본 페이지에서는 Text Summarization with Pretrained Encoders 논문에 대해서 말하고자 합니다.
BERT에 대한 이해가 있으면 논문 읽기가 편하실 거 같아 아래의 링크와 함께 같이 보시는 걸 추천드립니다.
1. Intro
기존의 언어 모델(ELMo, GPT, BERT)들은 감정 분석, QA(질문 답변), 자언여 추론 등 여러 Task에 대해서 좋은 성능을 냈습니다.
그러나 자연어 요약 부문에서는 좋은 성능을 내지 못합니다.
그 이유는 요약을 위해서는 문장 단위의 의미를 이해하고 이에 따른 요약이 필요하지만, 기존의 모델들은 토큰 단어의 의미를 이해하도록 학습 하기 때문에 요약의 성능이 저하됩니다.
그래서 본 논문에서는 이를 해결하기 위해 문장단위의 사전학습을 진행하는 BERT 모델을 기반으로 파인튜닝을 진행합니다.
자연어 요약은 크게 두가지로 나누어 집니다.
-
Extract(추출 요약) : 여러 문장들 중에서 주요한 문장들을 파악하고 선택(이진 분류)하여 적절한 요약문으로 추출하는 과정
-
Abstract(추상 요약) : 주요 문장의 의미를 파악하고 의미에 맞게 적절한 요약문을 생성(자연어 추론)하는 과정
저자가 말하는 본 논문의 장점은 다음과 같습니다.
본 논문에서는 어려운 방법론(강화 학습, 다양한 Encoder 사용)을 사용하는 것과는 달리 간단하게 위의 두 과정을 순차적으로 Fine-Tuning 하는 방식으로 추출 요약, 추상 요약 부분에서 SOTA를 달성할 수 있도록 하였습니다.
2. Why BERT?

위 이미지는 BERT 논문에 있는 이미지 입니다.
BERT는 문장에서 토큰화 된 단어 중 일부 토큰을 가리고 모델이 가려진 토큰을 예측하도록 하는 Masked Language Model(MLM)입니다.
기존의 Transformer 모델과 동일하게 BERT는 단어를 토큰으로 임베딩하는 Token Embedding 부분과 위치 정보를 추가해주는 Position Embedding을 추가합니다.
다른 점은 Segment Embedding이며 이는 각 단어가 어떤 문장에 속했는지에 대한 정보를 제공합니다.
예를 들면 다음과 같습니다.
문장 1 : 나는 밥을 먹었다.
문장 2 : 너는 라면을 먹었다.
BERT는 두 문장을 동시에 입력으로 넣기 위해 [SEP] 토큰을 기준으로 두 문장을 왼쪽과 오른쪽 나누고 각각 다른 Segment Embedding을 추가합니다.
이를 통해 BERT는 토큰 단어의 정보만을 학습하는 것이 아닌 문장 단위의 정보도 학습을 합니다.
이 때문에 본 논문에서는 문장 단위의 정보가 중요한 자연어 요약 문제에서 BERT를 사용한 것입니다.
3. Fine-Tuning BERT for Summarization
3.1. Summarization Encoder(BERTSUM)
2절에서 말했듯 BERT는 Segment Embedding을 통해 문장 단위의 정보를 어느정도 포함하고 있지만 다음의 이유로 토큰 단위의 정보를 더 우세하게 학습 하게 됩니다.
-
Mask된 토큰을 예측하기 때문에 Output Vector는 문장 대신 토큰 단어 토큰에 대한 정보를 담음
이러한 이유로 문장에 대한 정보를 주더라도 토큰에 대한 정보를 훨씬 더 우세하게 학습하게 됩니다.
-
두개의 문장으로 이루어진 하나의 문장 쌍에 대해서만 적용되는 Segment Embedding
BERT는 하나의 문장 쌍에 대해서만 사전학습을 하게 됩니다. 하지만 실제 문서와 같은 장문의 글은 여러 문장 쌍으로 이루어져 있기 때문에 요약에서 큰 성능 향상을 기대하기는 어렵습니다.
그래서 본 논문의 저자들은 BERT 모델의 Encoder 구조를 다음과 같이 바꾸었습니다.
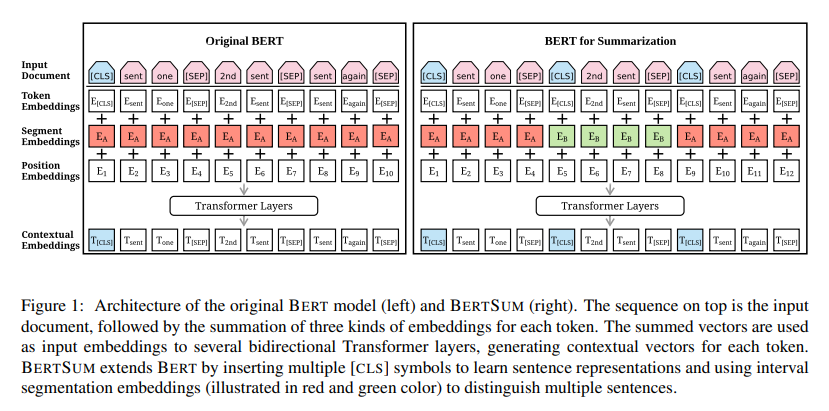
※ 원래 BERT는 하나의 문장 쌍에 대해서만 학습하게 되는데 Fig1의 왼쪽은 잘못된 사진 같습니다.
-
각 문장의 앞에 [CLS] 토큰을 삽입
[CLS] 토큰은 각 문장에 대한 정보를 담고 있는 토큰이 됩니다.
-
문서 내의 각 i번째 문장에 대해 번갈아가며(홀수, 짝수)에 따라 A, B 문장 정보 제공
문서가 으로 이루어 졌다면 임베딩 를 제공합니다.
-
긴 토큰을 가진 문서를 처리하기 위하여 입력 토큰 제한 수 변경
기본 BERT 모델은 토큰의 최대 길이가 512로 문서를 처리하기에는 너무 짧기 때문에 이를 해결하기 위하여 무작위로 초기화된 가중치를 Positional Encoding에 추가합니다.
이 과정을 통해 본 논문의 저자들은 문서에 대한 Representation을 계층적으로 학습한다고 합니다.
-
초기 레이어(Lower Layer) : 인접한 문장에 대한 정보
-
후기 레이어(Higher Layer) : 여러 문장에 대한 정보
3.2. Extractive Summarization(BERTSUMEXT)
이 절을 설명하기 위해 우선 단어에 대한 정의를 먼저 하겠습니다.
-
: 번 째 문장을 의미하며 는 1부터 시작
-
: 문서를 의미하며 를 포함
-
: 인코더 BERTSUM 에서 번째 [CLS] 토큰에 대응되는 출력 벡터
-
: 문장($t_{i})에 대한 정답 값으로 이 문장을 요약할 내용에 포함 여부에 대한 이진 분류 정답 값
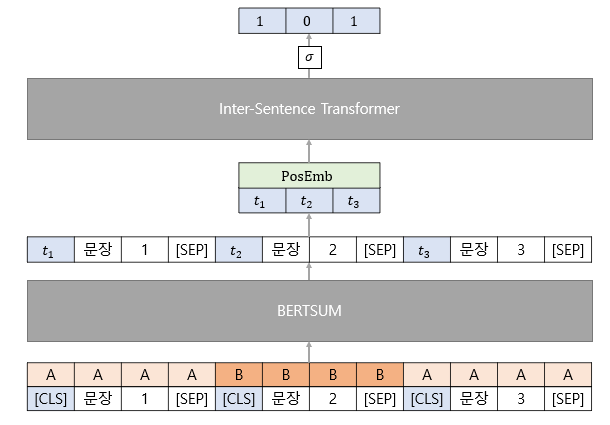
BERTSUMEXT는 BERTSUM의 출력 벡터에 Inter-Sentence Transformer 를 적용한 것과 같고, 다음과 같은 과정으로 작동합니다.
-
이전 절에서 말한 테이터 구조를 BERTSUM의 입력으로 합니다. ( [CLS] 토큰에 대한 위치 정보(인덱스)를 기억 )
-
BERTSUM의 출력 벡터들 중 [CLS] 토큰에 대응되는 벡터()들의 집합()를 만들어 줍니다.
-
에 대해서 Positional Embedding을 진행한 후 Transformer Encoder(BERTSUMEXT)에 입력으로 넣어줍니다.
-
최종적으로 각 출력에 대해 FC Layer를 적용하여 Sigmoid 함수를 적용하여 각 문장에 대한 이진 분류를 할 수 있도록 합니다.
실제 공식 GitHub에서 코드를 확인하면 다음과 같습니다.
-
PreSumm/src/models/model_builder.py
-
모델 학습 함수 "train_single_ext" 내부의 Model 부분
- class ExtSummarizer(nn.Module)
-
class ExtSummarizer(nn.Module):
def __init__(self, args, device, checkpoint):
# ...
self.ext_layer = ExtTransformerEncoder(self.bert.model.config.hidden_size,
args.ext_ff_size, args.ext_heads,args.ext_dropout, args.ext_layers)
# Inter-Sentence Transformer+ Sigmoid FC Layer 부분
# ...
def forward(self, src, segs, clss, mask_src, mask_cls):
top_vec = self.bert(src, segs, mask_src) # BERTSUM 부분의 출력 벡터들 != 집합 T
sents_vec = top_vec[torch.arange(top_vec.size(0)).unsqueeze(1), clss] # 출력 벡터들 중 [CLS] 토큰에 대응 되는 벡터들 == 집합 T
sents_vec = sents_vec * mask_cls[:, :, None].float()
sent_scores = self.ext_layer(sents_vec, mask_cls).squeeze(-1) # Inter-Sentence Transformer+ Sigmoid FC Layer
return sent_scores, mask_cls학습 파라미터는 다음과 같습니다.
-
Inter-Sentence Transformer의 레이어 수(Best) : 2
-
Optimizer : Adam ( )
-
Loss : Binary Cross Entropy (예측값, 정답값(Gold Label))
-
LR Scheduler : Warm-Up()
3.3. Abstractive Summarization(BERTSUMEXTABS)
추상 요약은 앞서 말했듯이 추출요약과 달리 자연어 요약 문제를 생성을 통해 문제를 해결하고자 합니다.
그래서 본 논문의 저자들은 기초적인 Transformer의 Encoder-Decoder 방식을 사용합니다.
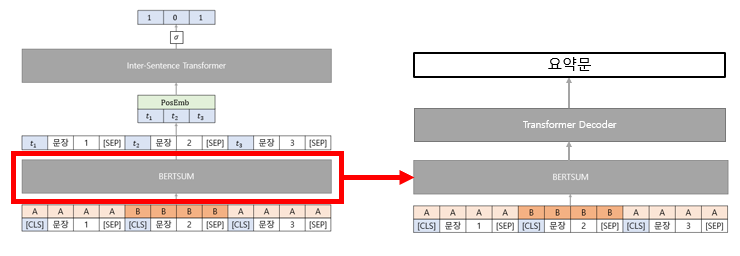
Encoder는 사전학습된 BERTSUM 가중치를 사용하며 Decoder는 무작위로 가중치를 초기화 합니다.
추출 요약 모델과 추상 요약 모델을 따로 학습하는 것이 아닌 순차적으로 추출 요약을 학습하고 추상 요약 모델을 학습하는 간단한 순서로 이루어집니다.
※ 추출 요약을 활용하는 것이 추상 요약의 성능을 더 크게 향상시킨다고 합니다.
이 과정에서 Encoder는 이미 사전학습 및 Fine-Tuning 된 상태이며 Decoder는 학습 초기 단계이기 때문에 같은 학습률(LR)로 학습을 진행하는 경우 다음과 같은 문제점이 발생합니다.
-
Encoder : 이미 최적화된 상태에서 더 학습이 되는 경우 과적합이 발생할 가능성이 높음
-
Decoder : Encoder의 과적합을 방지하고자 학습을 적게하면 과소적합이 발생할 가능성이 높음
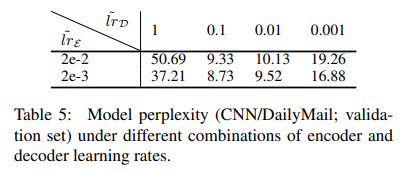
이를 해결하기 위해 Encoder와 Decoder 부분의 학습률을 아래와 같이 다르게 설정하여 Fine-Tuning을 진행합니다.
※ Decoder의 Layer수가 6인 점과 LR 부분을 제외하면 나머지 하이퍼 파라미터는 BERTSUMEXT와 동일
4. 마무리
본 논문은 요약 문제에 대해 직관적인 학습 방법을 사용하였고 복잡한 방법을 사용하지 않았다는 점이 인상 깊었던 거 같습니다.
특히 상대적으로 쉬운 추출 요약을 먼저 학습한 이후 더 어려운 문제인 추상 요약에 대해 학습하는 과정을 보며 Curriculum Learning(커리큘럼 학습)과 유사하다고 생각하였습니다.
Curriculum Learning : 상대적으로 쉬운 데이터에 대해 학습하도록 하여 좋은 성능을 낼 때 더 어려운 데이터로 학습하여 모델의 성능을 점진적으로 향상시키는 것으로 일반화 향상에 도움이 된다. - ChatGPT
자연어 요약 문제를 쉽게 생각했었지만 파면 팔 수록 더 어려운 문제인 거 같습니다...
