[RL] Fundamentals of Reinforcement Learning Week 4
Dynamic Programming
Policy Evaluation (Prediction)
Policy Evaluation vs. Control
-
Policy Evaluation과 Control이라는 두 가지 distinct task에 대해 알아보자.
- 이 중 Policy Evaluation은 policy를 개선하기 위한 평가 방법이다.

- 이번 강의에서는 policy evaluation과 control(policy improvement)에 대해 이해하고, dynamic programming에 대해 설명할 수 있게 될 것이다.

-
Policy evaluation은 미래 보상의 return으로 계산되던 state-value(given policy)로 평가하는 과정을 말한다.
- Bellman equation에 의하면 모든 state에서 얻어지는 decay rewards의 기댓값이 state-value(given policy)였다.

-
Dynamic programming이란 Bellman equation을 iterative하게 찾아나가는 과정을 말한다.
- 이를 통해 policy evaluation과 control을 모두 가능하게 하는 알고리즘이다.

-
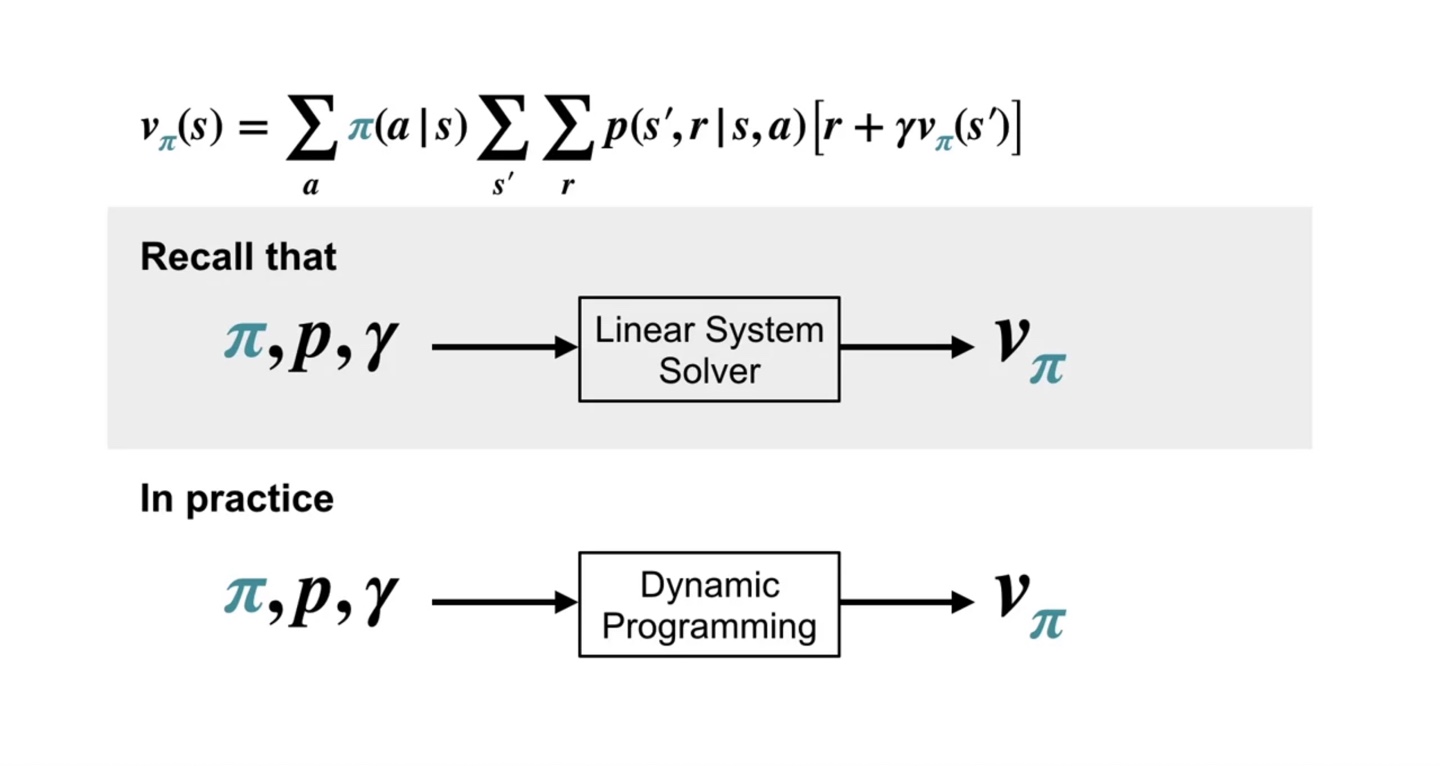
일반적인 state-value(givne policy) problem은 linear system으로 다뤄져 선형 방정식을 풀어 해결하는 것이 가능했다.
- 그러나 일반적인 MDP 세계에서는 Dynamic programming을 사용하여 policy evaluation을 진행하는 것이 더욱 적합하다.
-
아래와 같은 그래프를 보면 가 보다 항상 better policy를 가진다는 것을 알 수 있다.
- Control이란 value로 평가 및 비교하여 policy를 better policy를 찾아나가는 과정이다.

-
여러 번의 시행으로 우리는 optimal policy로 찾아나갈 수 있다.
- 아래와 같이 value가 가장 큰 policy를 optimal policy, 라고 정의한다.
-
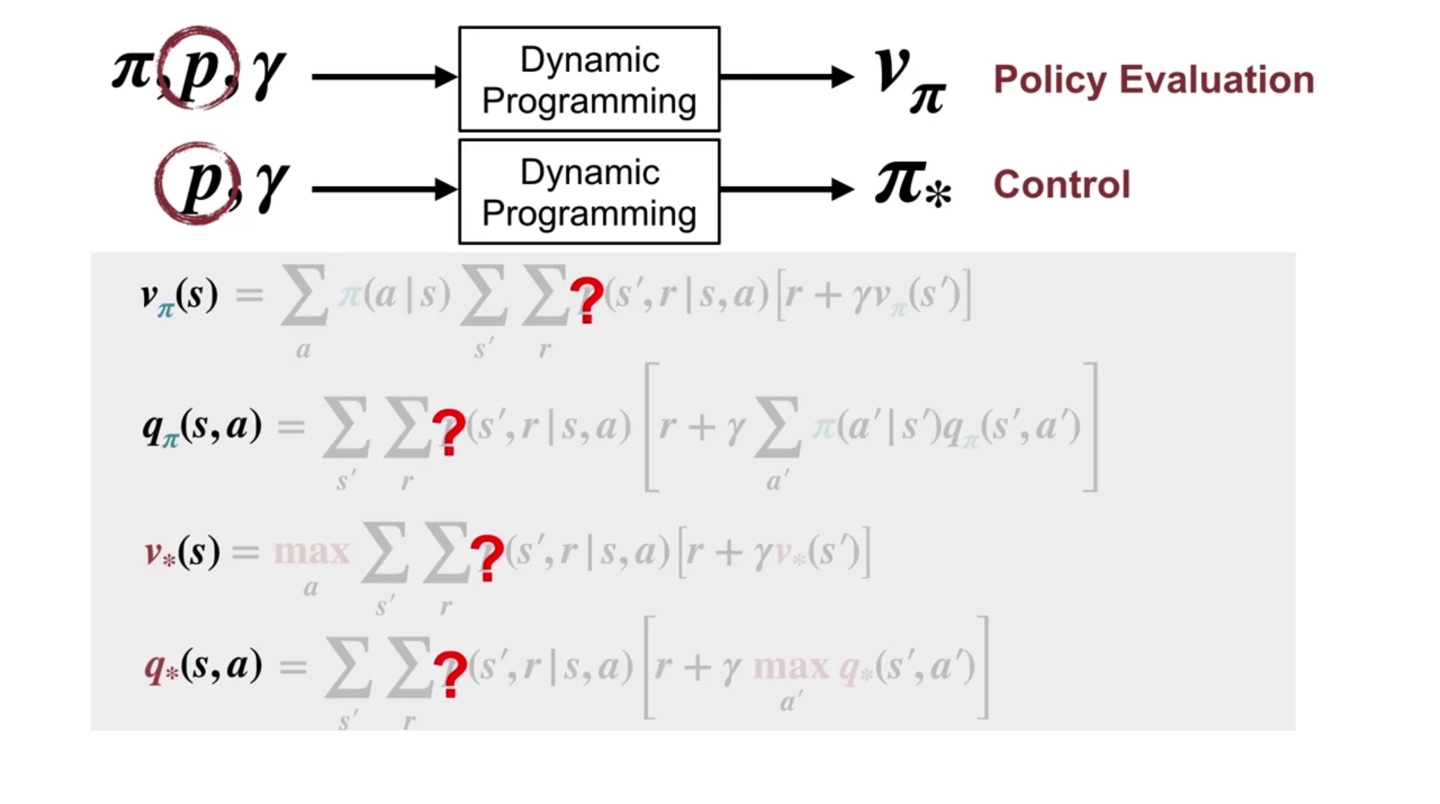
Dynamic programming이 필요한 이유는 Marcov process에 대한 정보 를 우리가 모르기 때문이다.
- Step by step으로 value를 업데이트해 나가면서 Policy evaluation → Control ... 의 과정을 거치는 것이 dynamic programming 알고리즘의 목적이다.
- Summary

Iterative Policy Evaluation
- 이제 policy evaluation을 통해 optimal value를 iterative하게 찾아 나가보자.
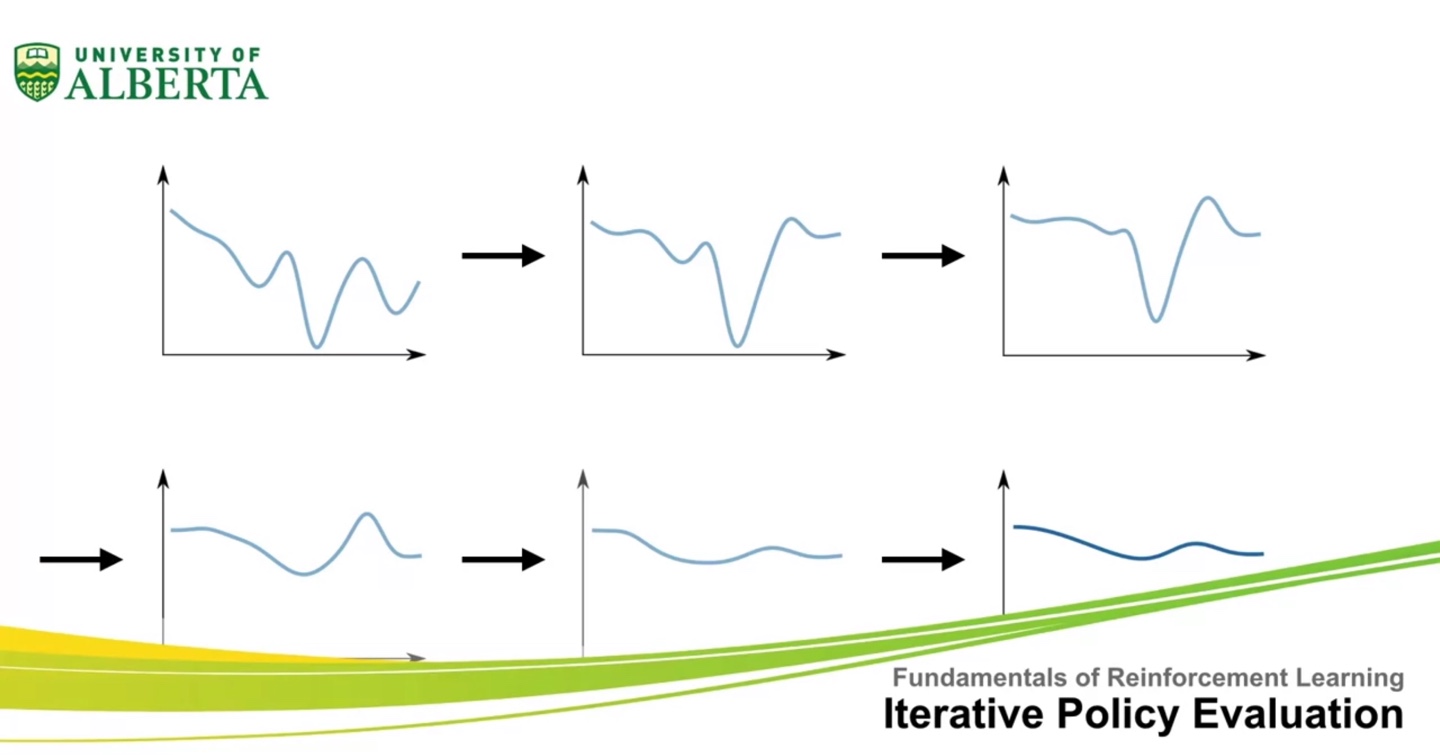
- 이번 강의에서는 iterative policy evaluation으로 optimal value를 estimating하는 과정에 대해 알아보도록 하겠다.

-
Iterative policy evaluation은 기존 Bellman equation에서의 state에 대한 notaion을 와 번째에 관한 수식으로 변경하여 표현한다.
- 이를테면, 바로 다음 state에서의 return을 이제는 번 iterative하게 업데이트하는 것이다.

- 한 번의 policy evaluation 수행으로, 처음 계산한 value를 라고 하자.
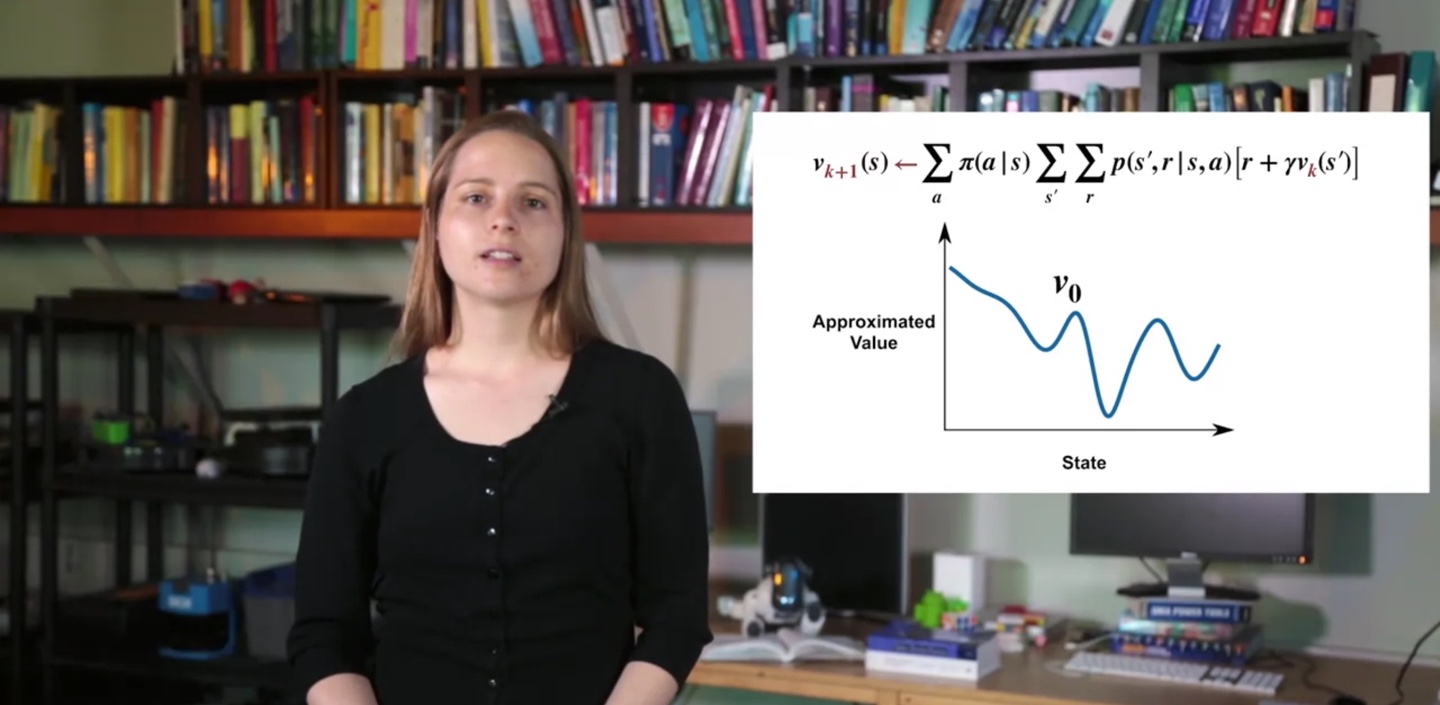
- 그 다음 iteration에 의해 value 즉, policy evaluation 값은 다소 상승하여 , , ..., , 로 얻어진다.
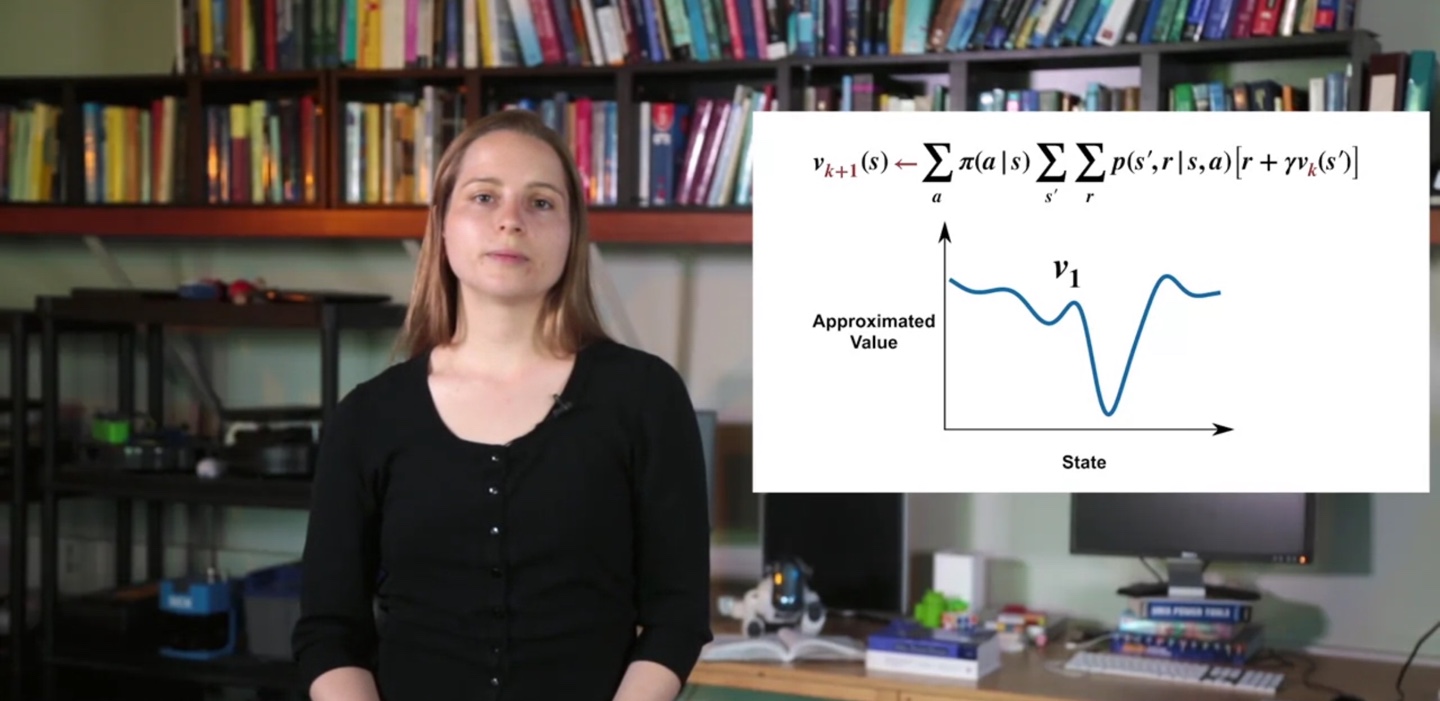
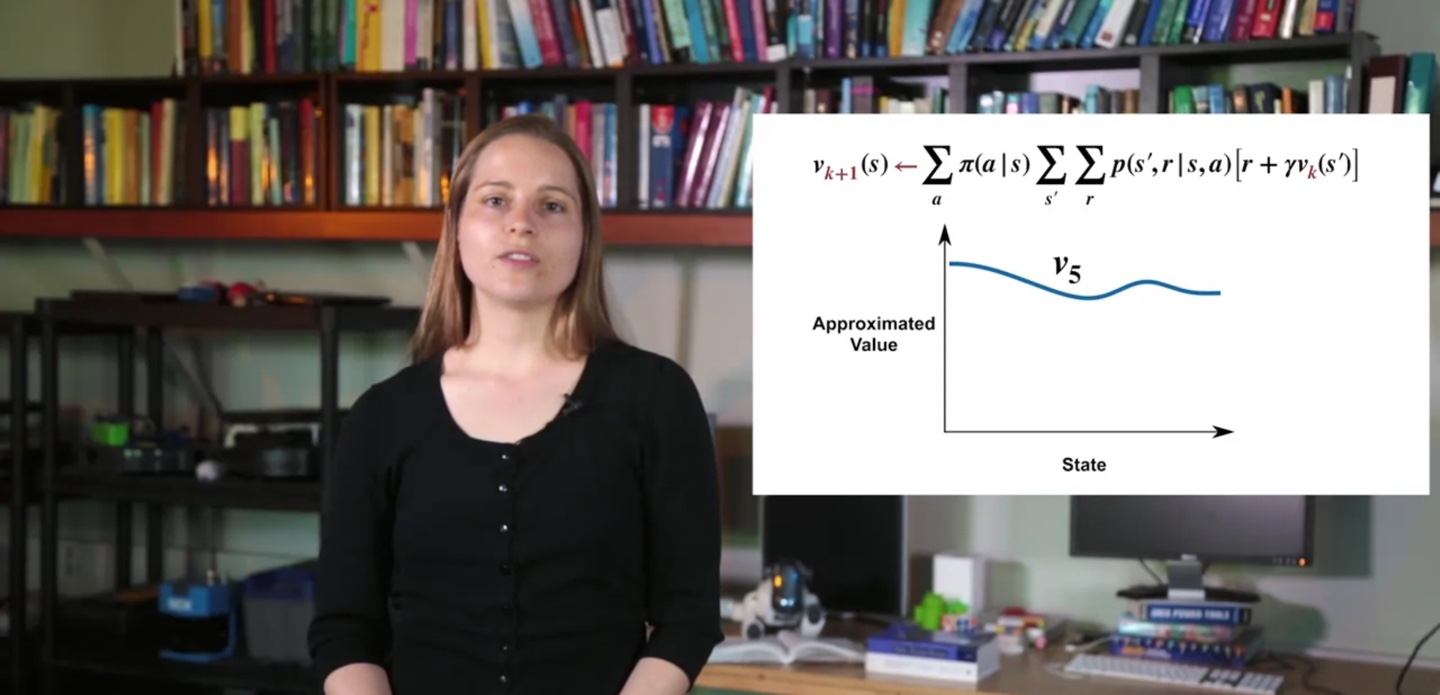
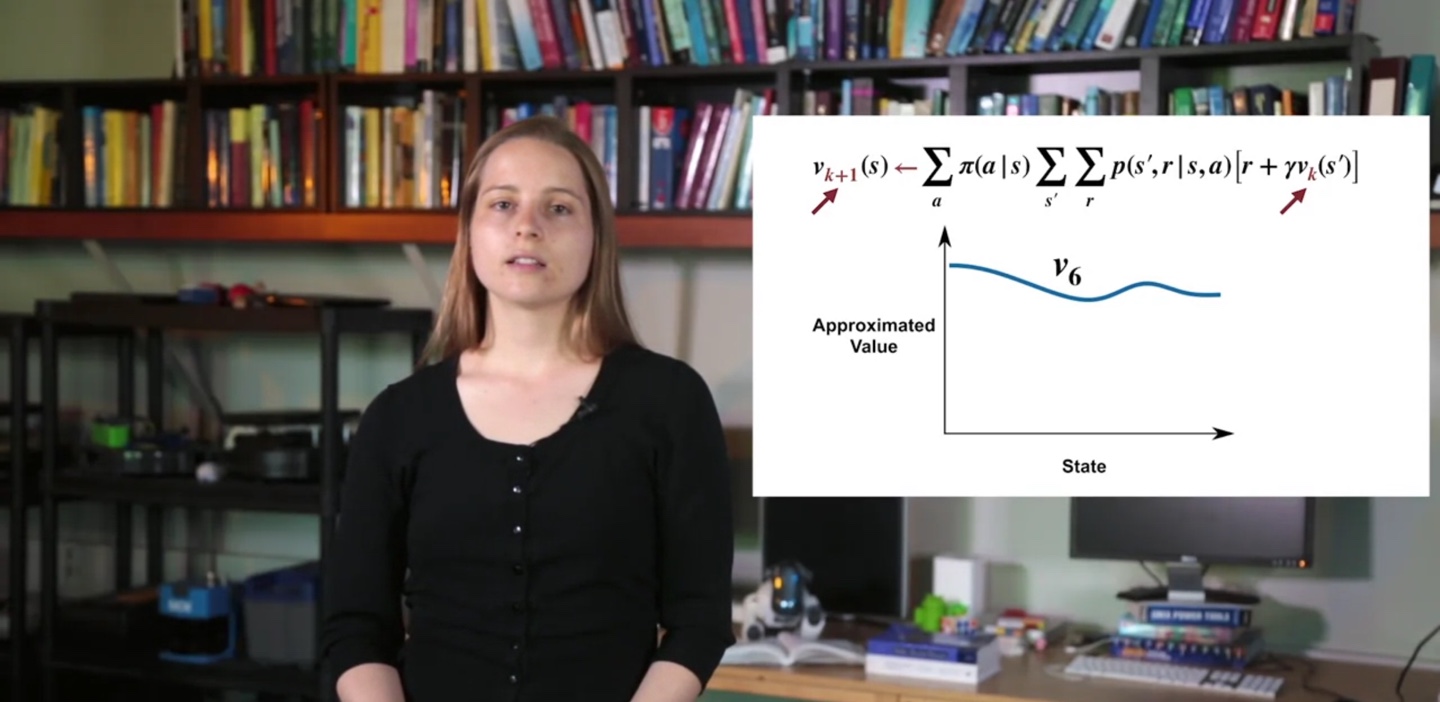
- 여러 번의 policy evaluation을 거쳐 계속해서 value를 업데이트하면, 모든 state에서의 value는 가장 optimal한 값()에 도달하게 된다.
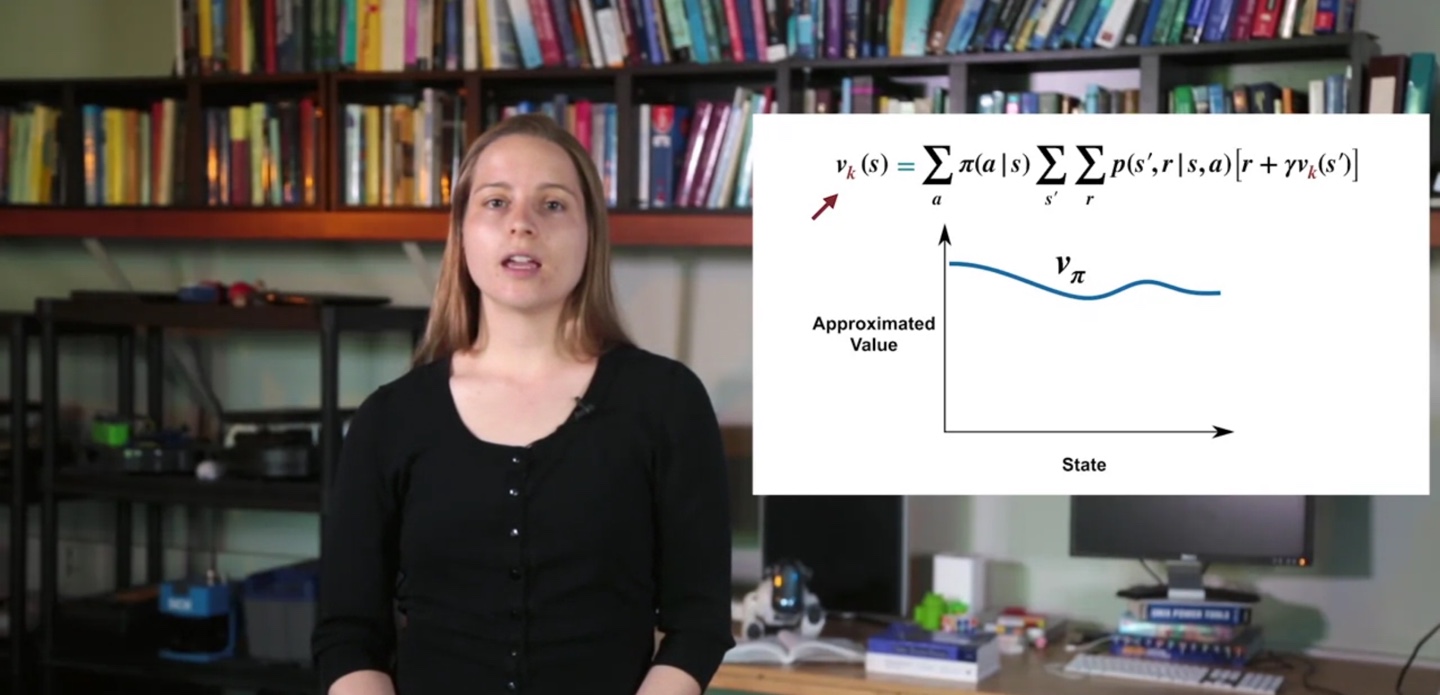
- 무한히 많은 시행으로 value가 수렴하게 되면 optimal한 value인 를 찾아낸 것이다.
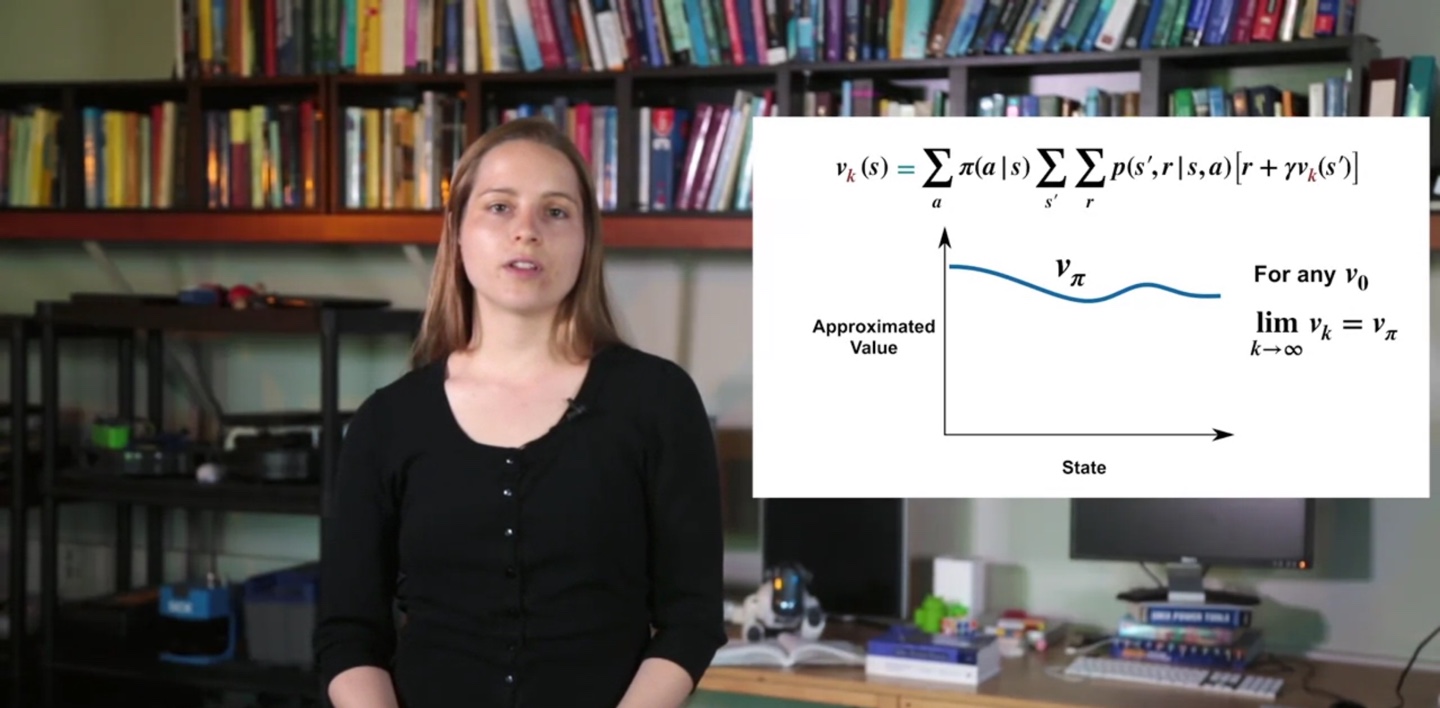
-
우리는 와 board를 놓고 iteration을 반복할 것이다.
- 한 step에서 모든 states의 value를 를 참고하여 계산한 뒤, 에 업데이트 후 에 합칠 것이다.
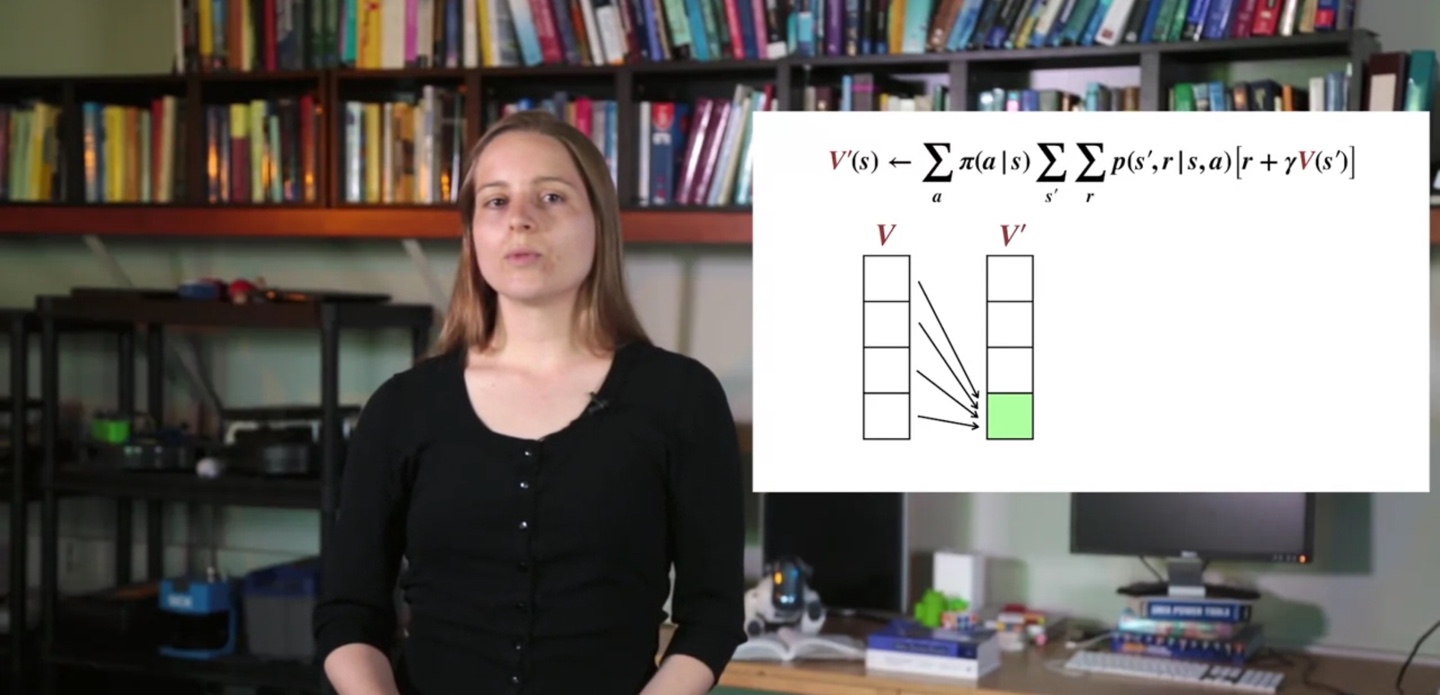
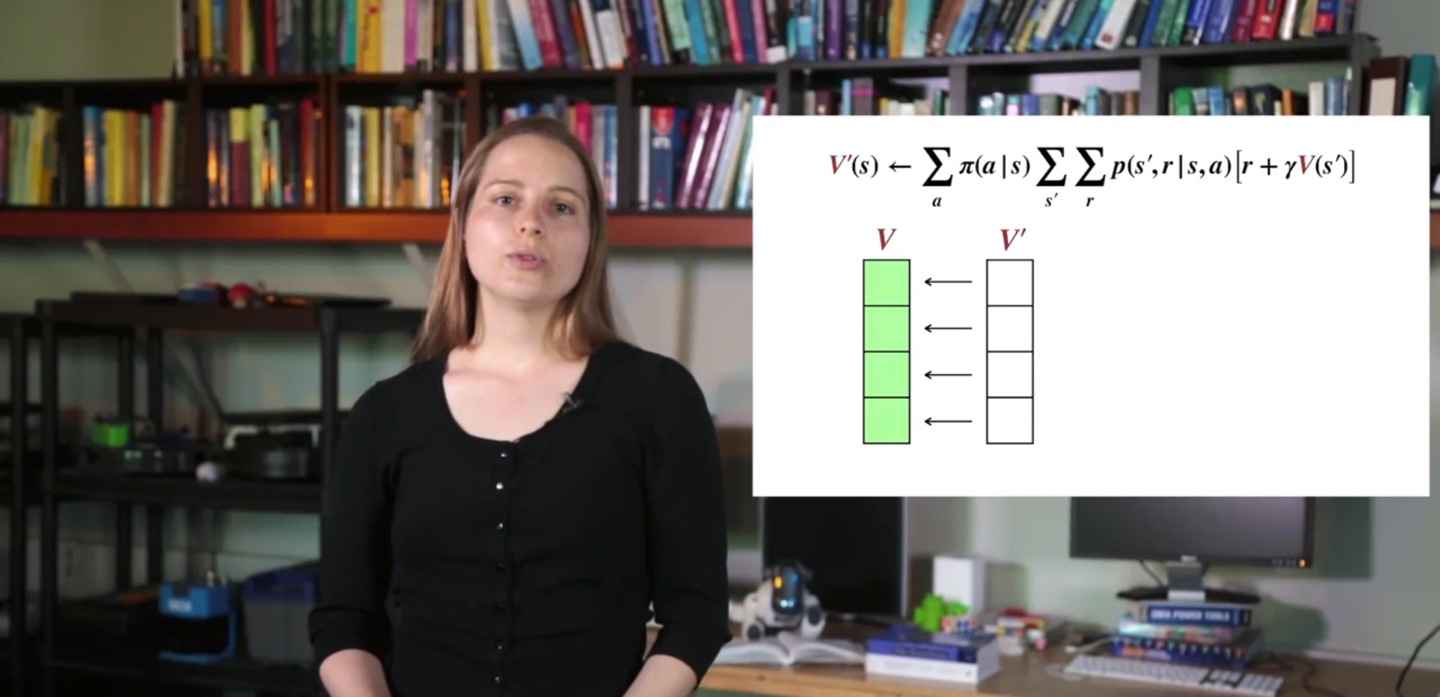
- 하나만 놓고 업데이트 해도 된다.
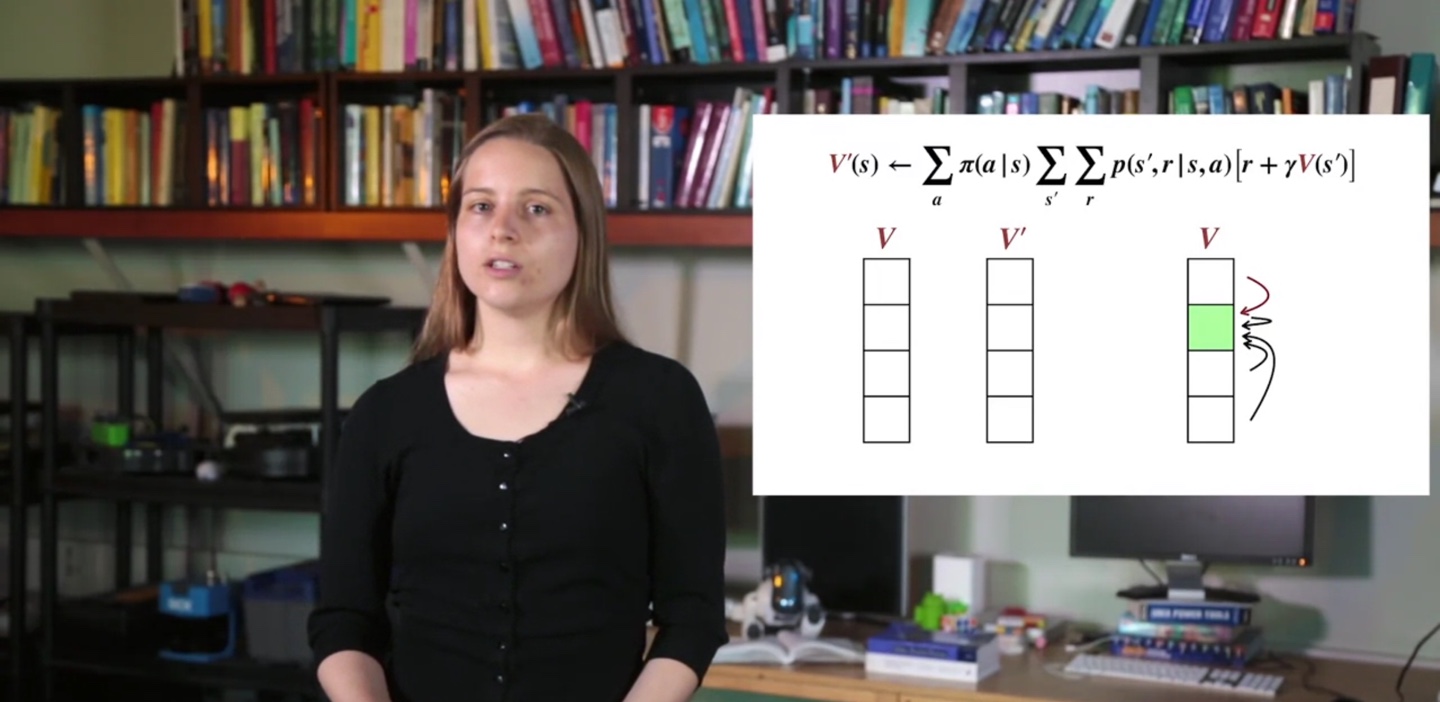
-
이제 아래와 같은 예시를 보자.
- 움직임의 reward는 , 감쇠계수 는 1, policy는 uniform하게 0.25로 설정하였다.
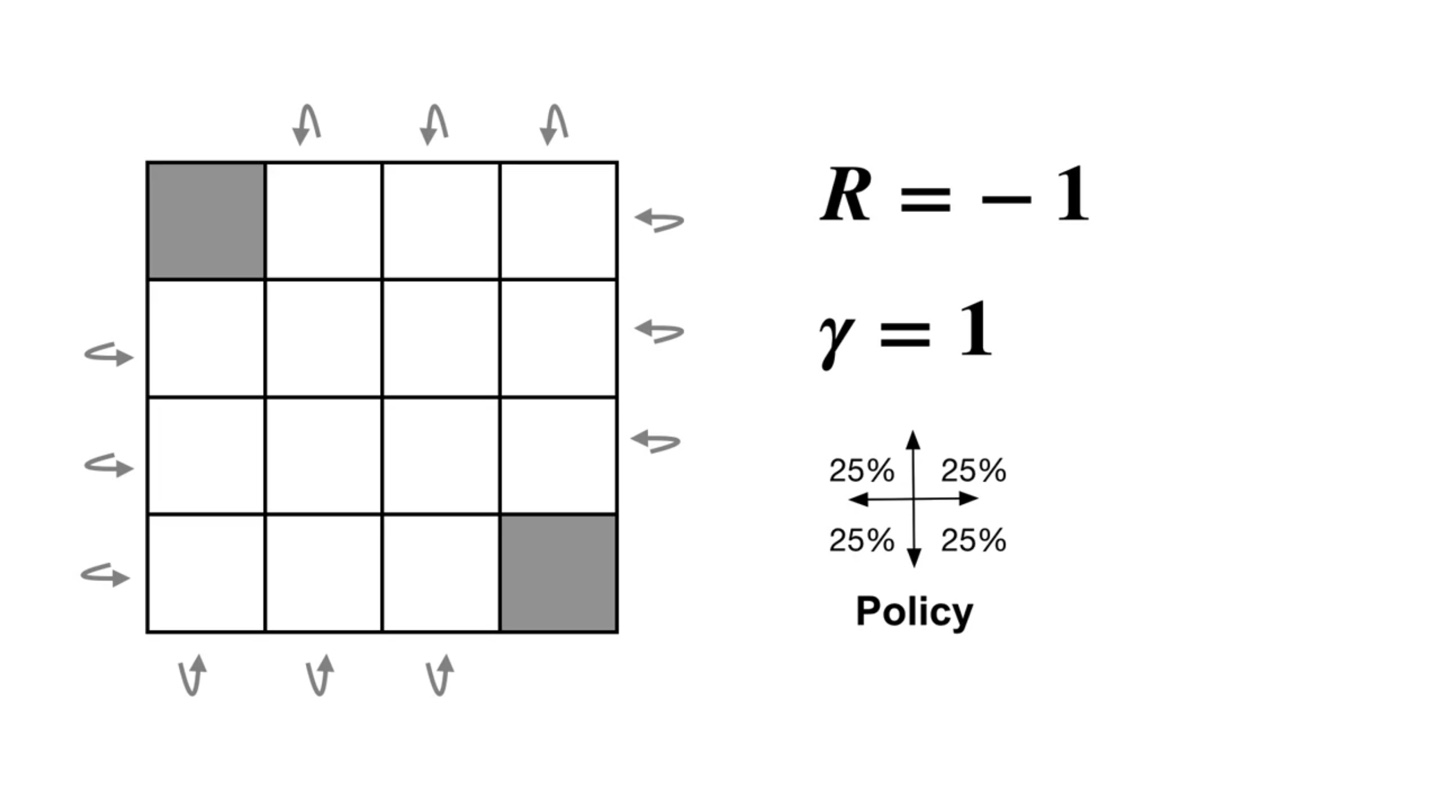
-
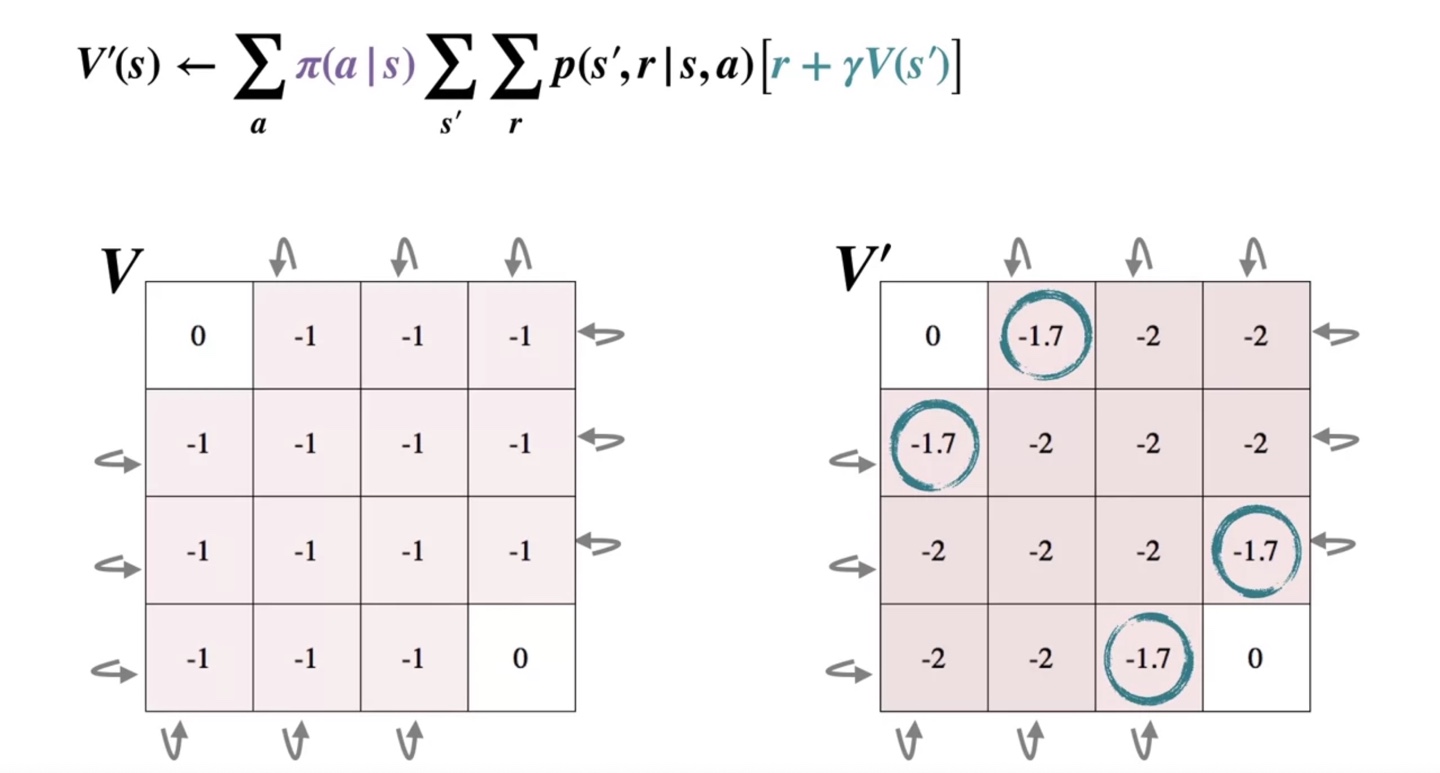
이제 왼쪽 위에서부터 board 안의 값을 쭉 보며, policy evaluation을 진행할 것이다.
- 맨 왼쪽 위와 오른쪽 아래가 terminal state인 environment가 주어졌다고 가정하자.
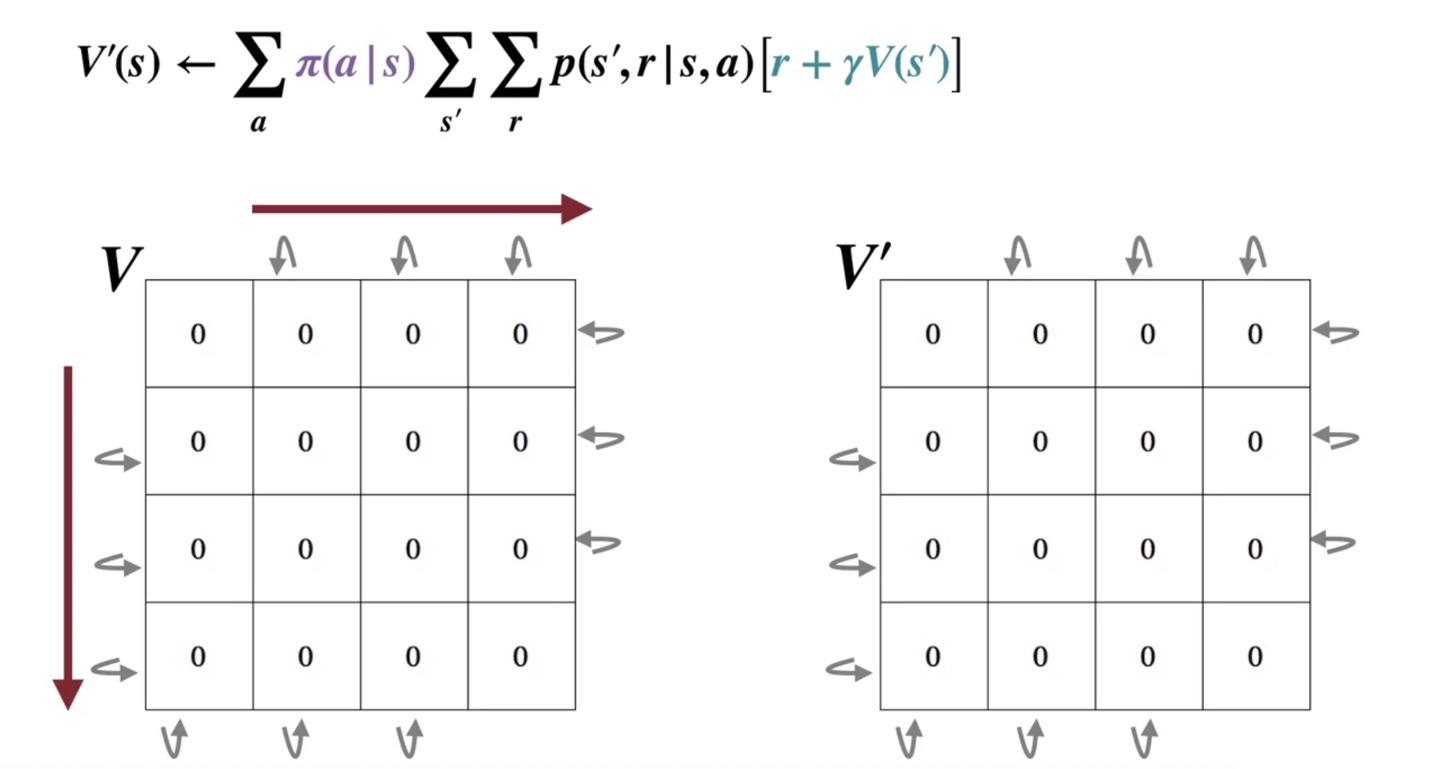
- 이 때 MDP process 는 결정론적이므로 policy와 reward, 그리고 가치만 계산에 관여한다.
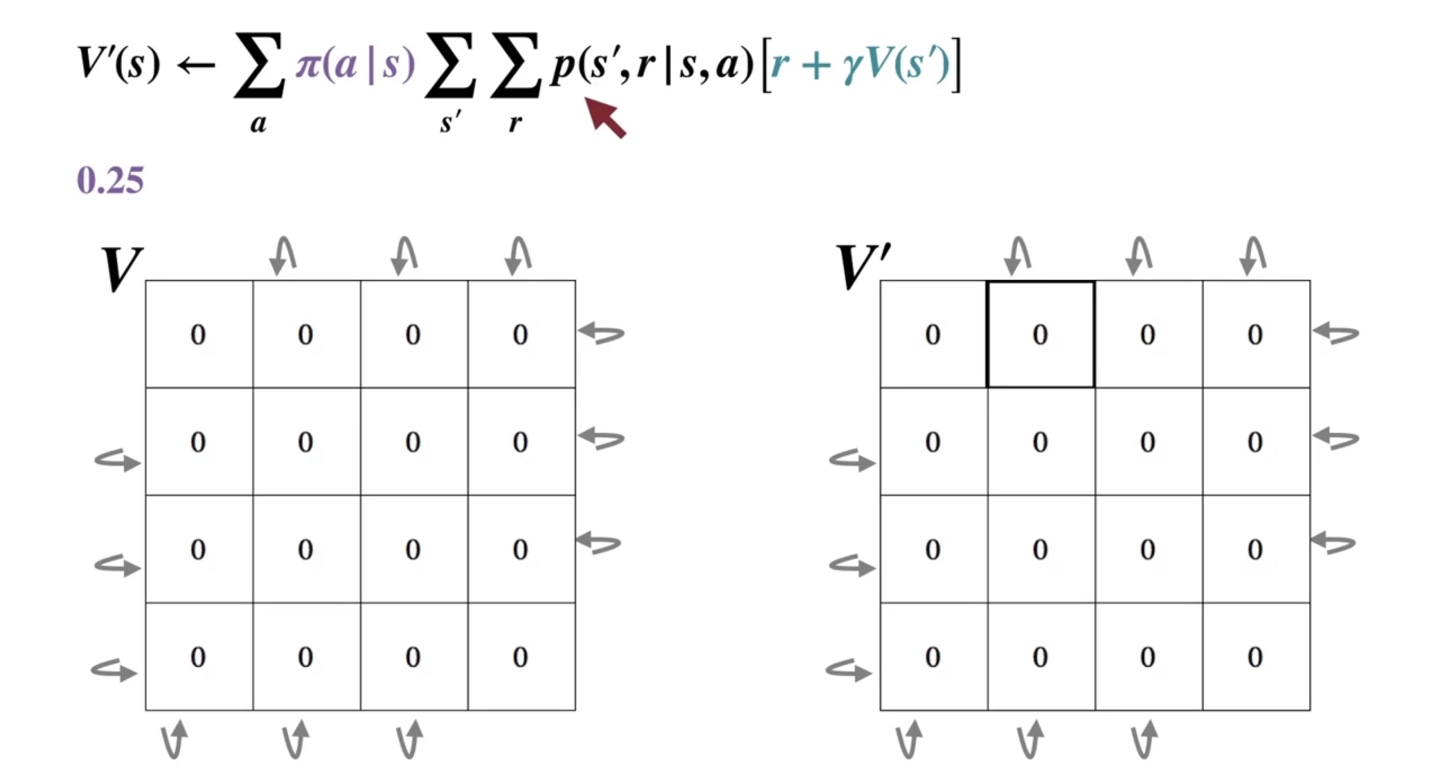
-
아래 검은 박스가 쳐진 곳에서부터 step을 밟아 나가보자.
- 왼쪽으로 향하는 경우의 수에서 얻어지는 value는 이다.
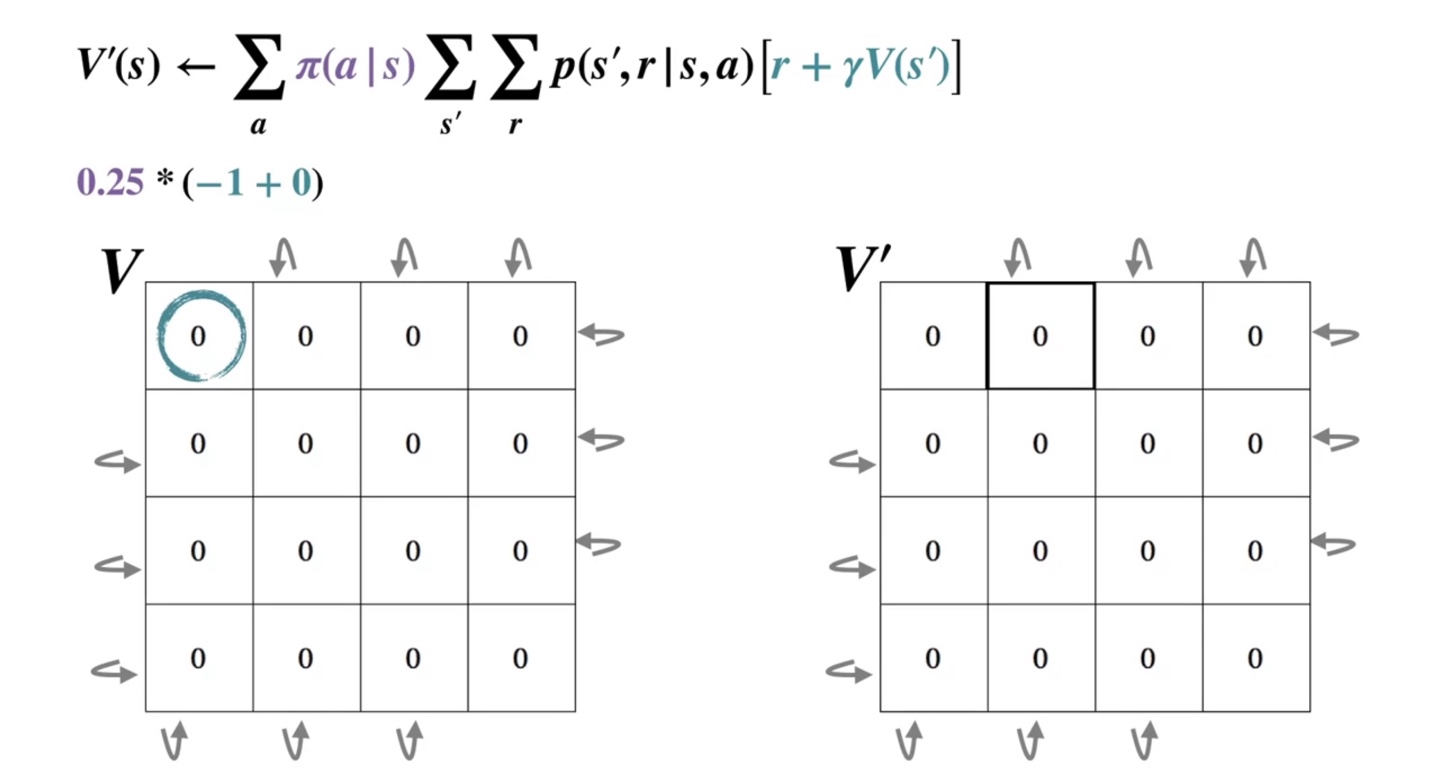
-
위로 가는 경우의 수는 다시 현재 상태로 돌아오고 오른쪽, 아래 state의 value까지 모두 계산한 값을 더하면 -1로 얻어진다.
- 이를 현재 state인 의 검은 박스 내에 기록한다.
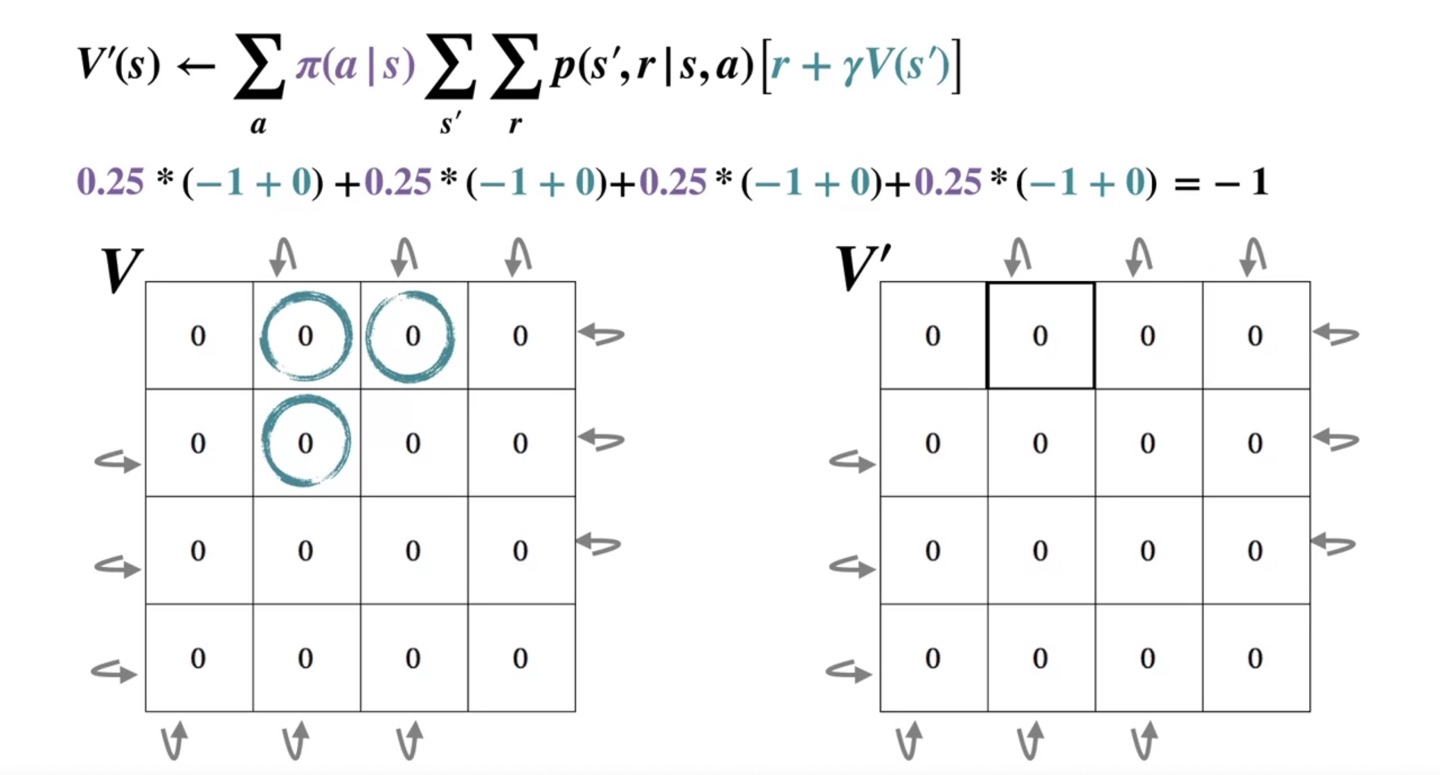
-
그리고 바로 옆 검은 박스의 왼쪽부터 다시 계산해나간다.
- 마찬가지로 왼쪽으로 향하는 경우의 수에서 얻어지는 value는 이다.
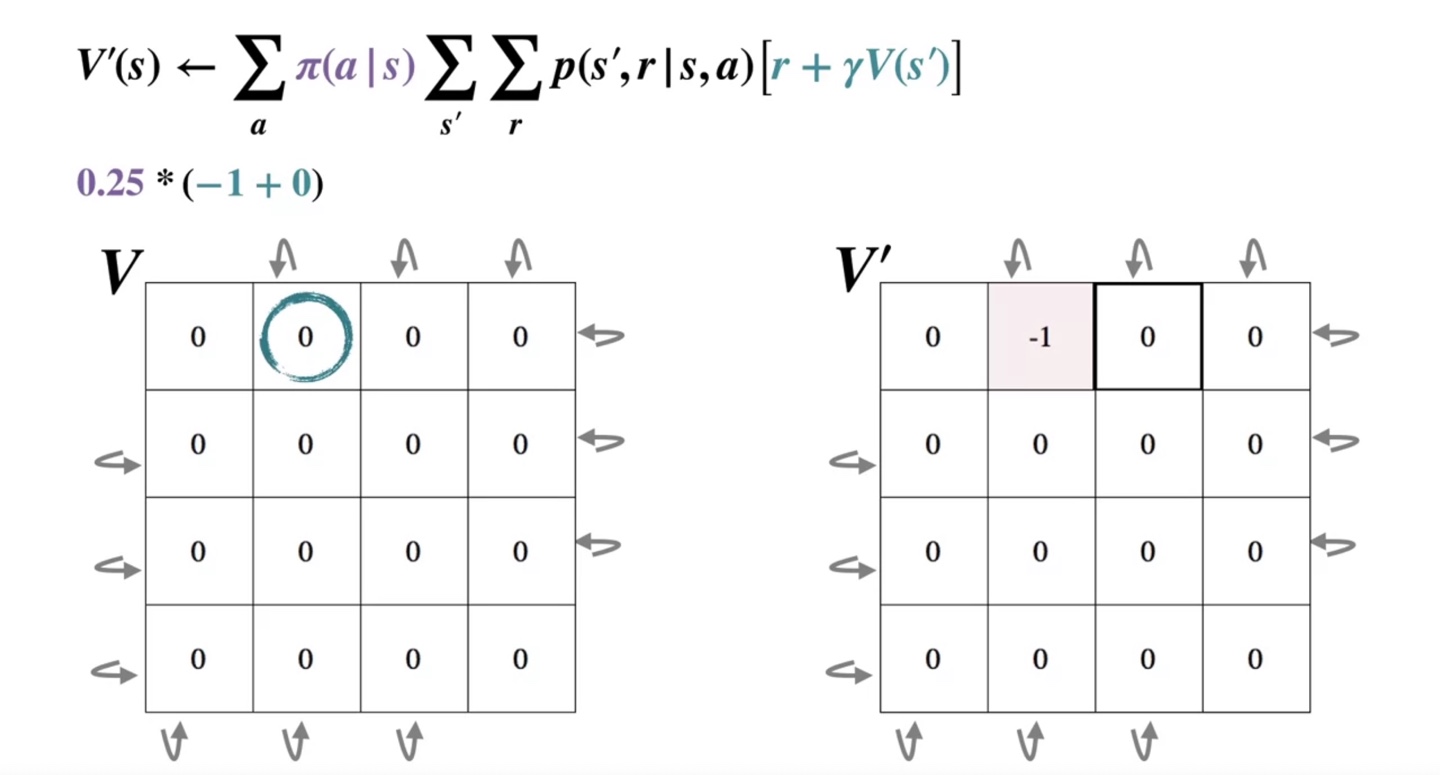
-
위로 가는 경우의 수는 다시 현재 상태로 돌아오고 오른쪽, 아래 state의 value까지 모두 계산한 값을 더하면 -1로 얻어진다.
- 이를 현재 state인 의 검은 박스 내에 기록한다.
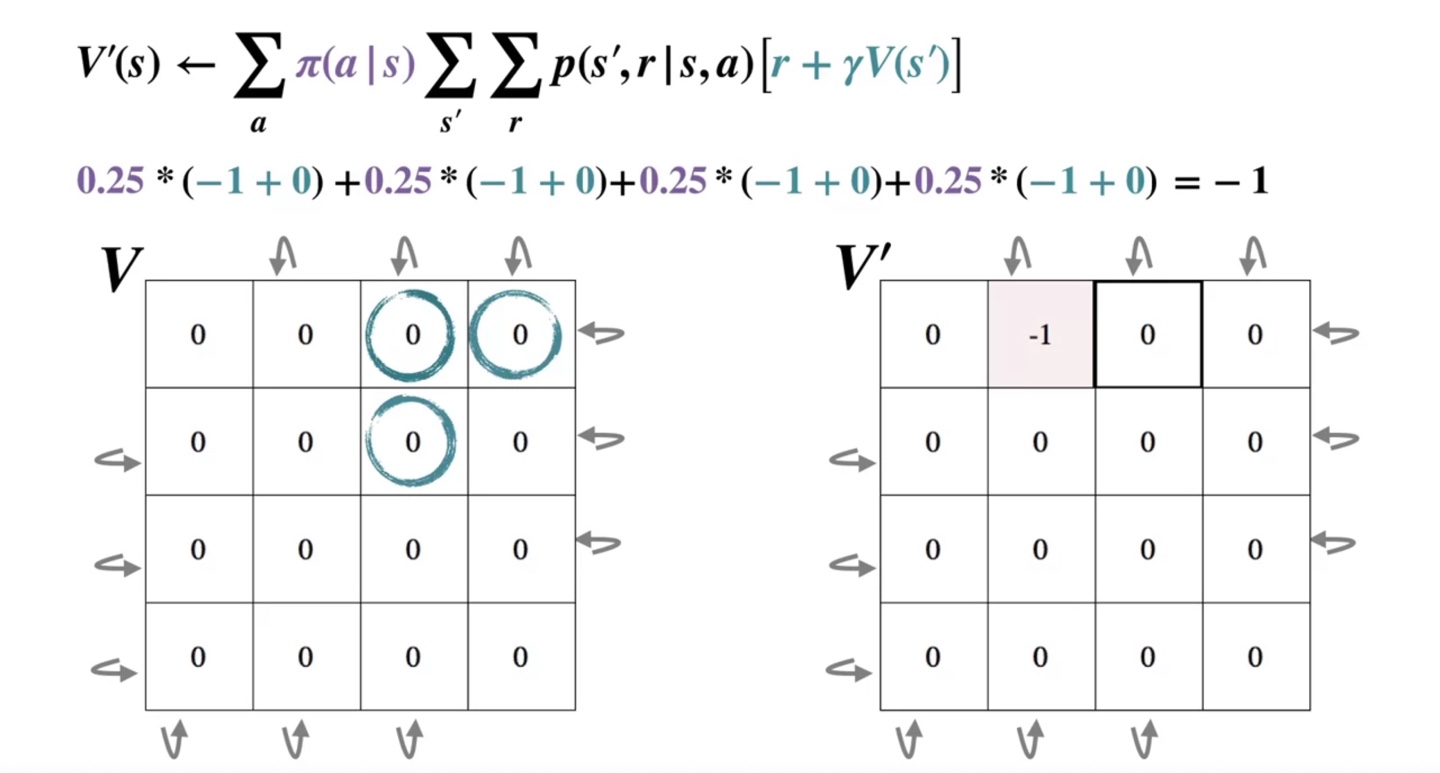
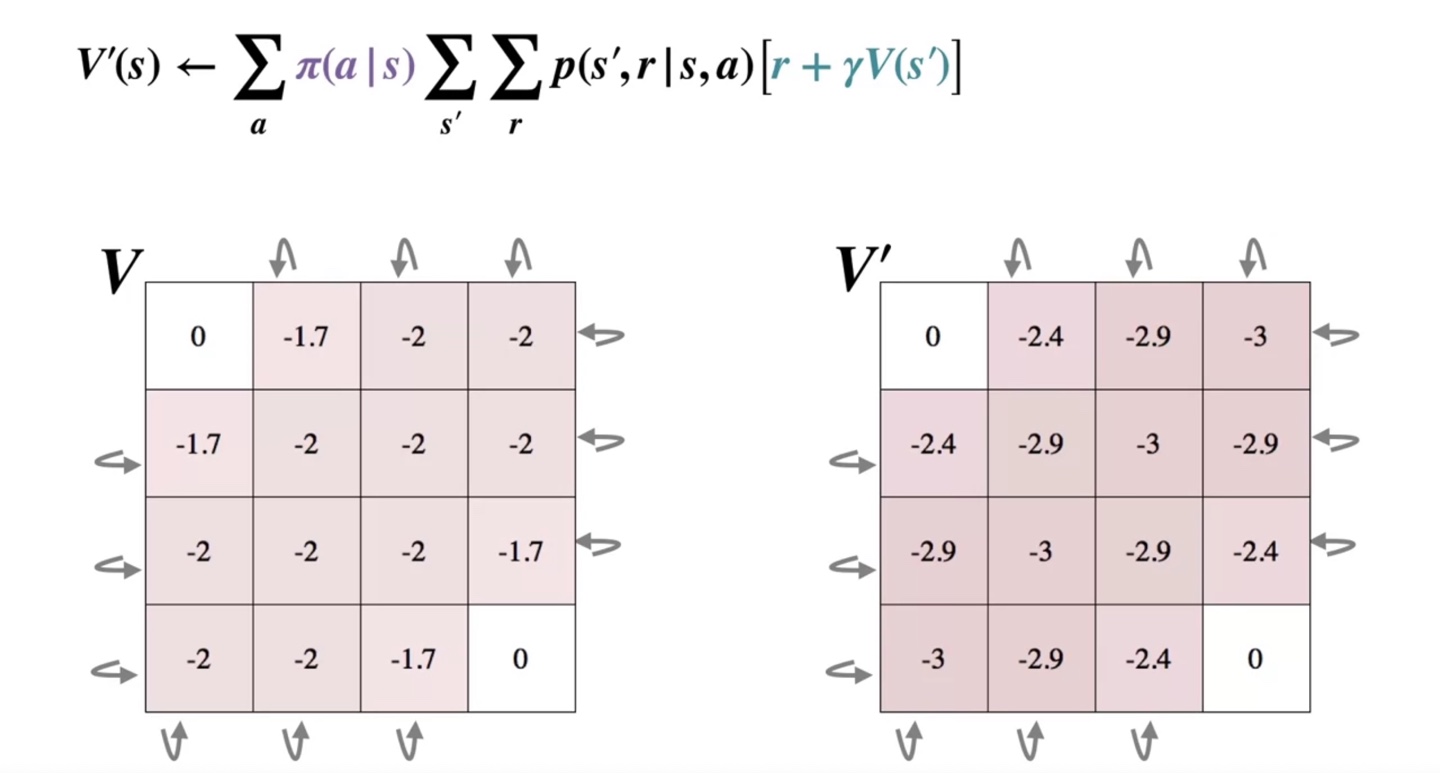
- 이와 같이 한 번의 iteration을 반복하면 아래와 같이 이 기록되고, 이를 에 그대로 복제한다.
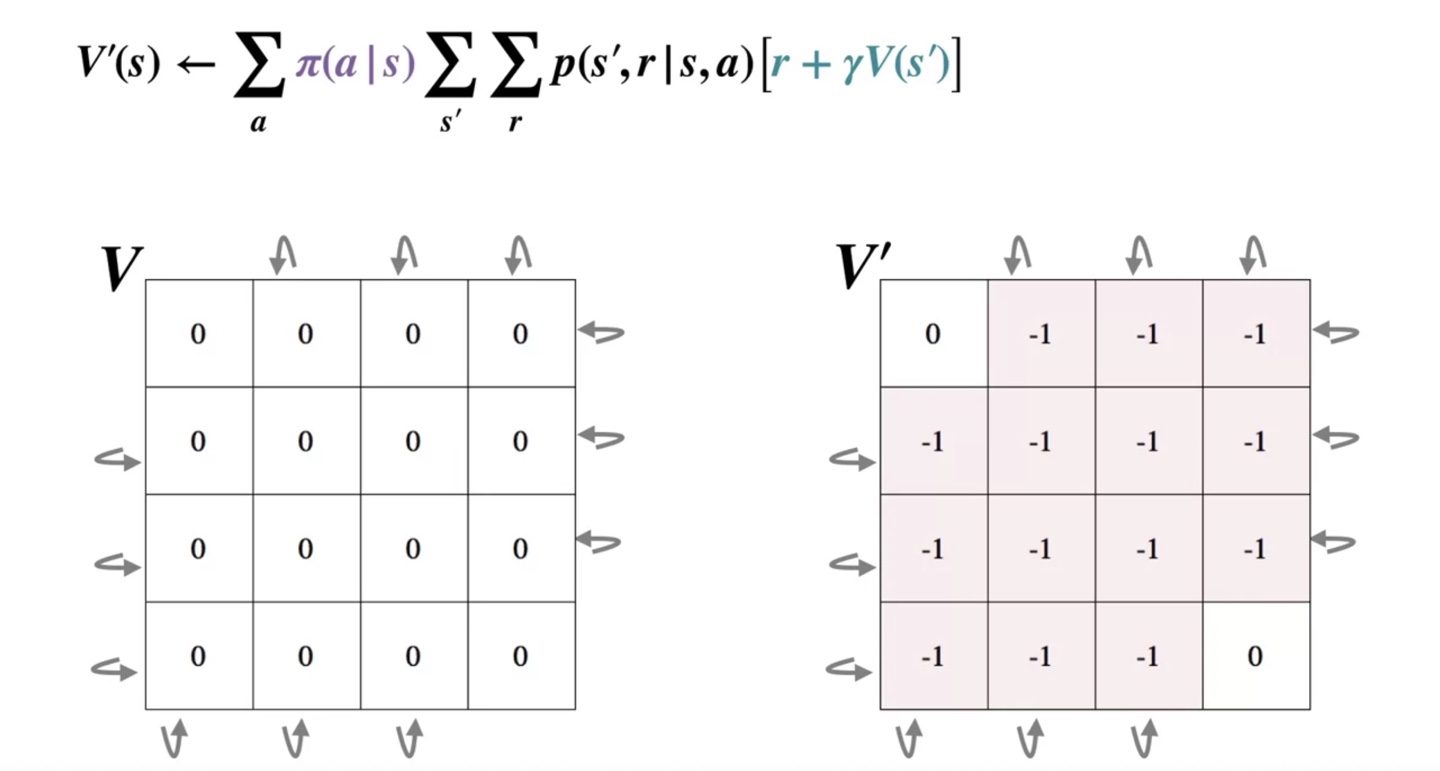
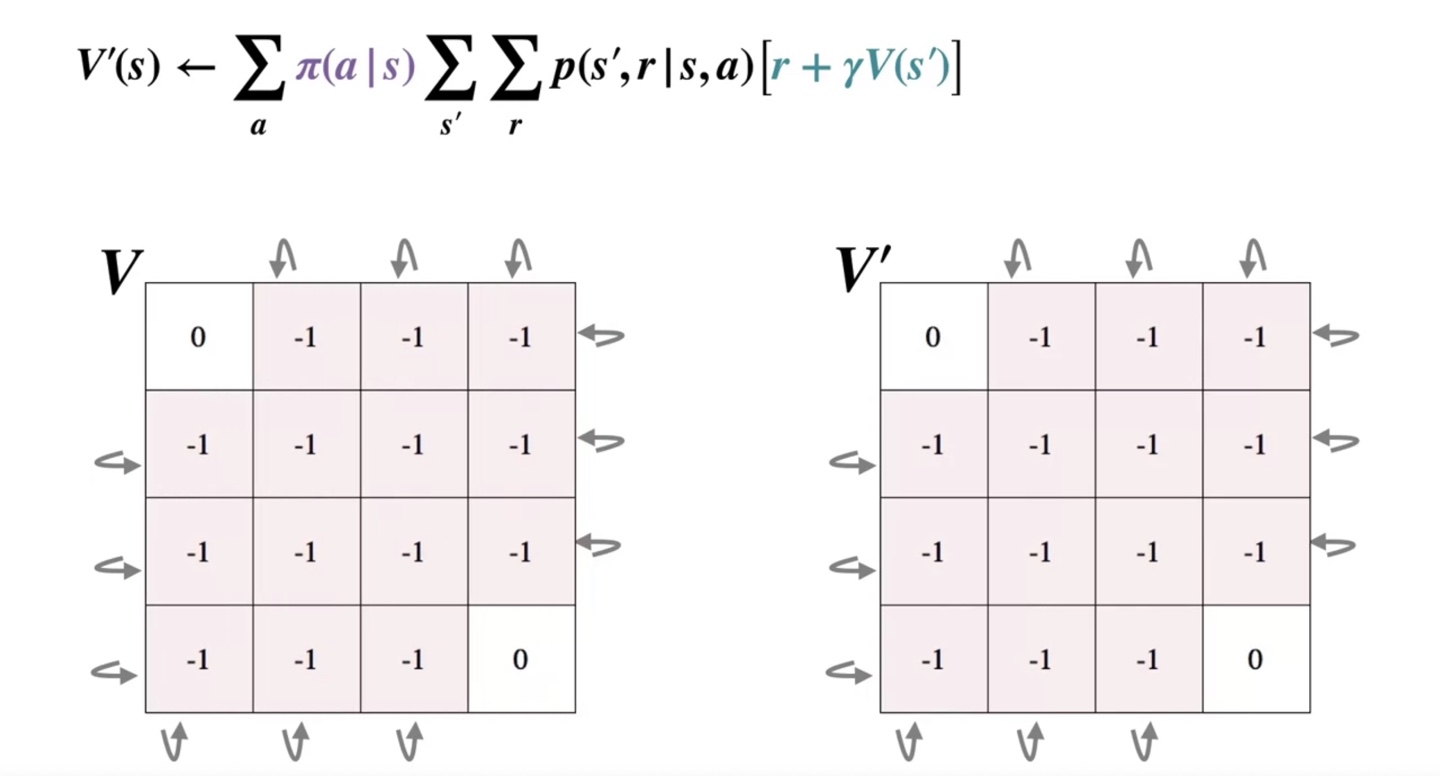
- 이렇게 , , ... 를 반복하여 value를 업데이트 하게 되면 optimal policy인 가 얻어질 것이다.
-
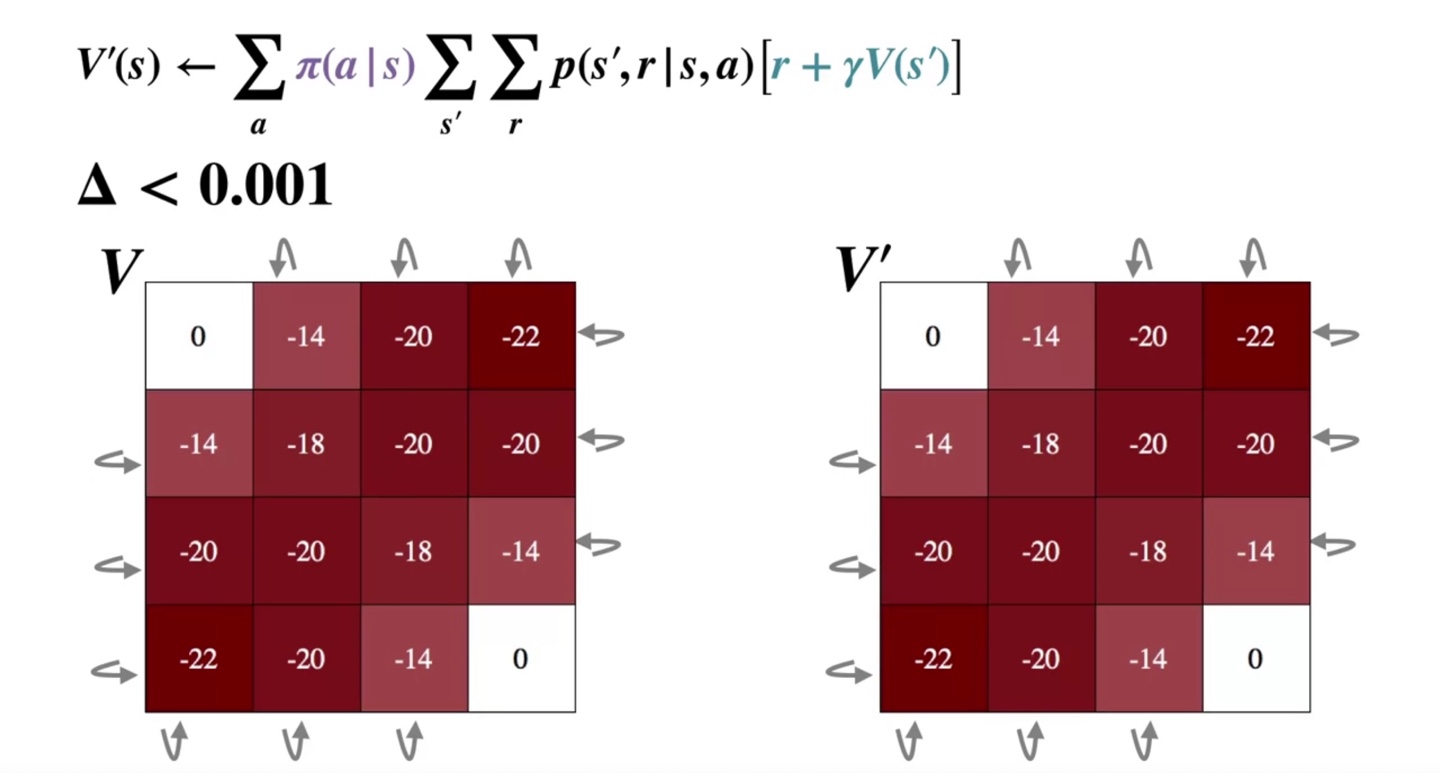
이러한 iteration을 멈추게 할 수 있는 방법은 parameter 를 설정함으로써 해결할 수 있다.
- 변화량의 max값 가 충분히 작은 값인 보다 작을 때 loop을 빠져나가게 하는 것이다.

-
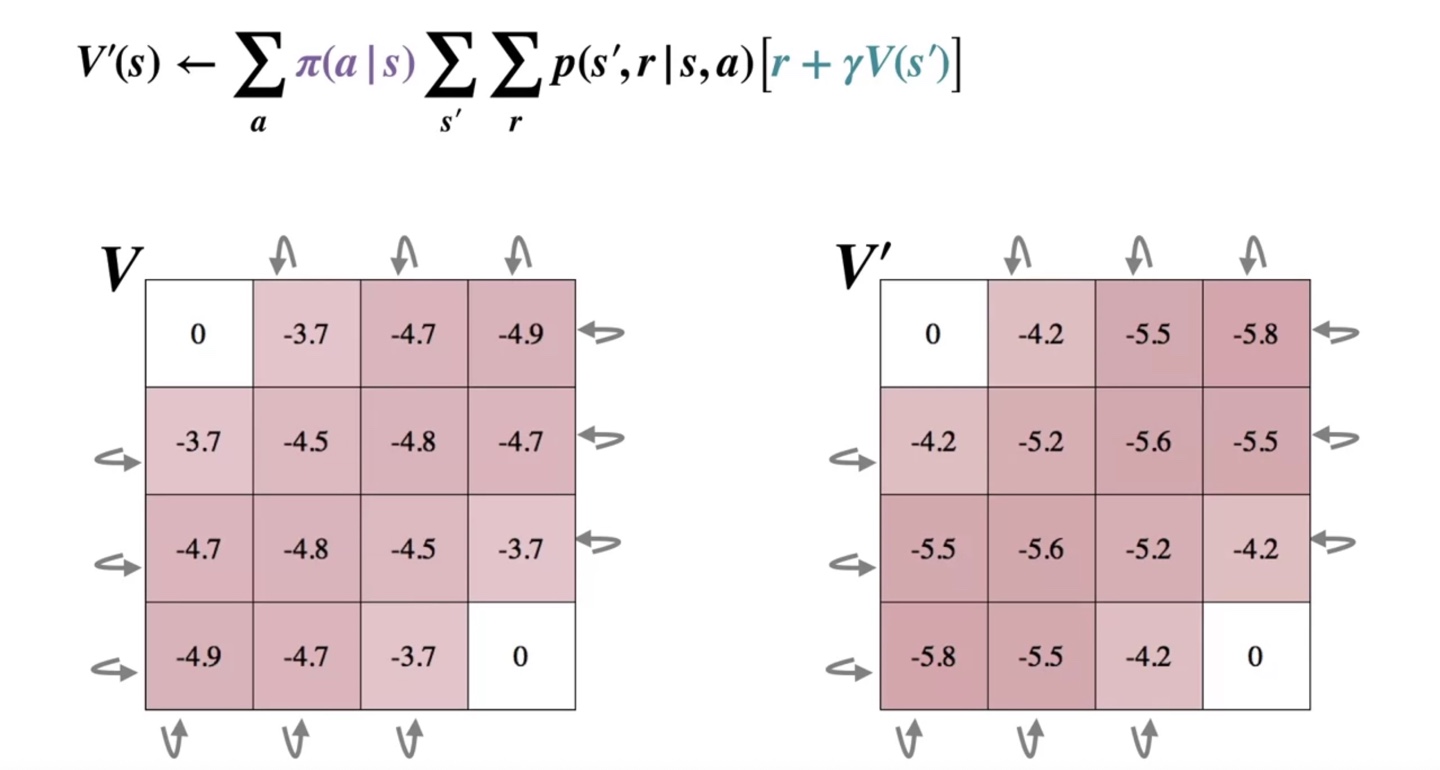
아래와 같이 첫 번째 iteration은 가 1이었기 때문에 계속해서 iteration을 진행한다.
- 이후 계속해서 value가 업데이트 되고 나면 어느 순간 가 보다 작아지는 순간이 찾아온다.
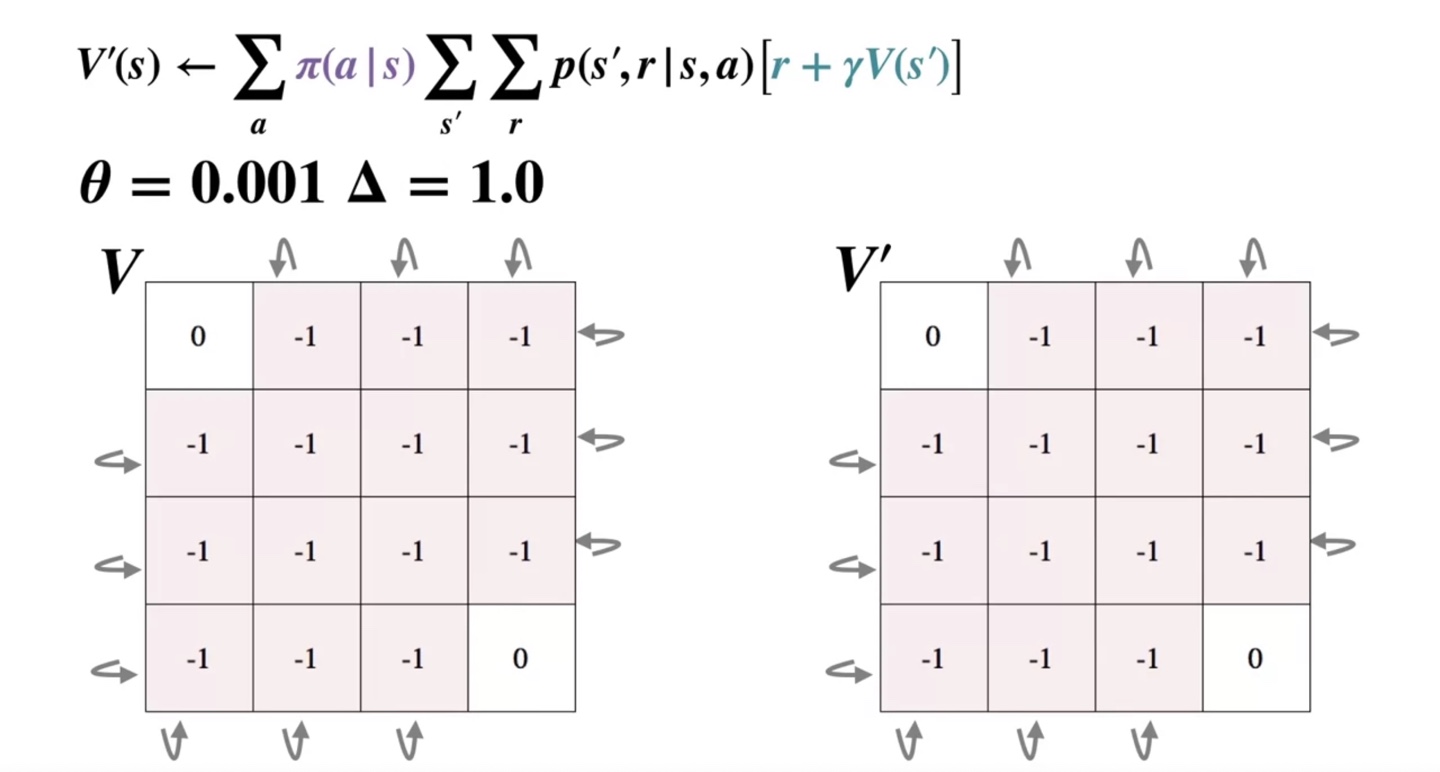
-
아래와 같이 value가 충분히 업데이트 되면 iteration간의 차이가 거의 없을 것이므로 optimal value에 도달하였다고 보아도 좋다.
- 이러한 과정이 바로 policy evaluation by state-value, using iteration이다.
- Summary

Policy Iteration (Control)
Policy Improvement
- Policy Improvement에 대해 알아보자.

- 이번 강의에서는 policy improvement theorem에 대하여 다룬다.

-
Optimal value 의 argmax 즉, greedy하게 value를 선택해 action을 취하면 optimal policy 를 따른다고 하였다.
- 결론적으로 가 Bellman equation을 따르면서 optimal value로 나아간다면 그 때 선택된 policy 는 이미 optimal하다는 것이다!

-
Policy Improvement Theorem은 가 이미 optimal하다는 가정 하에, 적어도 하나의 state에서 더 큰 action-value를 가진다면 더 가치가 높은 policy라고 얘기할 수 있는 정리다.
- 따라서 각 state마다 얻어지는 action-value 에 의해 greedy한 action을 선택하면 항상 기존보다 더 큰 policy임이 보장되는 것이다.

-
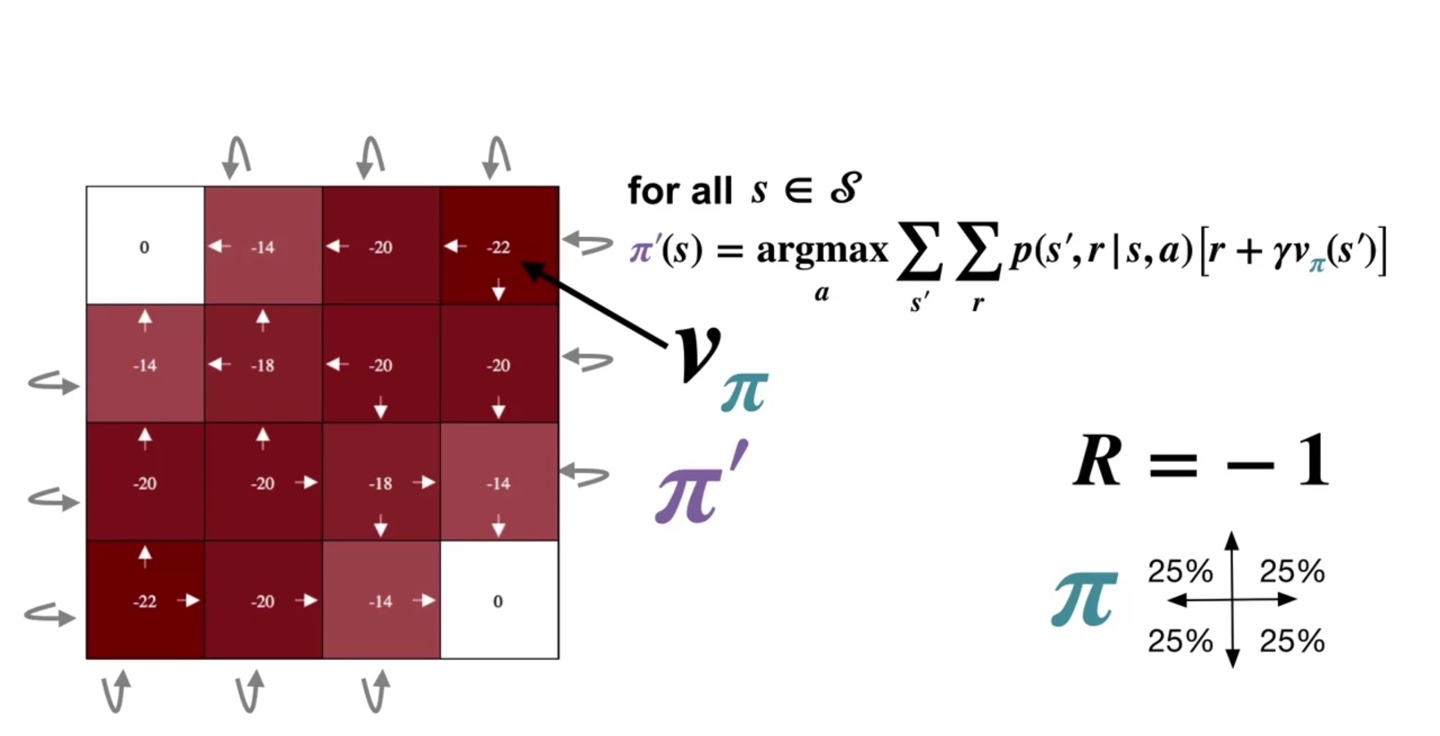
위에서 다루었던 board의 optimal value 를 update해 두고, greedy한 action을 선택하게끔 만들어보자.
-
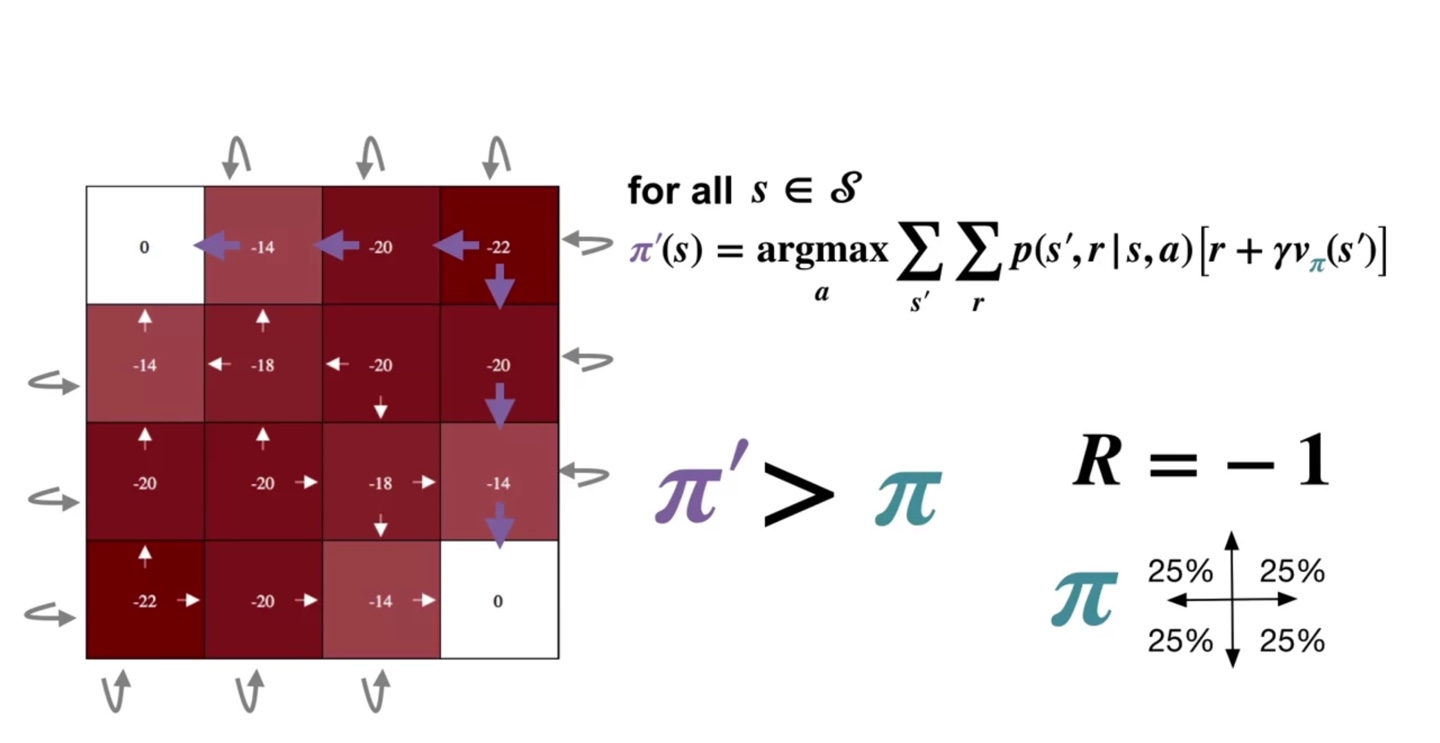
Value의 argmax를 취하도록 만들었더니 기존 policy에 비해 훨씬 향상된 경로로 value를 maximize하는 것이 가능해졌다.
- 따라서 상하좌우의 기존 policy 에서 보라색으로 색칠된 경로 policy 로 업데이트 되었다. ()
-
- Summary

Policy Iteration
- Policy Iteration에 대해 알아보자.
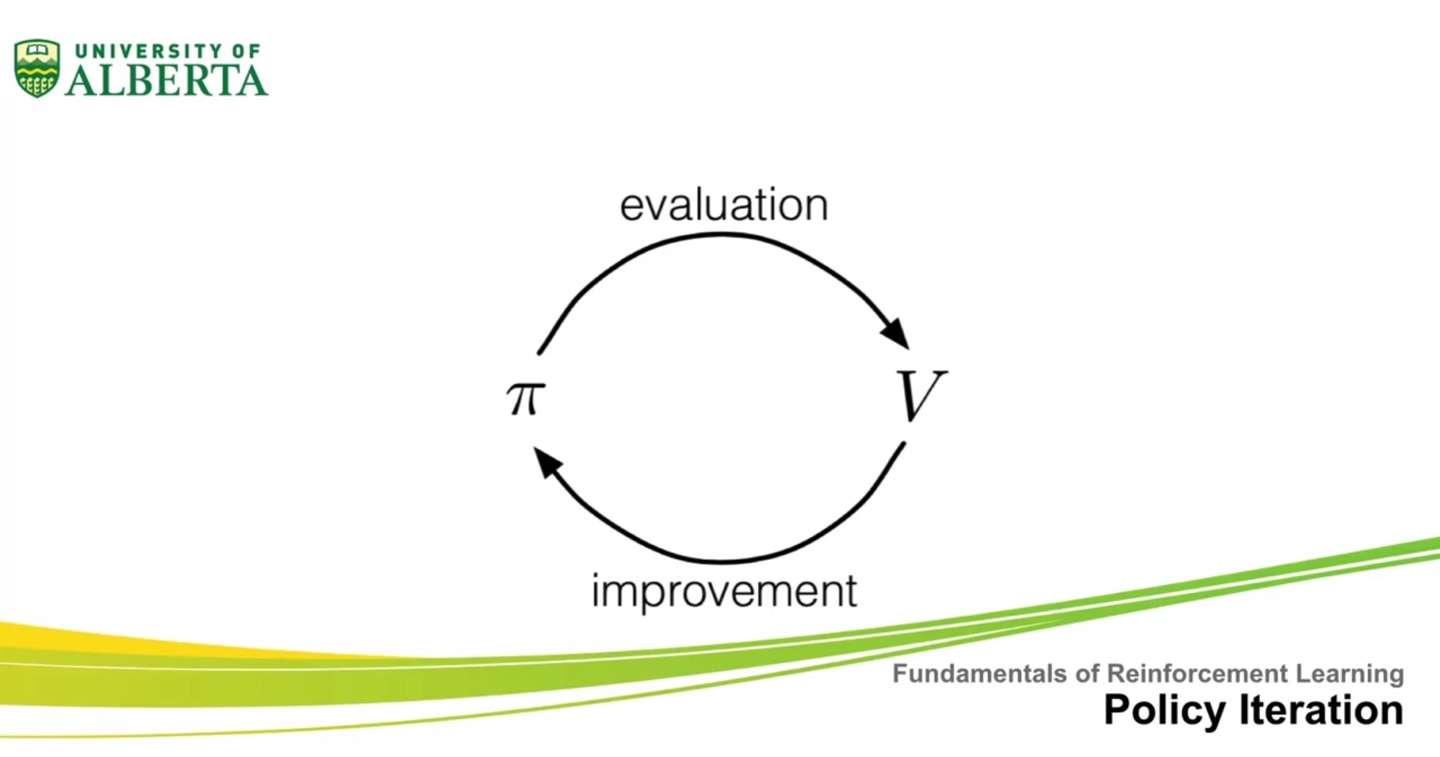
- 이번 강의에서는 policy iteration 알고리즘과 policy and value dance를 이해하고, optimal policies와 optimal values를 찾기 위해 policy iteration을 어떻게 적용하는지 대해 다뤄보려 한다.

-
Policy Improvement Theorem은 미래 state에서의 expected value를 argmax 취하여, greedy한 action으로 policy 를 업데이트하는 과정을 말한다.
- 이 때 improved된 policy 은 기존 에 비해 "strictly" better하다.

-
Policy Evaluation과 policy improvement를 반복하며 policy를 향상시키다 보면 이전 policy에 비해 항상 더 큰 value를 가진다는 것을 알 수 있다.
- 즉, deterministic policy를 선택해 나가면서 optimal policy를 찾아나가는 과정이라 볼 수 있는 것이다.




-
Policy Iteration은 아래와 같은 일련의 과정으로 evaluation과 improvement가 반복된다.
- 그러다보면 촤종 optimal value인 와 를 찾게 된다.
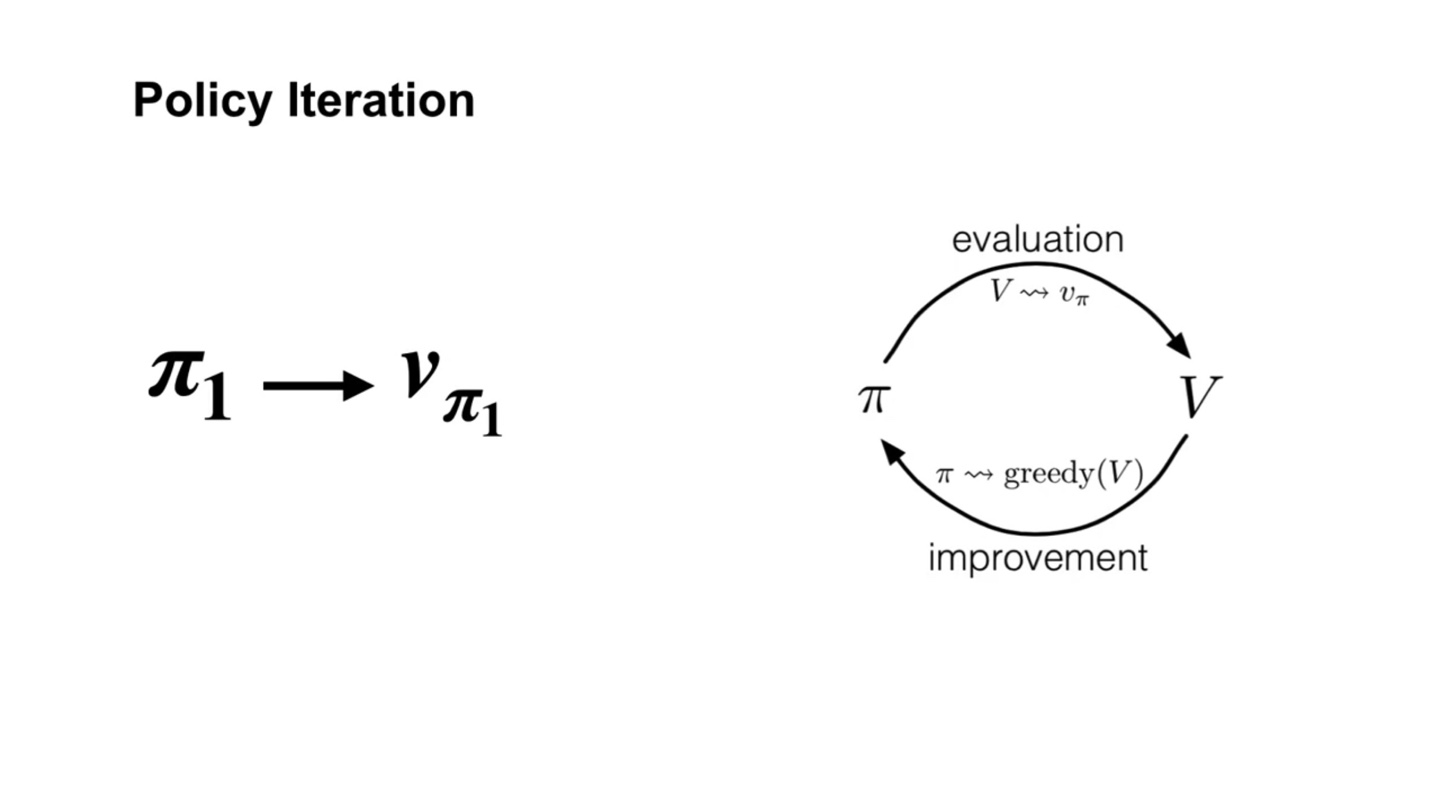
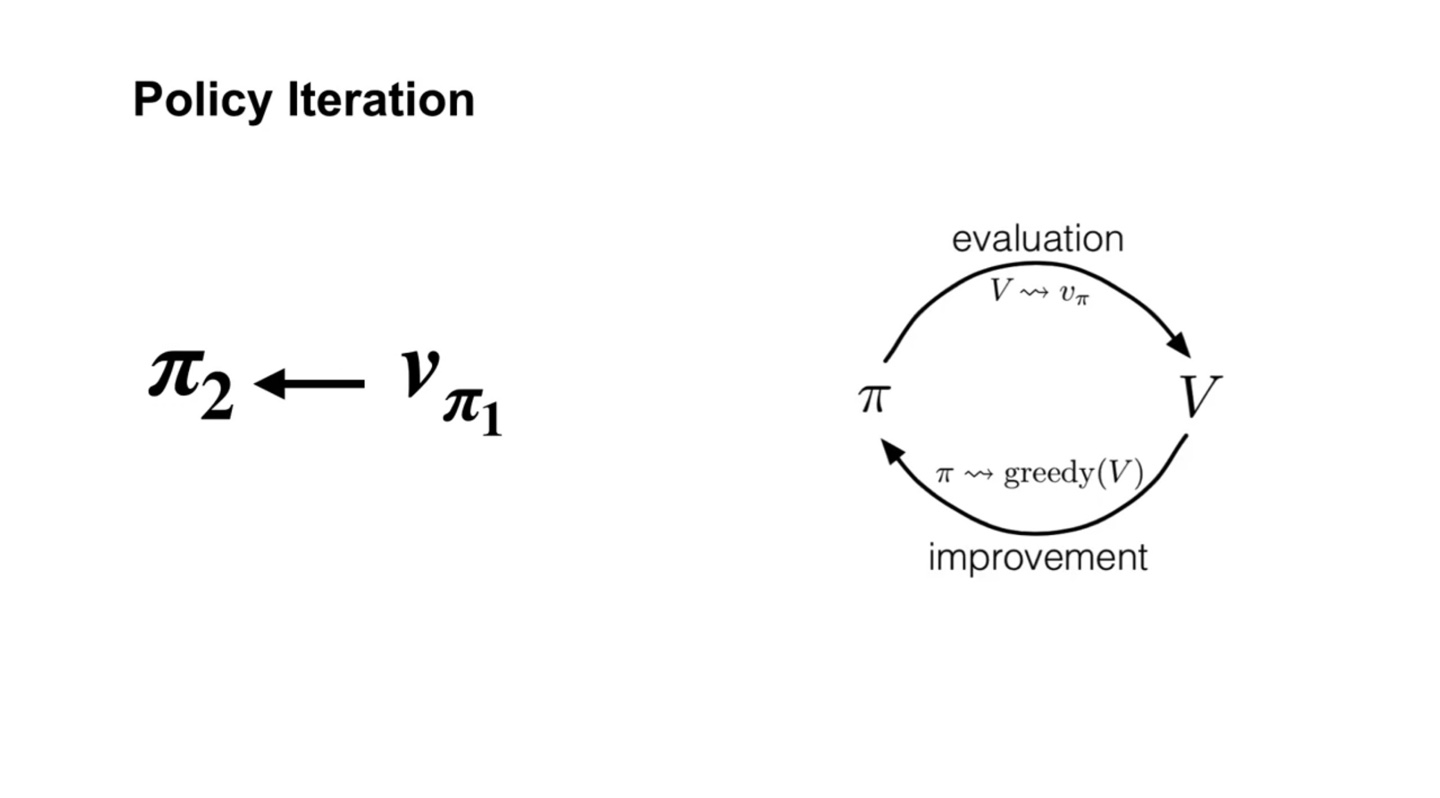
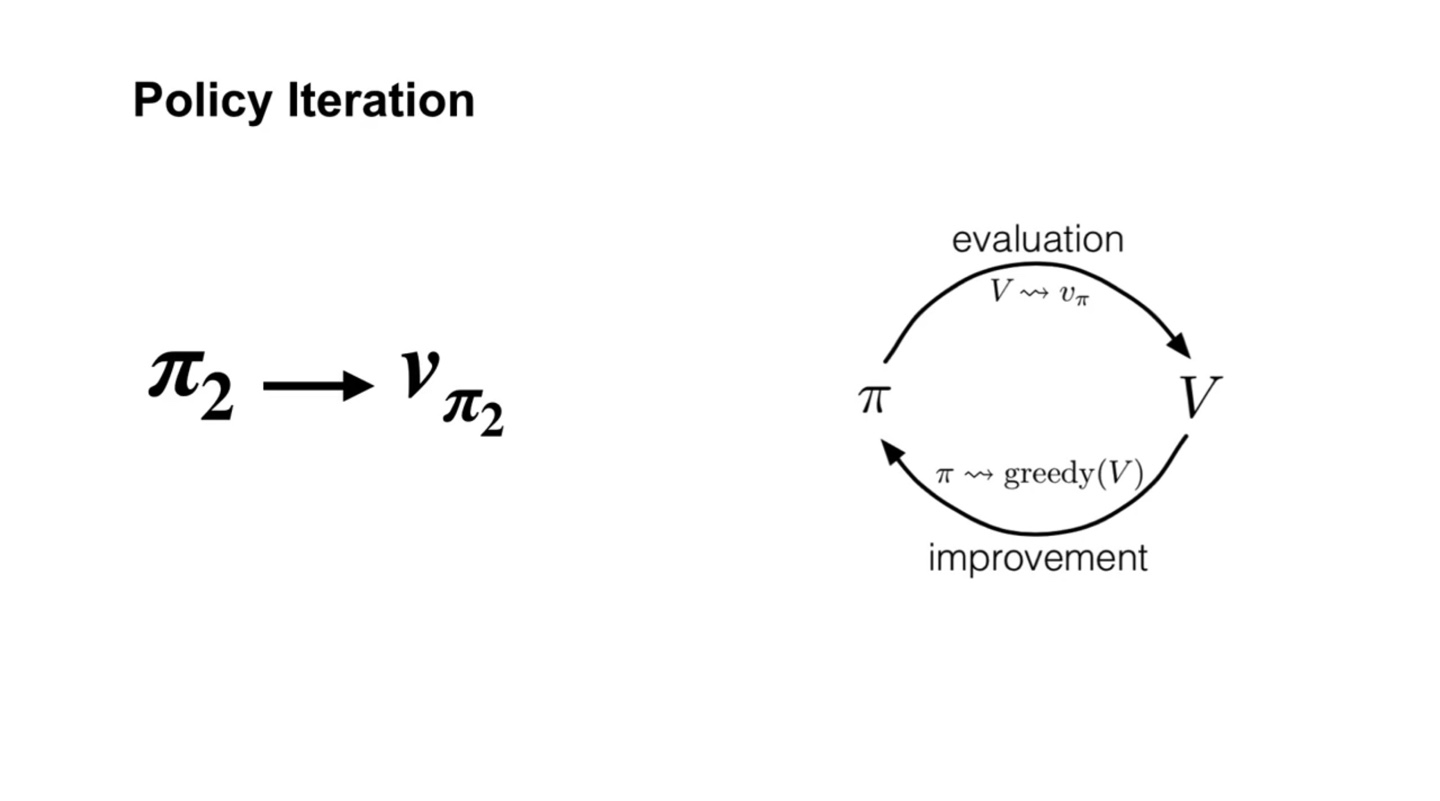
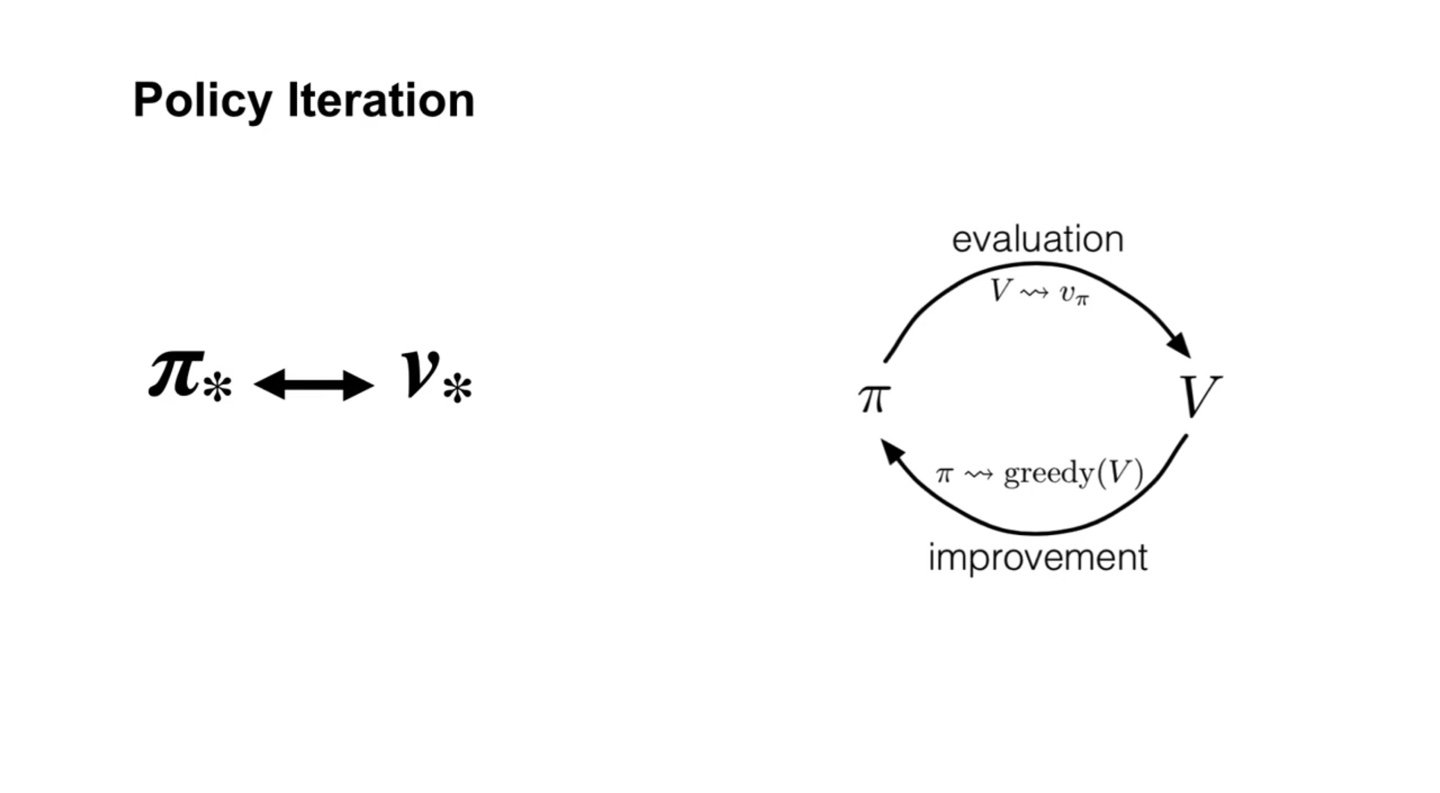
-
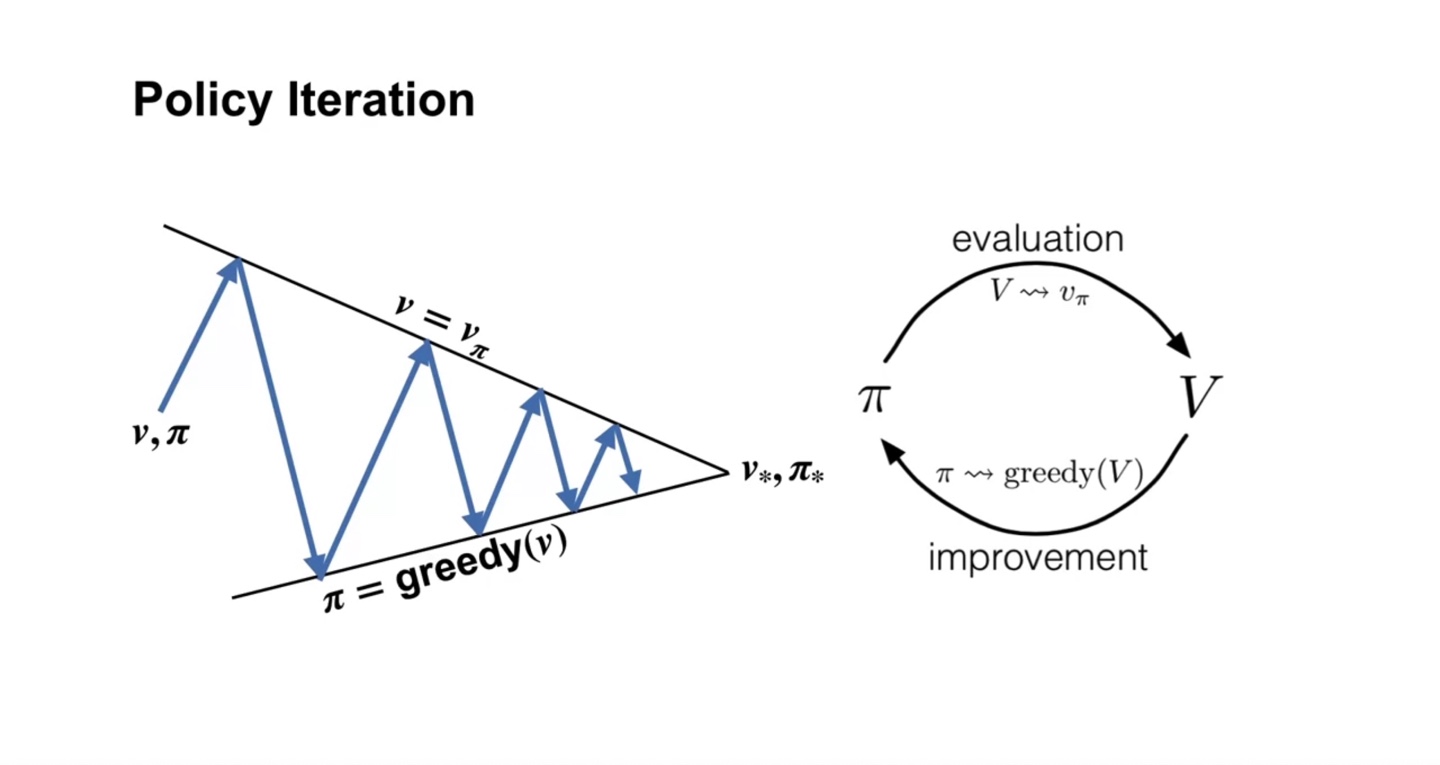
Policy iteration은 이와 같이 evaluation과 improvement(greedy selection)하는 과정을 반복하며 dancing한다.
- 그러다 보면 optimal value, optimal policy로 수렴해 나가게 되는 과정을 표현한 것이라 할 수 있다.
-
Policy iteration 알고리즘은 아래 sudo code와 같다.
- 크게 evalution과 improvement를 반복하는 과정이 보인다.

-
이제 아래와 같은 새로운 board판이 놓여졌다고 해보자.
- 파란색으로 색칠되어져 있는 부분의 Reward는 -10이고, 그 외의 부분은 -1의 값을 가진다.
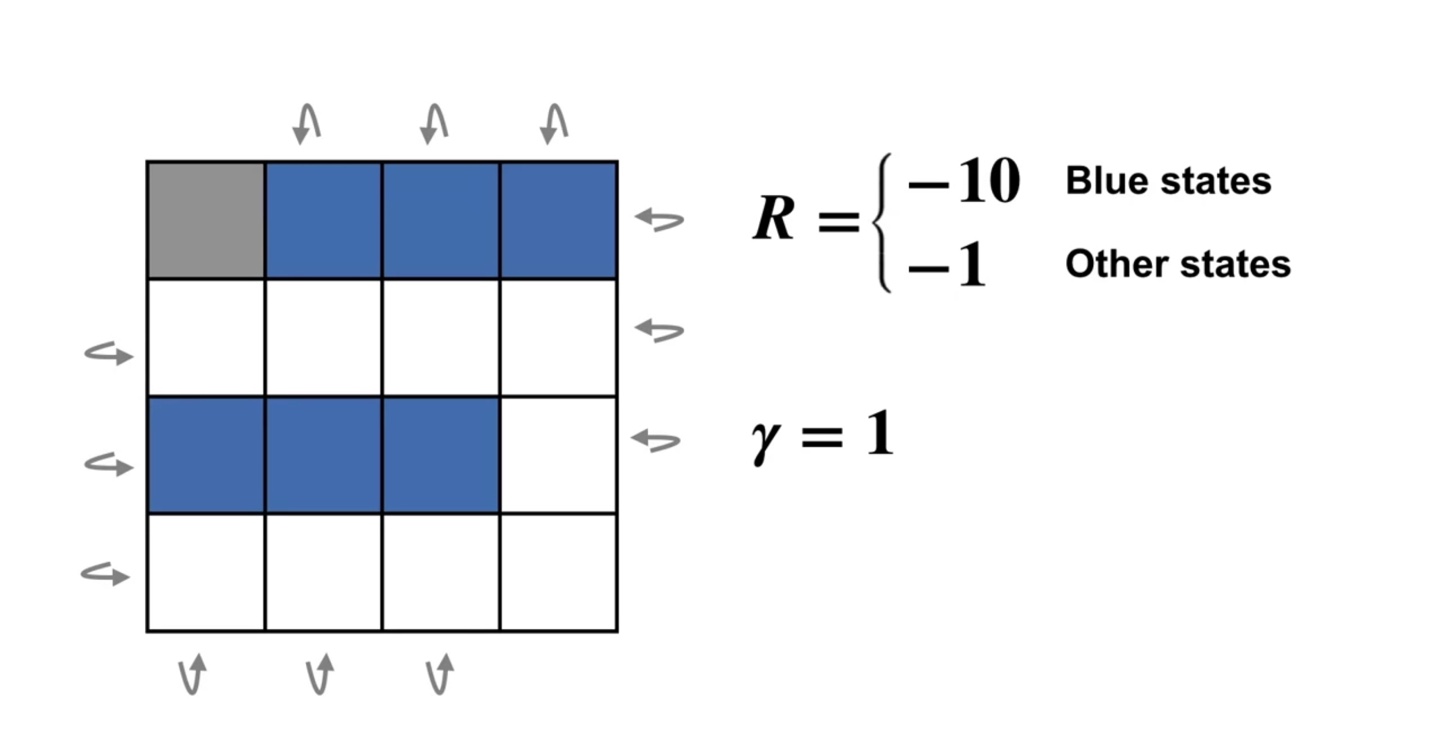
-
아래 판에 적힌 value는 한번의 Policy Evalution(sweep)을 통해 업데이트 된 상태를 나타낸다.
- 아직 policy는 상하좌우 모든 경우의 수를 따르고 있다.
-
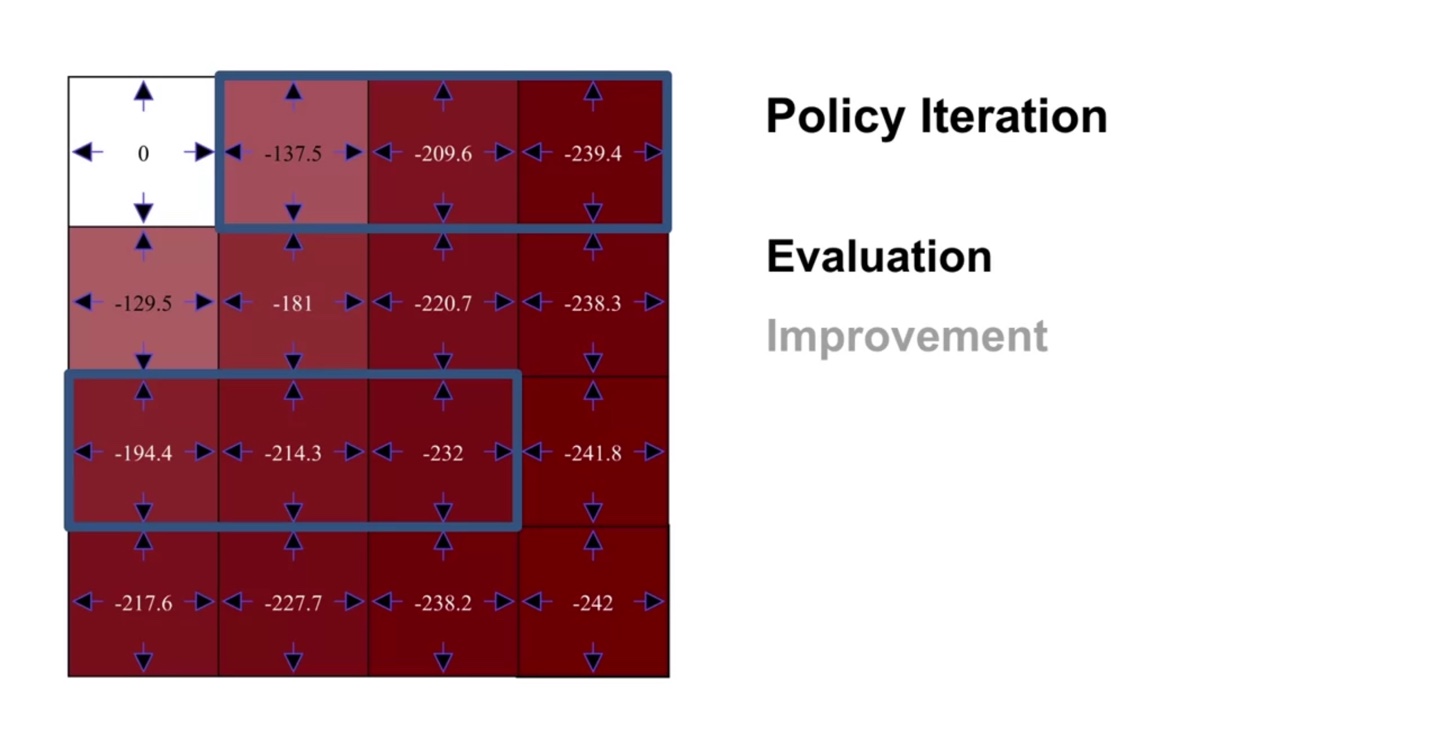
최종 evaluation 결과는 아래와 같고 이를 바탕으로 최종 policy improvement를 해보자.
- Greedy한 action을 취하면 다음과 같이 보라색으로 표시된 policy로 최종 업데이트 되었음을 알 수 있다.
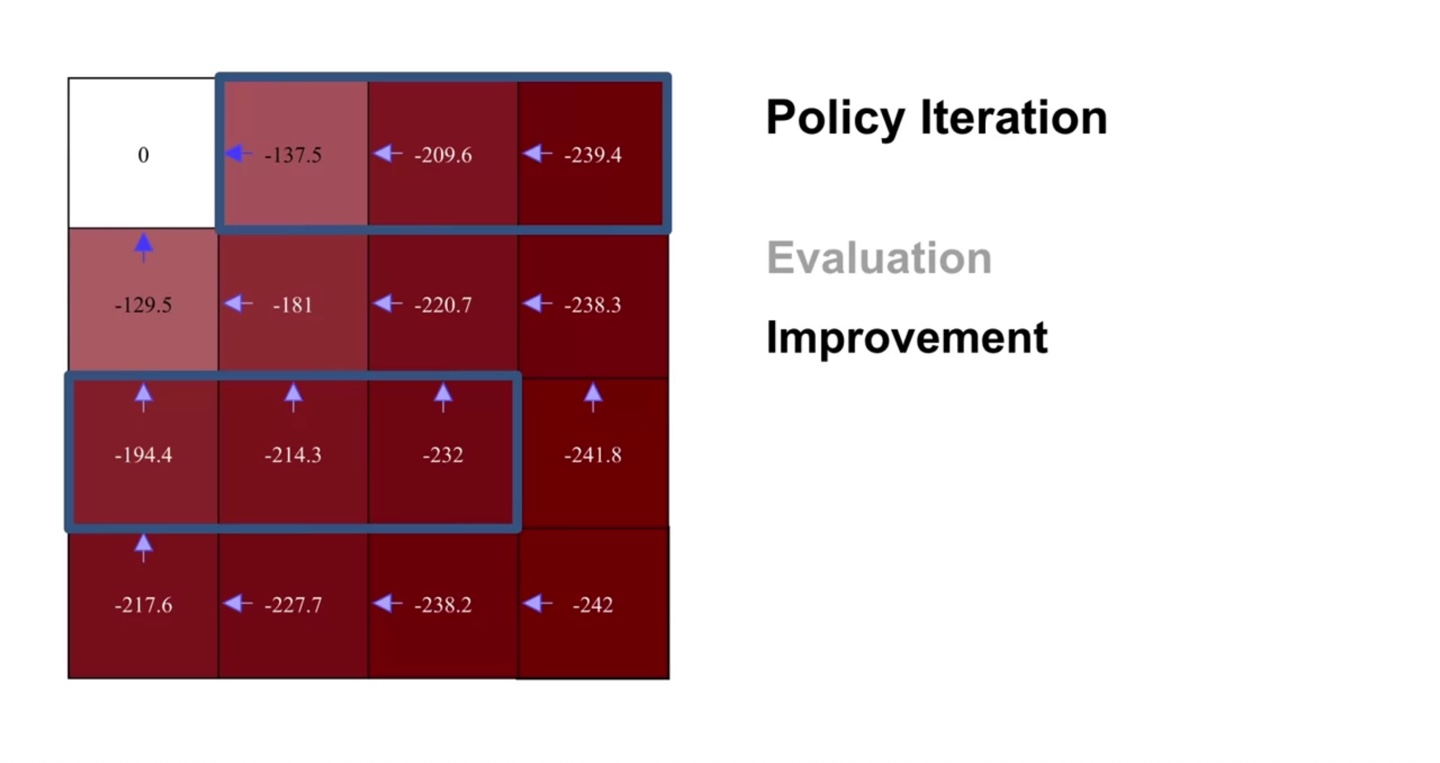
-
이제 첫 evaluation sweep과 improvement로 policy를 순차적으로 업데이트 해보자.
- 4행 3열의 policy가 improvement되었다.
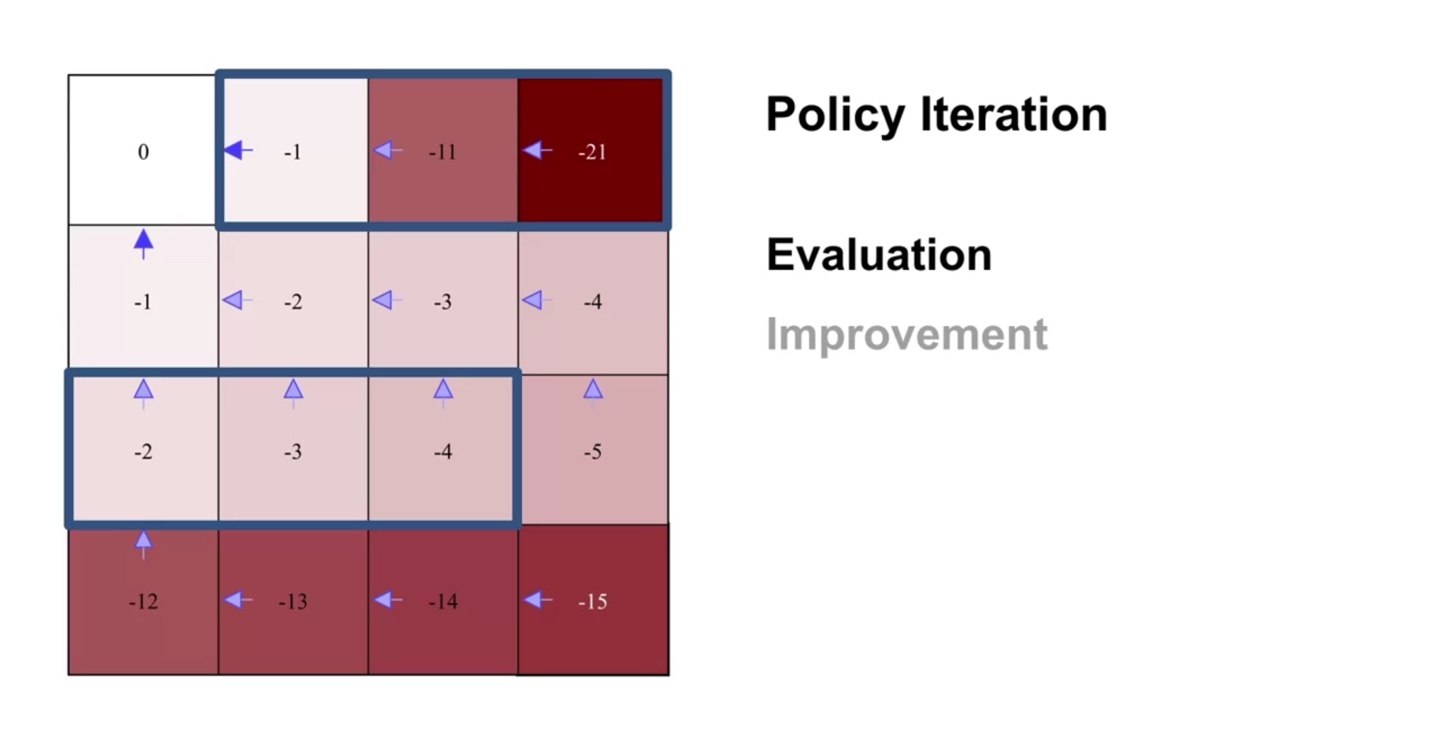
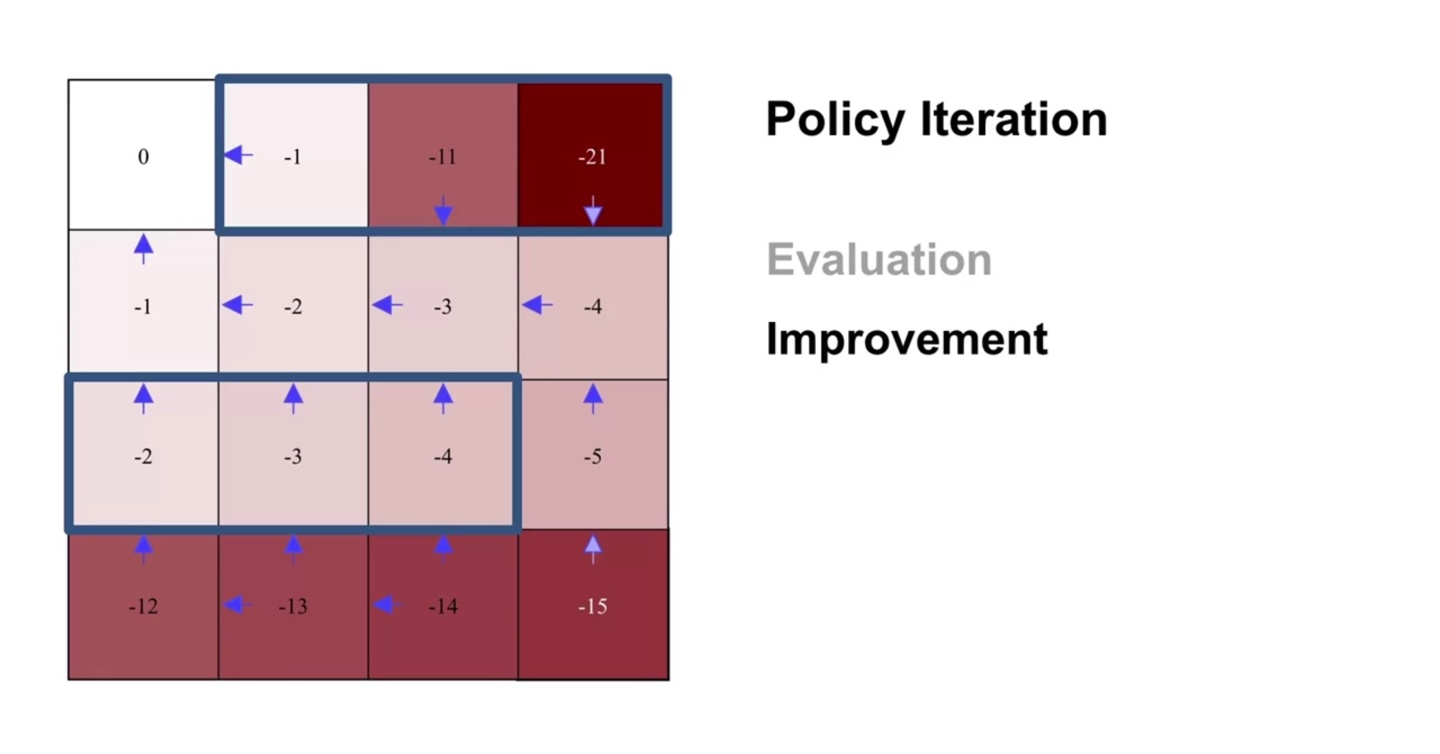
-
두 번째 evaluation sweep과 improvement를 반복해보자.
- 4행 3열의 policy가 또 한 번 improvement되었다.
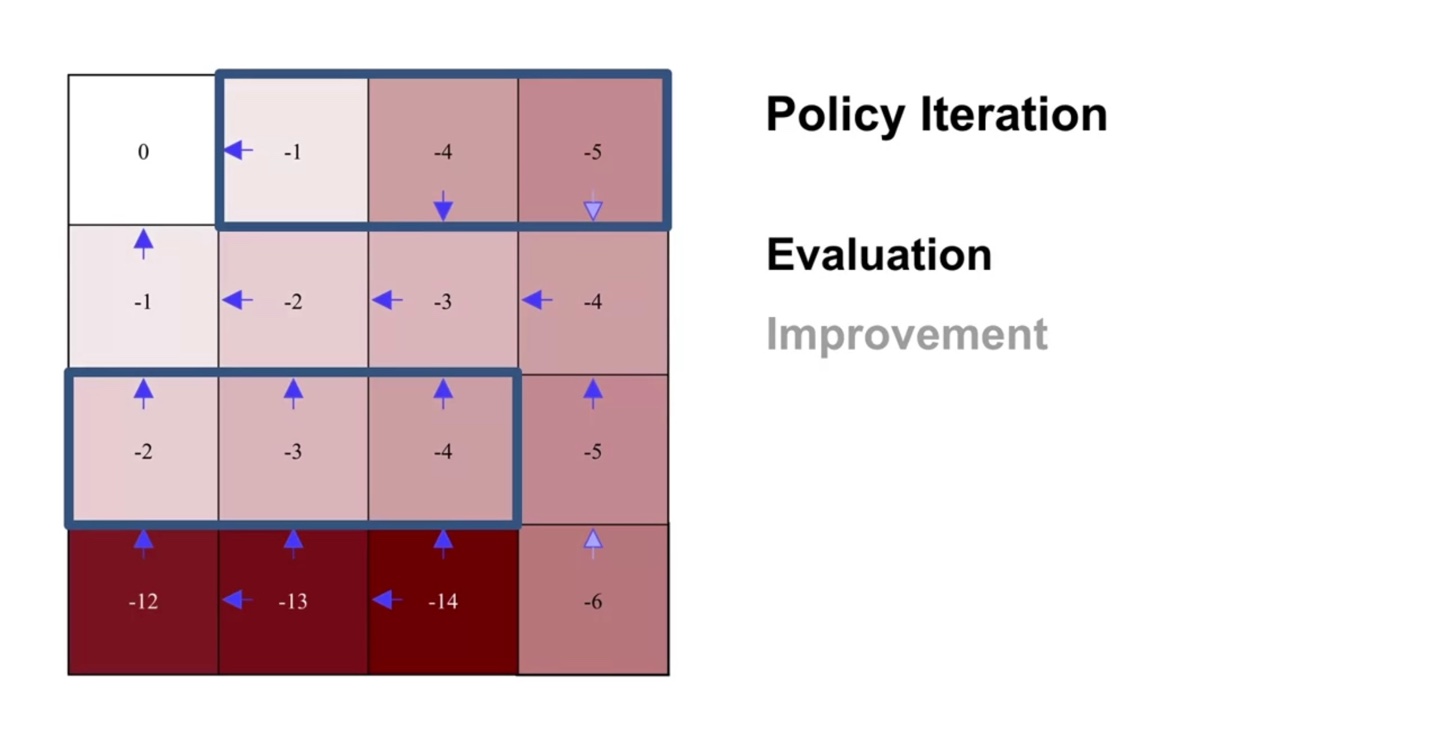
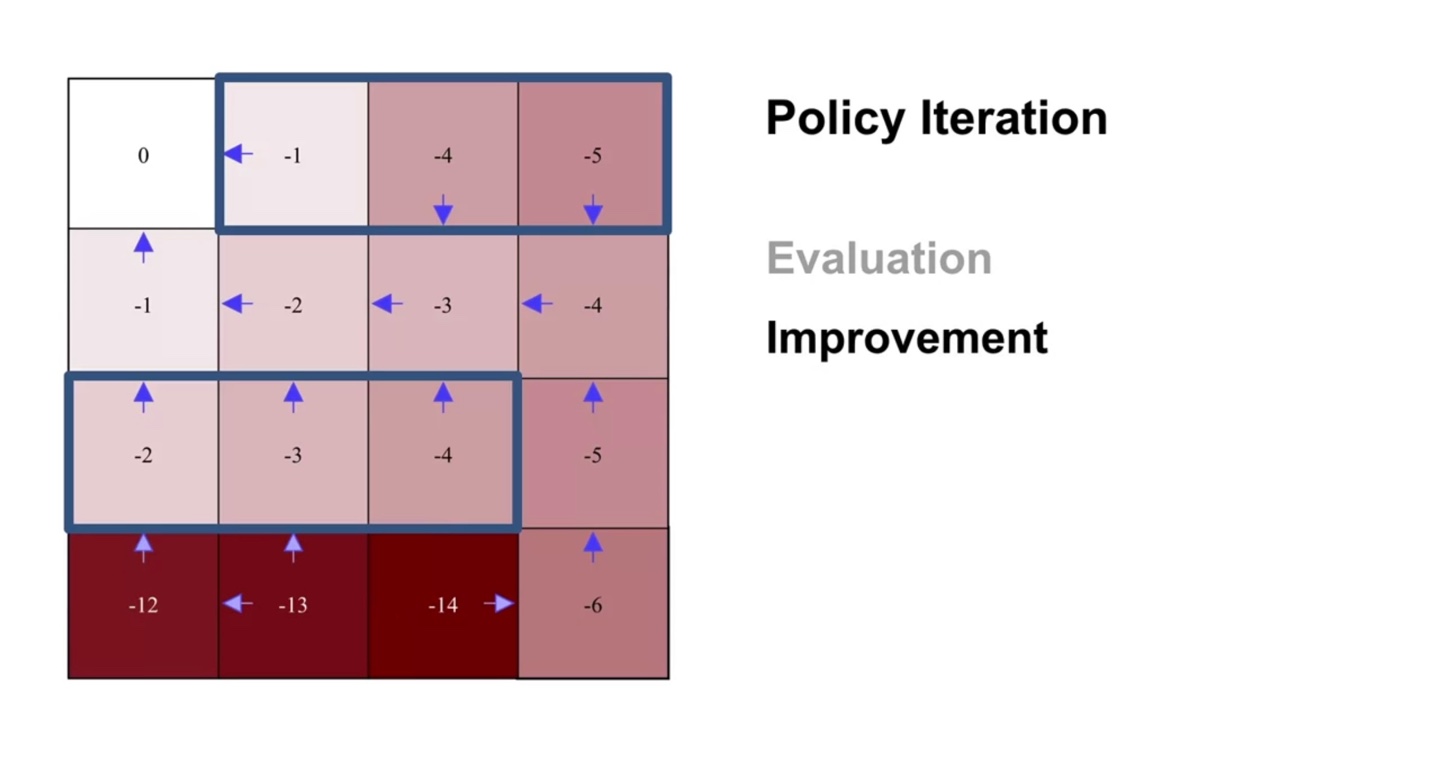
-
세 번째 evaluation sweep과 improvement를 반복해보자.
- 4행 1열의 policy가 improvement되었다.
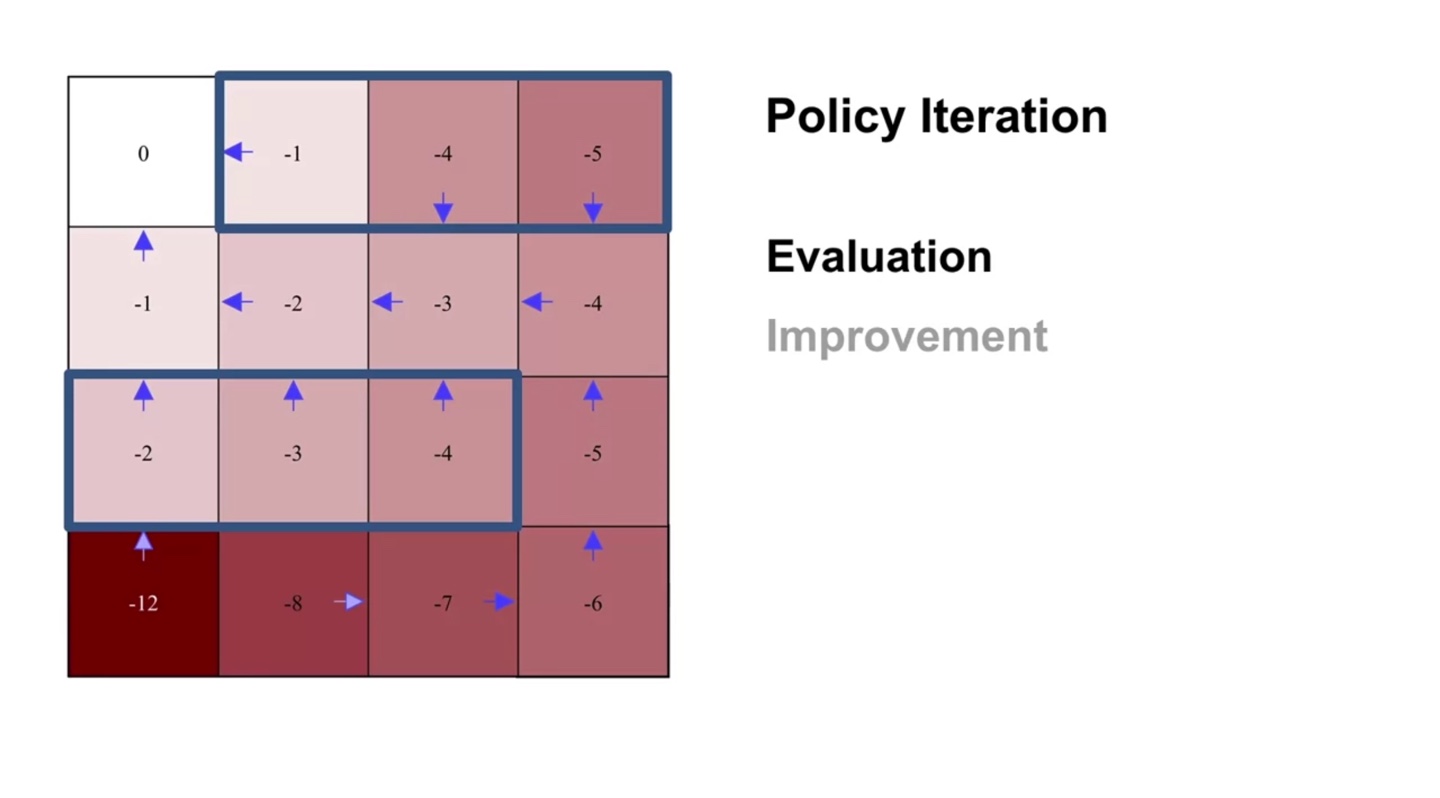
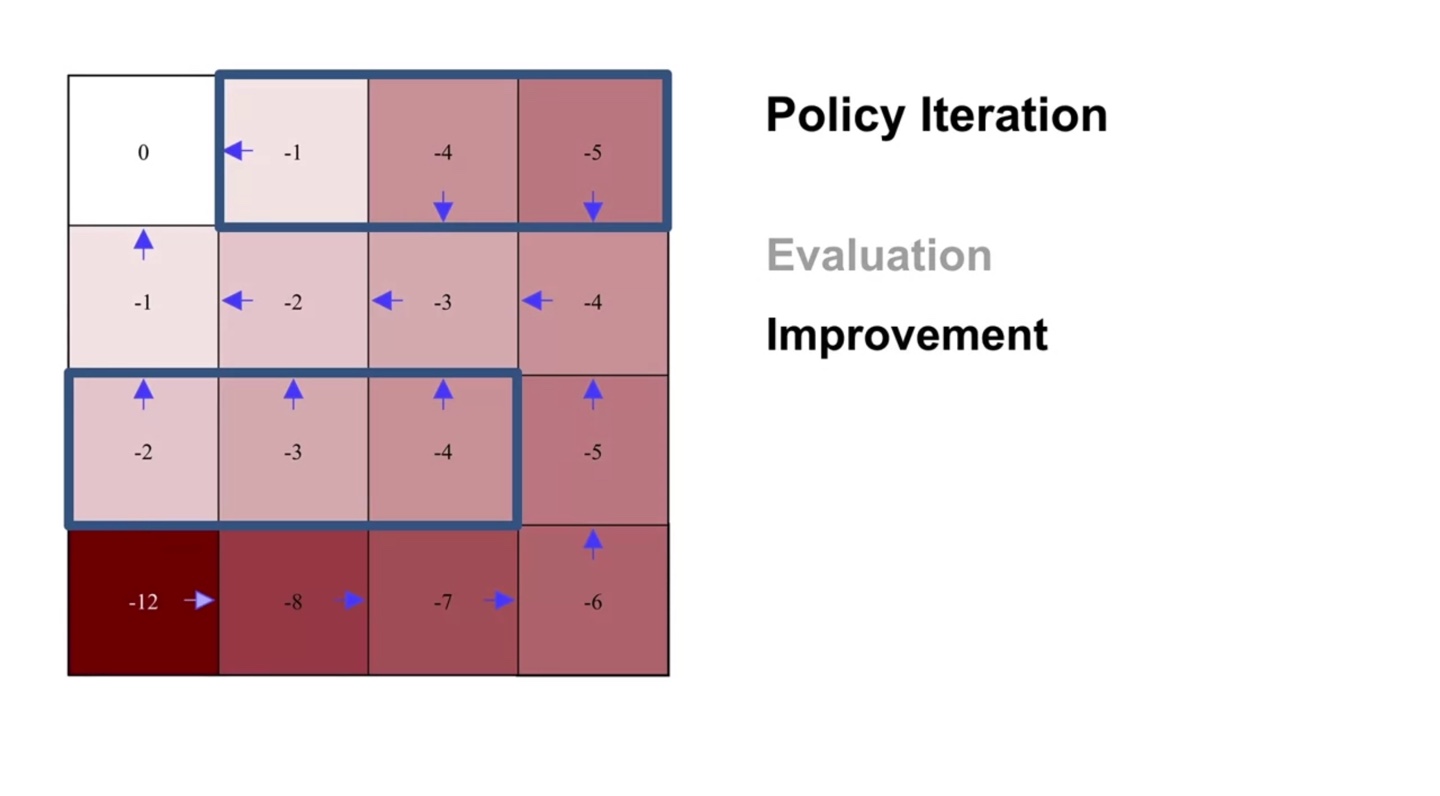
-
또 한 번의 evaluation sweep으로 value가 바뀌었고 이를 바탕으로 policy improvement한 결과, 어떠한 policy도 업데이트 되지 않았다.
- 즉, 더 이상 policy가 향상되지 않을 것이라 판단하여 policy iteration을 멈춘다.
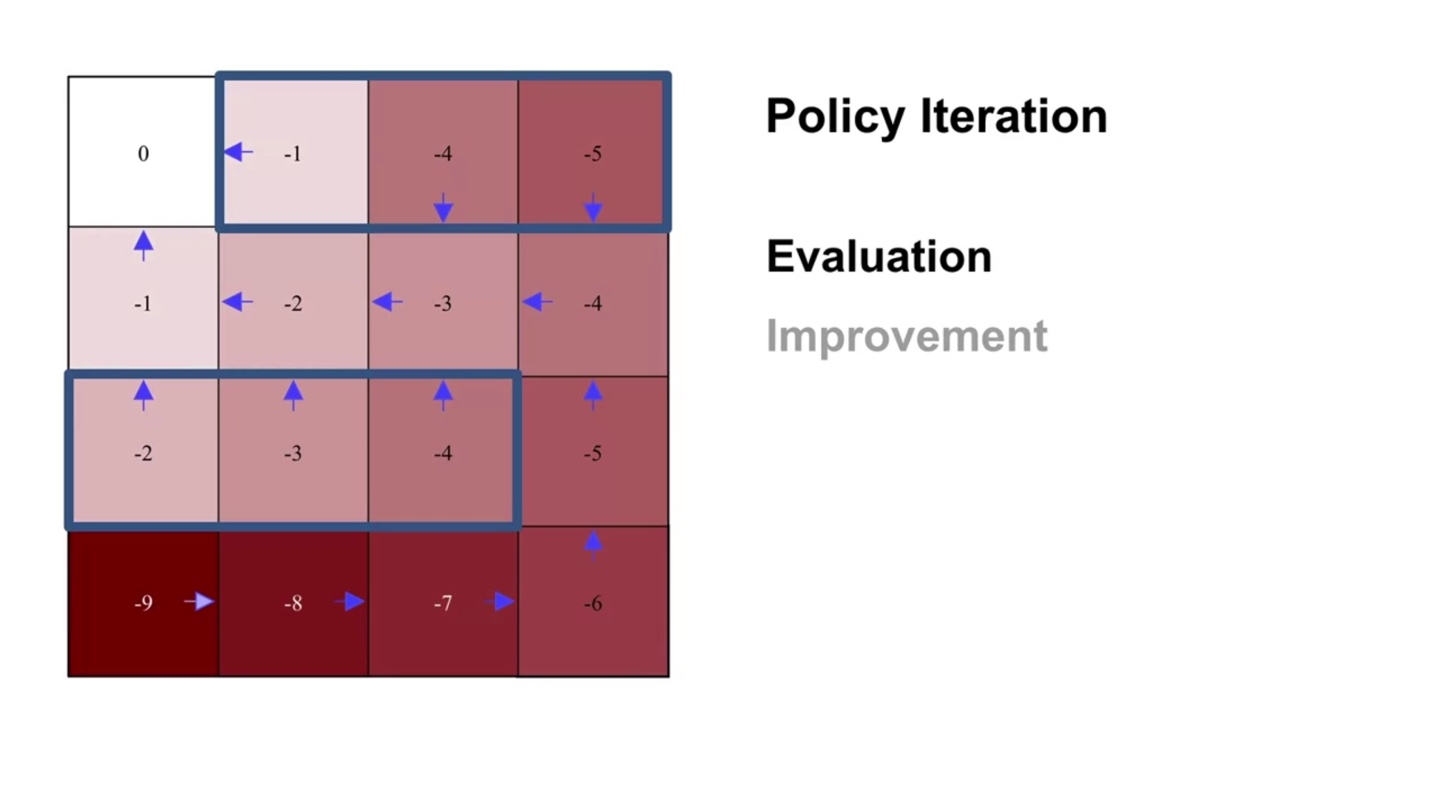
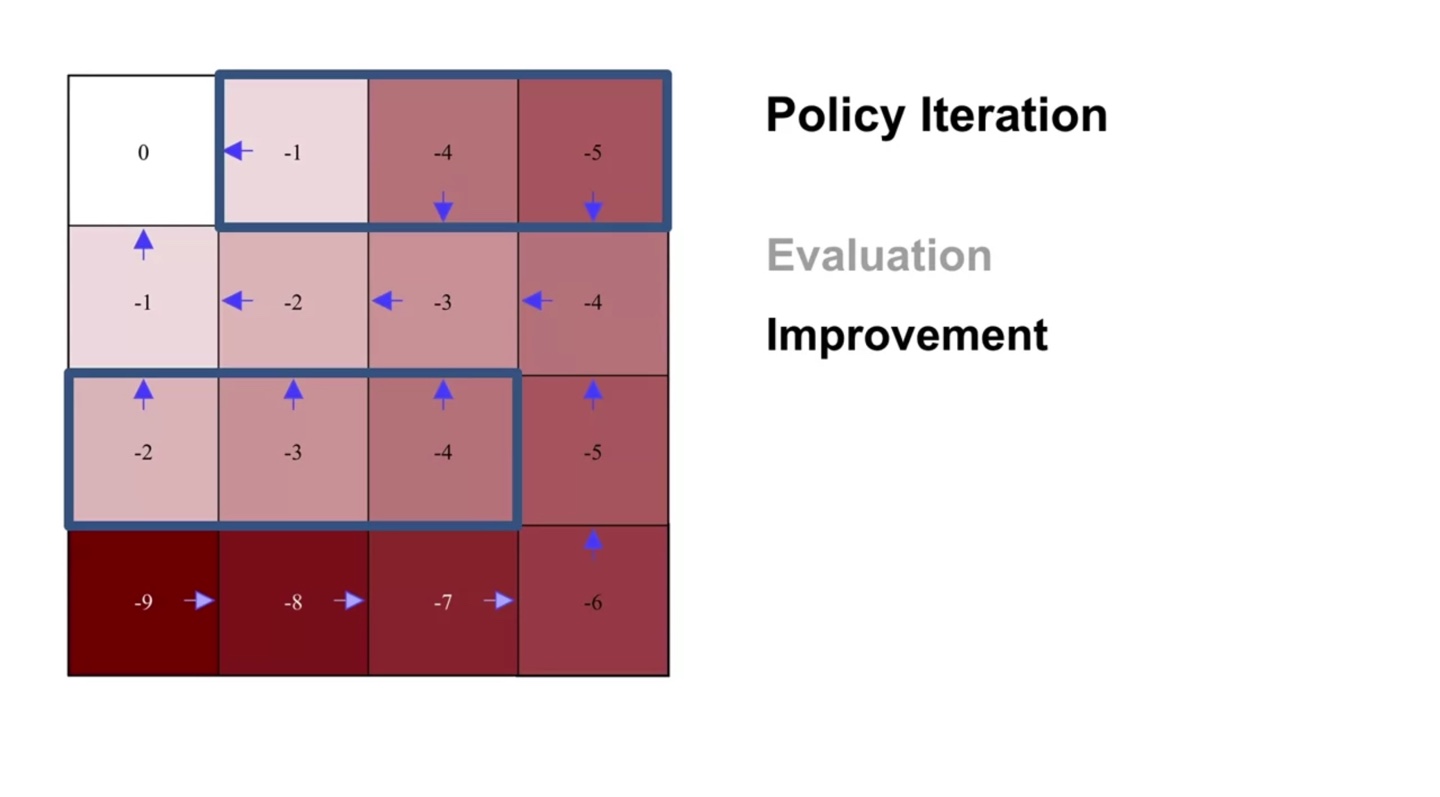
-
Policy iteration은 각 policy가 deterministic하다는 관점에서 출발하여 optimal policy를 찾아나가는 과정이다.
- 계속해서 선택한 improved된 policy는 이전 policy에 비해 더 나은 value를 가진다!

- Summary

Generalized Policy Iteration
Flexibility of the Policy Iteration Framework
- Policy Iteration Framework의 유연성에 대해 알아보자.
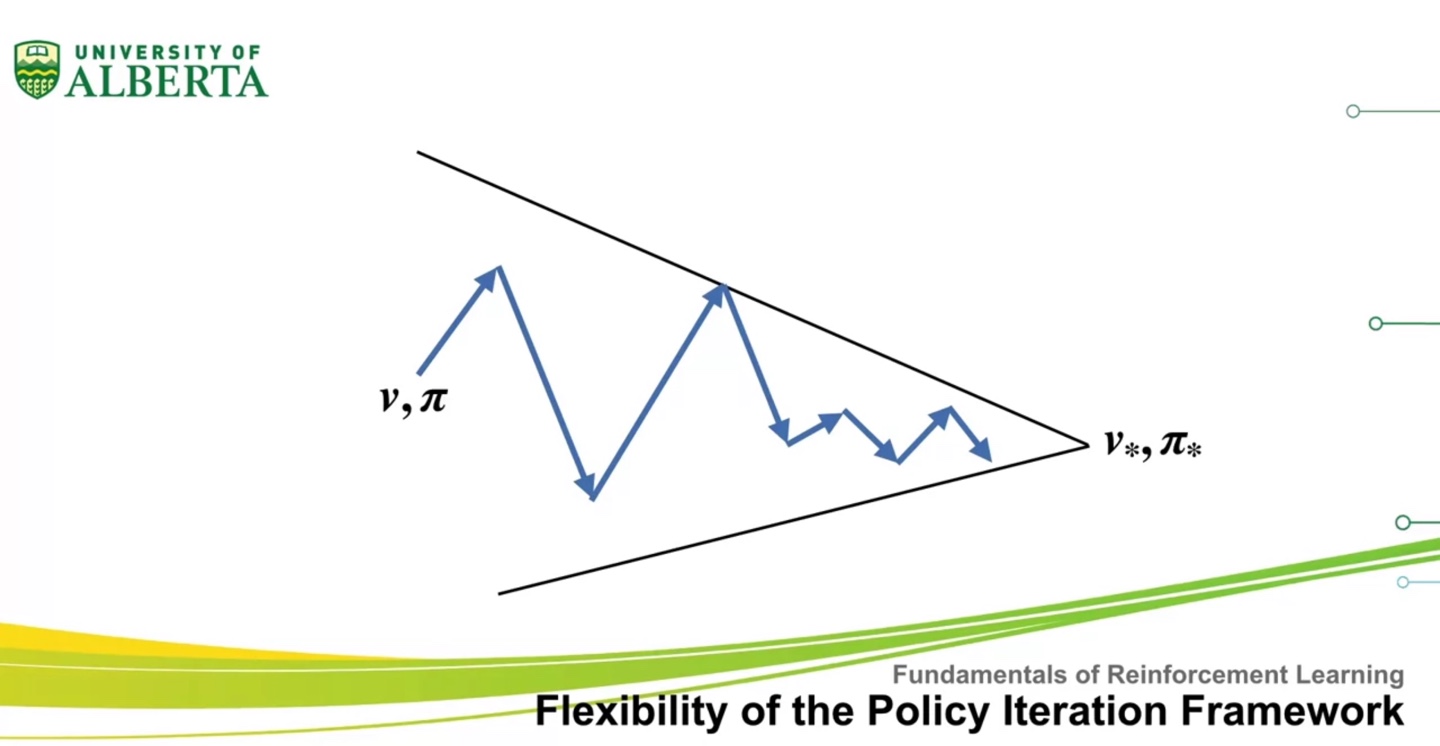
- 이번 강의에서는 value iteration이 generalized policy iteration의 special case라는 것을 이해하는 것과 asynchronous DP에 대해 이해해 보려고 한다.

-
Generalized Policy Iteration은 아래와 같이 maximum value와 완전한 greedy 선택이 아니더라도, optimal value & policy로 수렴하는 내용을 담고 있다.
- Evaluation을 모든 상황에서 전부 바라보는 것이 아닌 value의 max를 선택해나가며 policy를 improve해 나가는 것이다.
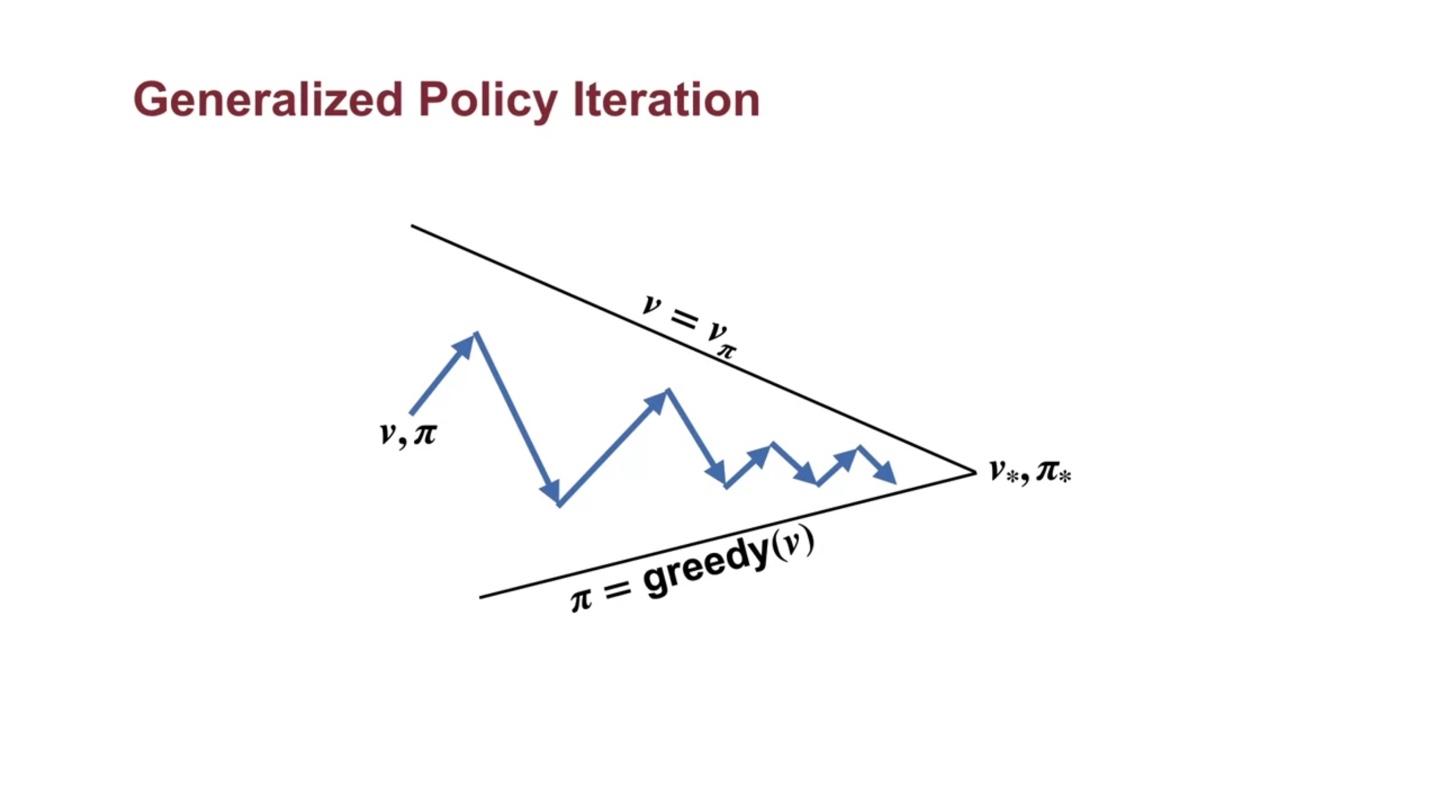
- Value iteration도 마찬가지로 evaluation과 greedy한 선택의 improvement를 반복하는 것으로 전개된다.
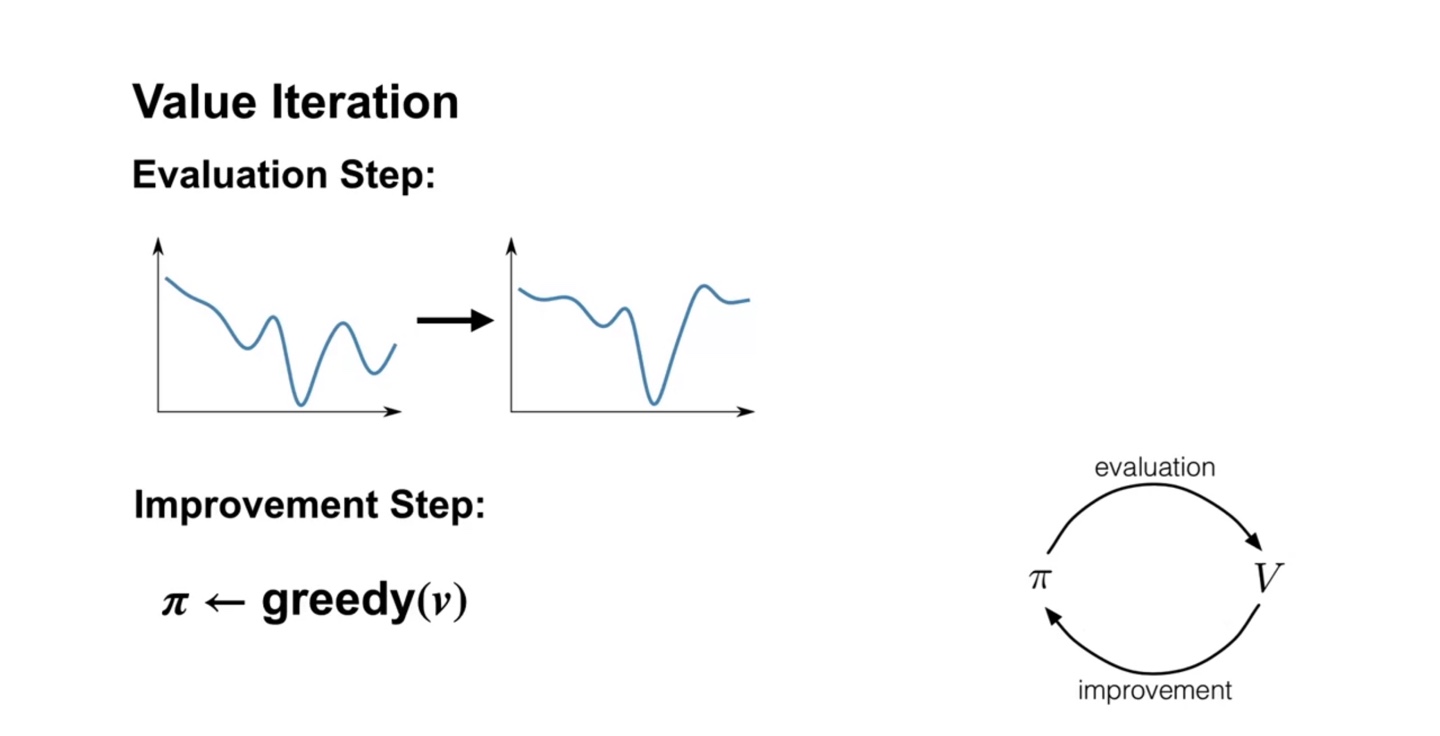
- Value iteration의 sudo code를 살펴보면 value 계산 시 max 를 선택하는 점에서 policy iteration과 차이를 보인다.

-
Synchronous DP는 모든 state에서의 policy probability와 value를 전부 계산해 업데이트 하는 과정이었다.
- 그에 반해 Asynchronouse DP는 말그대로, 비동기적인 state를 선정하고 이를 통해 계산된 max value로 업데이트 하는 과정이라 볼 수 있다.

- 따라서 Asynchronous DP는 특정 state에서의 value가 다소 깊어지는 효과를 가진다.

- Summary

Efficiency of Dynamic Programming
- Dynamic Programming의 효율성에 대해 논의해보자.
- 이번 강의에서는 Monte Carlo sampling에 대해 소개하고, DP가 갖는 장점 중에 하나인 Boostrapping에 대해 이해해보도록 하자.

-
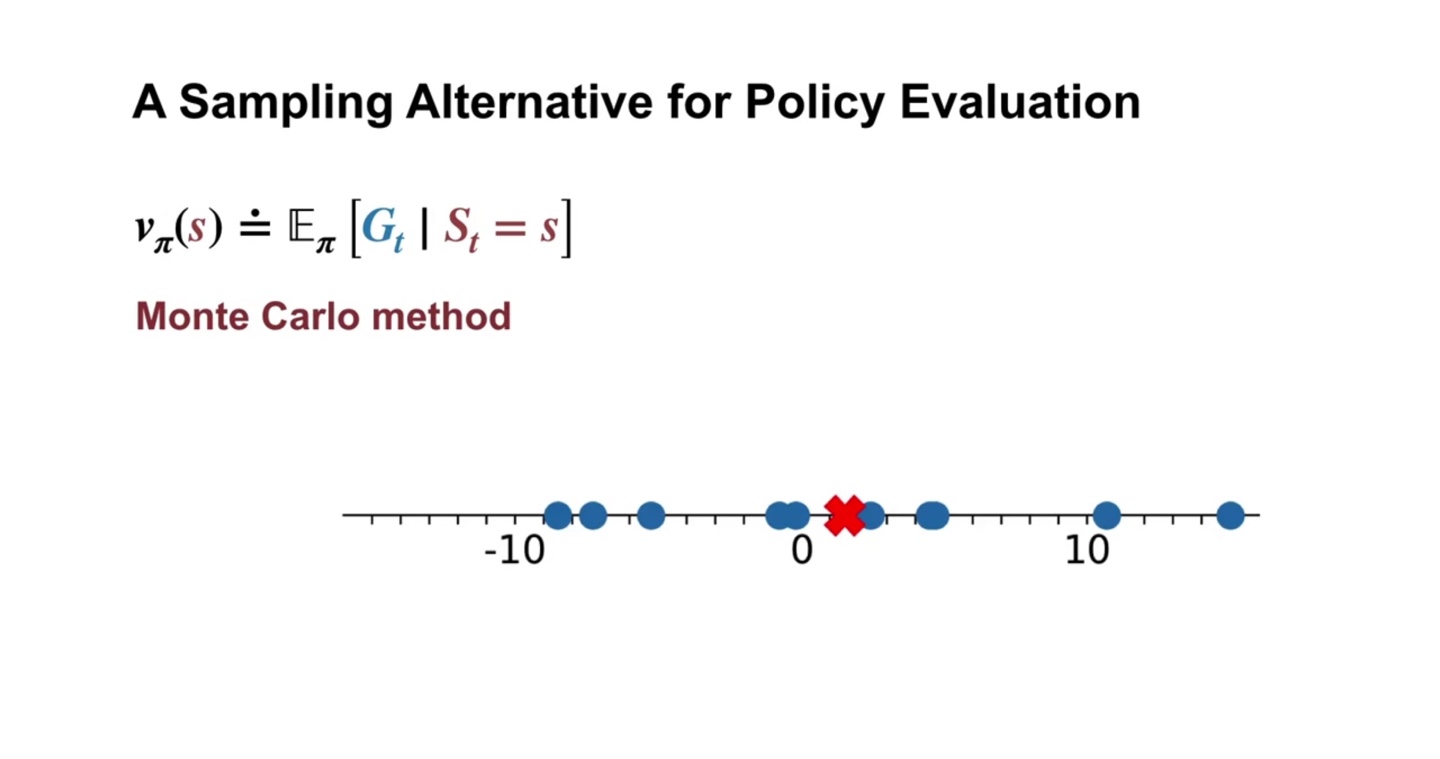
Monte Carlo method는 sampling한 선택지에서의 policy evaluation을 의미한다.
- 전체 선택지가 아래와 같은 big tree로 이루어져 있다면, 진한 선으로 표시된 sample 선택지가 현재 업데이트 되는 policy와 MDP probability 가 된다.
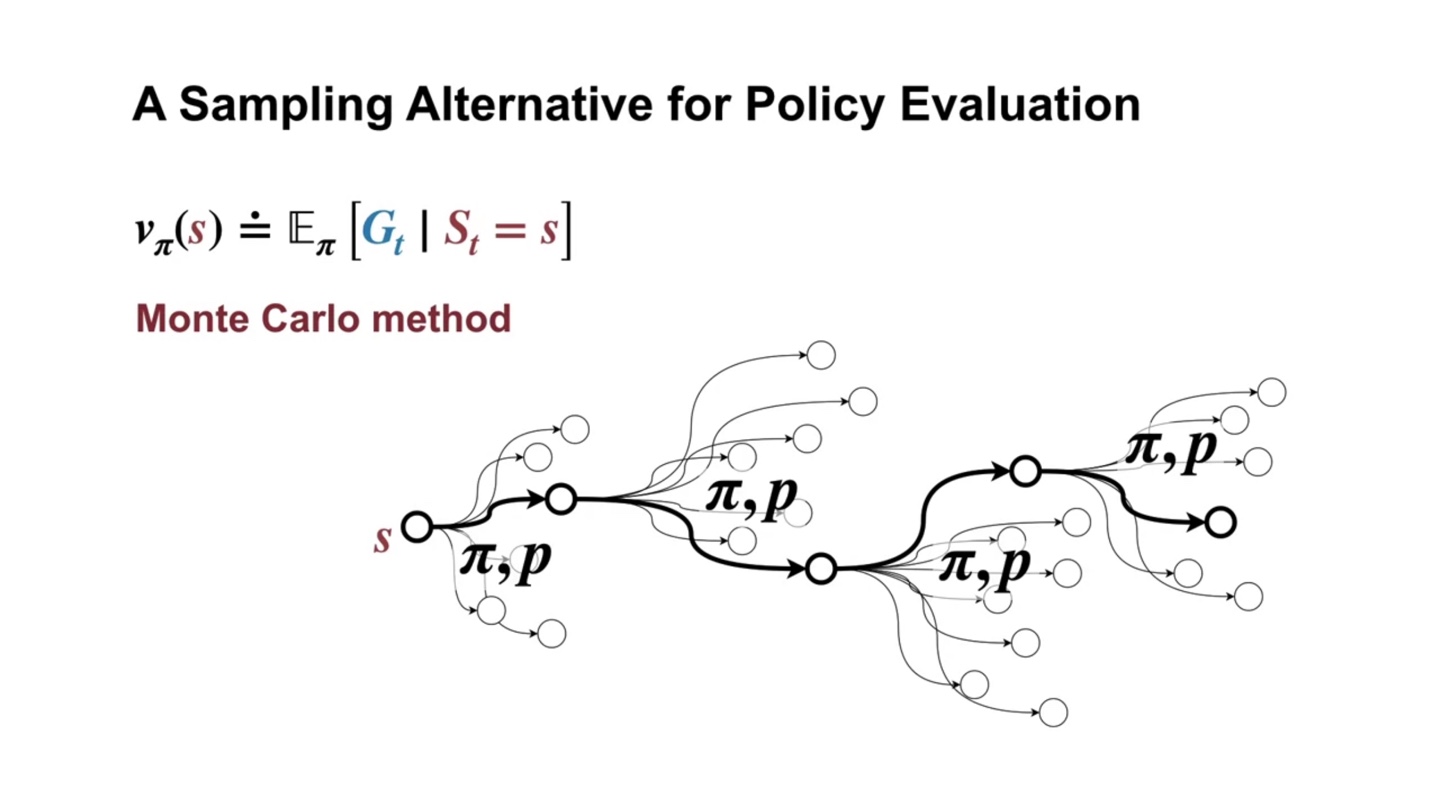
- 즉, Monte Carlo method는 sample의 expected value로 policy evaluation을 수행하는 것을 말한다.
-
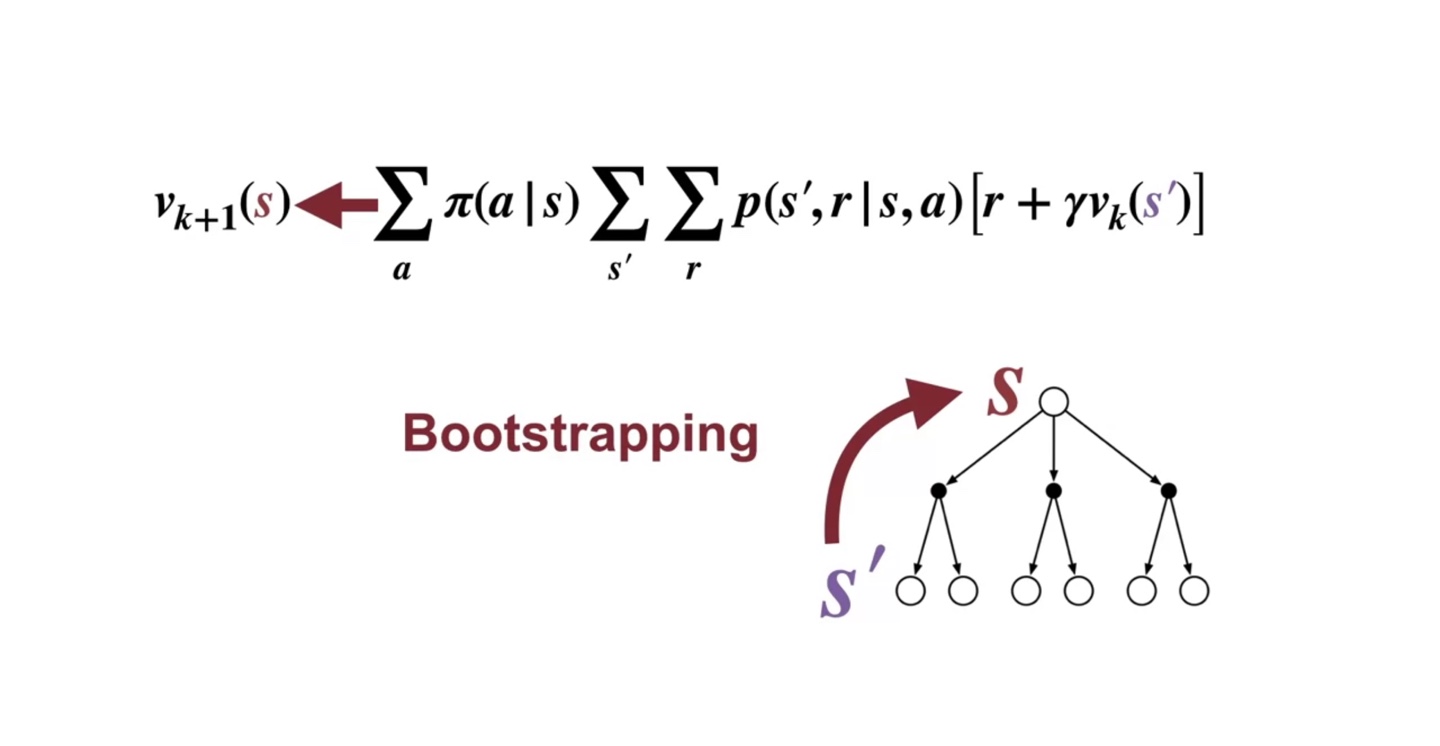
번째 state-value로 번째 value를 계산하는 과정을 Boostrapping이라 한다.
- 예측값을 이용해 또 다른 예측값을 예측하는 것을 말한다고 한다.
-
Brute-Force Search는 모든 경우의 수를 전부 계산하는 과정이다.
- 즉, 하나의 policy가 업데이트 될 때마다 action space 를 모두 탐색하므로, time-complexity는 라는 exponential한(매우 큰 소모량)을 갖는다.

-
Dynamic Programming으로부터 policy iteration을 수행하는 과정은 Brute-Force search 알고리즘에 비해 선형 와 선형 를 더한 값의 복잡도를 갖는다.
- 따라서 DP 방법이 Brute-Force 방법론에 비해 exponentially faster하다.

- 아까 보았던 파란색 board의 value를 업데이트 하기 위해 Brute-Force Search로 전체 경우의 수를 고려하면 의 복잡도를 갖게 된다.
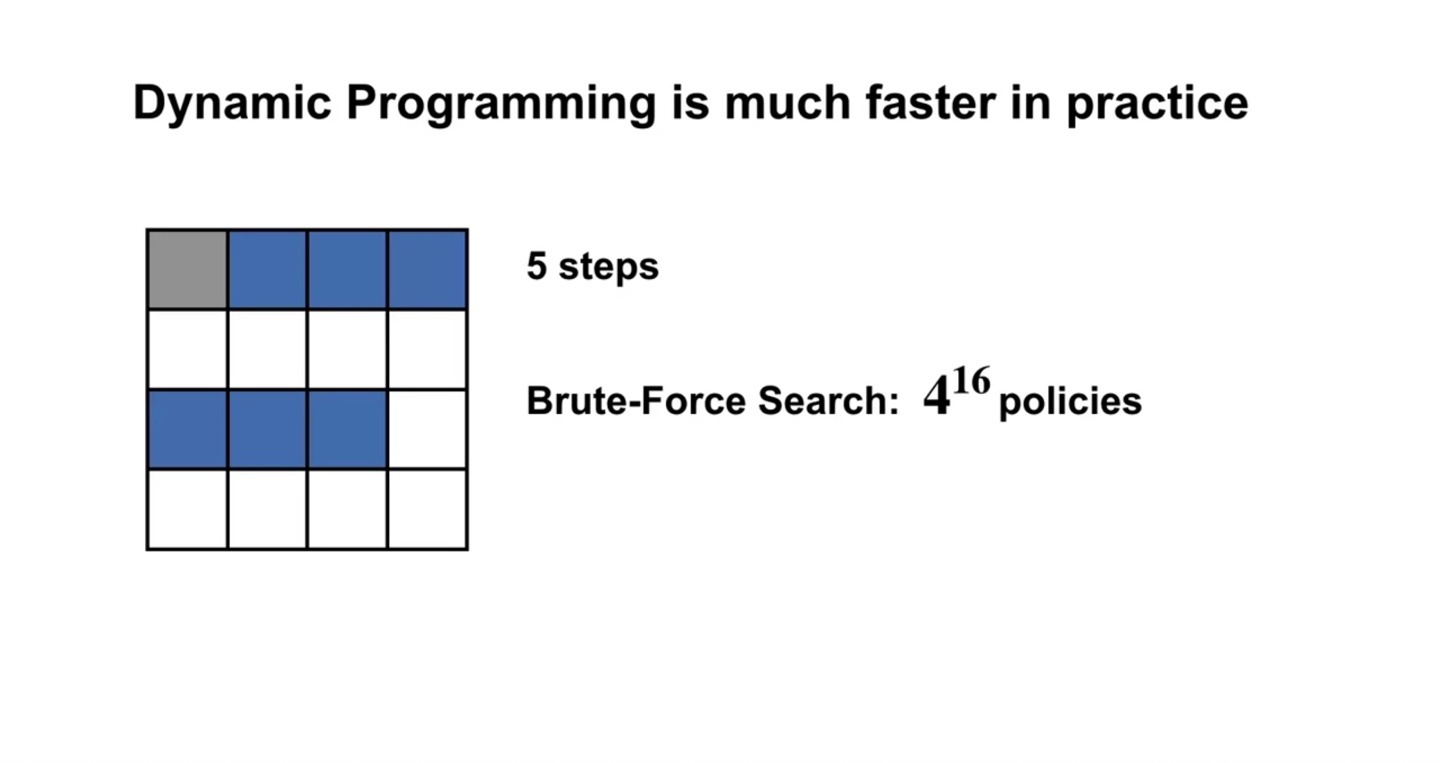
- Dynamic Programming은 아래와 같이 단 두 번의 computation으로 optimal policy를 구할 수 있게 만들어준다.
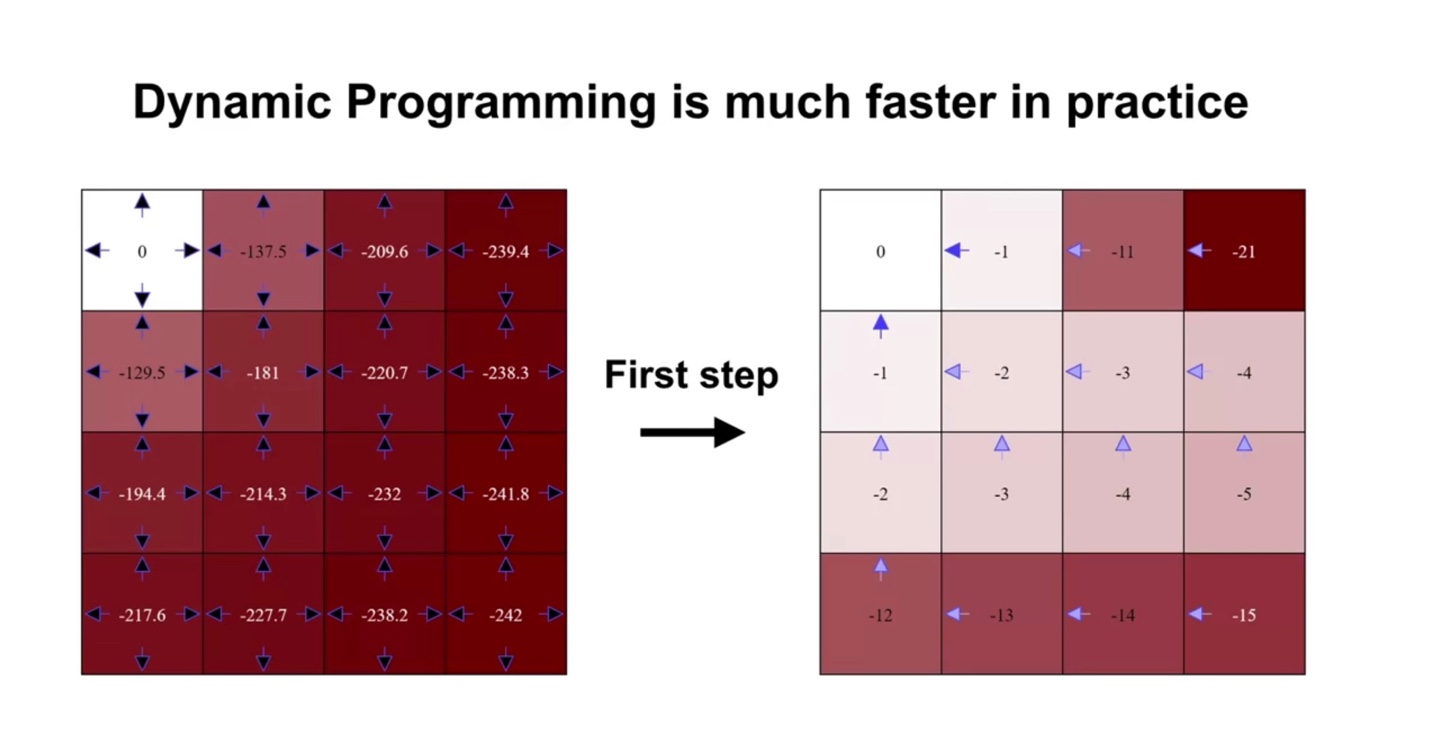
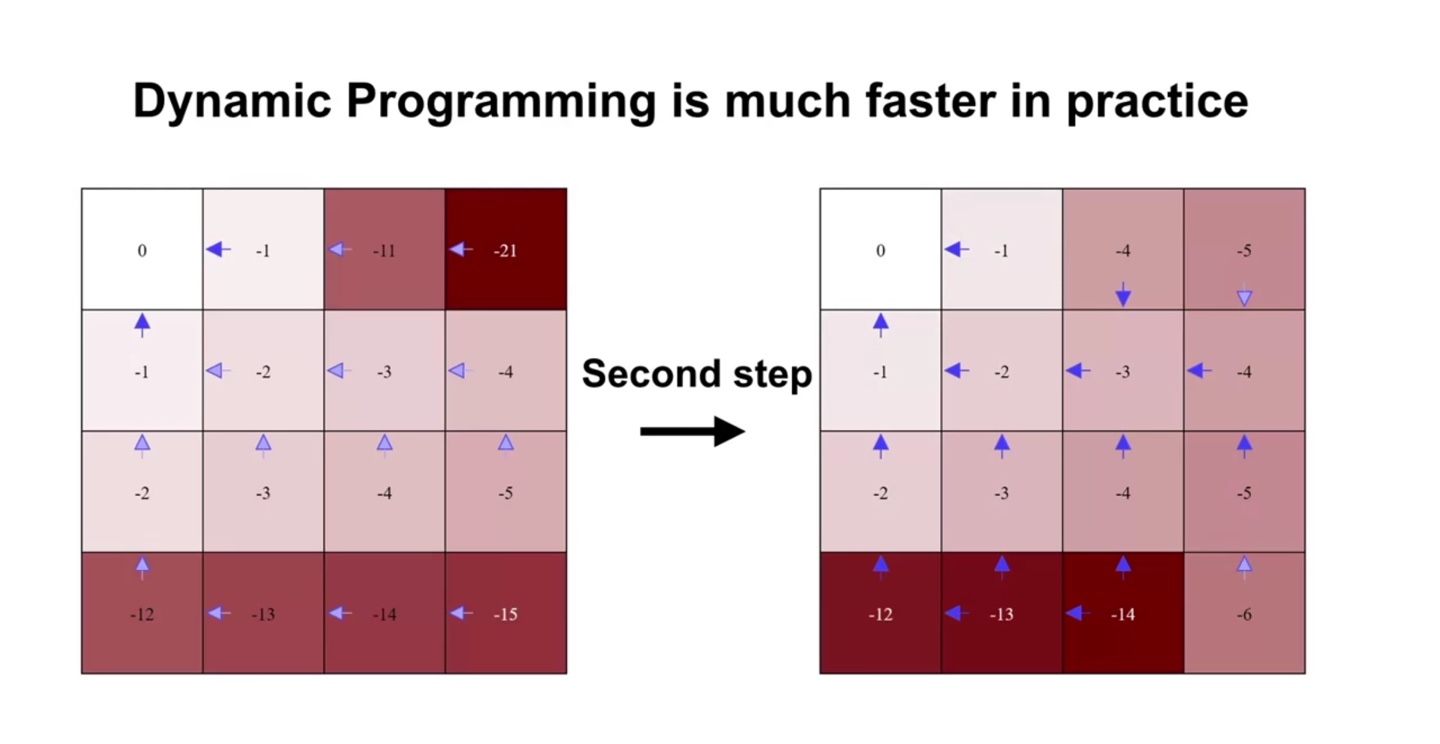
- 위와 같이 간단한 문제가 아니라 미국 전체 물류량의 value를 계산해야 한다면, Brute-Force 알고리즘은 기하학적으로 높은 계산량을 갖게될 것이다.
- 그런 의미에서 Dynamic Programming은 매우 효율적인 알고리즘이 될 수 있음을 알게 되었다.

- Summary

