본 페이지에서는 Aggregated Residual Transformations for Deep Neural Networks 논문에 대해서 말하고자 합니다.
1. Intro
당시 CNN 모델들은 구조가 복잡해지고 조정해야할 하이퍼 파라미터가 많아지게 되었습니다.
VGGNet과 ResNet 모델은 비슷한 레이어를 쌓기만 하면 되는 간단한 구조를 가지면서 발전하였습니다. (좌측)
반대로 Inception 계열 모델들은 Split-Transform-Merge 구조를 가진 레이어를 쌓았습니다. (우측)
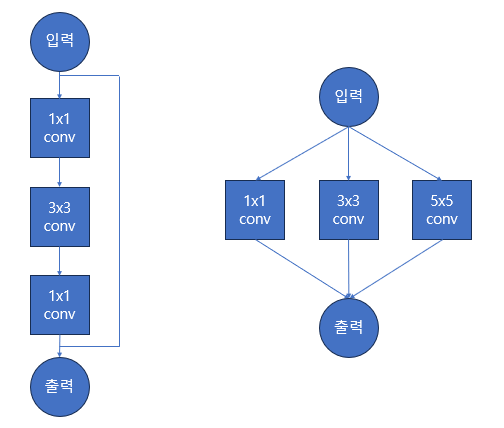
이에따라 새로운 Task에서 모델의 성능을 높이기 위해 하이퍼 파라미터를 새로 조정해야하는 번거로움이 발생했습니다.
이에 ResNeXt는 다음 두가지의 기준을 가지고 모델 구조를 고안합니다.
-
동일한 사이즈의 Spatial Map들을 만들 때 각 블록은 동일한 하이퍼 파라미터(너비,채널 수 등)를 공유한다.
-
Spatial Map들의 크기가 두배로 작아질 때 각 블록의 너비는 2배가 된다.
이런 기준으로 만들어진 ResNeXt는 다음의 특징을 가집니다.
-
VGGNet, ResNet과 비슷한 간단한 구조
-
Group Convolution 기법 사용
-
ResNet보다 상대적으로 적은 연산량과 파라미터 수
특히 본 논문은 ResNeXt의 구조를 가지면 모델의 깊이보다 너비가 더 중요하다는 것을 보여줍니다.
2. Group Convolution 이란?
ResNeXt에서는 기존 ResNet과는 다르게 Group Convolution을 사용합니다.
Group Convolution은 블록의 채널들을 개의 그룹으로 나누어 각 그룹별 Convolution을 진행합니다.
만약 입력 채널이 개라면 각 그룹당 채널은 개가 됩니다. (이 때 입니다.)
2.1 Group Convolution
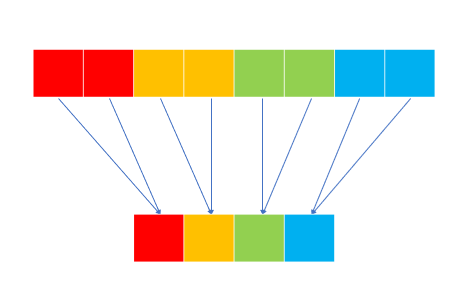
위의 사진은 Group Convolution 연산 과정이며 하나의 채널을 만들기 위해 한 그룹에서의 모든 채널을 사용합니다.
이때 입력 채널의 수는 8 그룹의 수는 4 이므로 각 그룹당 채널 수는 2가 됩니다.
일반적으로 출력 채널의 수는 그룹의 수로 나누어 떨어져야 합니다.
이 Group의 수를 잘 조절하면 Original Convolution과 Depthwise Convolution 모두 구현할 수 있습니다.
2.2 Original Convolution
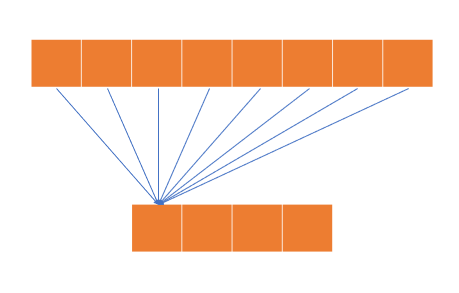
위의 사진은 기존의 Convolution 연산 과정이며 하나의 채널을 만들기 위해 입력 블록의 모든 채널을 사용합니다.
이때 입력 채널의 수는 8 그룹의 수는 1로 각 그룹당 채널 수는 8이 됩니다.
2.3 Depthwise Convolution
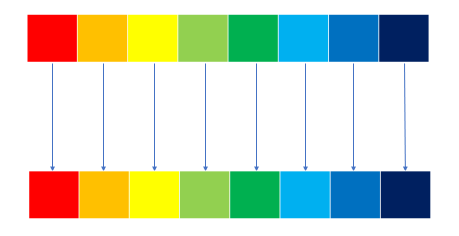
위의 사진은 Depthwise Convolution 연산 과정이며 하나의 채널을 만들기 위해 한 그룹에서의 하나의 채널을 사용합니다.
이때 입력 채널의 수는 8 그룹의 수는 8로 각 그룹당 채널 수는 1이 됩니다.
3 Bottleneck Layer
ResNet과 ResNeXt의 Bottleneck 레이어를 그림으로 표현하면 다음과 같습니다.
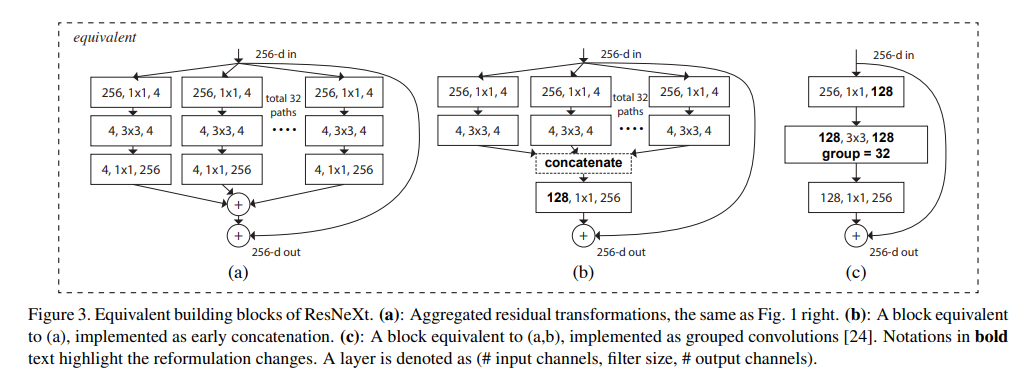
각 (a), (b), (c)에 대해 작동방식을 설명하겠습니다.
3.1 Method (a)
-
처음 256개의 채널에 대해 Conv연산을 32번 진행하여 각각 4개의 채널로 만듭니다. (총 채널)
-
32개의 그룹의 각 4개의 채널에 대해 Conv연산을 진행하여 동일하게 각각 4개의 채널로 만듭니다.
-
32개의 그룹의 각 4개의 채널에 대해 Conv연산을 진행하여 동일하게 각각 256개의 채널로 만듭니다.
-
이후 32개의 그룹의 각 256개의 채널을 더합니다.
3.2 Method (b)
Inception-ResNet Module과 비슷한 방식으로 마지막 Conv 연산 대신 Concatenate 연산을 만저 하고 Conv을 적용하는 방식입니다.
-
처음 256개의 채널에 대해 Conv연산을 32번 진행하여 각각 4개의 채널로 만듭니다. (총 채널)
-
32개의 그룹의 각 4개의 채널에 대해 Conv연산을 진행하여 동일하게 각각 4개의 채널로 만듭니다.
-
32개의 그룹을 Concatenate 연산을 진행하여 개의 채널로 만들어줍니다.
-
128개의 채널에 대해 Conv를 진행하여 256개의 채널로 만들어줍니다.
3.3 Method (c)
Group Convolution 방식을 사용한 방식입니다.
-
처음 256개의 채널에 대해 Conv연산을 진행하여 128개의 채널로 만들어 줍니다.
-
128개의 채널에 대해 32개의 그룹으로 Conv를 진행하여 128개의 채널로 만들어줍니다.
-
128개의 채널에 대해 Conv를 진행하여 256개의 채널로 만들어줍니다.
4. Model Architecture
모델의 전체구조를 표로 표현하면 다음과 같습니다.
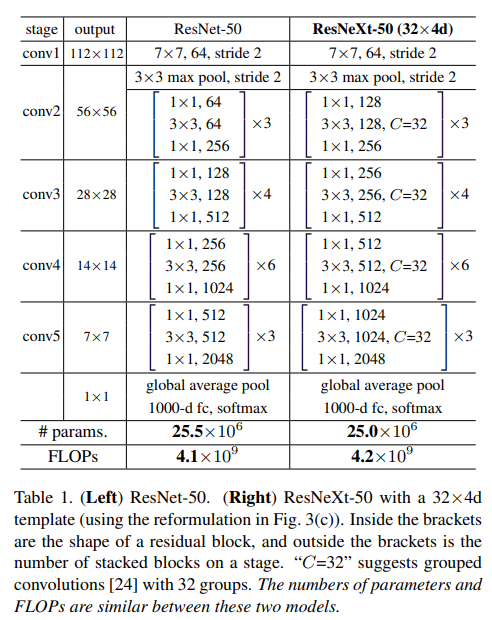
여기서 는 Cardinality로 그룹의 수이고 하이퍼 파라미터입니다.
위 구조에서 주목할 점은 ResNeXt의 Bottleneck 레이어의 채널 수가 ResNet에 비해 두배가 늘어났음에도 파라미터의 수가 오히려 줄었다는 것입니다.
이는 Group Convonlution의 특징 때문에 그렇습니다.
입력 채널의 수를 Kernel의 크기를 출력 채널의 수를 이라고 할 때 파라미터의 수는 다음과 같습니다.
기존 Convolution 연산
Group Convolution 연산 (Group의 수 )
이 때문에 채널의 너비는 더 넓어졌지만 파라미터의 수는 오히려 감소하게 됩니다.
5. Experiments
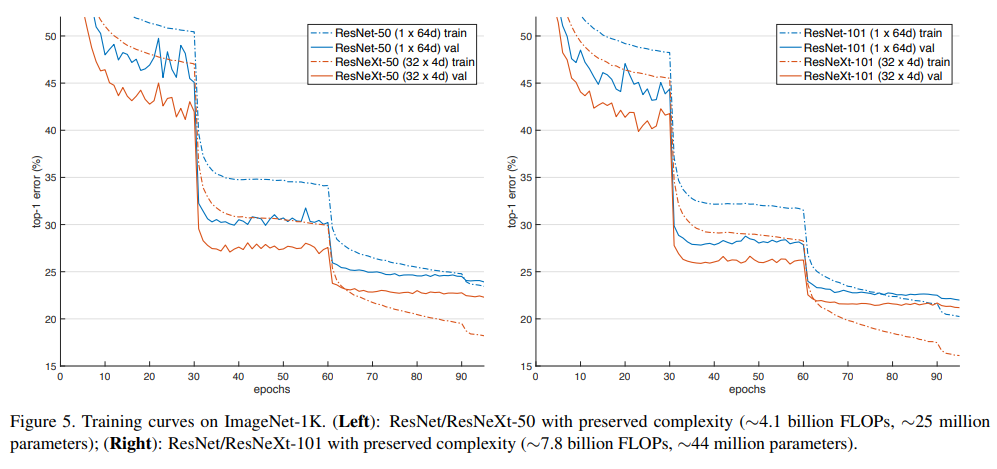
위의 그래프는 ResNet과 ResNext의 동일한 깊이별성능 비교이며 ResNext가 성능이 더 좋은 것을 알 수 있습니다.
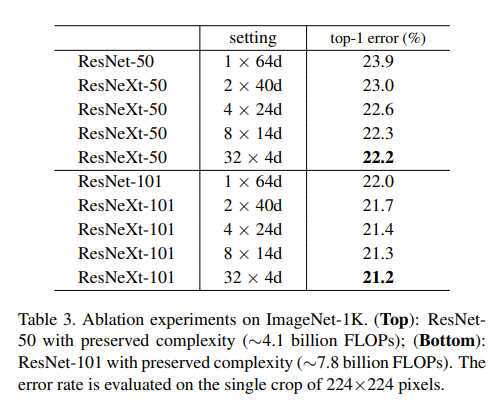
위의 표는 동일한 깊이별 그룹의 수에 따른 성능 비교이며 그룹이 증가할 수록 성능이 좋아집니다.
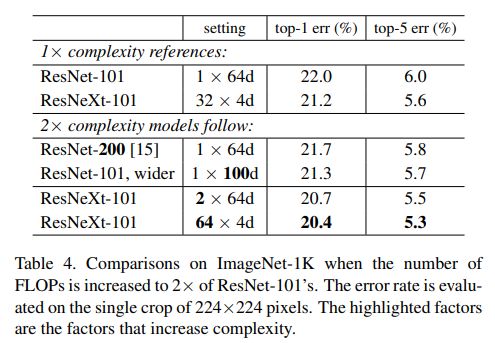
최종적으로 위의 표는 본 논문에서 말하고자 하는 실험결과를 담고 있습니다.
성능면에서 ResNet-200 < ResNet-101,wider < ResNeXt-101 의 순서를 보이고 있다는 것을 통해 모델의 깊이보다 넓은 것 그리고 그룹의 수가 많은 것이 더 좋다는 것을 보여주고 있습니다.
6. 코드구현
import keras
def conv(input,chennel,kernel_sizes,strides=2,padding='valid',groups=1,is_relu=True,is_bn=True):
x = input
x = keras.layers.Conv2D(chennel,kernel_sizes,strides,padding=padding,groups=groups)(x)
if is_bn:
x = keras.layers.BatchNormalization()(x)
if is_relu:
x = keras.activations.relu(x)
return x
def resnext50():
inputs = keras.Input(shape=[224,224,3])
x= inputs
initial_features=64
groups = 32
x = conv(x,initial_features,7,2,'same')
x = keras.layers.MaxPool2D(3,2,'same')(x)
repeat = [3,4,6,3]
for i in range(4):
for j in range(repeat[i]):
shortcut = x
strides = 1
if j==0:
if i != 0:
strides = 2
shortcut = conv(shortcut,initial_features*2**(i+2),1,strides,'same',False)
x = conv(x,initial_features*2**(i+1),1,strides,'same')
x = conv(x,initial_features*2**(i+1),3,1,'same',groups)
x = conv(x,initial_features*2**(i+2),1,1,'same',False)
x = keras.layers.add([x,shortcut])
x = keras.activations.relu(x)
x = keras.layers.GlobalAvgPool2D()(x)
x = keras.layers.Dense(1000)(x)
x = keras.activations.softmax(x)
return keras.Model(inputs=[inputs], outputs=[x], name=f'ResNeXt50')
model = resnext50()
model.summary()PyTorch
import torch.nn as nn
from torchsummary import summary
class bottleneck_block(nn.Module):
def __init__(self,i,o,s,e,stage,g):
super(bottleneck_block,self).__init__()
self.conv1 = nn.Conv2d(i,o,1,s)
self.bn1 = nn.BatchNorm2d(o)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(o,o,3,1,1,groups=g)
self.bn2 = nn.BatchNorm2d(o)
self.conv3 = nn.Conv2d(o,o*e,1,1)
self.bn3 = nn.BatchNorm2d(o*e)
if s == 2 or i < o:
self.identity = nn.Sequential(
nn.Conv2d(i,o*e,1,s),
nn.BatchNorm2d(o*e)
)
else :
self.identity = nn.Sequential()
def forward(self,x):
identity = self.identity(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNeXt50(nn.Module):
def __init__(self,e=2,num_layers=[3,4,6,3],g=32):
super(ResNeXt50,self).__init__()
def n_blocks(i,o,s,stage):
layers = []
layers.append(bottleneck_block(i,o,s,e,stage,g))
for _ in range(1,num_layers[stage]):
layers.append(bottleneck_block(o*e,o,1,e,stage,g))
return nn.Sequential(*layers)
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,7,2,3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(3,2,1)
)
self.stage1 = n_blocks(64,128,1,0)
self.stage2 = n_blocks(128*e,256,2,1)
self.stage3 = n_blocks(256*e,512,2,2)
self.stage4 = n_blocks(512*e,1024,2,3)
self.F = nn.AdaptiveAvgPool2d(1)
self.FC = nn.Sequential(
nn.Linear(1024*e,1000)
)
def forward(self,x):
out = self.conv1(x)
out = self.stage1(out)
out = self.stage2(out)
out = self.stage3(out)
out = self.stage4(out)
out = self.F(out)
out = out.view(out.size(0),-1)
out = self.FC(out)
return out
summary(ResNeXt50(),(3,224,224))
