
1. Confusion Matrix란?
분류 모델이 예측한 결과와 실제 정답을 비교하여 성능을 평가하는 표
예측이 맞았는지/틀렸는지를 한눈에 볼 수 있다.
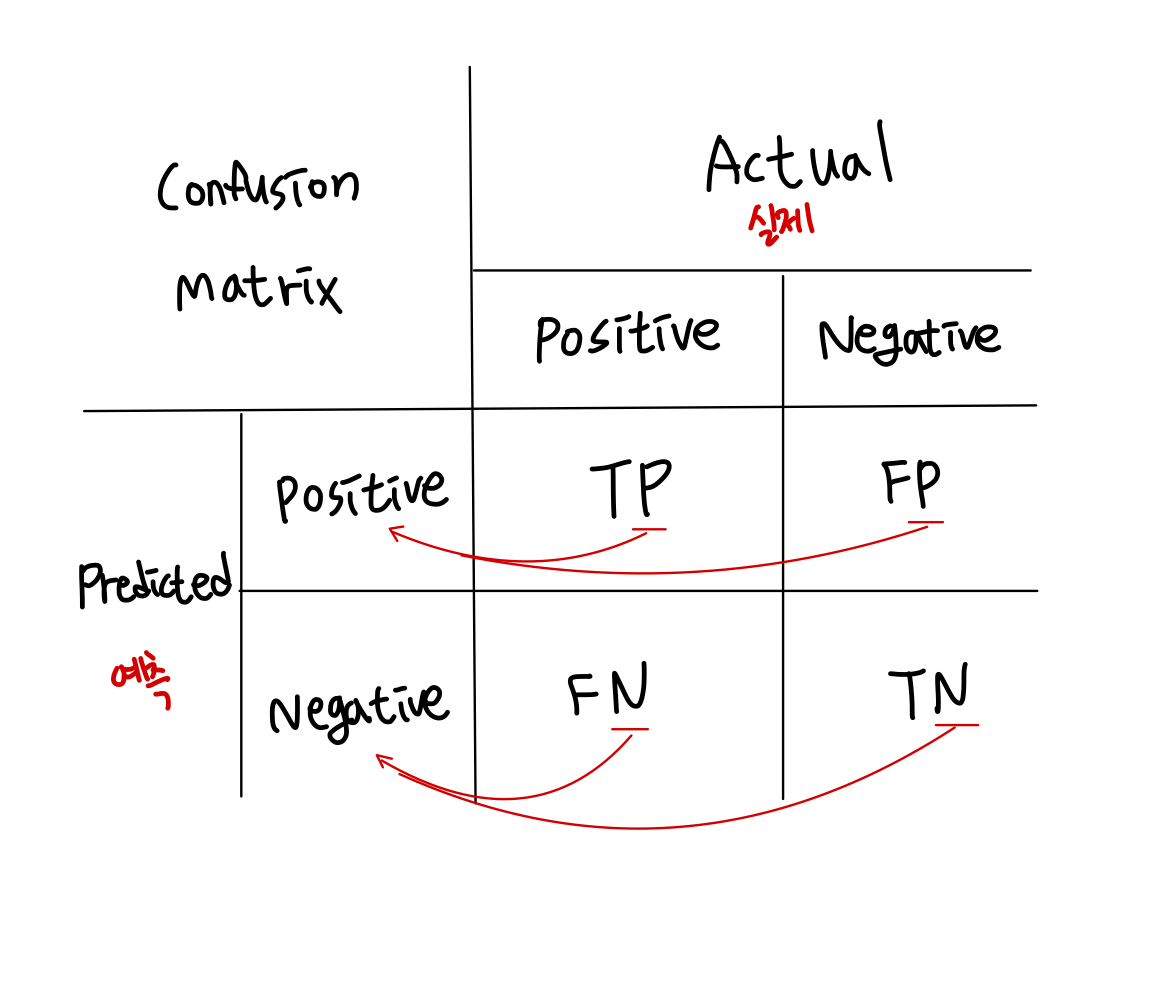
- TP: 실제 양성을 맞게 양성으로 예측(P)
- FP: 실제 음성인데 잘못 양성으로 예측(P)
- FN: 실제 양성인데 잘못 음성으로 예측(N)
- TN: 실제 음성을 맞게 음성으로 예측(N)
주요 성능 지표
- Accuracy (정확도)
전체 중 모델이 실제로 맞춘 비율. 클래스 불균형 데이터에는 적합하지 않을 수 있다.- Precision (정밀도)
모델이 Positive라고 예측한 것 중 실제로 맞은 비율- Recall (재현율, 민감도)
실제 Positive 중 모델이 잘 잡아낸 비율.- F1-score
Precision과 Recall의 조화 평균. 불균형 데이터 평가에 유용하다.예시
- Precision ↑ : 양성이라고 하면 진짜 양성일 확률이 높다.
- Recall ↑ : 양성을 놓치지 않고 잘 잡아낸다.
- Accuracy만 높아도 함정 : 예를 들어 데이터가 95% 음성이고 5% 양성이라면, 무조건 음성만 예측해도 Accuracy는 95%! 하지만 Recall은 0.
실전 활용 예시
- 의료 진단 모델 : Recall(민감도)이 중요 → 환자를 놓치면 안 됨.
- 스팸 메일 필터링 : Precision이 중요 → 정상 메일이 스팸 처리되면 안 됨.
- 신용카드 사기 탐지 : Recall과 Precision의 균형(F1-score)이 중요하다. → Why?
-
데이터 불균형
실제 신용카드 거래 중 사기는 극소수기 때문에,
10,000건 중 9,990건은 정상이고 10건만 사기라면 ?
무조건 정상이라고만 예측해도 정확도 99.9%,그러나 Recall = 0
이므로 사기를 하나도 잡을 수 없음.
-
Precision(정밀도) vs Recall(재현율)
정밀도 : 잡아낸 거래 중 사기일 확률 → 너무 낮으면 정상 거래를 막아서 고객 불편 높아짐 재현율 : 실제 사기를 놓치지 않고 잡아낸 비율 → 낮으면 사기를 못잡는다는 의미 = 따라서 사기 탐지는 정상 거래를 차단하면 안되고, 동시에 사기를 놓쳐서도 안됨!!그래서 F1-Score✅
Precision과 Recall의 적절한 조화가 이루어져야함.
둘 중 하나만 높은 경우보다, 둘다 적절히 높은 점수여야한다.
-
모델1 : Precision = 0.95, Recall = 0.20 → F1 = 0.33
-
모델2 : Precision = 0.80, Recall = 0.75 → F1 = 0.77
모델 2가 훨씬 현실적으로 유용한 모델임!
-

취준하는 데이터 분석가의 정리노트📘