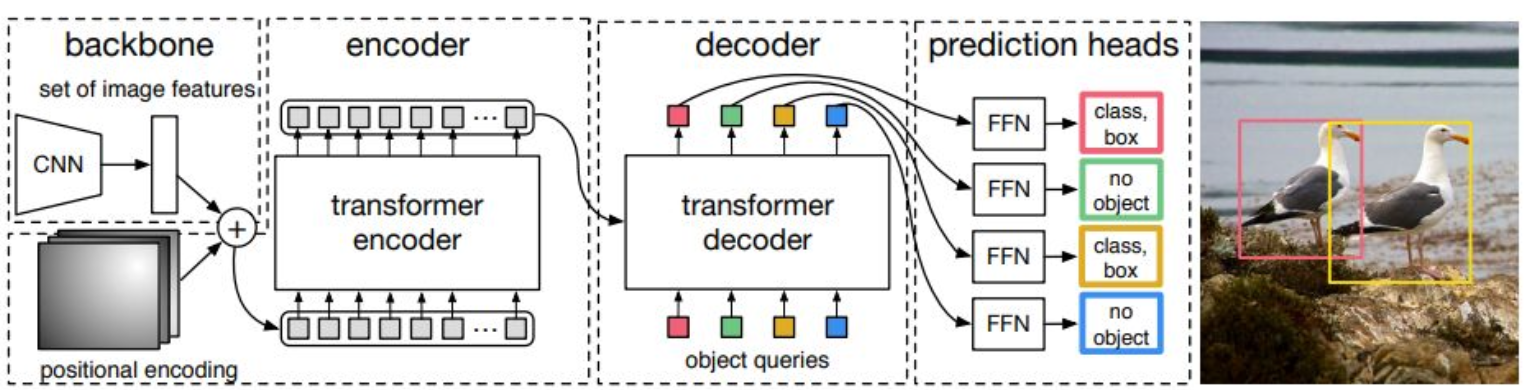
모델의 전체 구조
Image Classfification
Backbone -> Fully Connected Layers -> 활성화함수
-
Backbone: 이미지로부터 고수준 특징을 추출하기 위한 기본 네트워크.
여기서는 일반적으로 합성곱 신경망(CNN)이 사용되어 이미지 feature 추출한뒤 압축 -
Fully Connected Layers: 백본에서 추출된 특징을 바탕으로, 이미지가 속할 가능성이 있는 클래스에 대한 예측을 수행. 일반적으로 마지막에 하나 또는 그 이상의 완전 연결 계층이 사용.
-
활성화 함수: 최종 출력 계층에서는 Softmax 활성화 함수가 주로 사용되어, 각 클래스에 속할 확률을 출력.
Object Detection
Backbone -> (optional) Neck -> Head
-
Backbone: 객체 탐지에서도 백본은 이미지로부터 고수준의 특징을 추출하는 역할을 합니다.
-
(Optional) Neck: 일부 객체 탐지 모델에서는 백본과 헤드 사이에 넥이라고 불리는 추가적인 구조가 존재합니다. 이는 특징 맵의 품질을 개선하기 위해 사용되며, 예로는 FPN(Feature Pyramid Network)이 있습니다.
-
Head: 최종적으로, 헤드는 특징 맵을 바탕으로 객체의 클래스를 분류하고, 객체의 위치를 정의하는 바운딩 박스를 예측합니다. 객체 탐지 모델에서는 보통 여러 개의 작업(클래스 분류, 바운딩 박스 회귀)을 수행하는 여러 헤드가 있을 수 있습니다.
Semantic Segmentation
Backbone -> Encoder -> Decoder -> 활성화 함수
-
백본(Backbone): 이는 모델이 입력 이미지로부터 초기 고수준 특징을 추출하는 데 사용되는 기본 네트워크입니다. 대표적으로 ResNet, VGG, MobileNet 등이 백본으로 사용될 수 있습니다.
-
인코더(Encoder): 백본에서 추출된 특징을 바탕으로, 인코더는 이 특징들을 더 압축하고, 이미지의 중요한 정보를 캡처하는 동시에 차원을 줄입니다. 인코더는 일반적으로 여러 합성곱 계층과 풀링 계층으로 구성됩니다. 이 과정에서 활성화 함수가 사용되어 네트워크의 비선형성을 증가시킵니다.
-
디코더(Decoder): 인코더를 통해 압축된 특징 맵을 다시 확장하여, 최종적으로 원본 이미지 크기의 세그멘테이션 맵을 생성합니다. 디코더는 업샘플링 또는 전치 합성곱(transposed convolution)과 합성곱 계층을 사용하여, 각 픽셀에 대한 예측을 수행합니다. 여기서도 활성화 함수가 사용됩니다.
-
활성화 함수(Activation Functions): 이는 네트워크의 비선형성을 도입하기 위해 사용되며, ReLU 같은 활성화 함수가 인코더와 디코더의 합성곱 계층 후에 사용됩니다. 최종 출력 계층에서는 세그멘테이션 작업에 맞게 소프트맥스 또는 시그모이드 활성화 함수가 사용되어 각 픽셀의 클래스 확률을 출력합니다.
Backbone
- Backbone은 이미지에서 중요한 Feature를 추출(extract)할 수 있도록 훈련됨
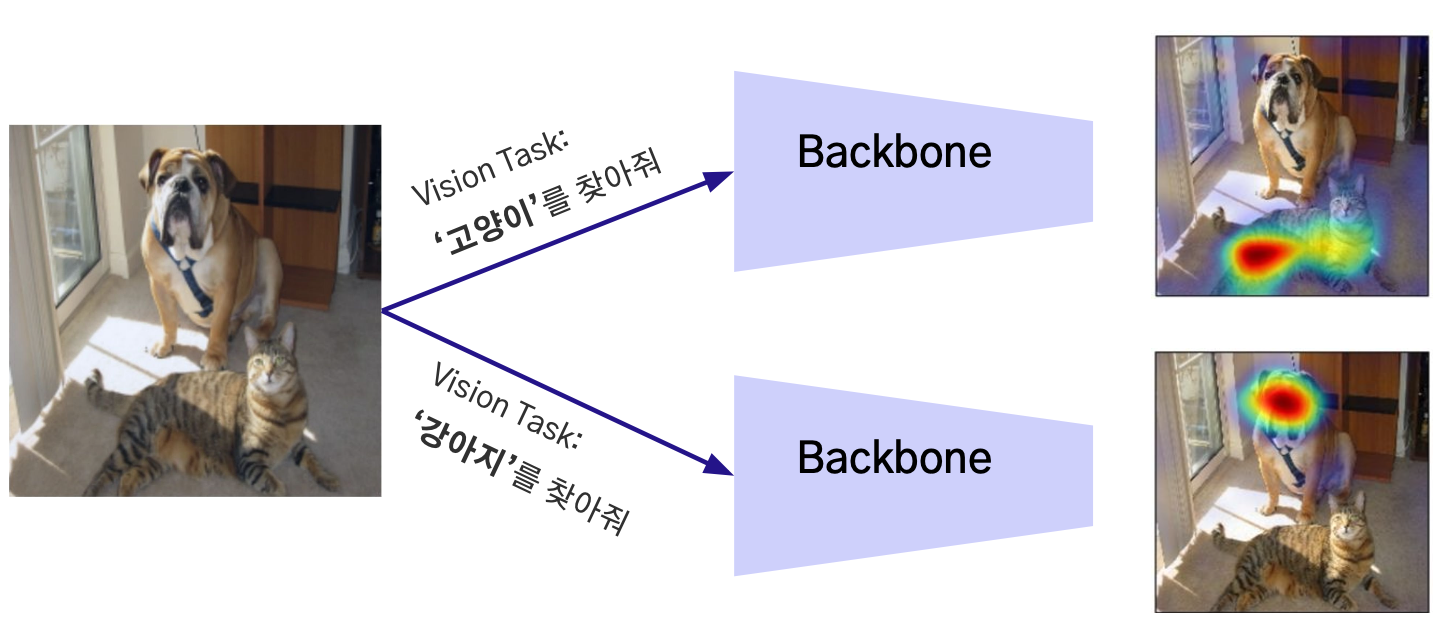
- Backbone의 역할은 주어진 비전 태스크를 잘 수행할 수 있는 압축된 Visual Feature를 산출하는 것
이미지나 비디오에서 고차원의 특징을 추출하는 데 사용되는 신경망의 일부입니다. 예를 들어, 객체 인식(object detection) 또는 세그멘테이션(segmentation) 작업을 수행할 때 백본 네트워크는 이미지에서 중요한 특징을 추출하는 기능을 합니다.
이러한 컴퓨터 비전 모델에서 백본은 흔히 사전 훈련된 모델(pre-trained model)을 사용하여 초기화됩니다. ResNet, VGG, MobileNet과 같은 모델들이 자주 사용되는 백본입니다. 이 백본은 더 복잡한 작업을 위한 다른 신경망 구조의 기반이 되며, 더 세분화된 특징을 추출하거나 특정 작업에 맞게 추가적인 네트워크 층을 쌓아 올릴 때 사용됩니다.
백본은 해당 분야에서 필수적인 기본적인 구조나 기능을 제공하는 중심적인 요소를 의미
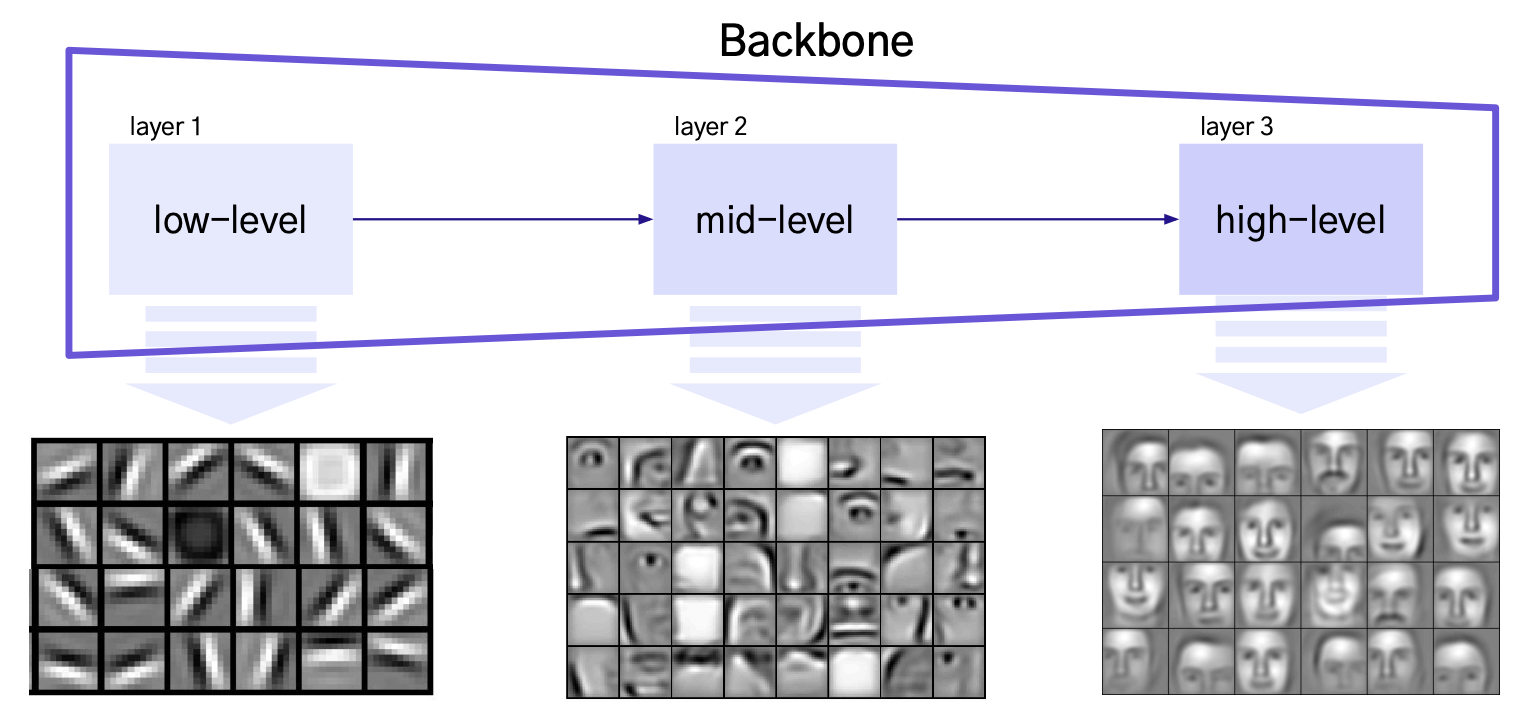
구조
- Layer: Input 이미지에서 Feature(points, edges, shapes, ...)를 추출하기 위한 연산을 하는 층
- Backbone은 여러 개의 Layer로 이루어져 있고, 이를 통해 다양한 Level의 Feature를 추출할 수 있음
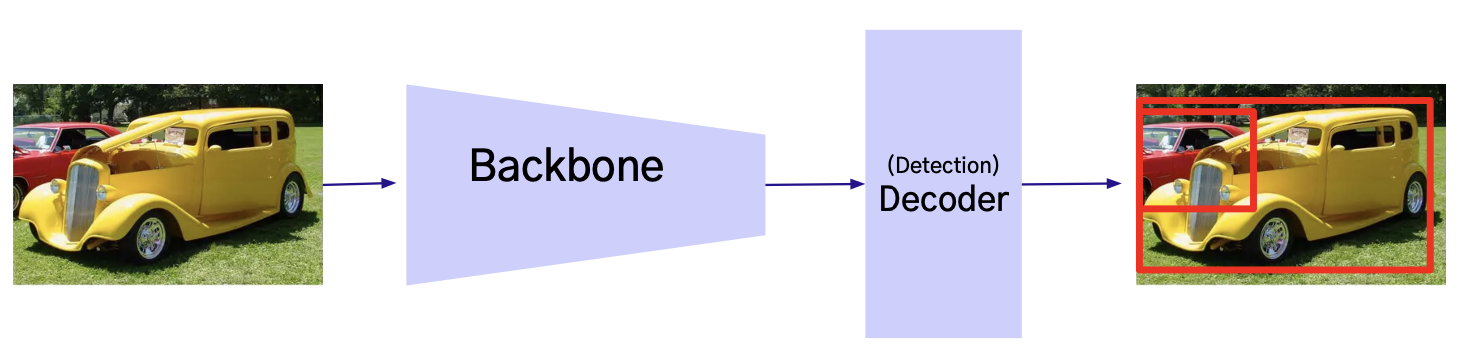
Decoder
- 모델의 쓰임새에 따라 다양한 비전 태스크가 존재함
- Decoder는 압축된 Feature를 목표하는 태스크의 출력 형태로 만드는 과정을 수행
딥 러닝 모델에서 합성곱 신경망(Convolutional Neural Network, CNN) 또는 다른 특징 추출 레이어를 통해 추출된 피처 맵(Feature Map)은 일반적으로 고차원 데이터임.
압축된 피처는 이러한 고차원 피처 맵을 더 작은 차원으로 축소하거나 압축하는 과정을 나타냄.
주로 피처 차원을 감소시켜 계산 효율성을 높이거나, 모델의 복잡도를 줄이는 데 사용.
비전 태스크 형태로의 출력(Vision Task Output):
"비전 태스크"는 컴퓨터 비전 분야에서 이미지 또는 비디오 관련 작업을 의미합니다. 이러한 작업은 이미지 분류, 객체 감지, 세그멘테이션, 키포인트 검출 등을 포함.
"비전 태스크 형태로의 출력"은 압축된 피처 또는 피처 맵을 활용하여 이러한 비전 태스크의 결과물을 생성하는 것을 의미
Task에 따른 Decoder 결과
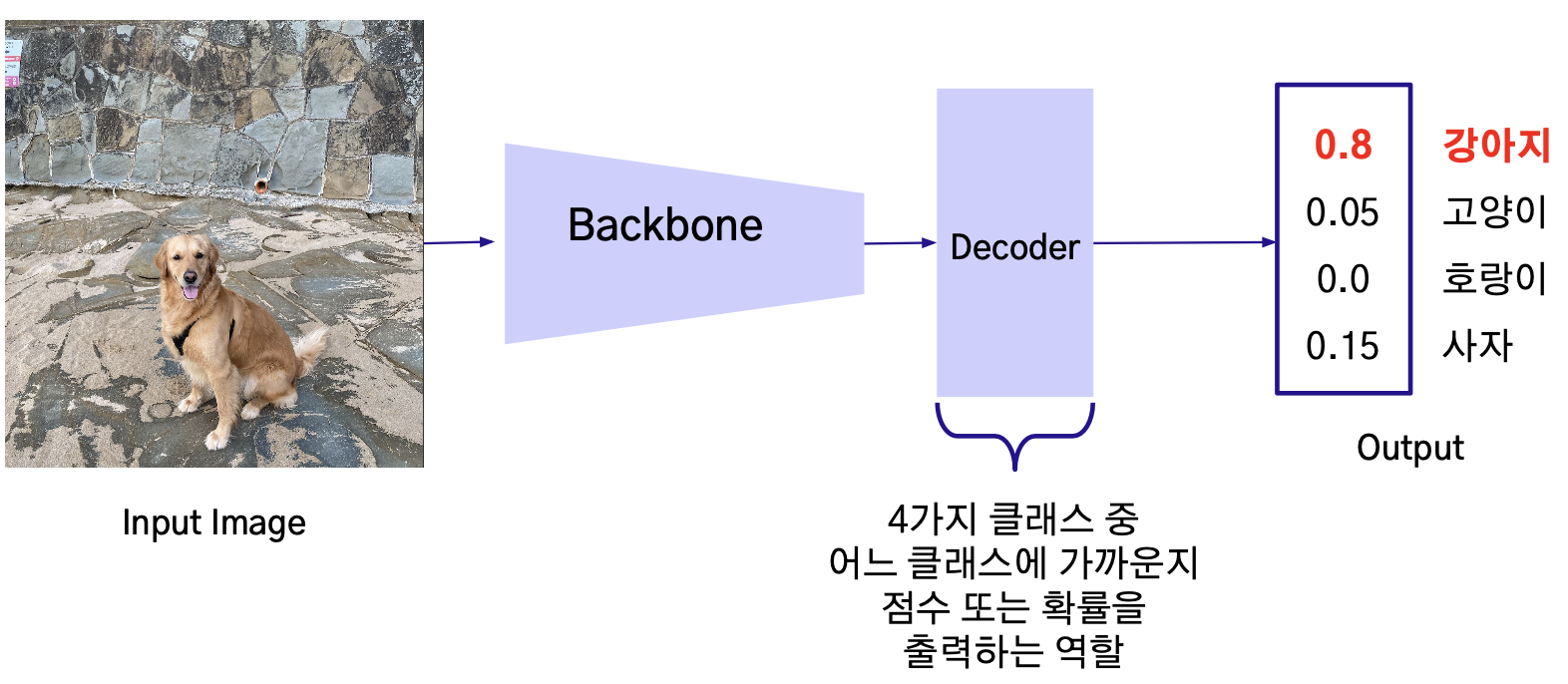
Classification
- ex) ‘강아지’, ‘고양이', ‘호랑이', ‘사자'를 포함하고 있는 데이터로 학습한 classification 모델의 경우
-
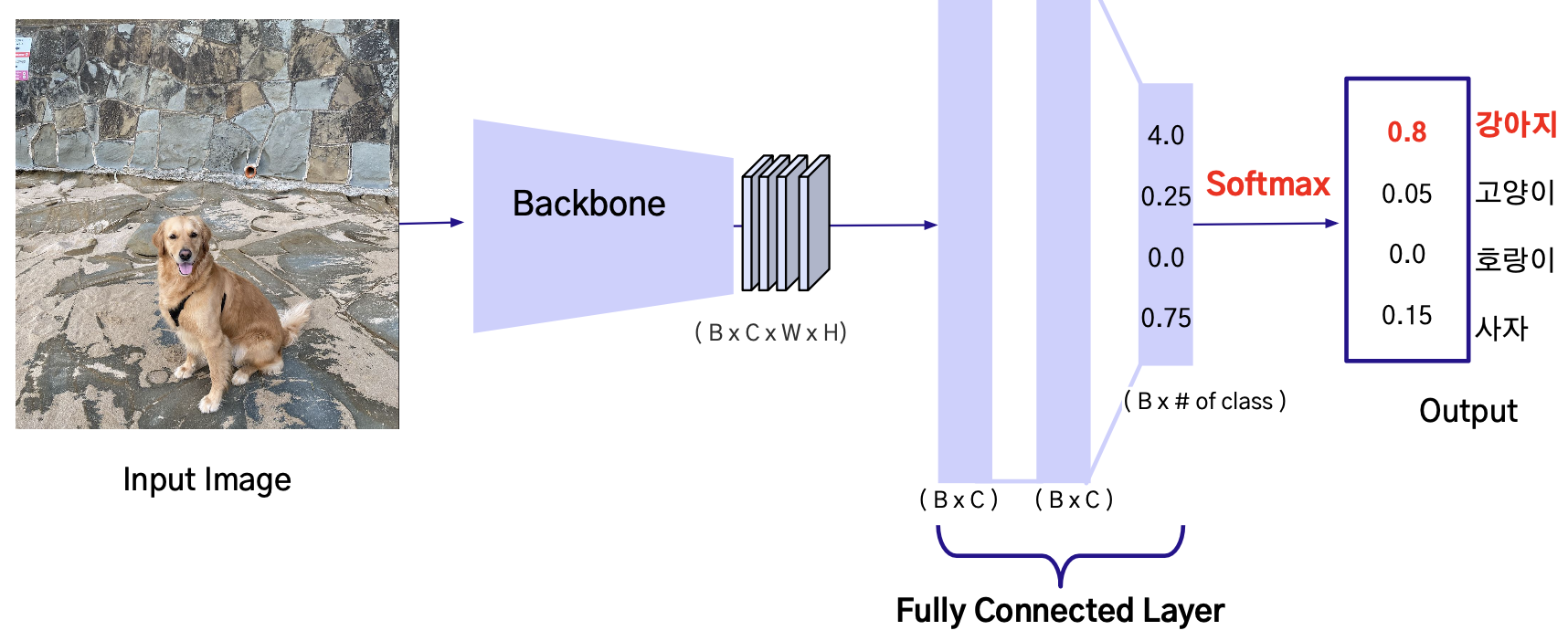
Fully Connected Layer (FC Layer): 한 layer가 다음 layer와 완전히 연결되어 있는 layer로, 이미지 분류 모델에서 Decoder의 역할로 사용됨
-
Softmax: 입력 받은 값을 모두 [0,1] 사이로 정규화 시켜주는 함수를 말함. 이를 통해 Decoder의 출력물을 각 클래스에 해당할 확률로 나타낼 수 있게 됨.
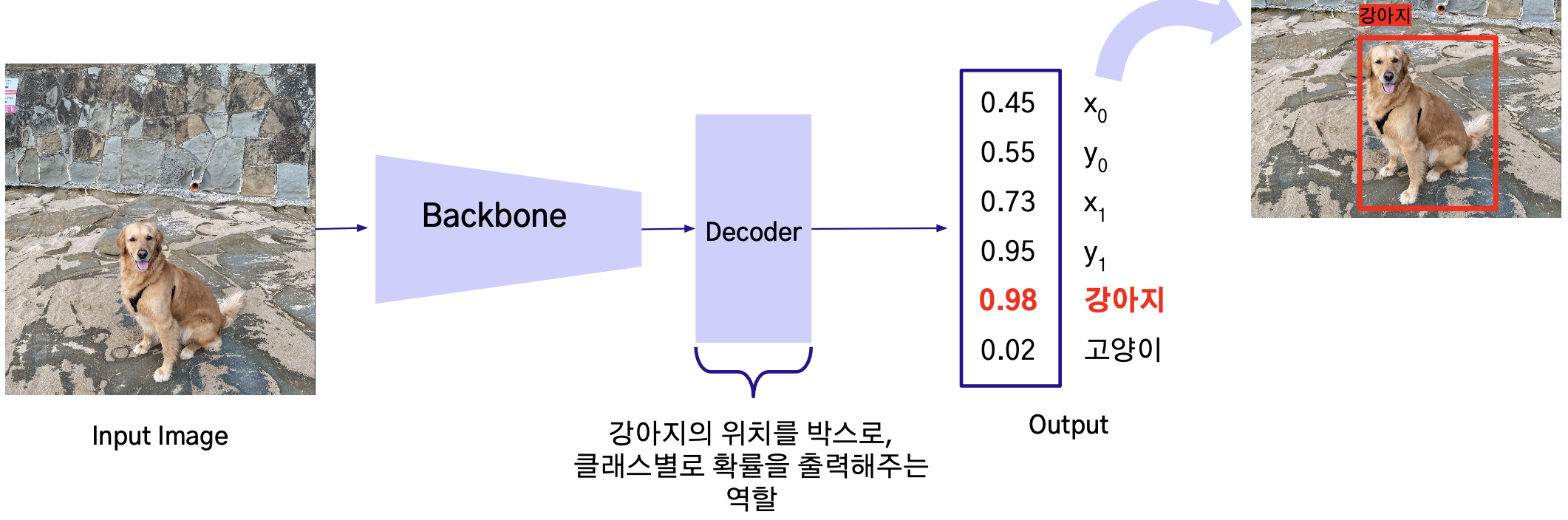
Detection
- ex. ‘강아지’와 ‘고양이'를 탐지할 수 있는 데이터로 학습한 detection 모델의 경우
Segemetation
- ex. ‘강아지’와 ‘고양이'의 영역을 알 수 있는 데이터로 학습한 segmentation 모델의 경우
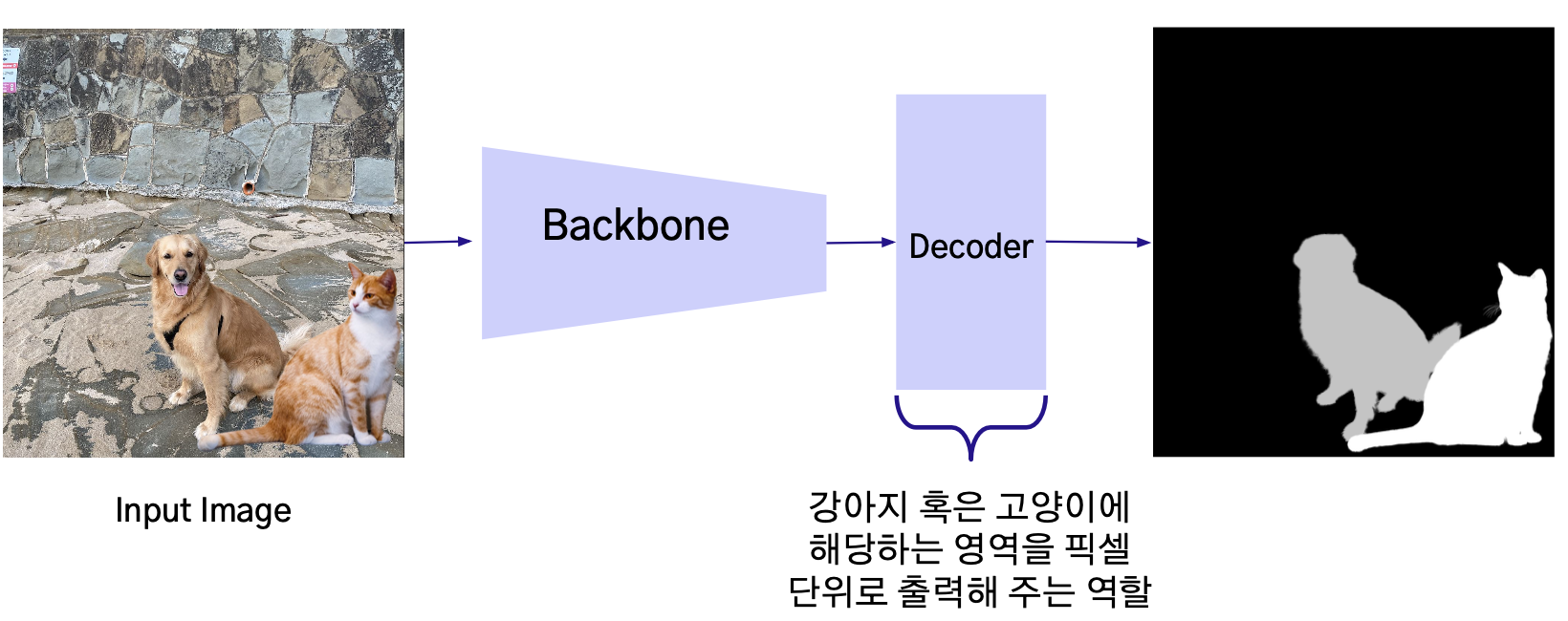
- Backbone은 입력 이미지에서 유의미한 Feature를 추출한 뒤 압축하는 역할이므로, 태스크 종류가 다르더라도 동일한 Backbone을 사용할 수 있음.
- Decoder의 경우에는 최종 결과를 출력해주는 역할이므로, 비전 태스크가 바뀐다면 올바른 형태로 결과를 산출할 수 있도록 디코더 구조를 변경시켜 주어야 함
Encoder
일부 모델들의 경우 Backbone 이후에 Encoder를 도입하여 Feature와 Image Patch들 사이의 관계를 학습시키기도 함