cs231n, 문일철교수님의 인공지능 및 기계학습 개론 참고
과적합(Overfitting)
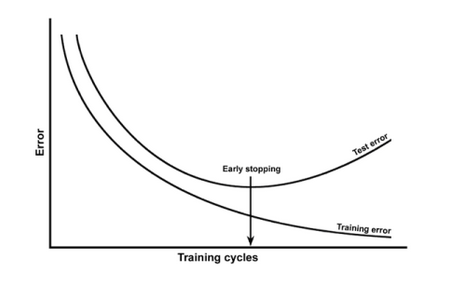
- 과적합은 Train data 에서는 error 가 낮지만, Test data에서는 error가 높음
- Train data 에 모델이 과적합 됨
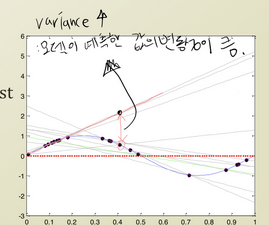
variance : 지나치게 복잡한 모델로 인한 error
variance가 클수록 과적합 됨과적합을 막는 방법
1) 데이터의 양 늘리기
- 데이터의 양을 늘릴수록 모델은 데이터의 일반적인 패턴을 학습하여 과적합 방지
- 이미지 데이터를 변형하고 추가하여 데이터의 양을 늘림(Data Augmentation)
2) 가중치 정규화
- 모델의 가중치에 규제(Regularization)를 두어 복잡한 모델을 간단하게 만듦
- 아래에서 더 자세히!
3) Dropout
- 신경망 학습시에 사용됨
- 후에 포스팅
정규화(Regularization) 적용
- 모델에 규제를 두어 모델의 복잡도를 줄이는 방법
- weight 값에 패널티를 가해서(weight가 작아짐) 과도하게 커지는 것을 방지
- weight가 작아지도록 학습을 한다는 것은 'local noise' 가 학습에 큰 영향을 끼치지 않는다는 것이고, 'outlier' 의 영향을 적게 받도록 하고 싶은 것임
Regularization 의 종류
1) L2 Regularization(=Ridge Regularization)
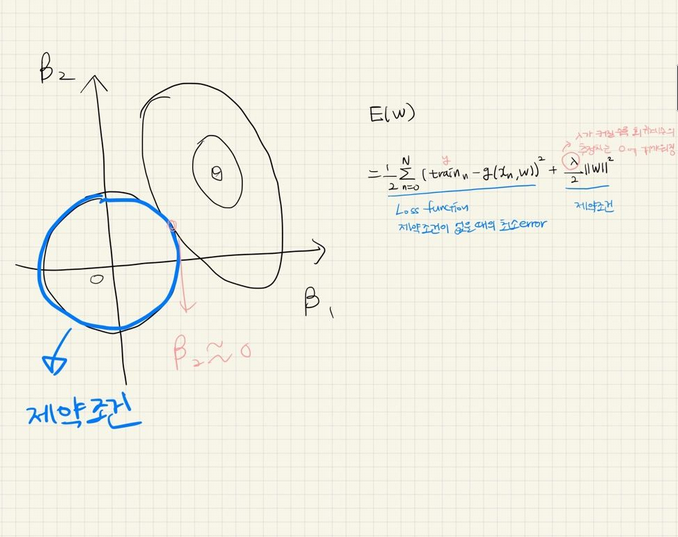
- weight를 계속 업데이트 해 나갈 때, 계수를 0에 가까이 만들어버림
- 전체적으로 weight를 작아지게 함
2) L1 Regularization(=Lasso Regularization)
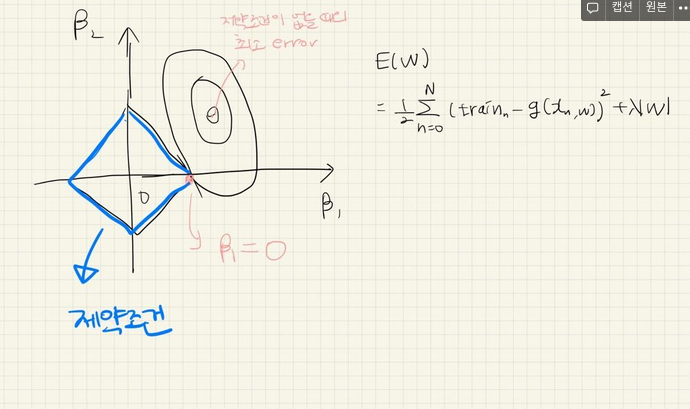
- weight를 계속 업데이트 해 나갈 때, 계수를 0으로 만들어버림
- 결과적으로 몇몇 중요한 weight들만 남게 됨
L1,L2 차이와 선택 기준
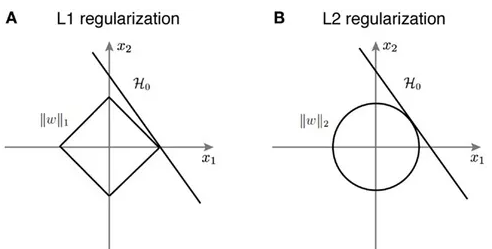
- 기본적으로 L2를 더 많이 사용
- L1 Regularization은 가중치 업데이트 시, 가중치의 크기에 상관 없이 상수값을 빼면서 진행. so, 작은 가중치들이 거의 0으로 수렴되어서 몇개의 가중치들만 남게 됨(Feature selection 가능)-> 몇개의 의미있는 값을 끄집어내고 싶은 sparse model 같은 경우에는 L1 Regularization이 효과적
- but L1 Regularization은 미분 불가능한 점이 있기 때문에 Gradient-base learning에는 주의가 필요
- L2 Regularization 은 가중치 업데이트 시, 가중치의 크기가 직접적인 영향을 미침
