How using CV?
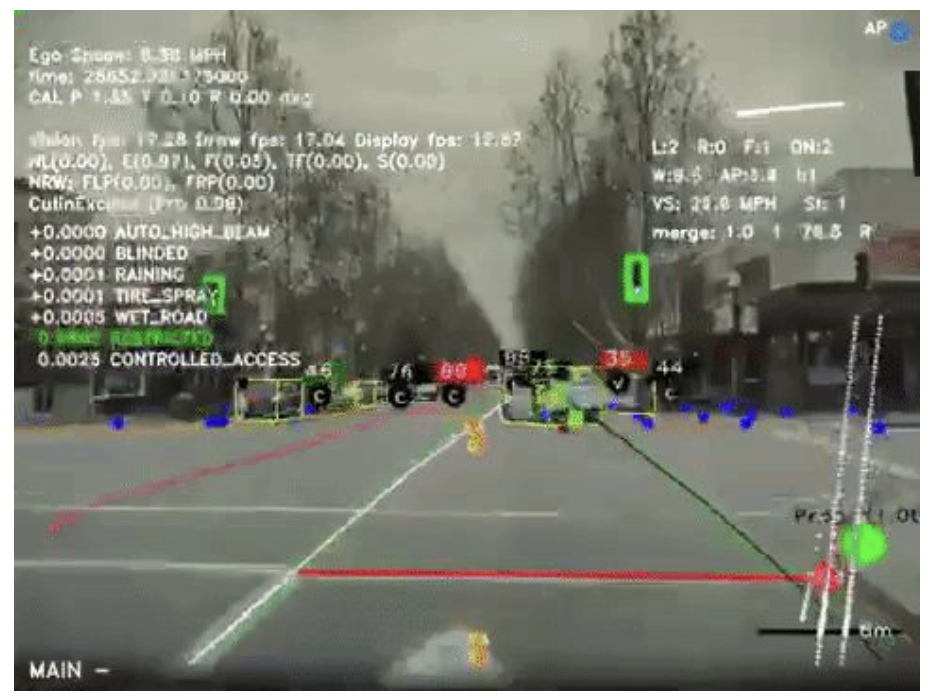
Tesla Autopilot
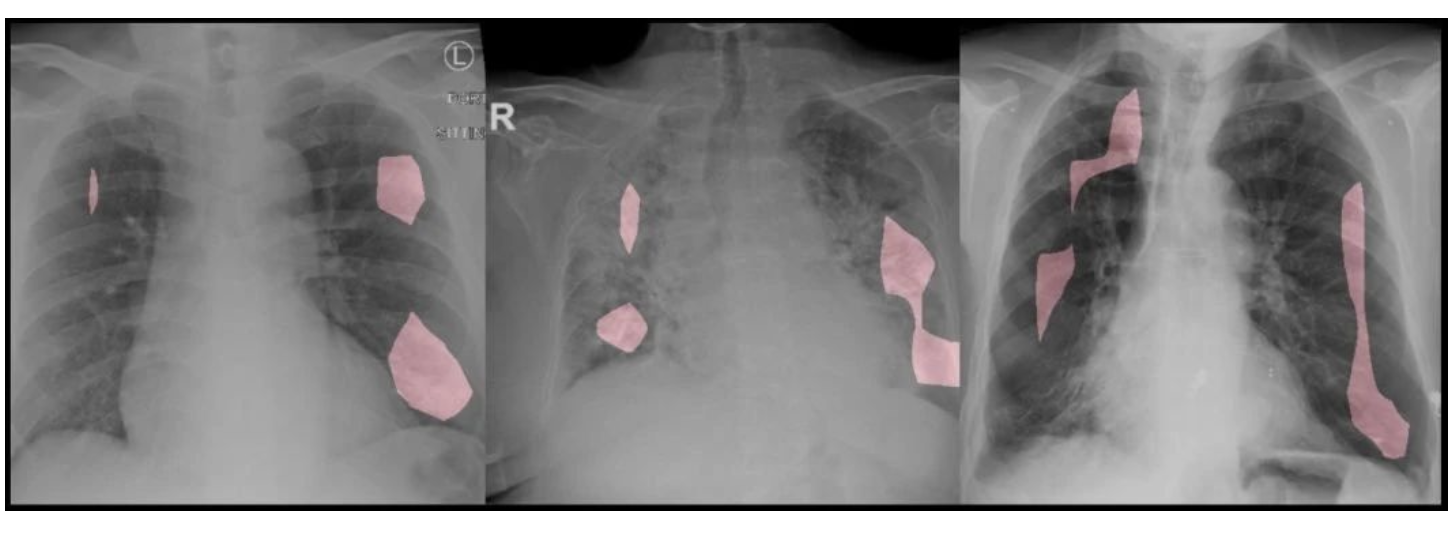
Medical AI
NeRF (Neural Radiance Field)

Neural Radiance Fields는 3차원 장면을 디지털로 재구성하는 데 사용되는 딥러닝 기반 기술
Why CNN?
Multi Layer Perceptron
- MLP는 input layer → hidden layers → output layer로 구성
- Input layer의 neuron 개수는 tabular data의 feature 수와 동일
- 각 feature가 neuron에 대응되기 때문!
- MLP는 tabular data 를 학습하는 데 최적화 되어있음
MLP in CV
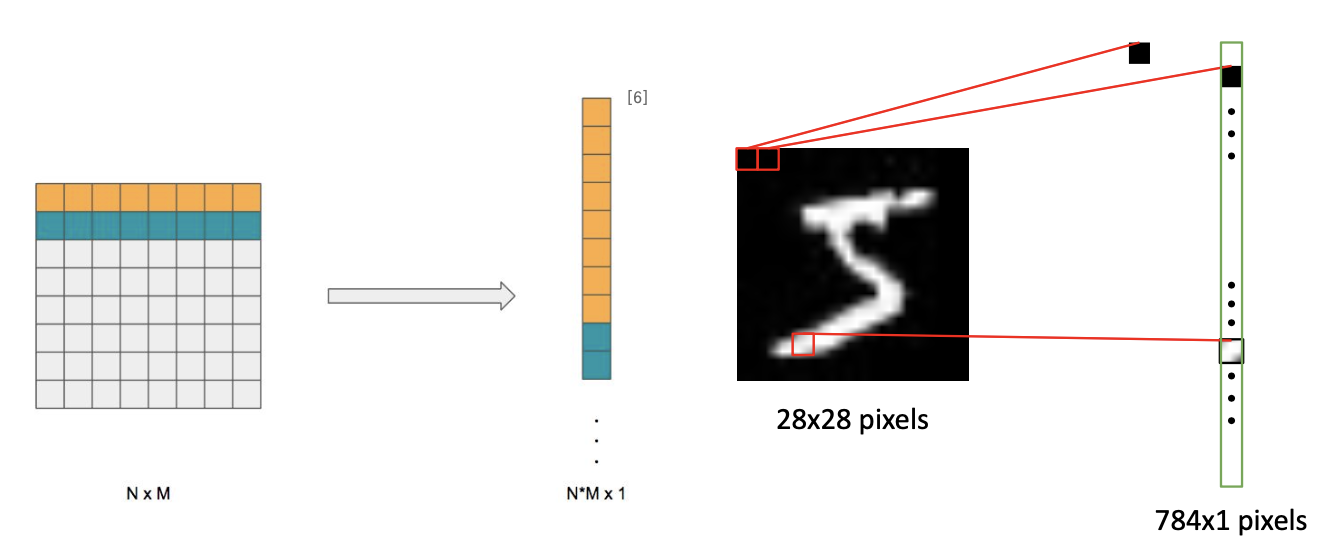
- 이미지를 MLP의 input layer에 입력하려면 이미지를 flatten 해야함
- 이미지를 flatten하면 어떤 단점이 있을까?
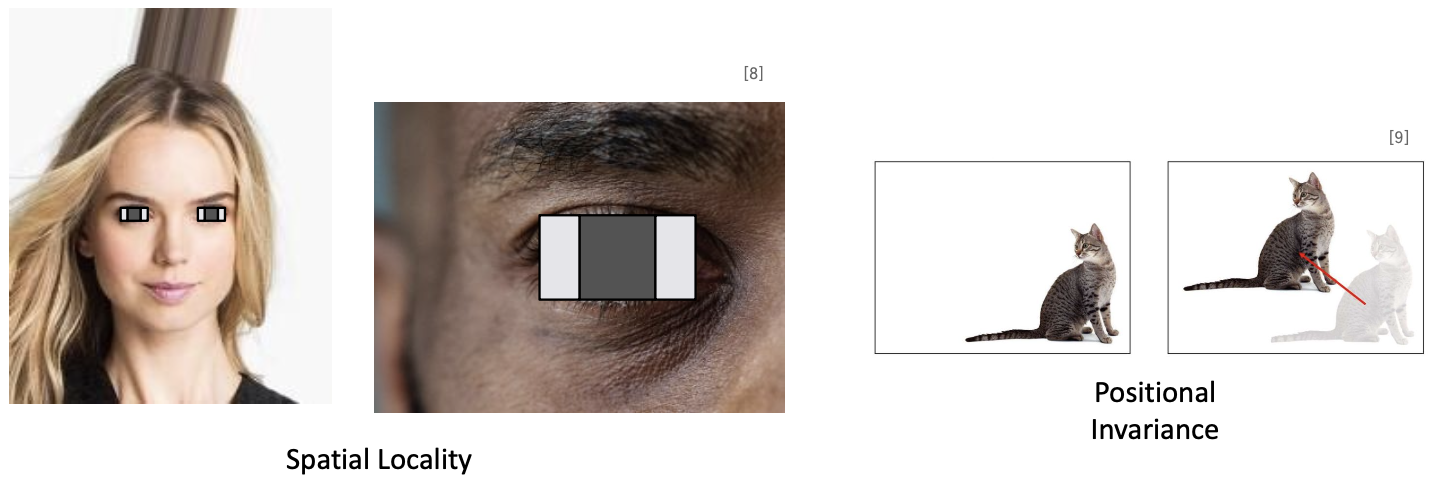
이미지의 Locality 특성
- Spatial locality: 같은 물체라도 이미지마다 크기가 다름
- Positional invariance: 같은 물체라도 다른 위치에 있을 수 있음
Convolution Filter
- Convolution filter를 사용하면 이미지를 flatten하지 않고 연산 가능
- Object의 구조와 주변 정보를 함께 연산할 수 있음
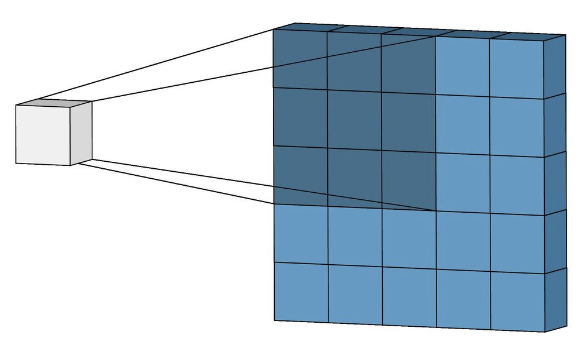
- 같은 필터를 이미지 전체에 적용하여, 다른 위치에 똑같은 물체가 있는 경우 같은 연산을 수행
CNN의 한계점
- Convolution filter로 locality를 쉽게 파악 가능했지만 다음과 같은 한계점이 있음
- 이미지 안에서 멀리 떨어진 객체끼리 관련성을 파악하기가 어려움
- 이미지의 각 파트가 이미지 이해에서 얼마나 중요한지, 얼마나 서로 관련이 있는지 평가할 수 없음
Transformer
CNN 한계 극복을 위해 고안
- NLP에서 제안된 Transformer를 computer vision에 적용하여 해결
- 이를 기반으로 data-centric AI 시대의 도래
- Natural Language Processing (NLP) task를 위해 고안
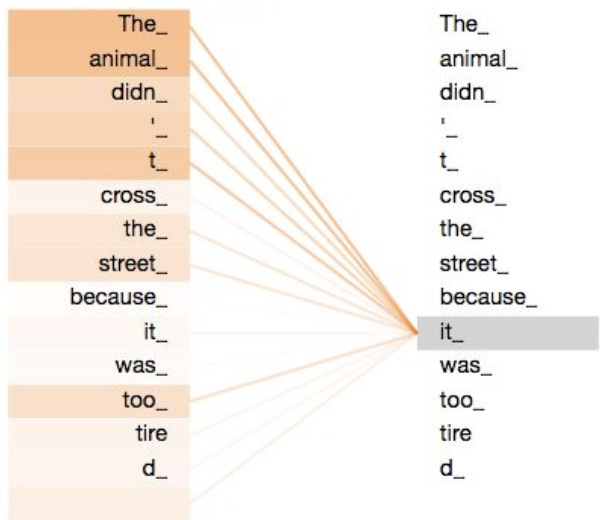
- Long-range dependency : 문장 안에서 멀리 떨어진 단어끼리도 서로 관계지을 수 있음
- Self-attention mechanism : 각 단어들이 얼마나 서로 관련있는지 평가
ViT & Swin
- Transformer 구조를 computer vision에 적용하여 해결한 ViT (Vision Transformer) 등장
- 더 나아가 CNN 특성을 ViT에 다시 적용한 Swin Transformer

Real Cryptocurrency Trader & AI Engineer LV.0