- 데이터셋은 2차원 배열을 전달
- Data 전처리(Data Preprocessing)
- Raw Data을 학습하기 전에 변경하는 작업이다.
- 목적에 따른 전처리 분류 2가지
- 학습이 가능한 데이터셋을 만들기 위한 전처리
(머신러닝 알고리즘 수식이기때문에 숫자만 처리할 수 있어 결측치, 문자열이 있으면 학습이나 추촌을 할 수 없다.) - 학습이 더 잘되도록 만들기 위한 전처리
- 학습이 가능한 데이터셋을 만들기 위한 전처리
- 결측치 처리
- 수집하지 못한 값, 모르는 값
- 머신러닝 알고리즘은 데이터셋에 결측치가 있으면 학습이나 추론을 하지 못하기 때문에 적절한 처리가 필요하다.
- 결측치 처리는 데이터 전처리단계에서 진행한다.
- 결측치 처리방법
- 제거(열단위/행단위-기본)
- 다른 값으로대체
- 가장 가능성이 높은 값으로 대체
- 결측치 자체를 표현하는 값을 만들어서 대체
- 이상치(Outlier) 처리
- 의미 그대로 이상한 값, 튀는 값. 패턴으 벗어난 값으로 그 Feature를 가지는 대부분의 값들과 동떨어진 값
- 오류값
- 처리 - 결측치로 변환 후 처리
- 극단치(분포에서 벗어난 값)
- 처리 - 값 유지 / 결측치로 변환 / 다른값으로 대체(보통 그 값이 가질 수 있는 Min/Max값 설정하고 그 값으로 변경)
Feature 타입 별 전처리
<통계에서의 데이터 타입>
-
어떤 종류의 값을 모았는지에 따라 크게 범주형과 수치형으로 나눈다.
-
통계적으로 데이터형식을 나누는 기준에는 여러개가 존재한다.
- 범주형(Categorical) 변수
=> 개별값들이 이산적(Discrete)이며, 값이 가질수 있는 대상값이 몇가지 범주(Category)로 정해져 있는 데이터 타입
즉, 기준이 정해져있는 것.
이산적(Discrete): 대상 값이 연속적이지 않고 떨어져 있는 형태
-
범주형 변수의 종류(2가지)
❤️ 명목(Norminal) 변수/비서열(Unordered) 변수
: 서열이 없는 변수로 단순 분류가 목적인 타입 ex) 성별, 혈액형
❤️ 순위(Ordinal) 변수/서열(Ordered) 변수
: 범주에 속한 값들 사이에 서열(순위) 존재 ex) 성적, 직급, 만족도 -
수치형(Numerical) 변수
=> 숫자 데이터 타입이다.
=> 보통 중복된 값이 없거나 적고 값으로 올 수 있는 대상이 정해져 있지 않다.
=> 이산형과 연속형 변수로 구성된다.❤️ 이산형(Discrete) - 정수형
=> 수치적 의미를 가지지만 실수(소숫점)형태로 표현되지 않는 값 ex) 물건의 재고량
❤️ 연속형(Continous)
=> 수치적 의미를 가지고 실수(소숫점)로 표현이 가능한 측정 할 수 있는 값 ex) 키, 몸무게
- 범주형(Categorical) 변수
-
"동일한 데이터도 어떻게 표현하느냐에 따라 다양한 타입으로 표현이된다. 예를들어 키는 그 자체가 연속형이지만 150cm대, 160cm대 이렇게 묶어서 표현하면 범주형이 된다."
<정리>
- 파이썬 데이터 타입별
- 실수형 데이터로 구성된 Feature는 연속형 값이다.
- 문자열 데이터로 구성된 Feature는 단순 문자열값이거나 범주형 값이다.
- 정수형 데이터로 구성된 Feature는 범주형이거나 일반 수치형(이산형)값이다. (고유값 몇개인지 확인하기!)
그럼 위에서 개념으로 설명한 부분들을 자세하게 사용법 및 처리방법을 예시와 함께 배워보자.
범주형 데이터 전처리
다시한번 말하자면 Scikit-learn의 머신러닝 API들은 Feature나 Label의 값들이 숫자(정수/실수)인 것만 처리할 수 있다.
그러므로 문자열(str)일 경우 숫자 형으로 변환해야 한다.
-
범주형 변수의 경우 전처리를 통해 정수값으로 변환
-
범주형이 아닌 단순 문자열인 경우 일반적으로 제거
-
범주형 Freature 처리 방법
- Label Encoding
- One-Hot Encoding
-
레이블 인코딩(Label Encoding)
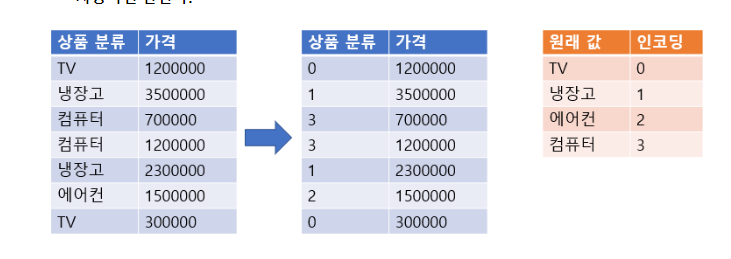
- 범주형 Feature의 고유값들을 오름차순으로 정렬 후 0부터 1씩 증가하는 값으로 변환
- 숫자의 크기의 차이가 모델에 영향을 주지 않는 트리 계열 모델(의사결정나무, 랜덤포레스트)에 적용
- sklearn.preprocessing.LabelEncoder 사용
- fit(): 어떻게 변환할 지 학습
- transform(): 문자열를 숫자로 변환
- fit_transform(): 학습과 변환을 한번에 처리
- inverse_transform():숫자를 문자열로 변환
- classes_ : 인코딩한 클래스 조회
items = ['TV', '냉장고', '컴퓨터', '컴퓨터', '냉장고', '에어콘', 'TV', '에어콘']
from sklearn.preprocessing import LabelEncoder
# LabelEncoder생성
le = LabelEncoder()
# 학습 (변환할 리스트를 학습)
le.fit(items)
# 변환 (학습한 le객체에 변환할 리스트를 넣어 변환)
item_label = le.transform(items)
item_label # 결과 array([0, 1, 3, 3, 1, 2, 0, 2])
# 여기까지 레이블인코딩으로 문자를 숫자로 바꾸기
# 인코딩된 클래스를 확인
le.classes_
# 결과 array(['TV', '냉장고', '에어콘', '컴퓨터'], dtype='<U3')
# 디코딩
le.inverse_transform([3, 2, 2, 1, 0, 0])
# 결과 array(['컴퓨터', '에어콘', '에어콘', '냉장고', 'TV', 'TV'], dtype='<U3')<심화>
# fit()과 transform()의 대상이 같은경우 -> fit_transform()
le2 = LabelEncoder()
item_label2 = le2.fit_transform(items)
print(item_label2)
print(le2.classes_)
# 결과
[0 1 3 3 1 2 0 2]
['TV' '냉장고' '에어콘' '컴퓨터']
# fit() 대상과 transform()대상이 다른경우
class_names = ["냉장고", "TV", "에어컨", "컴퓨터", "노트북", "스마트폰"]
le3 = LabelEncoder()
le3.fit(class_names)
print(le3.classes_)
# 결과 ['TV' '냉장고' '노트북' '스마트폰' '에어컨' '컴퓨터']
item_label3 = le3.transform(items)
print(item_label3)
# 결과 [0 1 5 5 1 4 0 4]<여기서 잠깐!>
왜 같은 items를 문자에서 수치형태로 변환한건데 변환된 값이 다르지?
이유:fit_transform() / fit(),transform() 사용 차이
-
fit_transform() 메서드로 items 리스트의 각 텍스트 값을 수치 데이터로 변환합니다. 수치화된 각 값은 fit() 메서드를 사용하지 않고, 상황에 따라 난수로 정해지기 때문에 변환된 결과값이 매번 달라질 수 있습니다.
-
fit() 메서드로 class_names 리스트에서 사용될 문자열 값을 레이블 인코딩할 때 사용될 수치 값의 매핑을 학습합니다. 이후 le3.transform(items) 코드의 transform() 메서드는 이미 학습된 매핑으로 items 리스트의 각 텍스트 값을 수치 데이터로 변환합니다. 따라서 변환된 결과값은 fit_transform() 메서드와 달리 매번 달라지지 않습니다.
원핫 인코딩(One-Hot encoding)
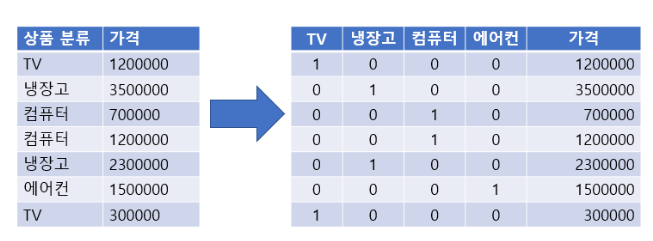
- N개의 클래스를 N차원의 One-Hot 벡터로 표현되도록 변환
- 고유값들을 Feature(컬럼)로 만ㄷ르고 정답인 열은1 나머지는 0으로 표시
- 숫자의 크기 차이가 모델에 영향을 미치는 선형 계열 모델(로지스틱회귀, SVM, 신경망)에서 범주형 데이터 변환시 Label Encoding보다 One Hot Encoding을 사용한다.
- One-Hot Encoding 변환 처리
- sklearn.preprocessing.OneHotEncoder 이용
- fit(데이터셋): 데이터셋을 기준으로 어떻게 변환할 지 학습
- transform(데이터셋): Argument로 받은 데이터셋을 원핫인코딩 처리
- fit_transform(데이터셋): 학습과 변환을 한번에 처리
- get_feature_names_out() : 원핫인코딩으로 변환된 Feature(컬럼)들의 이름을 반환
- sklearn.preprocessing.OneHotEncoder 이용
"원핫인코딩 처리시 모든 타입의 값들을 다 변환한다. (연속형 값들도 변환) 그래서 변환려는 변수들만 모아서 처리해야 한다."
import numpy as np
items=np.array(['TV','냉장고','전자렌지','컴퓨터','선풍기','선풍기','믹서','믹서', "냉장고"])
items = items[..., np.newaxis]
from sklearn.preprocessing import OneHotEncoder
# OneHotEncoder 객체 생성
ohe = OneHotEncoder()
# 학습
ohe.fit(items)
# 변환
result = ohe.transform(items)
result.toarray()
# 결과
array([[1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 1.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0., 0.],
[0., 1., 0., 0., 0., 0.]])
pd.DataFrame(result.toarray(), columns=ohe.get_feature_names_out())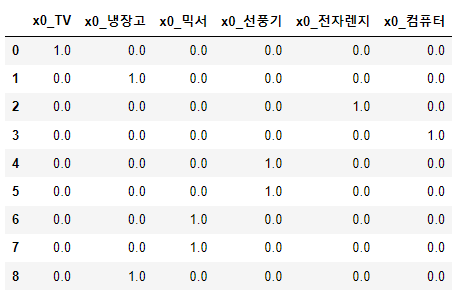
- OneHotEncoder객체 생성시 sparse 매개변수의 값을 False로 설정하지 않으면 scipy의 csr_matrix(희소행렬 객체)로 반환.
- 희소행렬은 대부분 0으로 구성된 행렬과 계산이나 메모리 효율을 이용해 0이 아닌 값의 index만 관리한다.
=> csr_matrix.toarray()로 ndarray로 바꿀수 있다.
수치형 데이터 전처리
- 데이터의 속성인 각 feature들간의 값의 척도(Scale)를 같은 기준으로 통일하기 위해 Feature Scaling(정규화)를 진행한다.
척도: 값을 측정하거나 평가하는 단위. ex) cm, km, kg
처리방법
1. Scaling(정규화)은 train set으로 학습(fitting) 한다
2. test set, validation set 그리고 모델이 예측할 새로운 데이터는 train set으로 학습한 scaler를 사용해 변환만 한다.
"새로운 데이터들이 모델링할 때 사용할 데이터셋(sample)의 scale과 같다라고 보장할 수 없으므로 전체 sample 데이터셋을 학습 시킨 뒤 train/validation/test 으로 나누는 것은 모델의 정확한 성능평가를 할 수 없다. 그러므로 sample데이터셋 학습 전 나눈다."
종류
- 표준화(Standardization) Scaling
- StandardScaler 사용
- Min Max Scaling
- MinMaxScaler 사용
메소드
- fit(): 어떻게 변환할 지 학습
- 2차원 배열을 받으면 0축을 기준으로 학습한다. (DataFrame으로는 컬럼기준)
- transform(): 변환
2차원 배열을 받으며 0축을 기준으로 변환한다. (DataFrame으로는 컬럼기준) - fit_transform(): 학습과 변환을 한번에 처리
- inverse_transform(): 변환된 값을 원래값으로 복원
표준화(StandardScaler)
- Feature의 값들이 평균이 0이고 표준편차가 1인 범위에 있도록 변환
=> 0을 기준으로 모든 데이터가 모여있게 된다. - sklearn.preprocessing.StandardScaler 를 이용
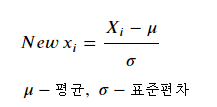
# iris dataset
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
df = pd.DataFrame(iris['data'], columns=iris.feature_names)
scaler = StandardScaler() # 객체생성
scaler.fit(iris['data']) # 데이터를 학습
iris_scaled = scaler.transform(iris['data']) # 변형
iris_scaled[:5]
# 결과
array([[-0.90068117, 1.01900435, -1.34022653, -1.3154443 ],
[-1.14301691, -0.13197948, -1.34022653, -1.3154443 ],
[-1.38535265, 0.32841405, -1.39706395, -1.3154443 ],
[-1.50652052, 0.09821729, -1.2833891 , -1.3154443 ],
[-1.02184904, 1.24920112, -1.34022653, -1.3154443 ]])Feature scaling
처리방법
1. scaler는 train set으로 학습(fit) 시킨다.
2. train, validation, test set은 train set으로 학습한 scaler로 변환한다. ==> validation, test set은 학습시키지 않는다.
# 분리
X_tmp, X_test, y_tmp, y_test = train_test_split(iris['data'], iris['target'],
test_size=0.2, stratify=iris['target'],
random_state=0)
X_train, X_val, y_train, y_val = train_test_split(X_tmp, y_tmp, test_size=0.2,
stratify=y_tmp, random_state=0)
# X_train으로 scaler 학습(fit())
scaler = StandardScaler()
scaler.fit(X_train)
# X_train을 Fit한 scaler를 이용해서 X_train, X_val, X_test 변환
X_train_scaled = scaler.transform(X_train)
X_val_scaled = scaler.transform(X_val)
X_test_scaled = scaler.transform(X_test)
print(X_train_scaled.mean(), X_train_scaled.std())
# 결과
2.6830389761774615e-16 0.9999999999999998
print(X_val_scaled.mean(), X_val_scaled.std())
# 결과
-0.10386741503088819 1.0571753140306965
print(X_test_scaled.mean(), X_test_scaled.std())
# 결과
-0.031708659543466244 0.9171878015445646MinMaxScaler
- 데이터셋의 모든 값을 0(Min value)과 1(Max value) 사이의 값으로 변환
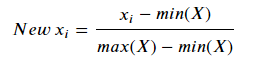
from sklearn.preprocessing import MinMaxScaler
# iris dataset
# train set의 min, max
print("Min value - train, val, test")
print(X_train.min(axis=0), X_val.min(axis=0), X_test.min(axis=0))
print("Max value - train, val, test")
print(X_train.max(axis=0), X_val.max(axis=0), X_test.max(axis=0))
# 결과
Min value - train, val, test
[4.3 2.2 1. 0.1] [4.7 2. 1.4 0.1] [4.6 2.4 1.3 0.1]
Max value - train, val, test
[7.9 4.4 6.7 2.5] [7.7 4.2 6.9 2.3] [7.2 3.8 6. 2.5]
# MinMaxScaling
mm_scaler = MinMaxScaler() # 객체생성
X_train_scaled_mm = mm_scaler.fit_transform(X_train) # 학습+변환: train set
X_val_scaled_mm = mm_scaler.transform(X_val) # trainset으로 학습한 scaler를 이용 변환
X_test_scaled_mm = mm_scaler.transform(X_test) # trainset으로 학습한 scaler를 이용 변환
print("Max value - train, val, test")
print(X_train_scaled_mm.max(axis=0), X_val_scaled_mm.max(axis=0), X_test_scaled_mm.max(axis=0))
print("Min value - train, val, test")
print(X_train_scaled_mm.min(axis=0), X_val_scaled_mm.min(axis=0), X_test_scaled_mm.min(axis=0))
# 결과
Max value - train, val, test
[1. 1. 1. 1.] [0.94444444 0.90909091 1.03508772 0.91666667] [0.80555556 0.72727273 0.87719298 1. ]
Min value - train, val, test
[0. 0. 0. 0.] [ 0.11111111 -0.09090909 0.07017544 0. ] [0.08333333 0.09090909 0.05263158 0. ]
감사합니다, 공부에 유용히 사용하겠습니다!