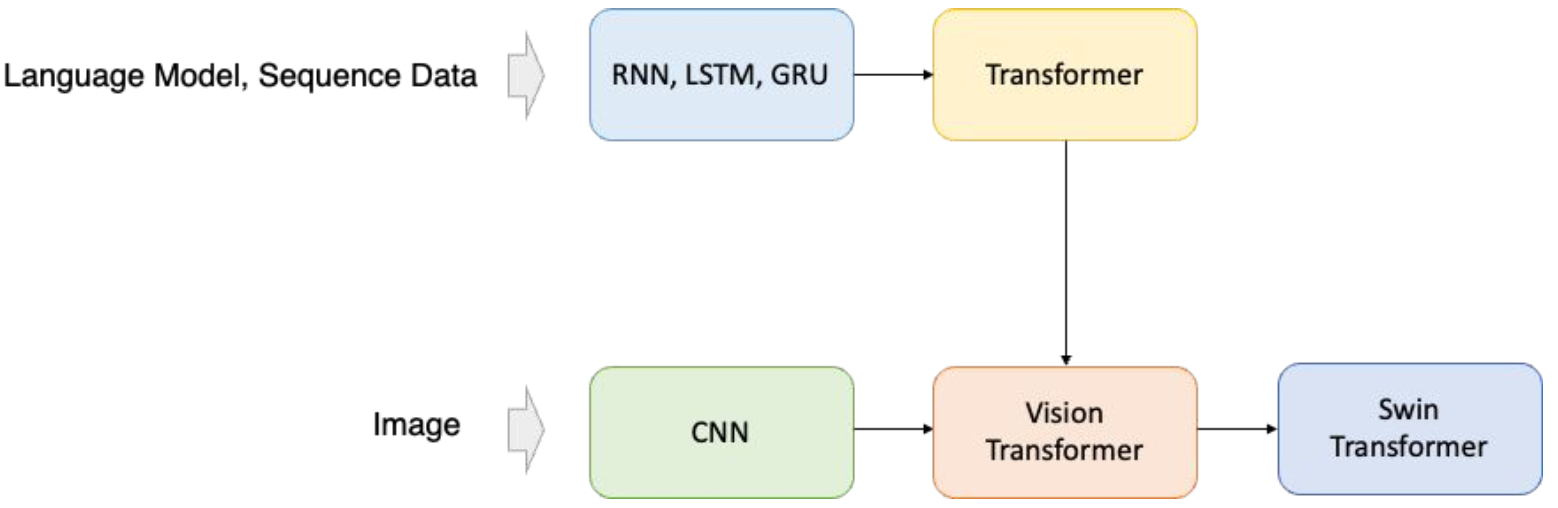
Why Transformer?
- 최근 computer vision domain에서도 transformer backbone이 주류
-
Natural Language Processing (NLP)에서 생기는 문제점을 해결하기 위해 고안
-
Long-term dependency
- 기존 모델들은 sequence data를 처리할 때 데이터를 순차적으로 처리함
- 데이터 길이가 길어지면 정보 손실이 발생함
-
Attention: Next token을 예측할 때, sequence 내의 다른 위치에 있는 정보들과의 상관 관계가 중요함
- a) The animal didn’t cross the street because it was too tired.
- b) The animal didn’t cross the street because it was too wide.
CNN 한계점
- Computer vision 분야에서도 NLP와 같은 문제에 발생
- Long-range dependency: 멀리 떨어진 두 물체에 대한 context를 학습하기 힘듦
- Attention: 이미지 내의 여러 object들에 대한 상관 관계를 알 수가 없음
- Transformer가 기존 NLP의 문제점을 어떻게 해결했는지 분석
- 이후, 동일한 메커니즘을 computer vision에도 적용 (ViT)
Transformer 구조
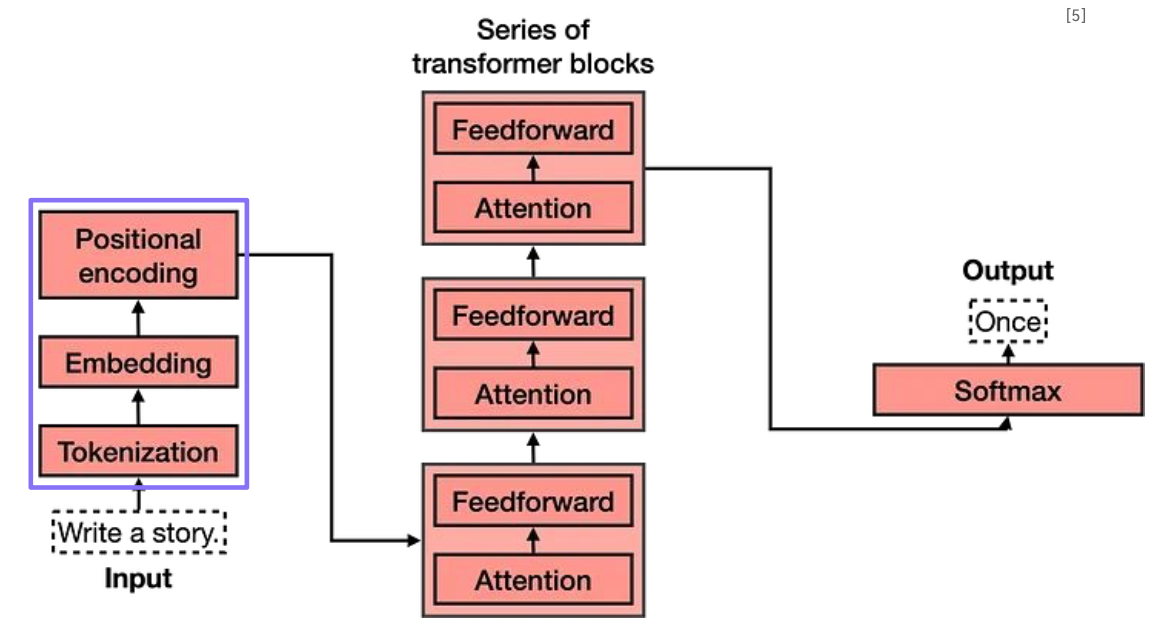
Sentence to Embedding
-
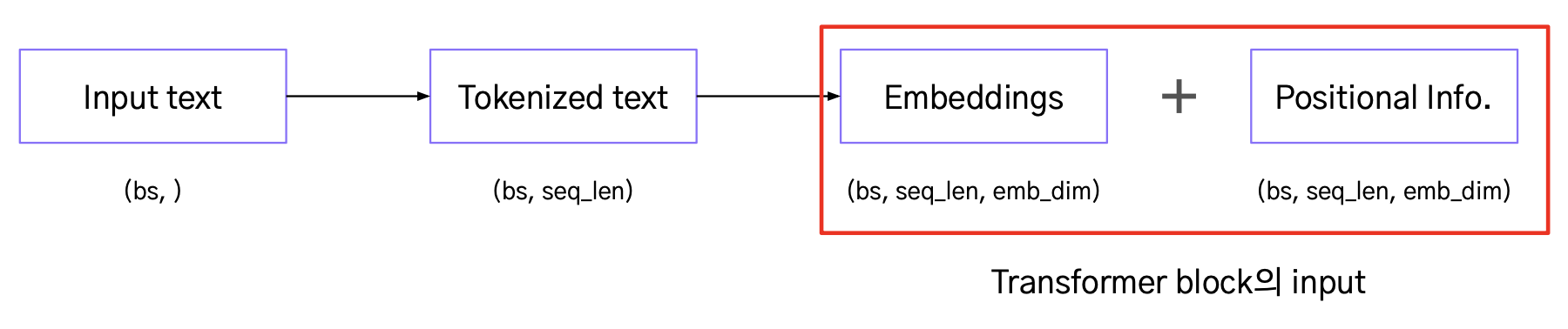
“Write a story” → 컴퓨터가 이해할 수 있는 무언가
-
컴퓨터는 무엇을 이해할 수 있을까?
- “Write a story” → 0,0,1,0,1,0,1,0,...,1 → Embedding
-
Sentence를 embedding으로 변환할 필요가 있음
-
좀 더 효율적인 방법은 없을까?
- “I read a book” → [“I”, “read”, ...] → [“I”, “read”, ...]
- “I’m reading a book” → [“I’m”, “reading”, ...] → [“I”, “_am”, “read”, “_ing”, ...]
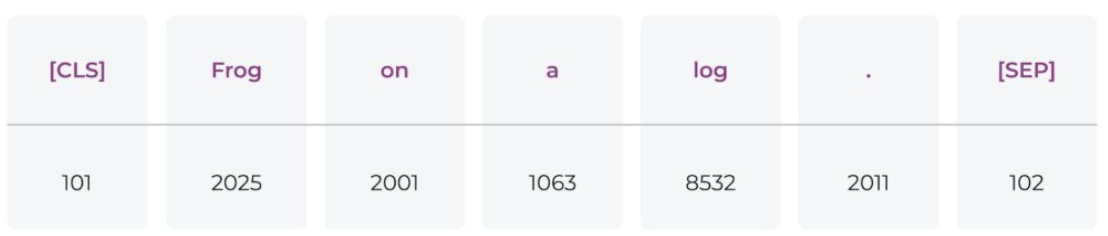
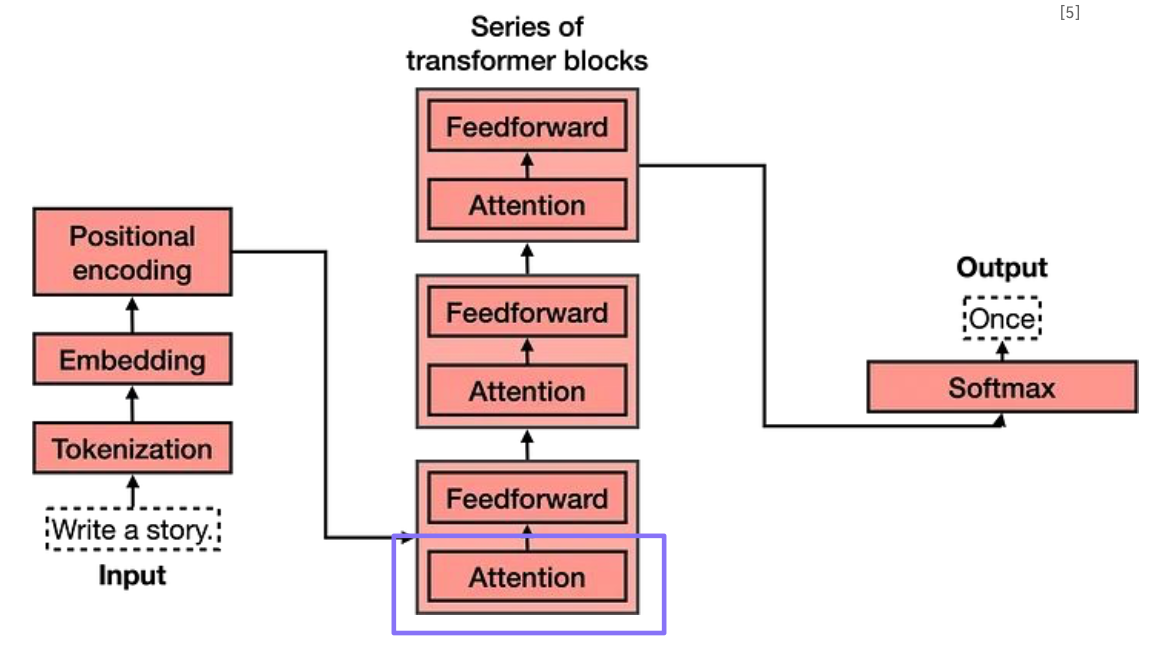
Tokenization
-
문장을 토큰 단위로 분할
- Token은 단어, 구두점 등 ‘의미 있는 단위'를 나타냄
- 문장의 시작이나 끝을 나타내는 token도 추가
- 각 token에 사전에 정의된 단어번호 할당
Word Embedding
- Token을 embedding으로 변환
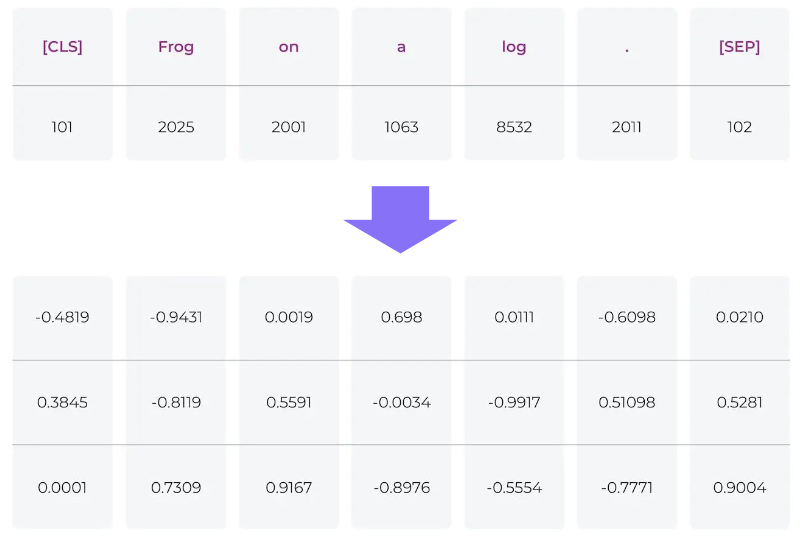
- Sentence: “Write a story”
- Token: [“Write”, “a”, “story”]
- Embedding w/ hidden_size 4: [[0.5, 0.1, 0.2, 0.9], [0.7, 0.12, 0.35, 0.9], [0.1, 0.12, 0.56, 0.99]]
- Shape
- () → (num_tokens) → (num_tokens, hidden_size) or (num_words, hidden_size) or (seq_len, hidden_size)
Positional Encoding
- Word embedding은 단어의 위치까지 반영하지는 않음
- 그러나 다른 위치에 있는 같은 단어는 다른 의미를 가질 수 있음
- 위치 정보(positional encoding)를 word embedding에 더하여 위치 정보를 추가
- 최근에는 위치 정보 역시 학습 가능한 파라미터로 두는 경우가 많음
- 즉, nn.Embedding을 정의하고, 모델 업데이트 과정에서 이를 학습
import torch
import torch.nn as nn
seq_len =10
embedding_dim = 768
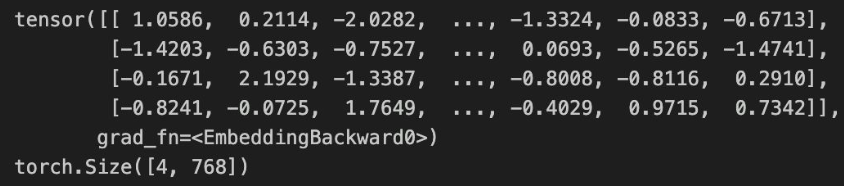
embeddings = nn.Embedding(seq_len, embedding_dim)
print(embeddings(torch.LongTensor([0,1,2,3])))
print(embeddings(torch.LongTensor([0,1,2,3,])).shape)
여기까지 Recap
Self Attention
-
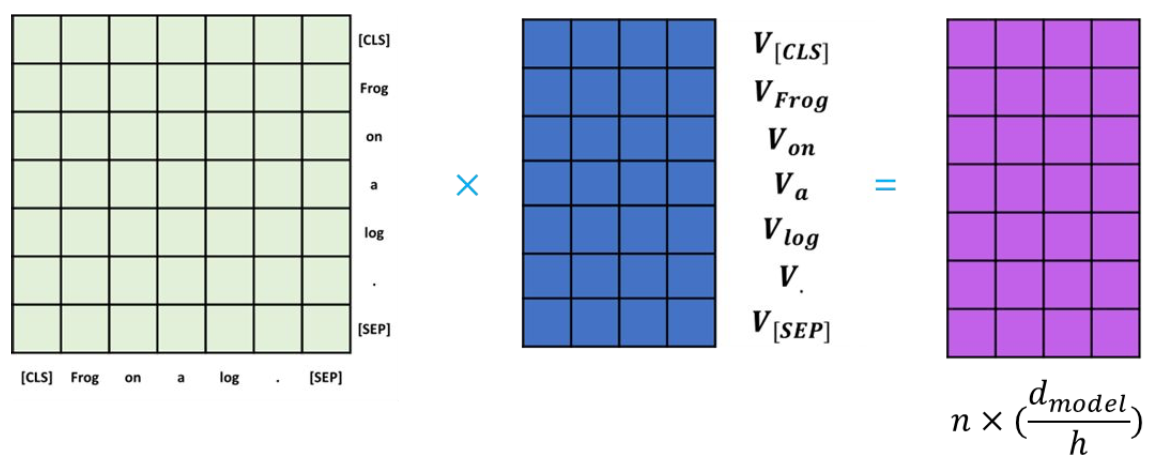
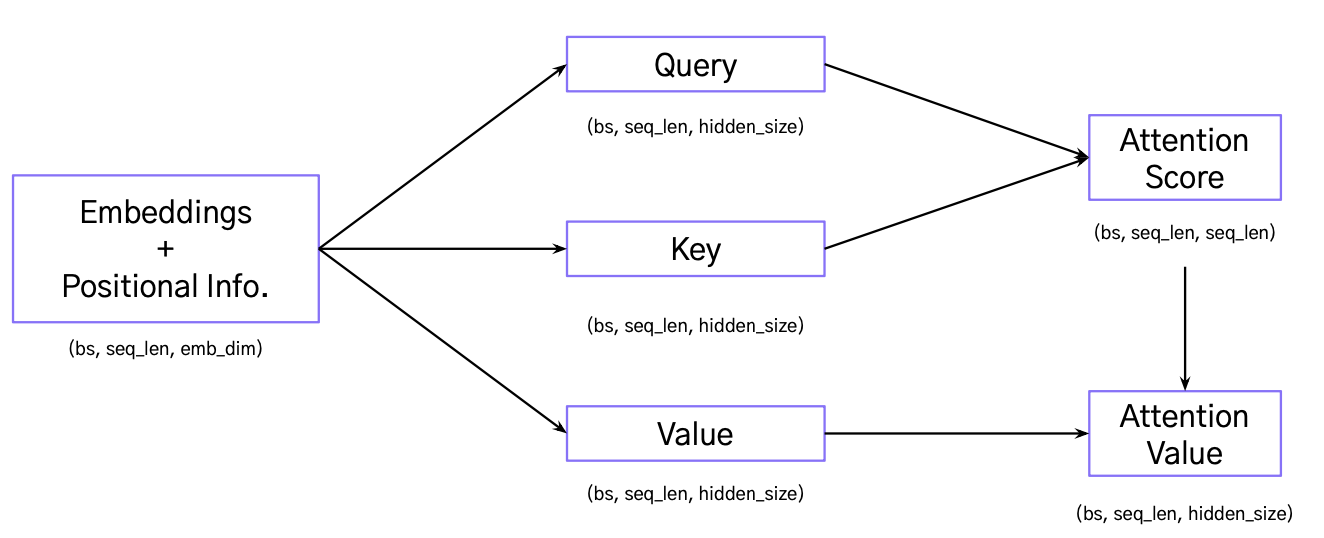
Input embedding이 query, key, value로 mapping
- Query: Attention을 확인하고 싶은 단어
- Key: Input embedding의 모든 단어
- Value: Input embedding 갖고 있는 정보
-
Attention score
- Query와 key를 통해 attention score를 계산
- Value를 곱함으로써 각각의 key가 가진 정보를 통합
- 각 query를 대표하는 attention value를 얻음
- Hidden size에 따라 query, key 내적값이 커질 수 있음
- 이는 softmax 연산할 때 vanishing gradient 문제를 야기할 수 있음
- 안정적인 학습을 위해 hidden_size 크기에 패널티 추가
-
Multi-head attention
- 다양하고 복잡한 context를 학습 가능
여기까지 Recap
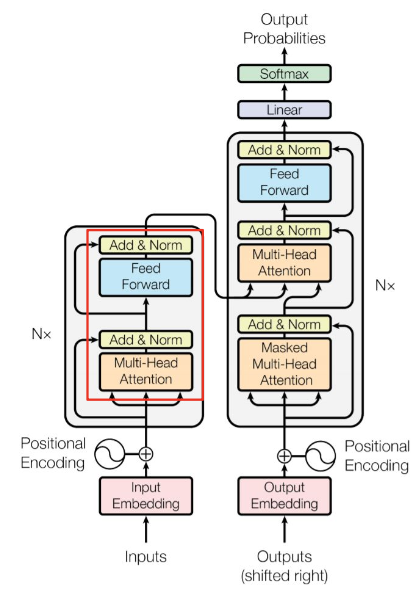
Feed forward
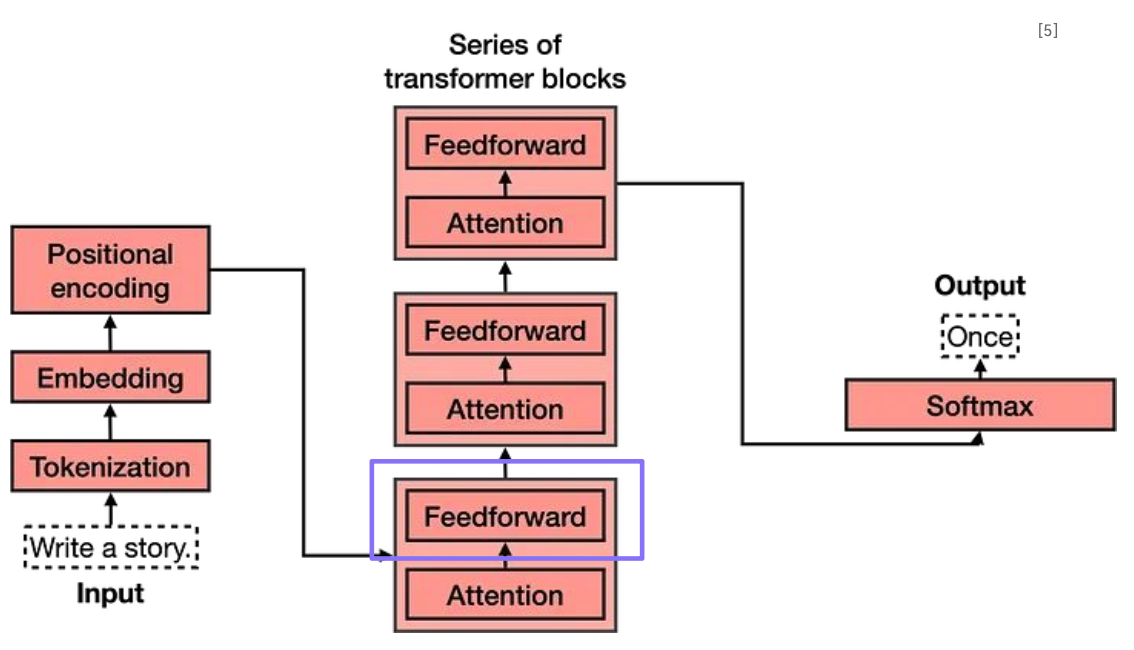
- Add & Norm: Attention이 반영된 embedding + 반영되기 전 embedding
- 이후, sequence context가 반영된 embedding을 fully connected layer에 통과
- Multi-head attention과 feed forward를 합하여 encoder라고 정의함
- Encoder를 여러개 쌓아 깊은 네트워크를 만들 수 있음

Real Cryptocurrency Trader & AI Engineer LV.1