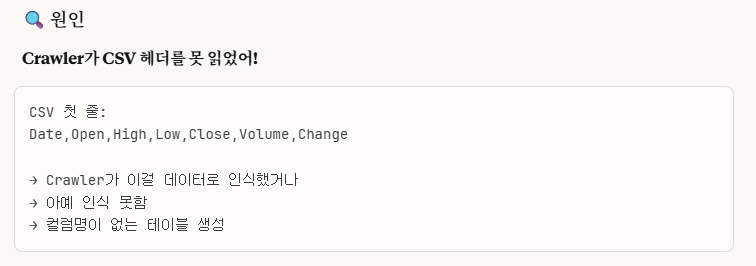

먼저 저는 '방법 1'로 진행해보았습니다.
방법 1. classifier 추가하기

진행 순서는 이렇게 됩니다.
Glue 콘솔로 돌아와서, classifier 탭에 들어갑니다.

우리는 classifier가 없으므로, 새로운 classifier를 추가합니다.
※classifier(분류기) vs Delimiter(구분기)



'Add classifier' 버튼을 누르고,
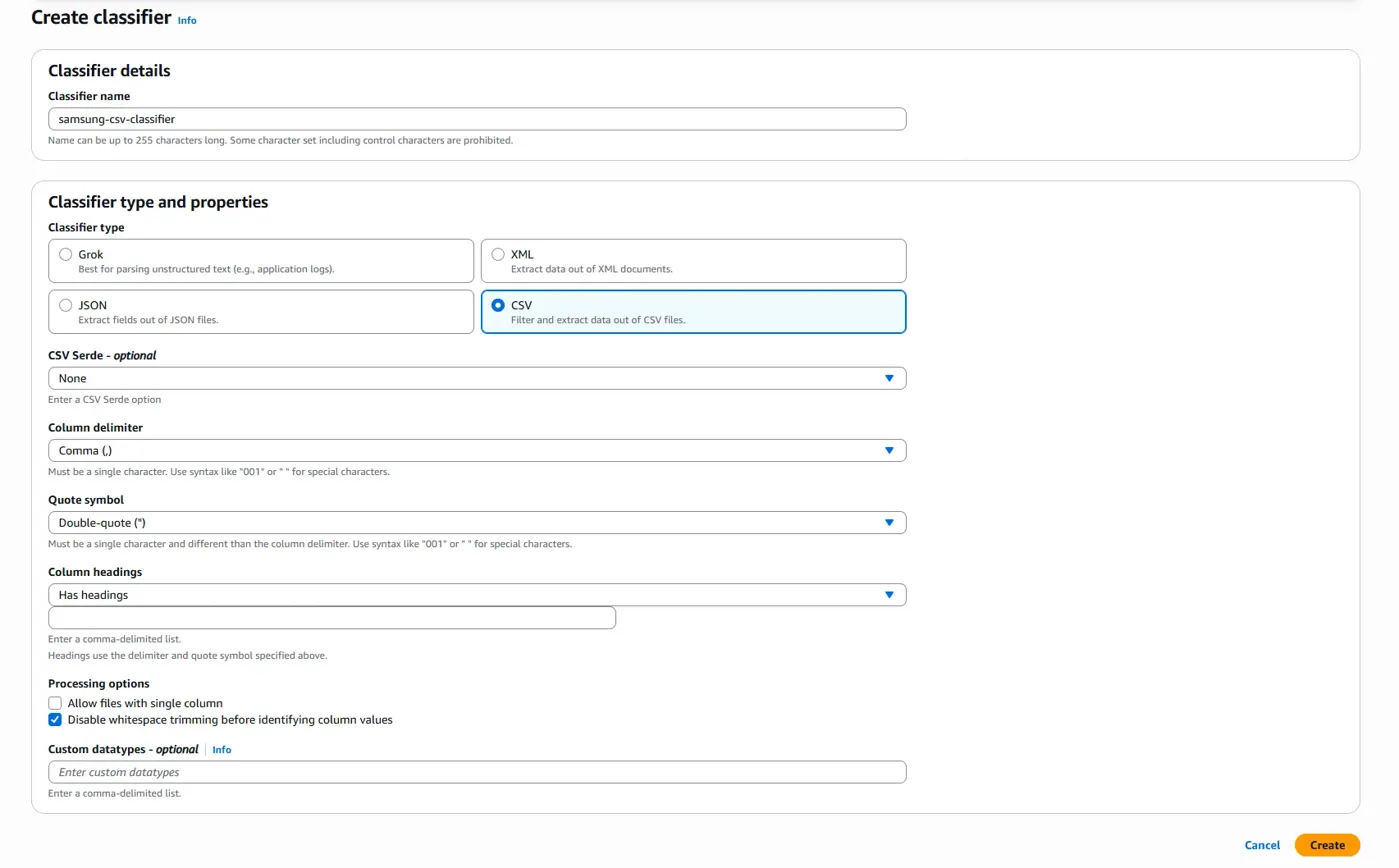
이렇게 설정합니다.
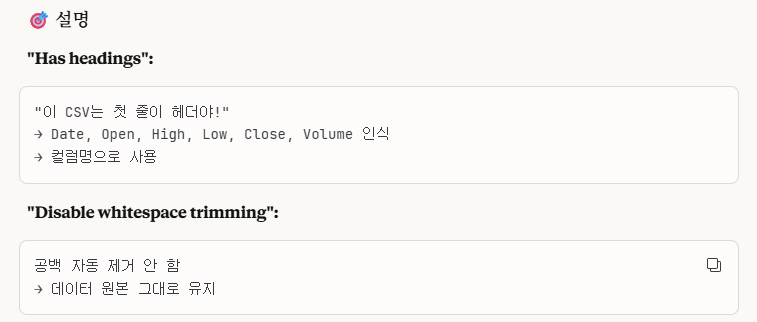
그리고 'create' 버튼을 눌러서 생성합니다.
그 다음은 Classifier 탭에서 우리가 방금 만든 classifier를 추가하면 됩니다.
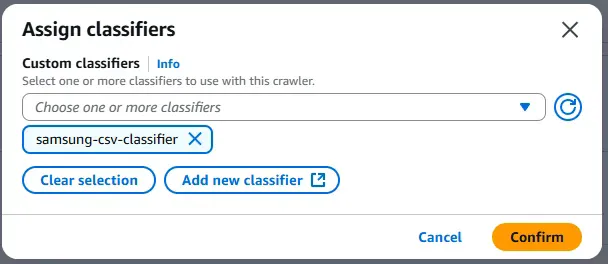
그 다음 Crawling을 한번 다시 시도합니다.
기존에 만든 테이블은 삭제 후 진행해줍니다.
(삭제를 안하고 진행하면 table change 정보에 변화가 없다고 뜹니다.)

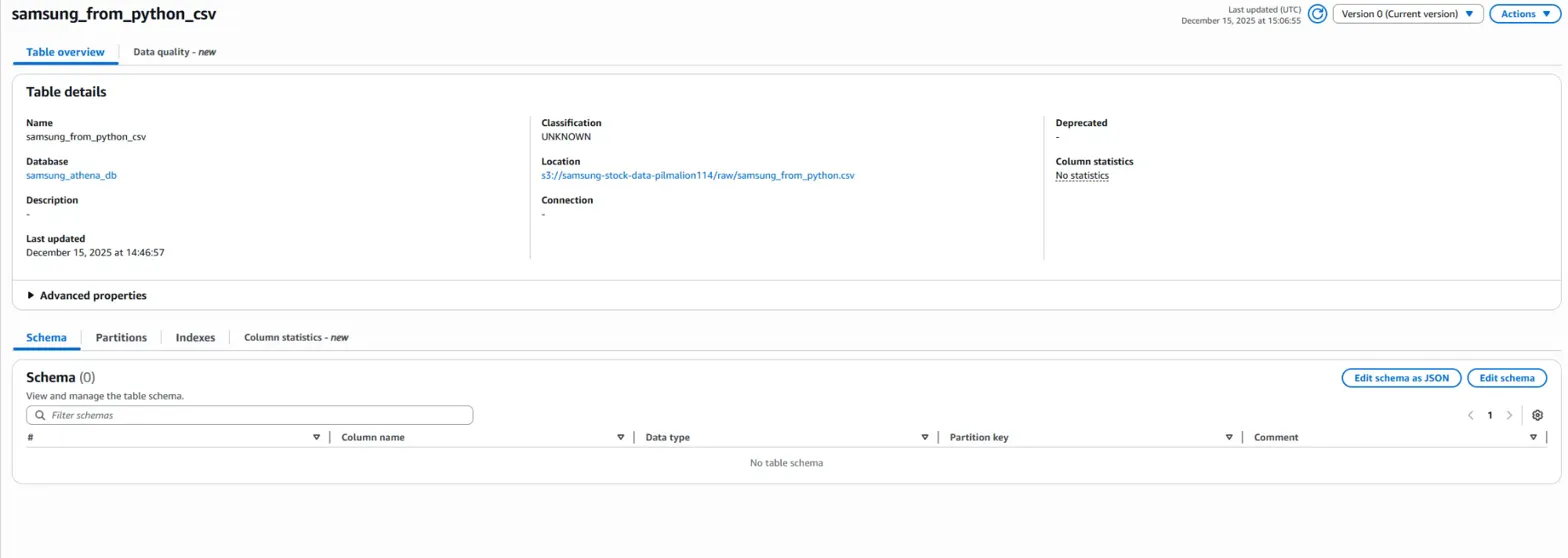
하지만 그럼에도 schema는 생기지 않았습니다.
방법 2. 직접 스키마 수동 작성하기
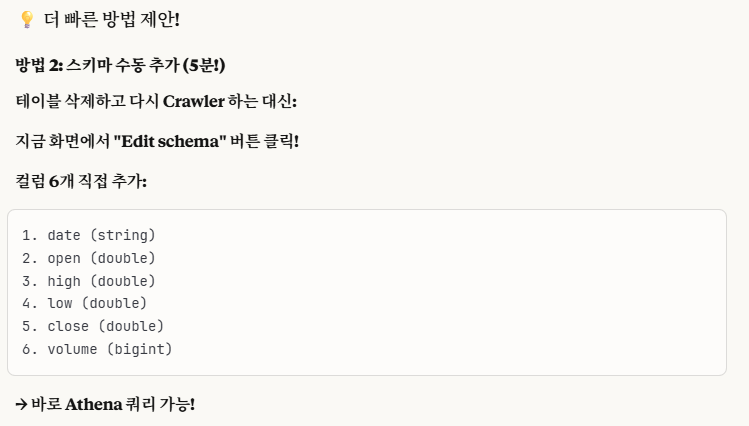
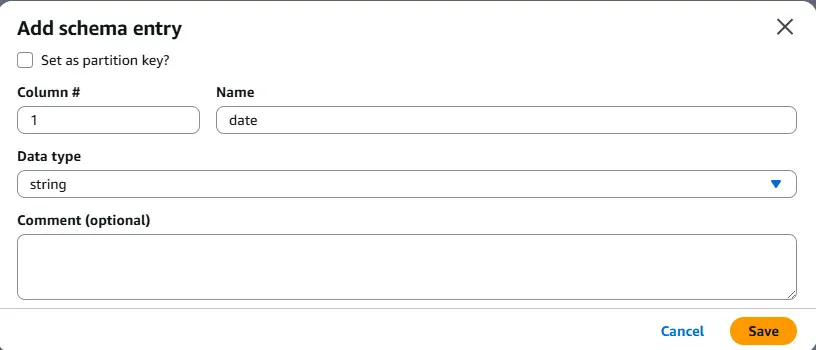

이런식으로 작성하면 됩니다.
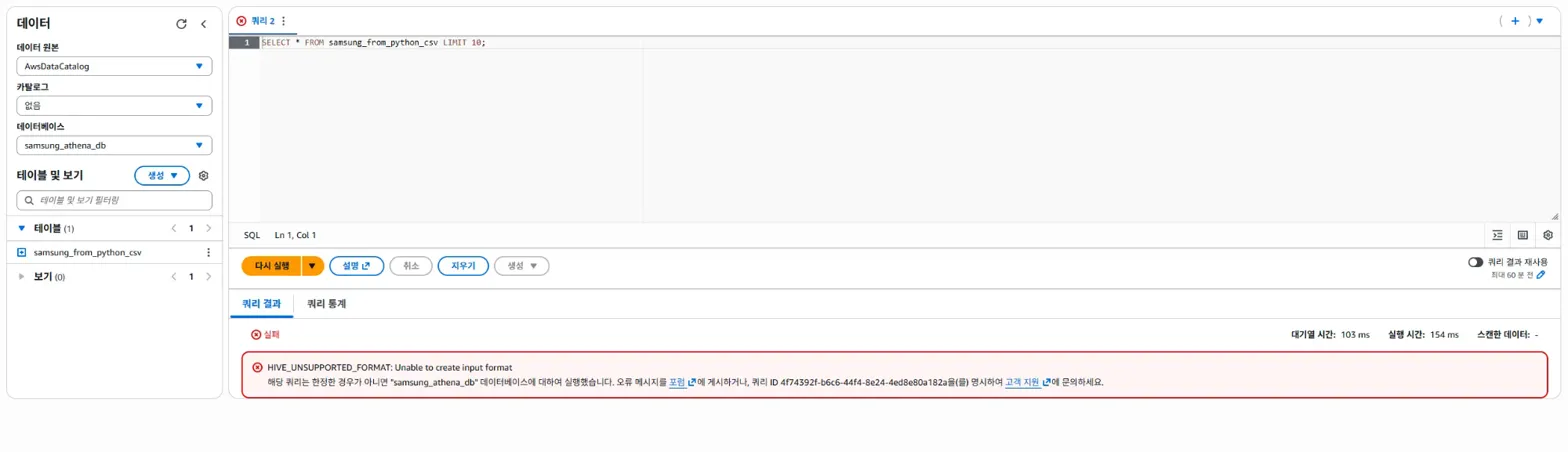
하지만, 또 다른 문제가 발생했습니다.
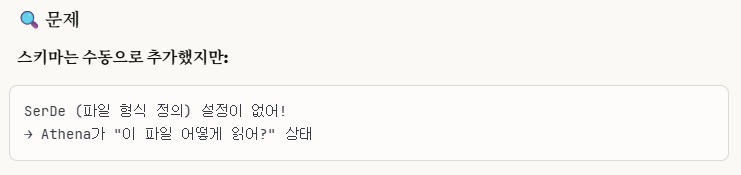
3-6. BOM Encoding 문제
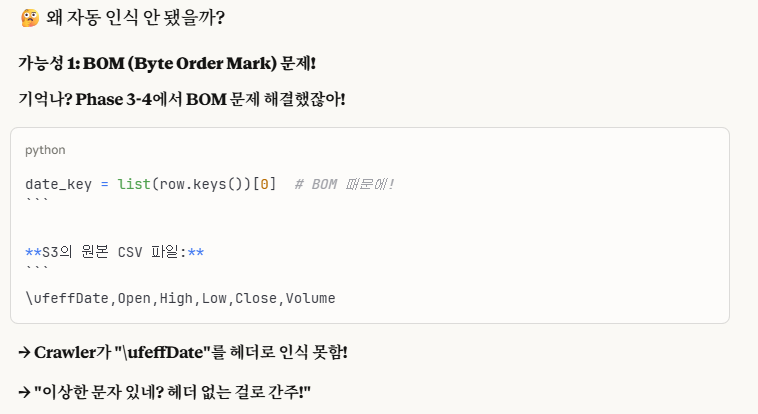
저는 이렇게 'BOM Encoding' 방식이 문제인 거 같아서, Crawler가 헤더를 인식 못하는 게 문제라고 생각했습니다.
이에 대한 해결책으로는 기존에 있는 csv 파일이 아닌 새로운 csv 파일을 생성하는 것입니다.
하지만, 이렇게 해결하기에 앞서서 먼저 다른 방식으로 해결하고자 하였습니다.
3-7. Serde 설정 추가하기
※사실 이 부분도 후반부에 보면 알겠지만, 이 설정 추가 부분이 문제 해결의 key point는 아닙니다.
이런 설정을 우리가 직접 설정해서 맞추는 것보다 S3 경로 설정 및 S3 파일 구조를 명확하게 설정을 한다면, 이 문제는 자동으로 해결됩니다.

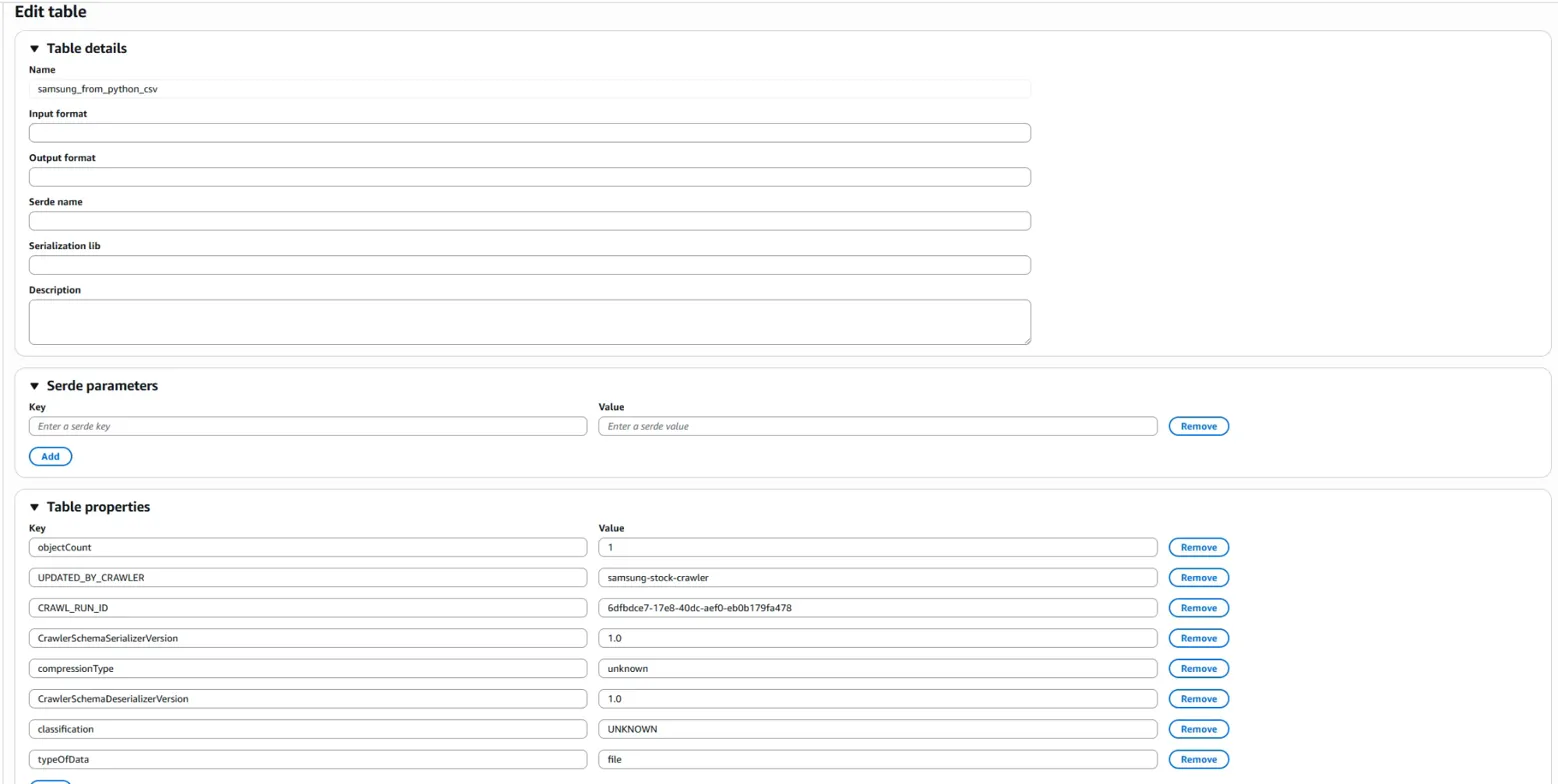
해당 edit table에서 다음과 같이 설정을 해줍니다.
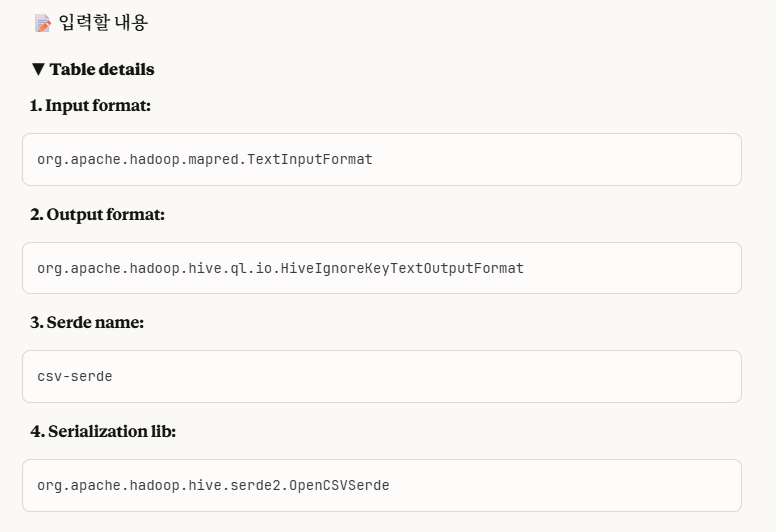

이 각각의 설정에 대해서 개념 설명을 하도록 하겠습니다.
1. Input Format
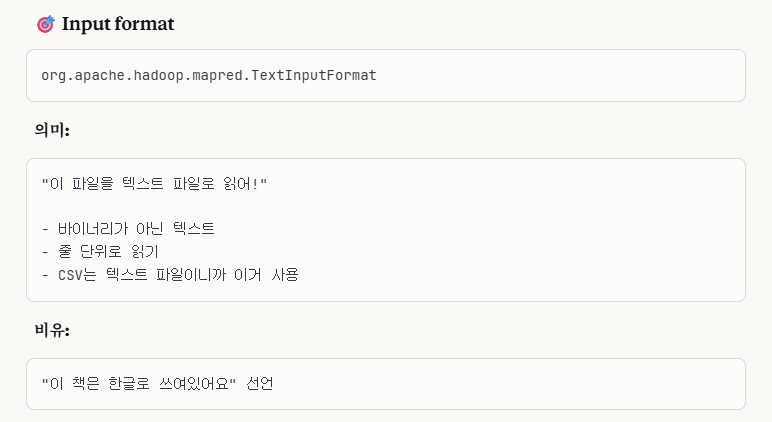
바이너리(0,1)로 읽지 않고, 줄 단위 텍스트로 읽어서 처리하는 방식입니다.
CSV 같은 텍스트 파일은 이 포맷을 사용합니다.
2. Output Format
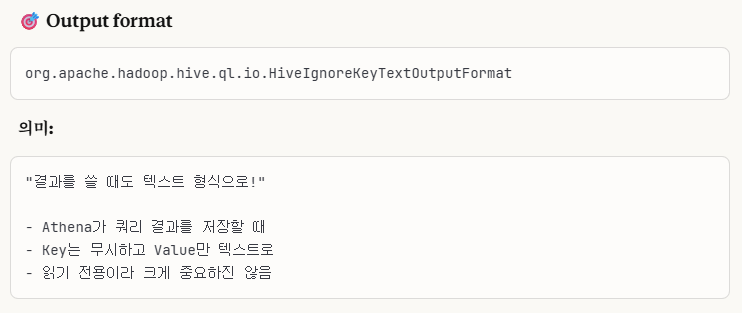
key는 무시하고 value만 텍스트 형식으로 저장한다는 의미입니다.
3. Serde Name
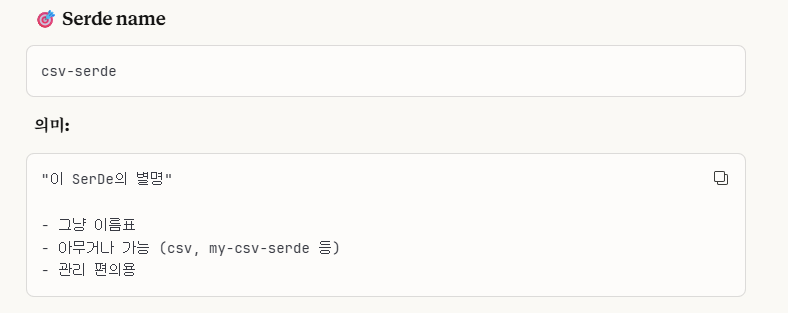
그냥 이름을 설정하는 부분입니다.
4. Serialization lib
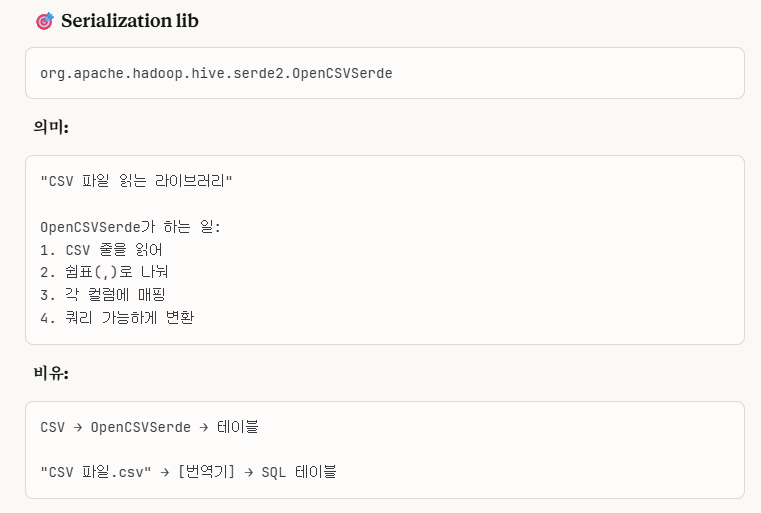
CSV 파일을 읽는 라이브러리 설정입니다.
5. Serde Parameters - 'separatorChar: ,' & 'skip.header.line.count: 1'
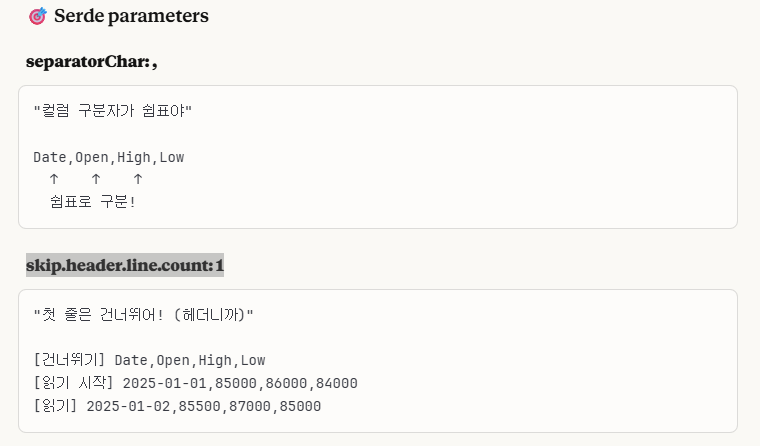
칼럼 구분자를 쉼표(,)로 구분하고, 첫 줄은 헤더이므로 건너뛰라는 설정입니다.
하지만 실데이터가 안 나오는 문제가 발생했습니다.
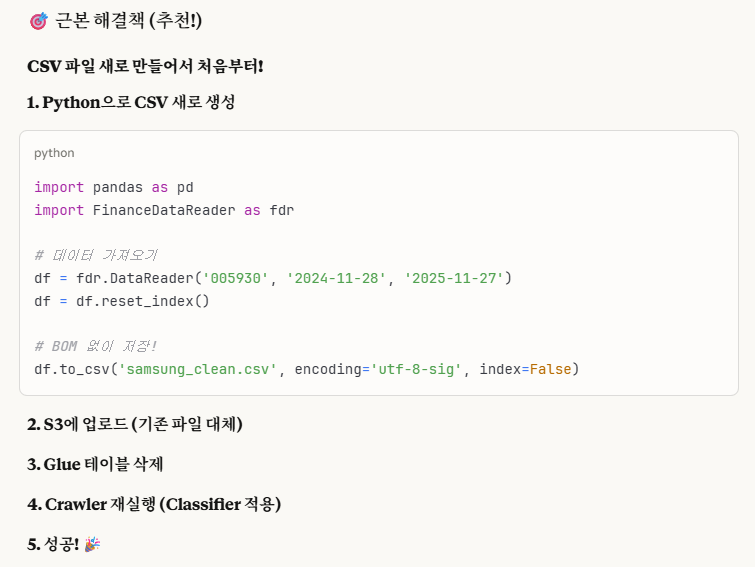
3-6-1. 다시 BOM Encoding - 새로운 csv python 파일 만들기로 돌아와서..
https://github.com/pilmalion114/data_engineer_portfolio/tree/main/phase%203/phase%203-5
해당 파이썬 파일 부분 역시 깃허브에 올려서 공유하도록 하겠습니다.
파이썬 파일 안에 각 코드들에 관한 주석 설명이 자세하게 되어있으니 참고하시면 될 거 같습니다.
간단하게 이 부분에 대해서 설명하자면,
우리는 BOM 문제가 나오는 encoding 설정을 'utf-8-sig' -> 'utf-8'로 변경해서 새로운 csv 파일을 만든 것입니다.
그 csv 파일이 'samsung_clean.csv'입니다.
그 다음은 S3 버킷에서 raw/ 폴더에 'samsung_clean.csv' 파일을 새로 업로드하고,
Crawler의 data sources 경로를 아래와 같이 변경했습니다.

그리고 다시 Crawling을 진행합니다.

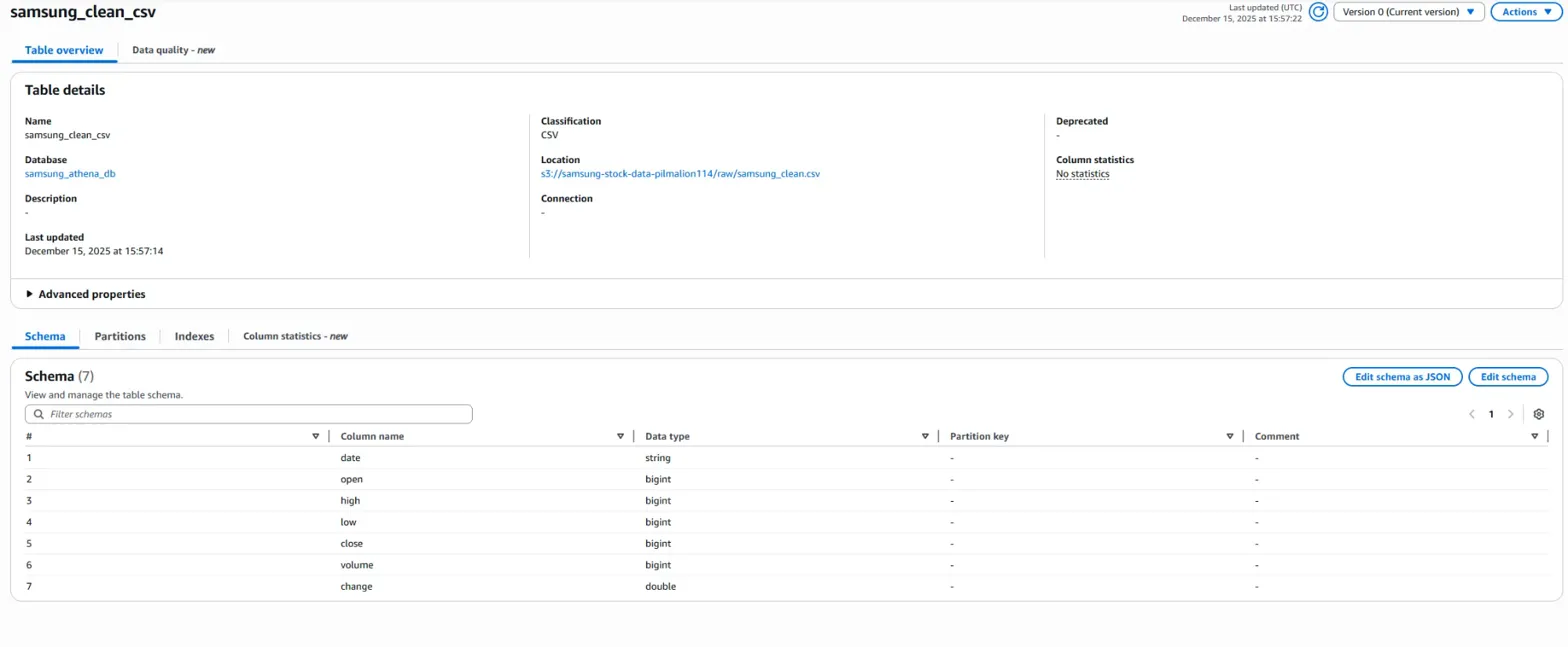
헤더는 잘 읽히지만 여전히 실 데이터는 나오지 않습니다.
이 때부터 멘붕이 좀 세게 오기 시작했습니다.
csv 파일은 문제가 없고, Serde Parameters 부분도 문제가 없었습니다.
3-7. Data Sources 폴더 경로로 변경하기
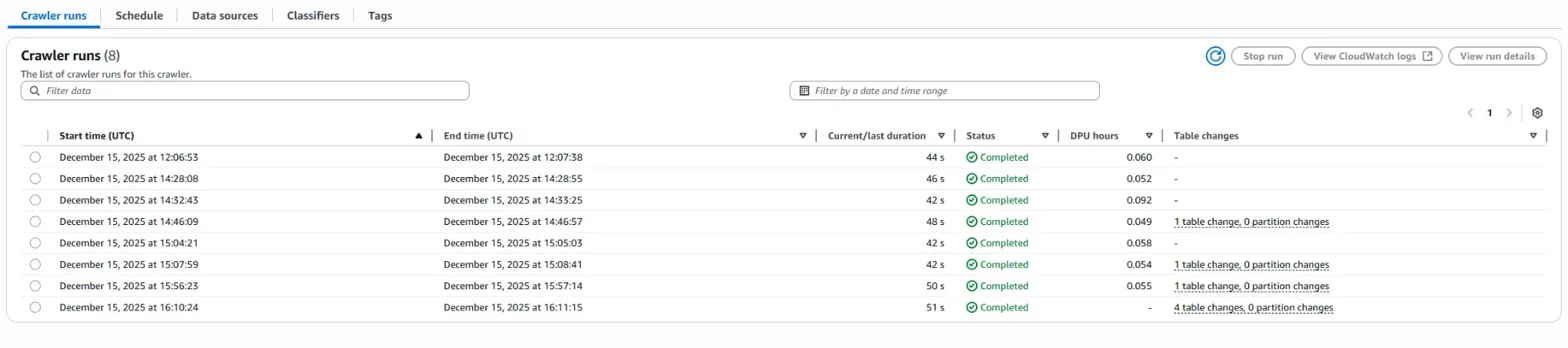
Data Sources 부분을 raw/ 폴더로 변경해보았습니다.

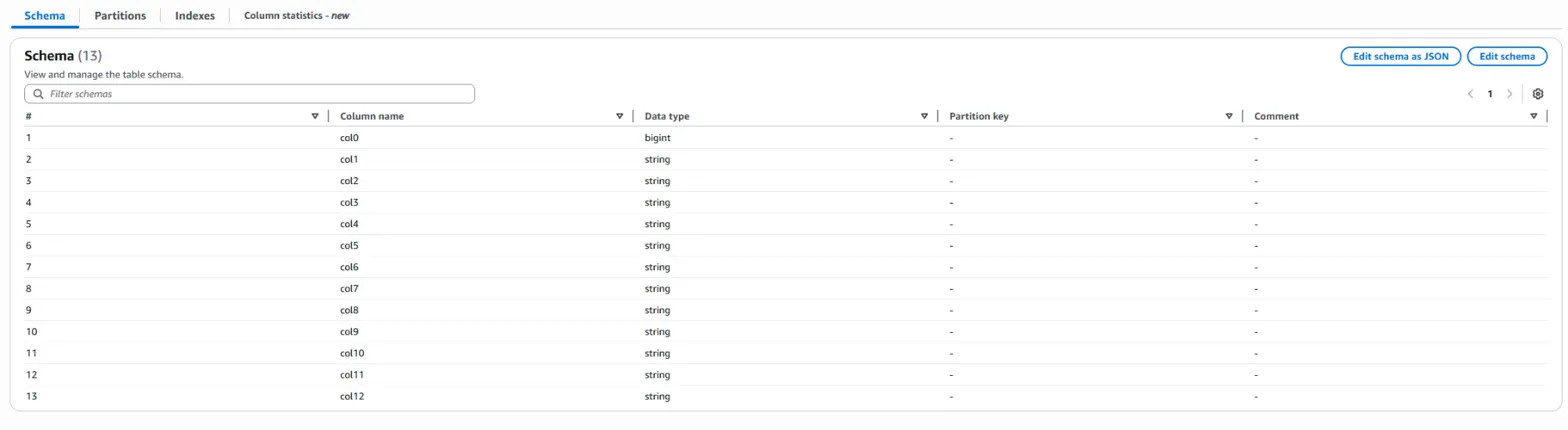
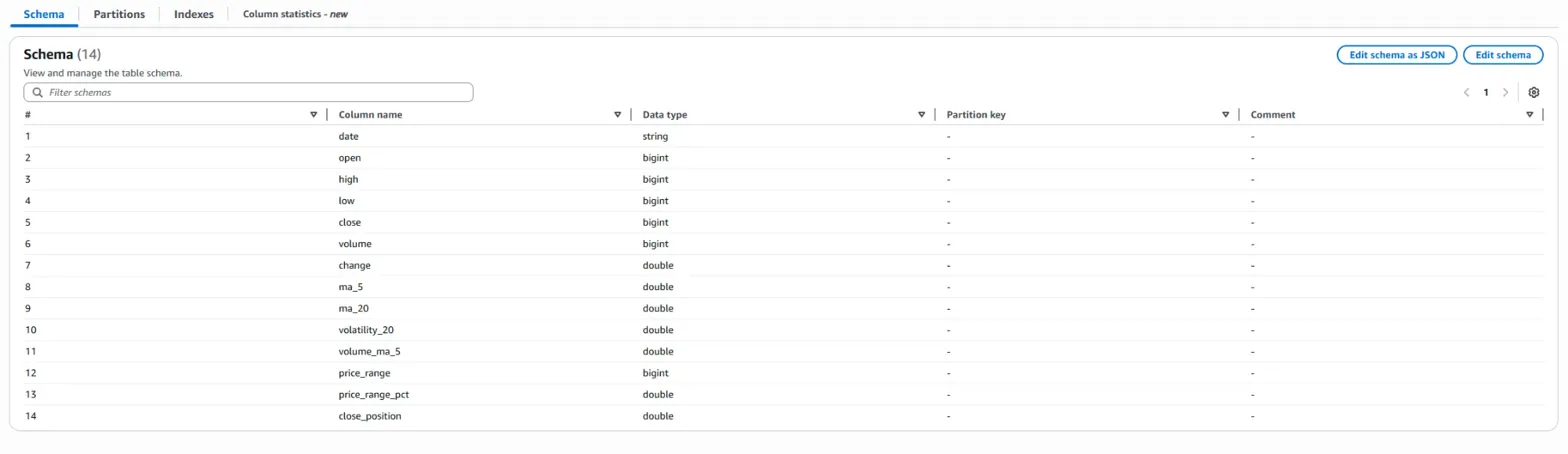

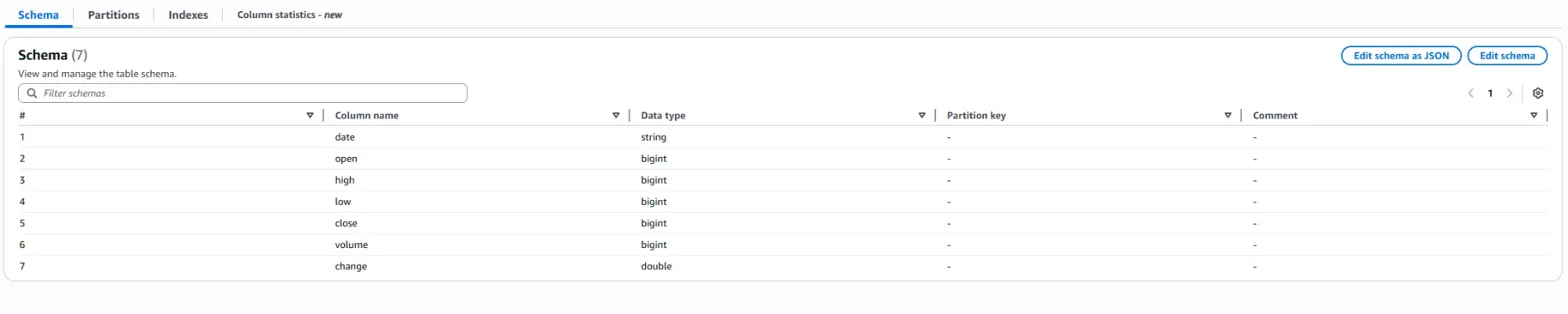
앞에서 말한 것처럼 스키마 설정이 다르므로 각각의 테이블이 생성되었습니다.

이렇게 명확하게 문제점을 찾지 못하다가 제일 큰 문제점을 발견하였습니다.
(이제부터 제가 맨 앞 부분에서 설명한 '폴더 경로' 문제점에 대해서 설명이 나옵니다.)
⭐3-8. Data Sources 폴더 경로로 변경하기(2) - 진정한 해결책

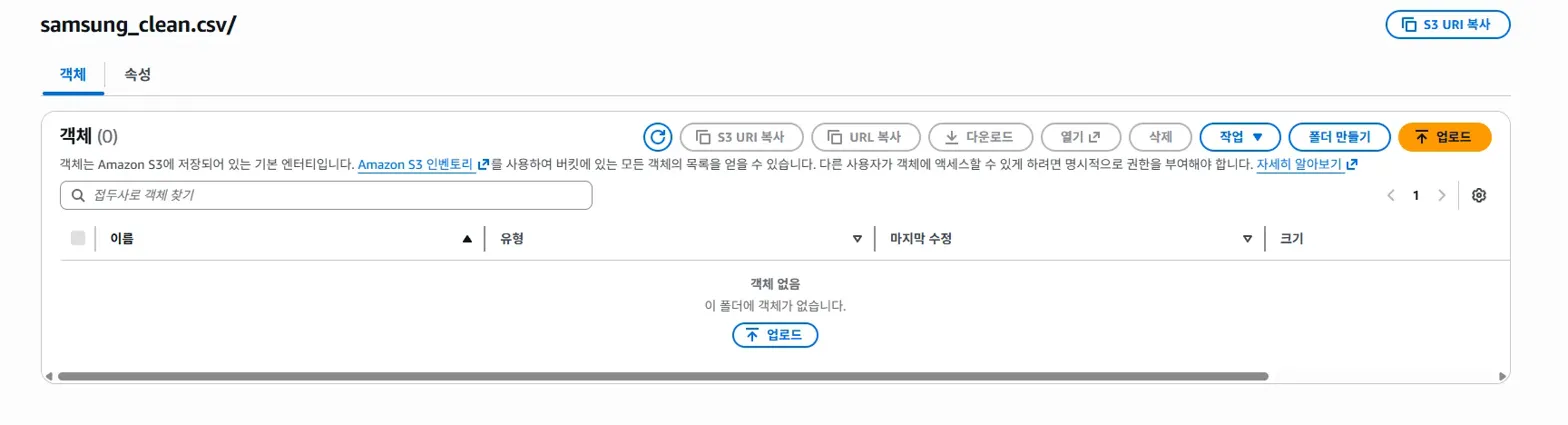

제가 직접 위 사진 속에 있는 Location 링크를 눌러서 확인해보니,
'samsung_clean.csv' 파일이 폴더 경로로 표현됨을 확인할 수 있었습니다.
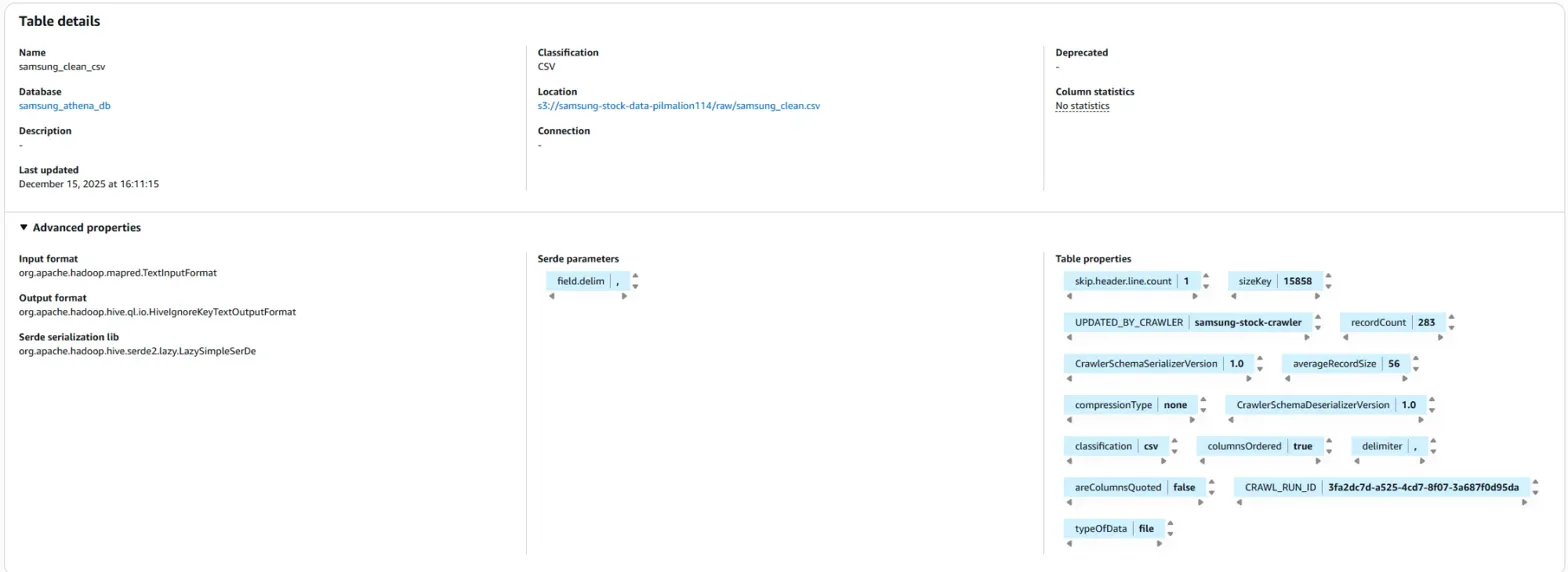
그렇지만 아주 오묘하게, 여기 Location 표시에서는 파일 경로로 잘 설정되어 있음을 볼 수 있습니다.
여기서 뭔가 이상함을 눈치챘습니다.
Claude가 마지막으로 저에게 이런 선택지를 제안했습니다.
3-8-1. S3 버킷에 새로운 폴더(clean/) 만들기
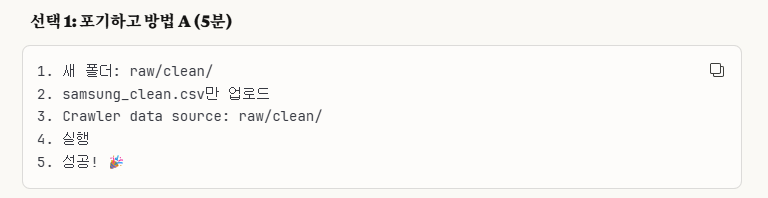


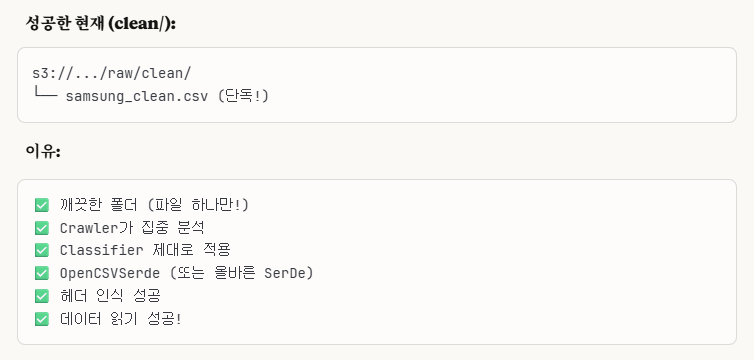
이렇게 S3 버킷에 'clean/'이라는 새로운 폴더를 만들고, 여기에다가 'samsung_clean.csv'를 추가했습니다.
그리고 data sources도 clean/ 폴더로 설정하였습니다.(개별 파일이 아닌 폴더 단위로 설정)
결과 성공적!! 🎉🎉🎉
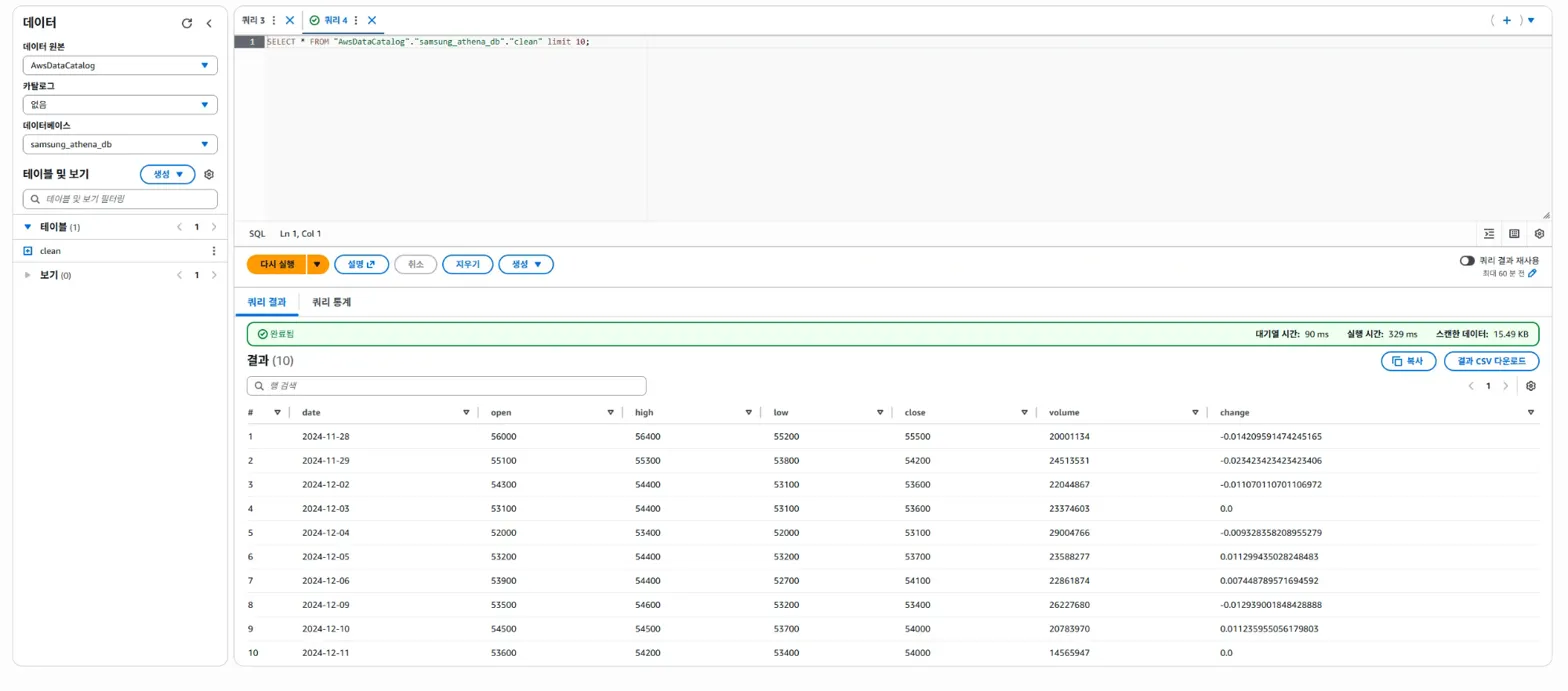
결과가 성공적으로 나왔습니다.
하지만, 왜 이렇게 결과가 성공적으로 나왔는지 명확하게 알고 싶었습니다.
결과 매커니즘 이해하기!
즉, 결론을 말하자면,
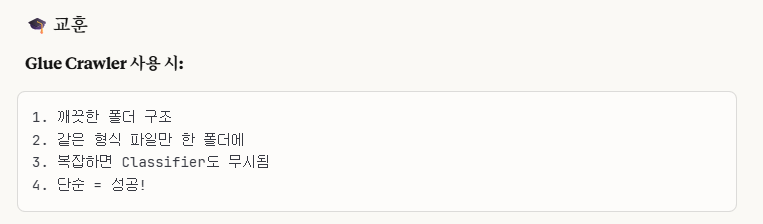
⭐⭐⭐(중요! - 제일 핵심 및 근본적인 해결 방법!!)
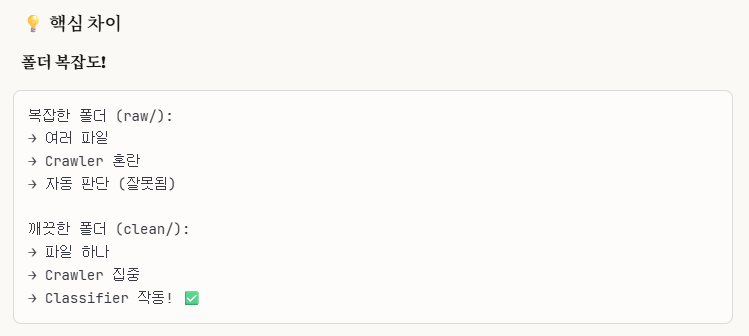
1.Data Sources는 무조건 폴더로 설정하기! -> Crawler가 자동으로 폴더로 인식하게끔 설정이 되어 있음.
->우리가 samsung_clean.csv를 파일이 아닌 폴더로 읽게 설정이 되어 있어서 빈 데이터로 나온 것임. 그래서 Athena SQL 쿼리문에서 실행을 해도 빈 값으로 나온 것이었음.2.AWS Crawler 및 Athena가 자동으로 잘 인식하게 설정하고 싶으면 S3 버킷에서 폴더 구조를 잘 정돈해서 만들어라(like clean/ 폴더 같이)
-> 그러면 Serde Parameter 설정은 알아서 잘 해준다. 우리가 수동으로 직접 작성할 필요가 없다.(오히려 오류 발생 가능성도 ↑)
- Athena에서 여러 csv 파일들을 하나의 테이블에 저장하고 SQL 쿼리를 불러오고 싶다면, 동일한 schema 구조를 유지하게 csv 파일을 생성하고, sub folder를 생성하지 말아라.
->아무리 스키마 설정이 같더라도 sub folder를 생성하면 다른 스키마로 인식을 한다.(위 4개 테이블 생성하는 거 보면 알 수 있음.)
4. 결론 및 마무리
지금까지 정말로 많은 오류/에러들을 다뤘다.
목록화를 해보자면,
1.BOM Encoding 문제
2.IAM 권한 부족
3.Classifier 설정
4.스키마 수동 추가
5.SerDe 설정
6.Location 경로(⭐ 핵심!)
7.복잡한 폴더 구조(기존 S3 버킷)
이렇게 목록화할 수가 있다.
아마 지금까지 작성한 게시글들 중에서 가장 오류를 많이 다뤄본 거 같다.
생각보다 간단할 작업인지 알았는데, 이렇게 많은 오류를 접하게 되어서 당황스럽기도 했지만,
한편으로는 실무에서도 충분히 일어날 수 있는 일을 미리 경험해보았다는 생각이 들어 기분이 좋았다.(미리 대비)
다음에는 'Phase 4'로 돌아오도록 하겠습니다.
오늘도 제 긴 글을 읽어주셔서 감사합니다 :) bb
