이번 게시글부터는 메모 스타일을 변경할까 합니다.
기존의 '모든 것을 적는 디테일함' -> '핵심 요약으로 간단하게'로 변경할까 합니다.
각각의 스타일에 장·단점이 있다고 생각합니다.
이번에 이렇게 바꾸게 된 이유는, '간편하고 핵심적인 것만 요약해서 보는 것이 제 뇌에 효과적/효율적으로 저장할 수 있지 않을까?'라는 생각을 해서 입니다.한 번에 이해하는 방식을 고수하기 보다는 여러 번 질문하고 알아가고 체득/체화하는 방향으로 학습법을 변경하고 결정하였습니다.
0. Phase 4의 소개
phase 4는 'Data Warehouse & Modeling' 부분으로, Data Warehouse(창고) 설계에 대해서 알아보는 시간을 가집니다.
저의 경우에는 크게 2개의 소그룹으로 나누는데(phase 4-1,4-2)
이번 4-1의 경우에는 'dimensional modeling & star schema'에 대해서 알아보는 시간을 가집니다.
※'Phase 4-2'의 경우에는 'dbt(data build tool)'에 대해서 배우는 시간을 가집니다.
1. Dimensional Modeling 개념 설명
Dimensional Modeling에는 'dimensional, fact, star schema, bridge table'이라는 개념이 나옵니다.

'Dimensional'은 '분류/구분'이 기준이 됩니다.
즉, '무엇으로 구분/분류하냐'가 기준이 됩니다.
이 분류 기준에는, '날짜,영화,장르,...'이 될 수 있습니다.
즉, 분류가 가능한 기준은 다 될 수 있습니다.
'Fact'는 '수치값,측정값'이 중심이라고 생각하면 됩니다.
즉, 우리가 데이터를 보고 논의를 하거나 의사결정을 할 수 있는 주체값인 측정값(수치값)이 메인이라고 보면 됩니다.
Dimensional과 Fact는 모두 테이블로 표현합니다.
다음은, Star Schema에 대한 설명입니다.
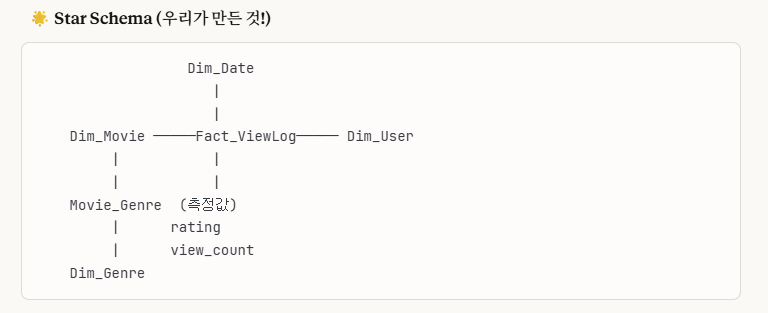
Star Schema는 Fact 테이블을 중심으로 Dimensional Table들이 방사형(중심에서 퍼져나가는 모양)으로 연결된 구조입니다.

->여기에 나오는 비정규화,조인 단순, 쿼리 빠름에 대한 설명은 뒤의 'Snowflake Schema'를 설명할 때 같이 하겠습니다.
Snowflake Schema는 Star Schema의 정규화 버전이라고 생각하면 됩니다.


즉, 정규화로 더 세부적으로 분해하여, 중복을 최소화합니다.
조인 복잡도 또한 늘어나는데,
뒤에 나오는 우리의 파이썬 실습 코드를 보면 알겠지만,
저희는 inner join만을 사용하며,


위 사진을 보면,
저희 코드의 대부분의 경우에는 1단계 수준의 깊이(depth)에 머물고,
bridge table의 경우에만 2단계로 거칩니다.
1단계는 직접 연결을 의미하고,
2단계는 중간에 Bridge table을 거치는 것을 의미합니다.

snowflake의 경우에는 이렇게 중간에 거치는 단계가 1개 이상인 구조인가봅니다.
또한, 여기서는 정규화를 진행하였으므로, 조인 또한 더 복잡한 구조로 되어 있습니다.
더 복잡한 구조이므로 쿼리 또한 상대적으로 느립니다.
하지만, 이렇게 정규화를 진행함으로써 저장 공간은 한 테이블에 모이는 게 아닌 분산되므로 절약됩니다.
즉, Star Schema(비정규화) vs Snowflake Schema(정규화) 이렇게 비교해서 이해하면 됩니다.
2. 구현 핵심
다음은 우리가 본격적으로 이 작업을 할 때 필요한 '구현 핵심'에 대해서 먼저 설명드리고자 합니다.

먼저,
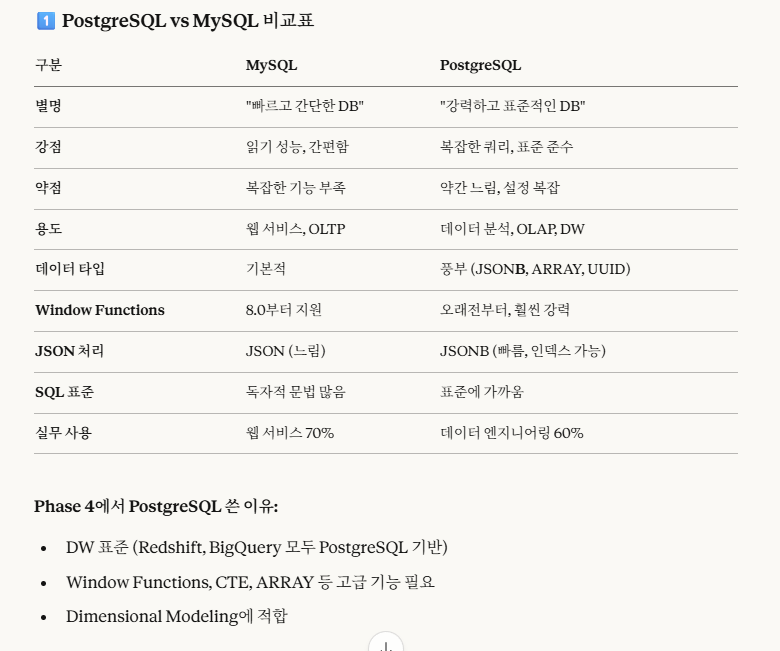
MySQL -> PostgreSQL로 변경하였습니다.
그 이유는 다음과 같습니다.
※MySQL vs PostgreSQL
즉, 간단히 요약하자면,
PostgreSQL은 MySQL보다 데이터 타입을 다양하게 지원을 하고, 약간 느리지만 복잡한 쿼리도 잘 처리하므로 이를 선택했습니다.
또한 실무에서도 PostgreSQL을 많이 쓰므로, 이를 선택했습니다.
그 다음은,
역시 docker-compose.yaml로 PostgreSQL 설정을 하였습니다.
테이블은 총 6개인데,
5개는 dimensional 4개 + Bridge Table(N:M,다대다관계) 1개
1개는 Fact 테이블로 구성되어 있습니다.
┌─────────────────────────────────────────────┐
│ │
│ Fact_ViewLog │
│ (관람 기록 - 중심 ⭐) │
│ │
│ view_id (PK) │
│ movie_id (FK) ──────────┐ │
│ user_id (FK) ─────┐ │ │
│ view_date (FK) ─┐ │ │ │
│ rating │ │ │ │
│ view_count │ │ │ │
└──────────────────┼─┼─────┼─────────────────┘
│ │ │
┌──────────┘ │ └──────────┐
│ │ │
▼ ▼ ▼
┌──────────┐ ┌─────────┐ ┌──────────┐
│Dim_Date │ │Dim_User │ │Dim_Movie │
│ │ │ │ │ │
│date_id │ │user_id │ │movie_id │
│year │ │username │ │title │
│month │ │age_group│ │vote_avg │
│quarter │ │region │ │ │
└──────────┘ └─────────┘ └─────┬────┘
│
│
┌──────▼──────┐
│Movie_Genre │
│(Bridge ⚡) │
│ │
│movie_id (FK)│
│genre_id (FK)│
└──────┬──────┘
│
▼
┌──────────┐
│Dim_Genre │
│ │
│genre_id │
│genre_name│
└──────────┘
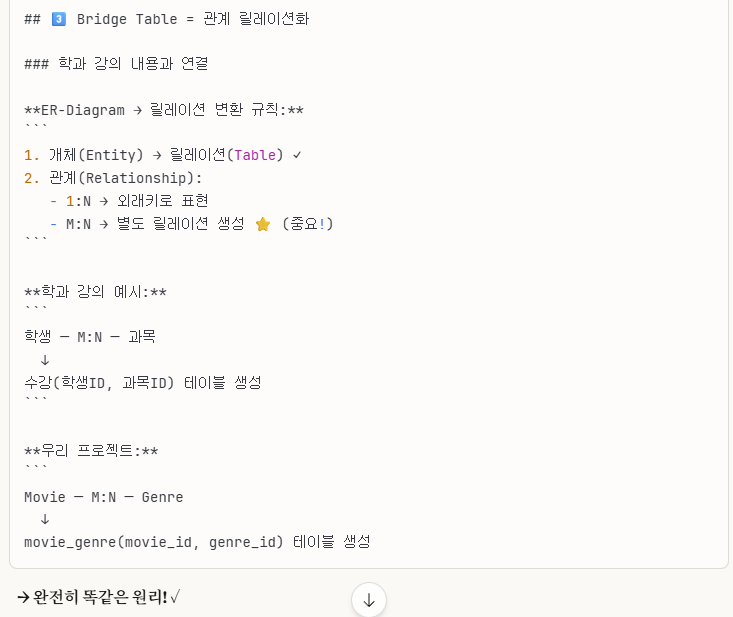
cf.) Bridge Table이란?
위 설계도의 'Movie_Genre' 테이블을 보면, 이 테이블이 'Bridge Table'입니다.
말 그대로 다리로 연결하듯이 연결을 해주는 테이블이고,
외래키로 구성이 되어 있습니다.
그럼 이 테이블은 왜 필요할까요?
바로 다대다 관계(N:M)를 해결하기 위함입니다.
예시를 들어봅시다.

영화와 장르의 관계는 다음과 같이 나타낼 수 있습니다.
- 한 개의 영화는 여러 개의 관계를 가질 수 있다.(1:N)
- 한 개의 장르는 여러 개의 영화에 포함될 수 있다.(1:N)
☞ N:M 다대다 관계
이 두 개의 테이블을, 다대다 관계의 테이블을 직접적으로 바로 연결을 한다면 어떤 문제가 생길까요?
어떤 영화는 2개의 장르를 가지고 있고, 어떤 영화는 3개, 다른 영화는 1개의 장르를 가지고 있다고 가정해봅시다.
그러면 장르의 갯수에 따라 장르 열이 생성되고 생성되지 않고 이렇게 뒤죽박죽으로 됩니다.
과연 이 구조가 이쁘고 정상적인 구조로 보일까요?
그래서 우리는 다대다 관계를 Brige Table이라는 새로운 릴레이션을 만들어서 외래키 참조 관계로 설정해서 이를 해결합니다.
※cf.)
Question
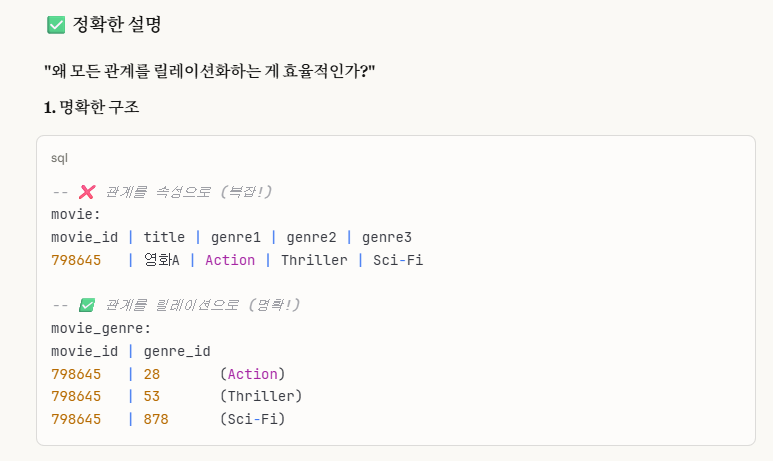
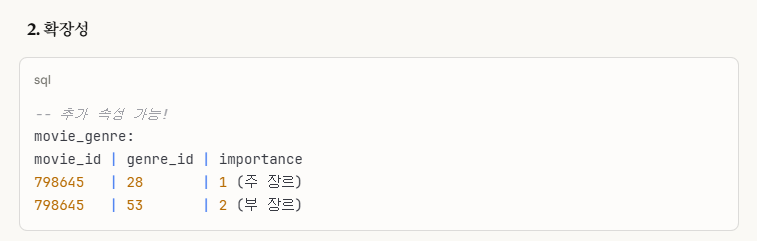
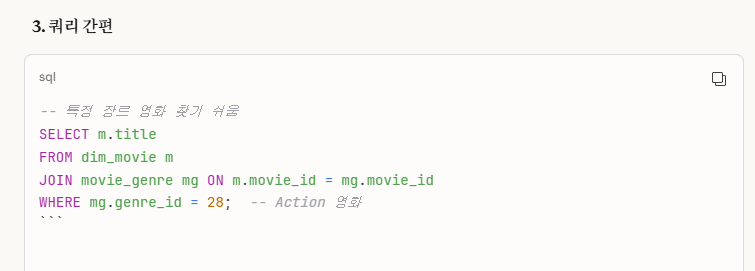
본인이 '데이터 엔지니어링' 프로젝트 시작한 처음 부분에('데이터베이스 학과 프로젝트 리뷰')
데이터베이스를 복습을 하면서, '관계(1:1,1:N,N:M)에 따른 릴레이션화'에 대해서 공부를 했었다.
위 사진은 해당 '데이터베이스 학과 프로젝트 리뷰' 부분을 캡쳐한 사진이다.
여기서 보면,
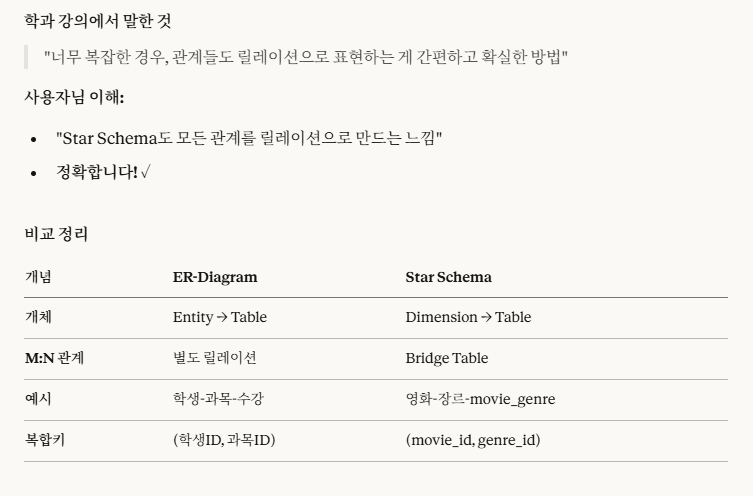
6번에 '모든 관계를 독립적 릴레이션으로 변환 가능하다.' 이 부분에 대해서 언급을 한 것이다.사실, 여기서도 알 수 있지만,
관계가 복잡하거나 귀찮을 경우에, 그냥 모두 다(개체,관계) 릴레이션화해도 상관없고, 오히려 이게 더 효율적일 수 있다.아마 이 이유는,
'Star Schema' vs 'Snowflake Schema'처럼 비정규화로 구성되어 있는 부분도 세부적인 릴레이션으로 분해해서 정규화를 쉽게 할 수 있기에 그런 거 같다.
->이 부분도 맞는 설명이나, 다음의 설명이 정확한 설명이다.
->정규화는 '중복 제거'를 하기 위해 더 세부적으로 분해하는 것을 의미한다.
->정규화를 이용해서 모두 다 릴레이션화를 이해하는 방향도 맞다고 함.





3. Python 코드 작성
https://github.com/pilmalion114/data_engineer_portfolio/tree/main/phase%204/phase%204-1
역시 6개의 파이썬 코드 및 'result_txt'를 깃허브에 업로드하였다.
6개의 파이썬은 5개의 dimensional,bridge table + 1개의 fact 테이블 코드이고,
result_txt는 각 6개의 파이썬 파일 실행 결과를 보여주는 txt 파일이다.
과정에 대한 설명은 앞에서 했고,
주석에서도 설명이 자세하게 되어있으므로 참고하면 된다.
※cf.) PostgreSQL 데이터 확인 방법
# psql -U movie_user -d movie_dw psql (16.11 (Debian 16.11-1.pgdg13+1)) Type "help" for help. movie_dw=# \dt List of relations Schema | Name | Type | Owner --------+--------------+-------+------------ public | dim_date | table | movie_user public | dim_genre | table | movie_user public | dim_movie | table | movie_user public | dim_user | table | movie_user public | fact_viewlog | table | movie_user public | movie_genre | table | movie_user (6 rows) movie_dw=# select * from fact_vielog limit 5; ERROR: relation "fact_vielog" does not exist LINE 1: select * from fact_vielog limit 5; ^ movie_dw=# select * from fact_viewlog limit 5; view_id | movie_id | user_id | view_date | rating | view_count | created_at ---------+----------+---------+------------+--------+------------+---------------------------- 301 | 798645 | 11 | 2024-01-05 | 2.8 | 1 | 2025-12-28 21:27:54.482979 302 | 1180831 | 4 | 2024-05-14 | 2.7 | 1 | 2025-12-28 21:27:54.482979 303 | 1286185 | 1 | 2025-02-18 | 6.2 | 2 | 2025-12-28 21:27:54.482979 304 | 1013446 | 4 | 2025-08-22 | 7.8 | 1 | 2025-12-28 21:27:54.482979 305 | 152760 | 16 | 2025-03-06 | 1.2 | 3 | 2025-12-28 21:27:54.482979 (5 rows) movie_dw=#movie_user와 movie_dw(data warehouse)는 yaml 파일에 설정되어있다.
C:\Windows\System32>cd C:\Users\dc\Desktop\새로운 포트폴리오를 위한 폴더\데이터,AI\포트폴리오용\데이터 엔지니어링\실습\data_engineer_portfolio\phase 4\phase 4-1 C:\Users\dc\Desktop\새로운 포트폴리오를 위한 폴더\데이터,AI\포트폴리오용\데이터 엔지니어링\실습\data_engineer_portfolio\phase 4\phase 4-1>docker exec -it movie_postgres psql -U movie_user -d movie_dw psql (16.11 (Debian 16.11-1.pgdg13+1)) Type "help" for help. movie_dw=# \dt List of relations Schema | Name | Type | Owner --------+--------------+-------+------------ public | dim_date | table | movie_user public | dim_genre | table | movie_user public | dim_movie | table | movie_user public | dim_user | table | movie_user public | fact_viewlog | table | movie_user public | movie_genre | table | movie_user (6 rows) movie_dw=# select * from fact_viewlog limit 5; view_id | movie_id | user_id | view_date | rating | view_count | created_at ---------+----------+---------+------------+--------+------------+---------------------------- 301 | 798645 | 11 | 2024-01-05 | 2.8 | 1 | 2025-12-28 21:27:54.482979 302 | 1180831 | 4 | 2024-05-14 | 2.7 | 1 | 2025-12-28 21:27:54.482979 303 | 1286185 | 1 | 2025-02-18 | 6.2 | 2 | 2025-12-28 21:27:54.482979 304 | 1013446 | 4 | 2025-08-22 | 7.8 | 1 | 2025-12-28 21:27:54.482979 305 | 152760 | 16 | 2025-03-06 | 1.2 | 3 | 2025-12-28 21:27:54.482979 (5 rows) movie_dw=#똑같이 나온다.
*추가 cf.)



4. 마무리 및 결론
이렇게 해서 phase 4-1을 알아보았다.
핵심 개념들만 요약해서 설명을 하였다.
세부적인 부분들은 추후 게속 반복 학습하여 체화/체득을 할 예정이다.
오늘도 제 글을 봐주셔서 감사합니다 :) bb
