ConvNeXt 논문 리뷰
본 페이지에서는 A ConvNet for the 2020 논문에 대해서 말하고자 합니다.
이 글을 읽기 전에 ResNeXt와 Swin Transformer에 대한 내용을 확인하시고 읽으시면 더 이해가 쉬우실 겁니다.
1. Intro
당시 ViT계열 모델이 CNN보다 좋은 성능을 내면서 SOTA를 달성했습니다.
초기의 ViT는 분야에서는 패치 또는 이미지의 크기, 연산량 등의 이유로 Backbone으로 사용되지 못해 Object Detection, Segmentation 등의 분야에서 SOTA를 달성하는데 어려움이 있었습니다.
그러나 Sliding Window Attention, Cyclic Shift Window Attention 기법과 함께 계층적 구조의 ViT의 (Swin Transformer) 등장으로 기존의 CNN Backbone을 대체할 수 있게 되었고 성능 또한 좋았습니다.
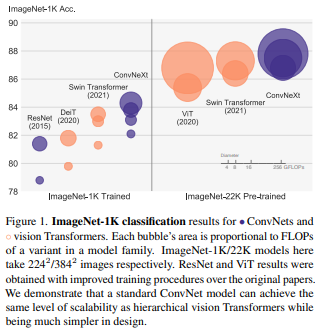
본 논문의 저자들은 Swin Transformer의 비교군으로 ResNet을 사용 했는데 두 모델은 비슷한 듯 다르며 성능이 차이가 나는 이유가 있다고 합니다.
위와 같이 말한 이유는 다음과 같습니다.
-
두 모델은 비슷한 Inductive Bias를 가진다는 점에서 비슷함.
-
학습 과정과 Macro/Micro 수준에서의 구조 디자인이 다름.
그래서 본 논문에서는 ViT의 구조 디자인을 참고하여 ResNet을 수정하며 성능에 대한 실험을 하고자 합니다.
본 논문의 방향성은 다음과 같다고 볼 수 있습니다.
Transformer의 디자인 결정이 ConvNet의 성능에 얼마나 영향을 미칠까?
2. 모델 구조 변경
본 절에서는 기존의 ResNet의 모델 구조 변경점과 이유에 대해서 말하고자 합니다.
저자들은 FLOPs를 기준으로 두가지의 비교 실험을 진행합니다.
-
ResNet-50 VS Swin-T : FLOPs가 거의 정도 됩니다.
-
ResNet-200 VS Swin-B : FLOPs가 거의 정도 됩니다.
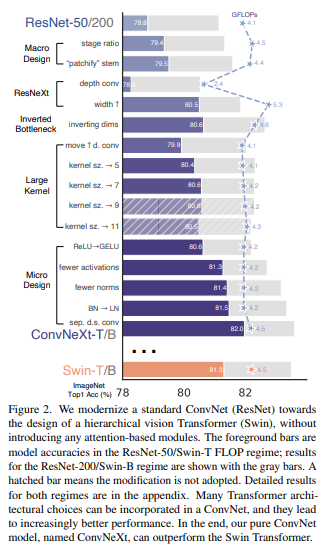
위의 표는 각 모델의 수정방향에 따른 성능과 FLOPs를 나타낸 표 입니다.
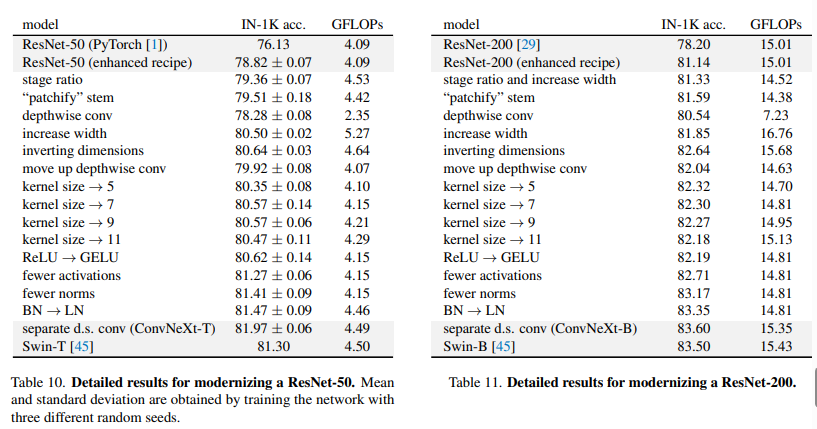
2.1 Training Techniques ( 76.1% -> 78.8% )
변경 이유
- ViT의 학습 방식에서 Optimizer, Hyper Paramater, Augmentation 등의 차이가 있습니다.
변경점
-
ViT와 동일하게 AdamW Optimizer를 사용
-
DeiT와 비슷한 Hyper Paramater 사용
-
Mixup, Cutmix, RandAugment 등의 Data Augmentation 사용
2.2 Macro Design ( 78.8% -> 79.5% )
Changing stage compute ratio ( 78.8% -> 79.4% )
변경 이유
- Swin-T 의 각 Stage의 블록 수의 비율은 1:1:3:1이고 ResNet의 경우는 3:4:6:3 임
변경점
- ResNet-50의 스테이지별 블록 수를 3,4,6,3 에서 3,3,9,3으로 바꾸어 비율을 1:1:3:1로 맞춤
Changing stem to “Patchify” ( 79.4% -> 79.5% )
변경 이유
- Swin Transformer에서 Patchify는 ResNet의 첫 Conv 레이어(Stem)과 비슷하다고 봄
변경점
- ResNet의 첫 Conv 레이어의 Kernel 크기와 Stride를 각각 ( 7 -> 4 ), ( 2 -> 4 )로 조정하여 Swin Transformer (패치 크기 = ) 와 비슷하게 함
2.3 ResNeXt-ify ( 79.5% -> 80.5%)
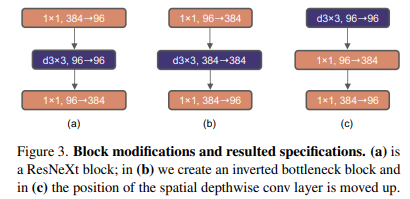
변경 이유
-
ResNeXt의 Group Convolution이 FLOPs를 크게 줄이면서 Accuracy는 최대한 유지할 수 있음
-
Depthwise Convolution이 Self-Attention 구조에서 가중합 연산과 비슷하다고 판단(한 차원의 내에서만 정보를 혼합함)
-
Depthwise Conv 이후 Conv가 DepthWise의 채널별 정보가 섞이도록 함
변경점
-
(a)처럼 Conv를 Depthwise Conv(그룹의 수와 채널의 수가 동일한 Group Conv) 로 대체
-
연산량의 감소로 채널의 너비를 증가시킴 ( 64 -> 96 )
2.4 Inverted Bottleneck ( 80.5% -> 80.6% )
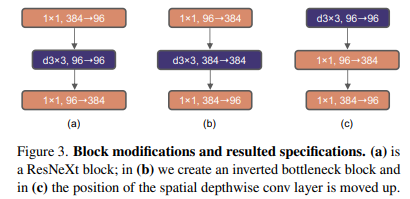
변경 이유
-
Transformer의 MLP 블록이 중간에서 채널을 4배로 늘렸다 줄이는 Inverted Bottleneck 구조를 사용
-
Inverted Bottleneck 구조를 사용하면 Shortcut Conv 레이어에서 채널의 수가 감소하기 때문에 전체 FLOPs가 오히려 줄어듦
변경점
- (b) 처럼 96 -> 384 -> 96으로 늘렸다 줄이는 형식으로 채널의 수를 조정
2.5 Large Kernel Sizes ( 80.6% -> 80.6% )
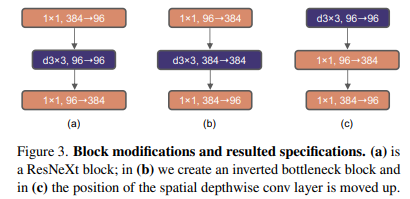
Moving up depthwise conv layer ( 80.6% -> 79.9% )
변경 이유
-
Transformer의 Self Attention은 각 블록 앞에 위치함
-
Self-Attention과 비슷한 특징을 가지는 ConvNeXt의 Depthwise Conv를 각 블록 앞에 위치하도록 변경
변경점
- (c) Depthwise Conv를 맨 앞에 위치하도록 함
성능 감소 이유
- Depthwise Conv가 맨 앞으로 오게 되면서 를 하는 채널의 수가 급감하게 됨
Increasing the kernel size ( 79.9% -> 80.6% )
변경 이유
-
Swin Transformer의 Window 크기는 임
-
Conv 의 Kernel 크기는 성능에 중요한 영향을 미침
변경점
- 크기의 Kernel을 크기로 변경 ( 3, 5, 7, 9, 11 ... 중 제일 좋은 성능을 보임 )
2.6 Micro Design (80.6% -> 82.0% )
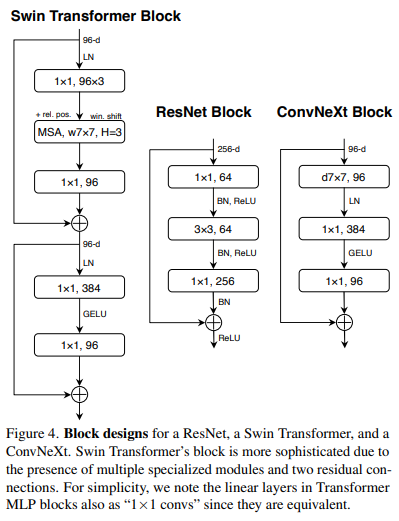
Replacing ReLU with GELU (80.6% -> 80.6%)
변경 이유
- Swin Transformer은 ReLU 대신 GELU를 사용함
변경점
- 비선형 함수를 ReLU 대신 GELU를 사용함
Fewer normalization layers ( 80.6% -> 81.3% )
변경 이유
- Transformer에서 비선형 함수는 MLP에 존재하는데 MLP내에 비선형 함수는 하나만 존재함
변경점
- 두 Conv 사이에만 비선형 변환 GELU 사용
Substituting BN with LN ( 81.3% -> 81.4%)
변경 이유
- Transformer에서는 주로 Layer Normalization을 사용함
변경점
- Batch Normalization을 Layer Normalization으로 변경
Separate downsampling layers ( 81.4% -> 82.0% )
변경 이유
- Swin Transformer는 다음 계층으로 갈 때 인접한 윈도우를 하나로 뭉치며 이를 CNN에서는 Downsampling 레이어라고 판단
변경점
- ConvNeXt의 Downsampling 레이어에서 Conv를 로 변경함
3. 최종 모델 구조
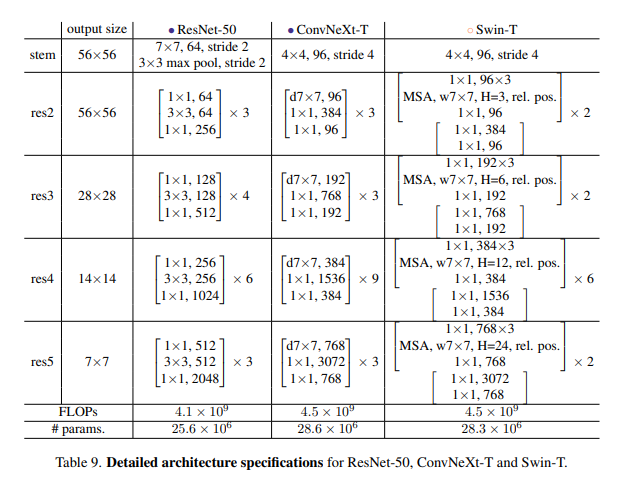
- ConvNeXt-T: C = (96, 192, 384, 768), B = (3, 3, 9, 3)
- ConvNeXt-S: C = (96, 192, 384, 768), B = (3, 3, 27, 3)
- ConvNeXt-B: C = (128, 256, 512, 1024), B = (3, 3, 27, 3)
- ConvNeXt-L: C = (192, 384, 768, 1536), B = (3, 3, 27, 3)
- ConvNeXt-XL: C = (256, 512, 1024, 2048), B = (3, 3, 27, 3)
최종적으로 Swin-T의 성능인 81.3%를 능가하는 82.0%의 성능을 달성하였습니다.
실험했던 모델 구조들은 이미 ConvNet에 대한 이전의 연구들에서 나온 것입니다.
단지 적절히 조합하여 순수한 ConvNet의 구조를 통해 당시의 ViT 모델들보다 좋은 성능을 냈다는 점에서 의의가 있는 논문인 것 같습니다.
