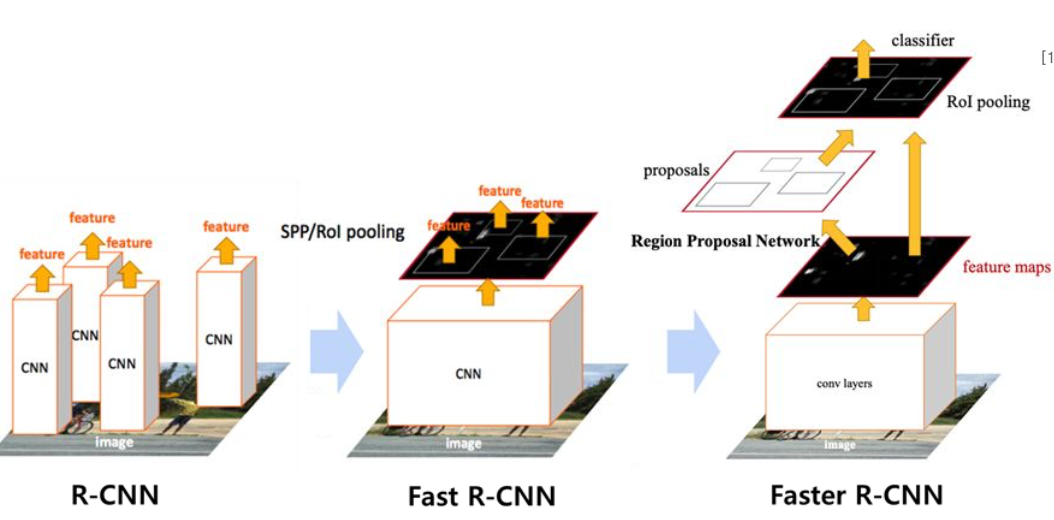
2-Stage Detector
2-Stage Detector란?
Object Detection = Localization + Classification
→ 두 가지의 task를 분리하여 2 stage로 따로 수행
- Stage 1: 이미지 내에서 object가 있다고 판단되는 위치 찾기 (Region proposal)
- Stage 2: 각 위치에 있는 object의 종류 판단 (Classification)

2-Stage Detector의 발전 흐름

R-CNN
- 2-stage detector의 최초 모델
- Region proposals + CNN

Sliding Window
고정된 크기의 window를 이미지 내에서 sliding하면서 객체의 위치를 찾아내는 방법
- 계산 비용이 높고 속도가 매우 느림
- 고정된 크기의 window

Selective Search
- 초기에 매우 작은 픽셀 단위의 region을 잡고, 유사성이 높은 region들을 점차적으로 병합해나가는 방법
- 색상, 질감, 경계 등을 기준으로 유사성이 높은 region을 병합
- Sliding window의 두 가지 단점 해결(계산 resource, 고정된 크기의 window)

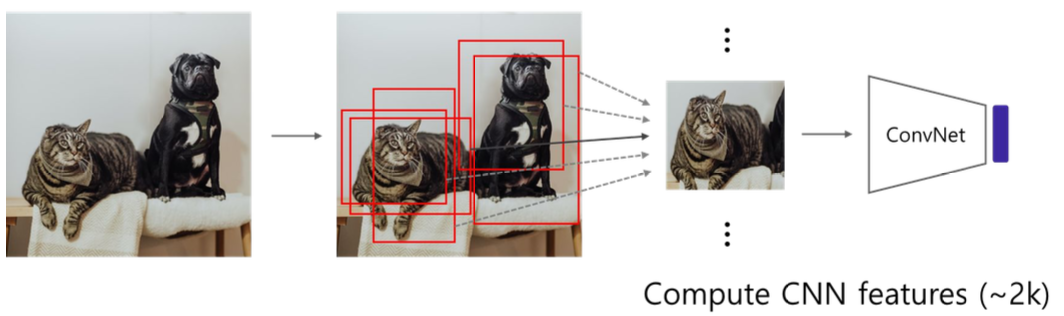
R-CNN Pipeline
-
Input image에서 selective search를 통해 약 2000개의 RoI(Region of Interest) 생성
-
각 RoI 영역을 모두 동일한 크기로 warping
- 이후에 통과할 CNN의 마지막 fc layer의 input size가 고정되어 있기 때문
- 조정된 RoI를 각각 CNN에 넣어서 feature 추출 (2000x4096)
- Region마다 4096-d의 feature vector로 추출
- Pretrained AlexNet 사용
4-1. 추출된 feature vector를 SVM에 넣어서 각 RoI(region of interest)의 object에 대한 classification (2000x(C+1))
- C+1: class 개수(C) + background(1)

4-2. 추출된 feature vector를 regression을 통해 각 RoI의 bounding box 위치 조정 ● Selective search의 부정확한 bounding box 위치 조정

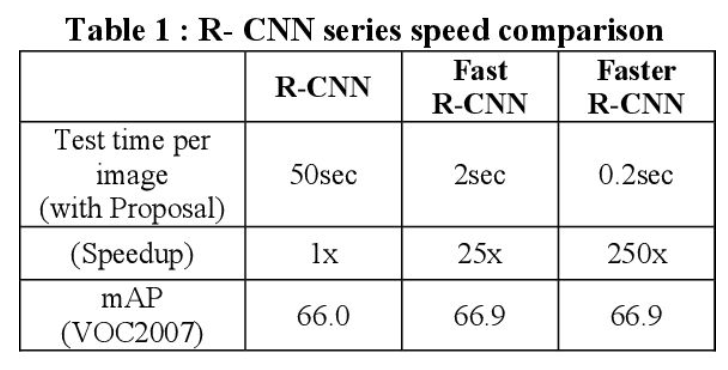
Fast R-CNN
R-CNN의 단점
- 약 2000개의 RoI 각각에 대해 CNN 연산 → 연산량이 많고 속도가 매우 느림
- 모든 RoI를 동일한 사이즈로 맞추기 위해 이미지를 crop/resize하는 과정 필요 → 성능 저하
- Stage2의 모델(CNN, SVM, bbox reg) 모두 따로 학습
Fast R-CNN
- 단일 CNN을 통해 연산량 감소
- RoI projection 모듈을 통해 CNN 연산을 줄이고 속도를 개선한 모델
- RoI pooling 모듈을 통해 이미지 사이즈 강제 조정하는 과정 제거
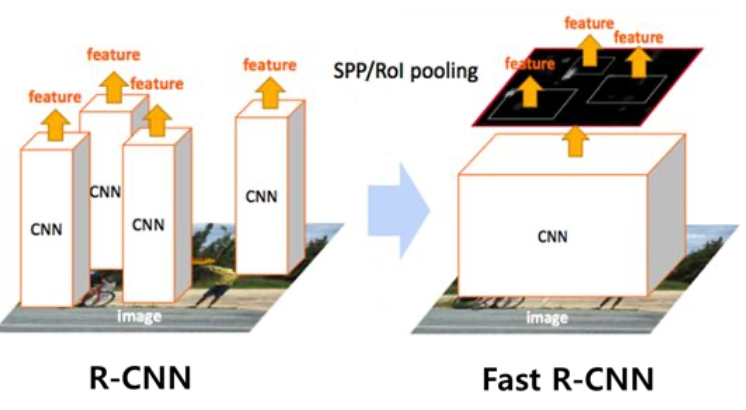
RoI Projection의 등장 배경
- R-CNN에서는 2000개의 RoI를 뽑고, 이후 CNN에 통과 (2000번의 CNN 연산)
- → CNN을 한번만 통과하여, feature vector를 얻을 수 있을까?
- Feature map을 한번만 추출하고, 그 위에서 RoI 위치에 맞는 feature vector를 추출하자!
- CNN 연산 2000번 → 1번
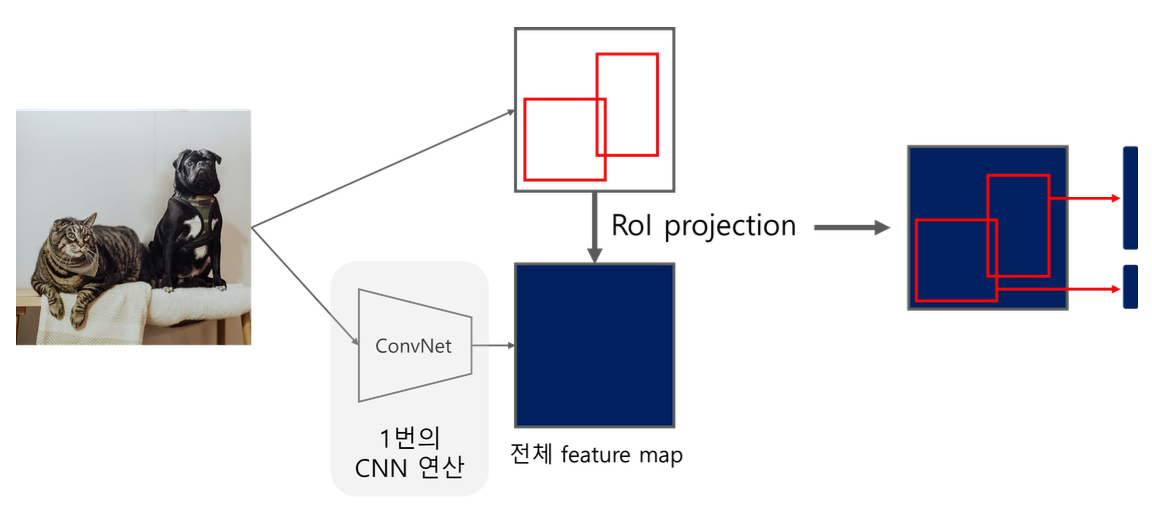
RoI Projection이란?
- CNN 연산 이후, feature map의 사이즈가 변할 수 있음
- 사이즈가 변한 feature map에 RoI를 투영하는 과정
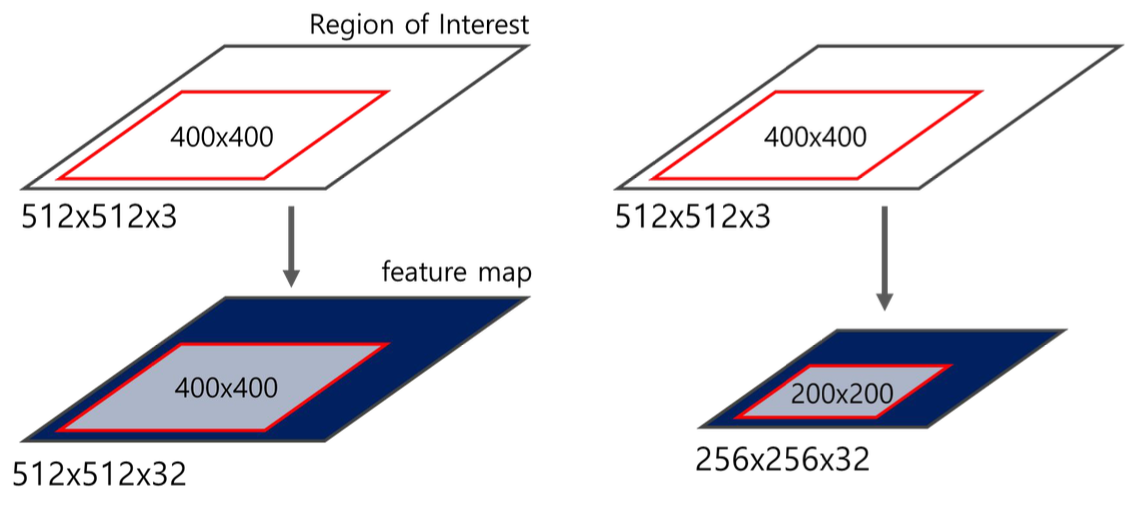
RoI Pooling
RoI Pooling의 등장 배경
- CNN을 먼저 통과하기 때문에 RoI를 crop/resize하는 과정 없음
- Fc layer의 input으로 들어가기 전에 feature vector 크기를 조정해야 함

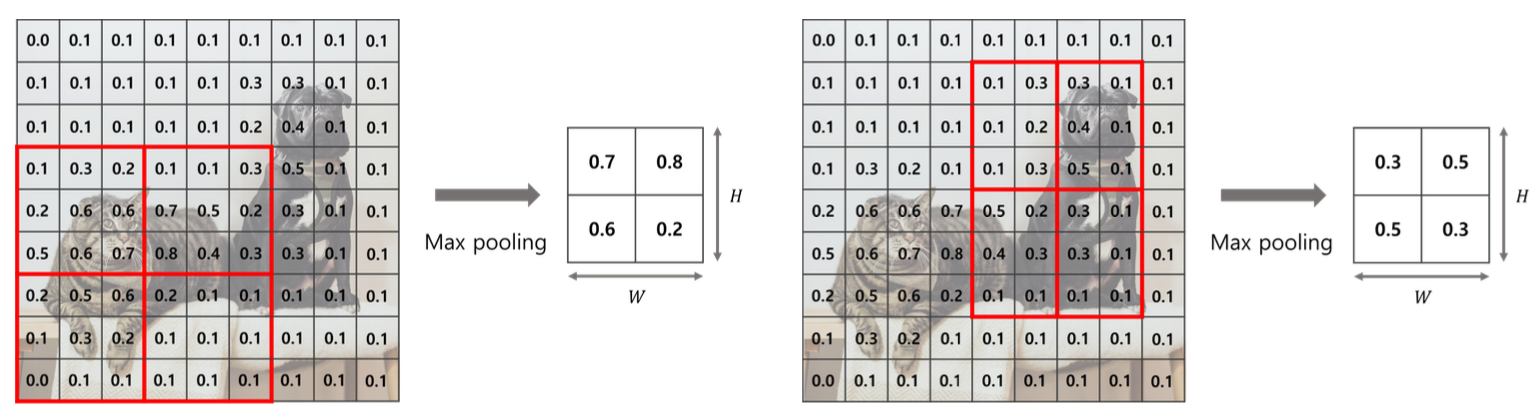
RoI Pooling
어떤 크기의 feature map이 들어와도 동일한 사이즈로 pooling하고자 하는 방법
- RoI를 지정된 size(WxH)에 맞추기 위해 그리드 설정 (66→22 / 46→22)
- 설정된 각 그리드에서 max 값을 가져와서 최종적으로 같은 size로 통일
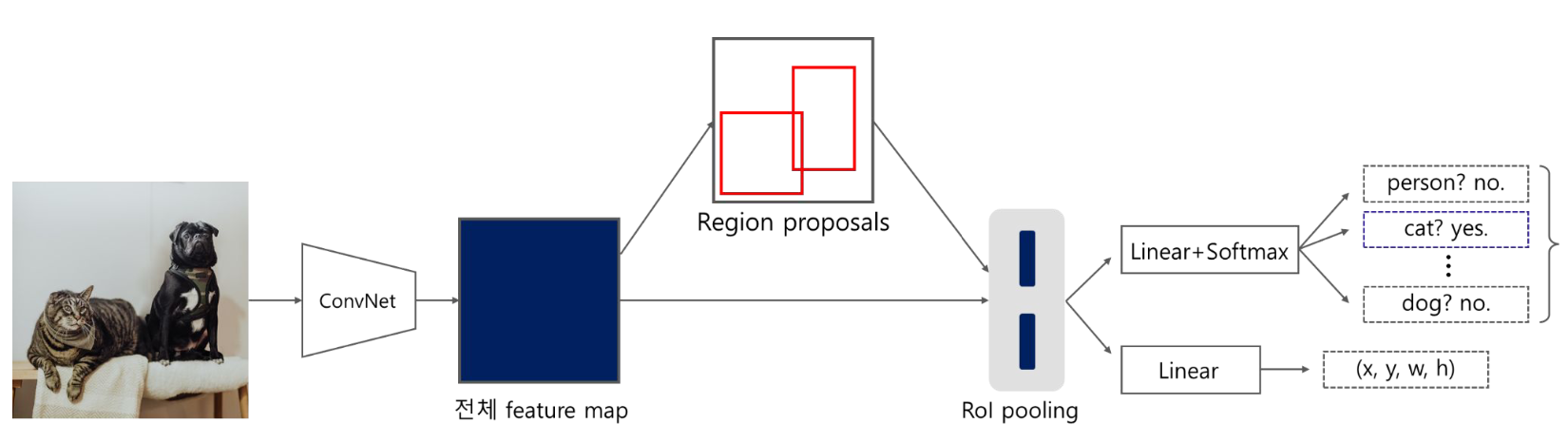
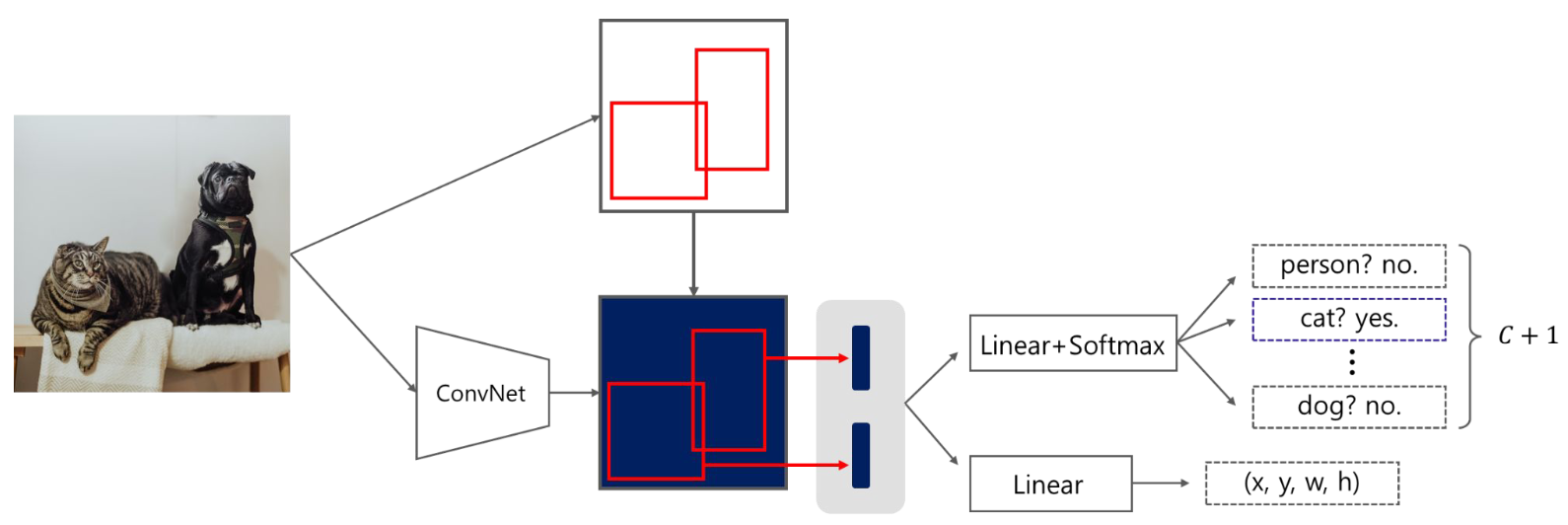
Fast R-CNN Pipeline
1-1. Input image에서 selective search를 통해 약 2000개의 roi 생성
1-2. 단일 CNN 연산으로 전체 feature map 생성
2. RoI projection, RoI pooling으로 각 RoI에 맞는 고정된 사이즈의 feature vector 생성
3. 추출된 feature vector에 대해 linear, softmax 연산 수행
- 이후, 각 RoI의 object에 대한 classification과 Bounding box regression 수행
Faster R-CNN
R-CNN, Fast R-CNN의 단점
- 픽셀 단위부터 영역을 병합하는 selective search는 GPU와 CPU 연산이 모두 필요하며 매우 느림
- GPU에서만 연산하는 network와 분리되어 end-to-end 학습이 불가능
Faster R-CNN
- Selective search를 제거하고 Region Proposal Network(RPN) 모듈을 사용하여 연산을 더 가속화한 모델
- 전체 프레임워크가 한번에 연산되는 end-to-end 모델
Region Proposal Network (RPN) 이란?
- GPU에서만 연산하여 RoI를 찾는 network를 만들자!
- 미리 지정된 크기의 anchor box를 이용하여 roi search
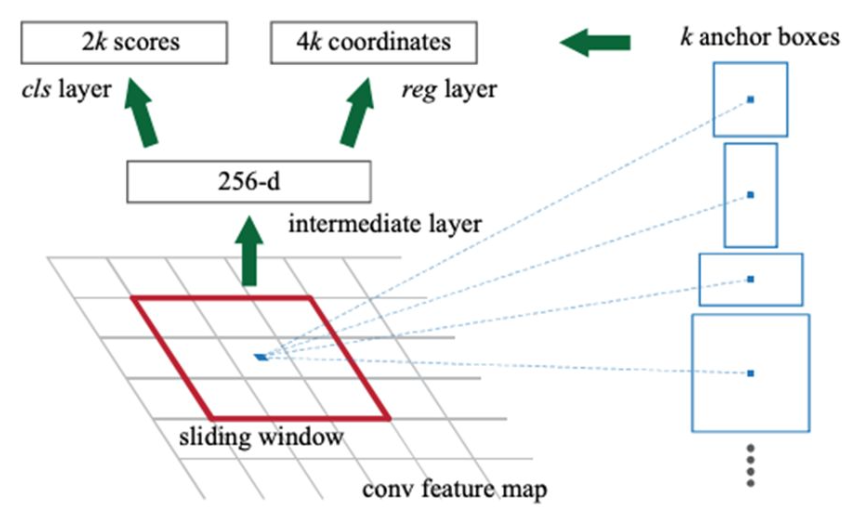
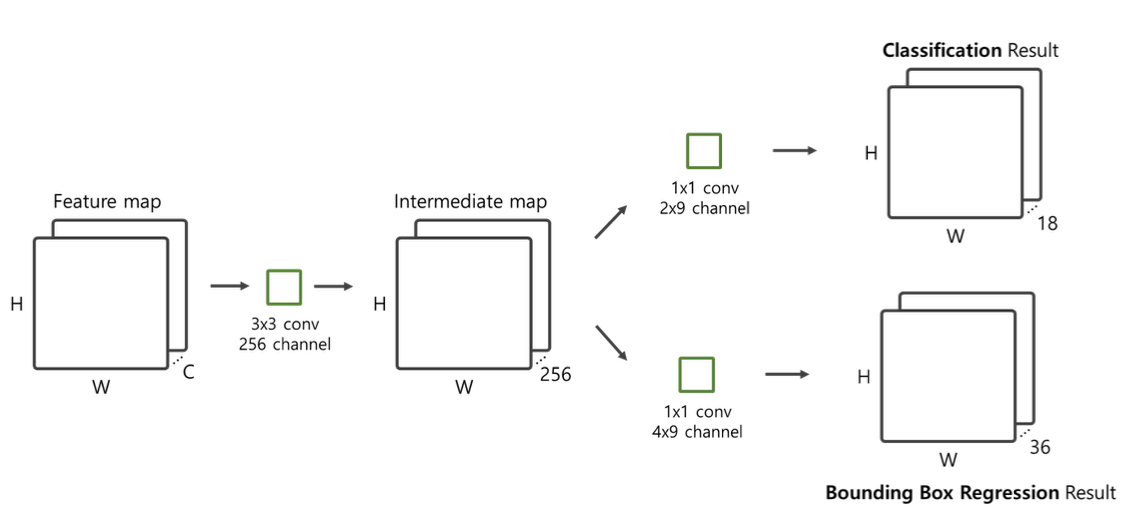
Region Proposal Network (RPN) 동작 과정
- CNN을 통해 얻은 feature map을 input으로 받아서 intermediate layer 생성
- 33256 또는 33512 convolution 사용
- Intermediate layer의 feature map을 입력받아 classification
- 1118 convolution: 2(object 여부) x 9(anchor의 개수)
- Intermediate layer의 feature map을 입력받아 bounding box regression
- 1136 convolution: 4(bbox의 좌표) * 9(anchor 개수)
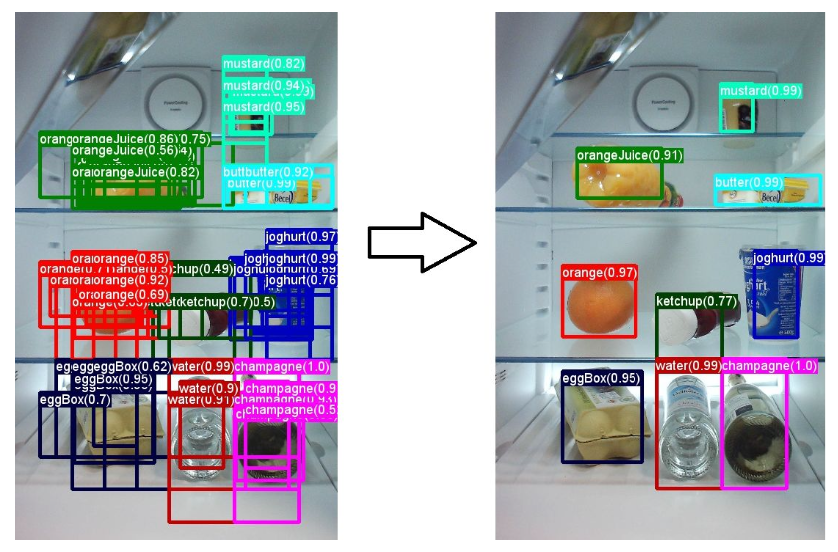
Non-maximum Suppression (NMS)
RPN으로 생성된 RoI 중에서 유사한 bounding box들을 제거하기 위해 사용
Faster R-CNN Pipeline
- CNN을 통해 전체 feature map 추출
- 생성된 feature map을 RPN, NMS 연산 후 RoI 생성
- RoI projection, RoI pooling을 통해 모든 RoI를 동일한 사이즈로 변환
- Softmax + bounding box regression 동시에 수행 (multi-task 학습)