Masked AutoEncoder(MAE) 논문 리뷰
본 페이지에서는 Masked Autoencoders Are Scalable Vision Learners 논문에 대해서 말하고자 합니다.
1. Intro
본 논문은 ViT 모델을 Self-Supervision을 하는 MAE(Masked Auto Encoder) 방법에 대해 발표를 합니다.
기존의 Deep Learning은 적은 양의 데이터셋으로 학습 시키기에 과적합되곤 합니다.
더 많은 데이터셋이 필요하지만 라벨링하기엔 시간과 비용이 듭니다.
이런 점을 NLP에서 GPT, BERT 등에서 Self-Supervied Pre-Training으로 라벨링 없이 학습을 할 수 있게 되었고 많은 학습을 통해 데이터셋 부족의 문제를 해결했습니다.
본 논문은 BERT의 사전 학습 방법인 Masked Auto Enconding 방법에 초점을 두며 다음의 질문을 합니다.
무엇이 Computer Vision 분야와 Natural Language Process 분야의 Masked Auto Encoding 방법이 달라지게 했을까?
이에 대한 답은 다음과 같습니다.
-
근본적으로 다른 구조 : 기존에 CV 분야에서는 CNN구조를 주로 사용하고 NLP 분야에서는 Transformer를 사용하여 구조적 차이가 있었지만 최근 ViT가 발표 되면서 이는 해결되었다.
-
정보 밀도의 차이 : 가려진 단어의 예측은 언어에 대한 이해를 하면 예측할 수 있지만 가려진 패치는 장면,객체 등 여러 정보에 대한 이해를 통해 예측을 해야 하기에 더욱 복잡합니다. 이를 해결하기 위해 가려지는 패치 수의 비율을 매우 높게 하였습니다.
-
원본을 출력해야하는 Decoder : 원본 단어를 예측하는 것은 쉽지만, 원본 패치를 예측하는 것은 쉽지 않습니다.
위의 분석을 통해 MAE를 다음의 특징을 갖도록 연구하였다고 합니다.
-
비대칭적 Encoder-Decoder 구조 사용
-
Masking 되지 않은 패치만을 사용하는 Encoder(Masking Token은 Decoder로)
-
경량화된 Decoder를 통한 원본 이미지 예측
-
전체 이미지 중 75%의 패치를 Masking
-
3배 이상 빠른 학습 속도
2. Approach
이 절에서는 MAE의 구조에 대해서 설명하겠습니다.
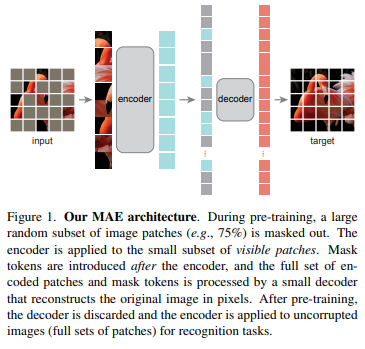
MAE는 다음과 같은 순서로 작동합니다.
-
Patchfy + Linear Projection + Positional Embedding : 기존의 ViT와 동일하게 이미지를 여러 패치로 나누어 토큰으로 다룹니다.
-
Random Shuffle : Token들을 무작위로 섞은 다음에 전체 패치의 일부만을 남깁니다.
-
Transformer Encoder : 가려지지 않은 토큰들만을 Transformer Encoder에 넣어줍니다.
-
Append Mask Token : Encoder 결과에 원래 이미지의 패치수와 동일하도록 동일한 Mask Token을 넣고 원래 Token 순서에 맞게 정렬해줍니다.
-
Transformer Decoder : Positional Embedding을 더하여 Transformer Decoder에 넣어줍니다.
-
Reconstruct : Decoder의 결과를 활용해 원본 이미지와 동일하도록 만들어줍니다.
2.1 Masking (Random Sampling)
이미지를 나눈 패치들을 정규 분포에 따라 무작위로 원하는 비율만큼 버립니다.
이때 MAE 기법은 높은 비율로 패치를 버리게 되는데 이 때문에 이미지 원본을 예측하기 쉽지는 않지만 그만큼 모델에게 정확한 특징을 학습시킬 수 있는 장점이 있습니다.
또한 정규분포를 통해 무작위로 패치를 버리기 때문에 중앙의 이미지가 더 많이 버려지게 되며 전체적으로 남은 패치의 위치가 중앙으로 편향되는 현상이 줄어듭니다.
2.2 MAE Encoder
기존의 AutoEncoder들은 Masking된 부분을 버리지 않고 Mask 토큰으로 대체하여 패치 전체를 입력으로 넣었지만 MAE는 Masking되지 않은 패치만을 입력으로 넣습니다.
이 때문에 학습 중에 사용되는 Computational Cost가 현저히 줄었습니다.
2.3 MAE Decoder
MAE Decoder는 Encoder의 출력 토큰들과 Mask 토큰을 사용하는 또다른 Transformer Block들 입니다.
원래 패치의 수만큼 Encoder의 출력 결과에 Mask 토큰을 Append 하며 원래의 위치에 맞게 순서를 정렬시켜줍니다.
이때 각각의 Mask 토큰은 학습가능한 동일한 토큰입니다.
이후 모든 토큰에 대해 Positional Embedding들을 더해줍니다.
MAE Decoder는 사전 학습 중에만 사용하며 Fine-Tuning 과정에서는 다른 Decoder로 대체합니다.
또한 Decoder는 경량화 되어있기 때문에 Encoder에 피해 토큰 당 Computational Cost가 10% 더 작습니다.
2.4 Reconstruct Target
Decoder의 각 출력은 각 패치에 대응되는 벡터입니다.
Decoder의 마지막 부분에 Linear Projection을 하여 패치 내의 픽셀 수로 출력 채널을 맞춰줍니다.
이후 Reshape 연산을 통해 원본 이미지 크기에 맞게 재구성하고 Normalization 합니다.
최종적으로 원본이미지와 Mask된 패치에 해당하는 부분과의 MSE Loss를 통해 손실 값을 구합니다.
3 ImageNet Experimnets

본 절에서는 실험에 따른 성능 차이와 그에 대한 이유를 설명하겠습니다.
3.1 Main Properties
Masking Ratio
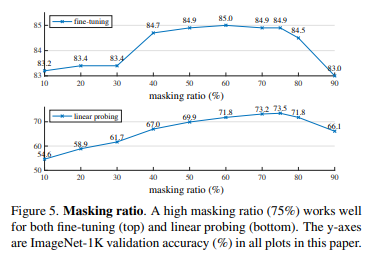
위의 표는 Masking Ratio에 따른 Fine-Tuning 성능과 Linear Probing을 보여줍니다.
기존의 논문들은 Masking Ratio가 높은 경우 오히려 성능이 떨어지는 결과가 있었지만 MAE 방법에서는 Masking Ratio가 75%일 때가 가장 최적인 상태를 보입니다.
논문 저자들은 이 이유를 많은 부분을 Masking 하였을 때 효율적인 Representation을 학습 하도록 한다고 합니다.
Decoder Design
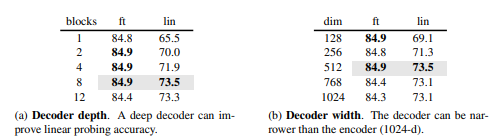
위의 표를 보면 Linear Probing의 성능은 Decoder의 깊이가 깊어질 수록 증가하는 양상을 보입니다.
그러나 Fine-Tuning에서는 큰 의미가 없고 놀라운 점은 Decoder의 깊이가 1임에도 좋은 성능을 보인다는 점입니다.
Decoder의 Width(채널의 수)의 성능 차이는 크게 보이지 않으며 원래보다 더 적은 채널인 512일 때가 가장 적절한 성능을 내며 이를 Baseline으로 잡는다고 합니다.
Mask Token
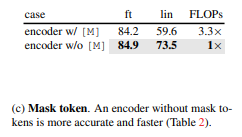
MAE 구조의 중요한 점은 Encoder 부분에서는 Mask 토큰을 없앴다는 것이고 후에 Decoder에 적용했다는 점입니다.
Mask 토큰을 Encoder에서 사용하는 경우 Linear Probing 성능이 오히려 14% 감소하였습니다.
이 이유에 논문 저자들은 실제 이미지에 많지 않을 Mask 토큰이 Encoder에 너무 많이 들어온 것이 이유라고 합니다.
이 Mask 토큰을 Encoder에서 제거하고 Encoder는 실제 이미지 패치만을 보도록 하였고 이에 따라 성능이 향상됐다고 합니다.
또한 Mask 토큰을 없앰으로 서 Computational Cost가 많이 감소하였고 75% 부분을 Masking 하면 4배 이상으로 속도를 향상시킬 수 있다고 합니다.
이 때문에 MAE는 대형 모델 사전학습에 적합하다고 합니다.
Reconstruction target
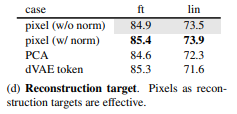
정규화된 픽셀을 사용하여 원본이미지를 구성하는 것은 성능 향상에 도움이 된다고 합니다.
다른 기법으로 Patch Space에서 PCA기법을 사용하는 것이 있는데 96과 같은 높은 Coefficinets를 사용할 경우 성능이 감소했다고 합니다.
이외에도 DALLE의 사전 학습된 dVAE를 Tokenizer로 사용하였고 Loss로 CE Loss를 사용하였다 이는 성능 향상이 0.4%정도 일어났지만 Normalization한 결과와는 큰 차이도 없고 이점도 없었습니다. (이 외에도 추가적인 사전학습 필요 등의 문제로 고려하지 않아도 될 사항 같습니다.)
Data Augmentation
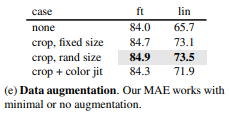
MAE에서는 Crop만을 사용할 때 성능이 좋다고 합니다.
하지만 Color Jittering을 추가해서 사용하는 경우에는 오히려 성능이 감소했다고 합니다.
놀라운 점은 어떤 Augmentation을 적용하지 않을 때에도 오히려 성능이 좋았다고합니다.
이런 특성은 Contrastive 학습 방법과 큰 차이를 보입니다.
이 이유를 본 저자들은 MAE에서는 Random Masking이 이미 데이터 증강의 역할을 한다고 합니다.
Mask sampling strategy

Masking 하는 여러 방법에 대한 실험을 진행해봤다고 합니다.

Block-Wise Masking의 경우 큰 블록을 제거하는 경향이 있습니다.(Fig6의 중간)
이 방법의 경우 Masking 하는 비율이 50%인 경우에는 성능이 괜찮은 수준이었지만 75%가 되는 경우 오히려 성능이 감소할 뿐 아니라 Loss또한 증가했다고 합니다.
Grid-Wise Sampling의 경우에는 인접한 4개의 패치 중 하나의 패치를 남기는 방식입니다.(Fig6의 우측)
이 경우 낮은 Training Loss를 갖기도 하고 학습하기에도 쉽지만 Representation 질이 너무 안좋다고 합니다.
MAE에서는 간단한 Random Sampling이 제일 좋다고 하며 높은 Masking Ratio를 사용해도 성능이 좋고 속도 향상과 좋은 정확성을 얻을 수 있다는 점이 있다.
Training Schedule
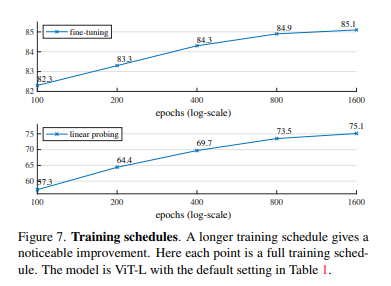
800 Epoch을 사전 학습 하는 중에 성능 향상은 꾸준히 발생했고 Linear Probing 또한 1600 Epoch동안 Saturation 되는 현상이 없었다고 합니다.
반대로 Contrastive Learning 방법은 300 Epoch에 Saturation 되었다고 합니다.
3.2 Comparisons with Previous Results
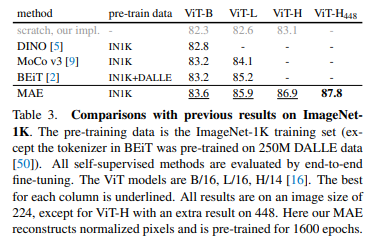
기존의 방법과 비교하였을 때 MAE 기존의 방법들보다 좋은 성능을 냅니다.
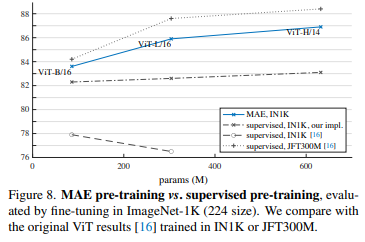
기존의 ViT Paper에서는 IN1K 데이터로 ViT-L을 사전학습하는 경우에 성능이 감소되는 것을 확인했지만 MAE 방법에서는 더 잘 Generalizae 되며 JFT-300M 사전학습과 비슷한 양상을 보입니다.
이를 통해 MAE 방법은 큰 모델을 사전학습 시키기에 적합하다고 합니다.
4. 코드구현
논문의 공식 코드를 참고해 구현했습니다.
PyTorch
class MHA(nn.Module):
def __init__(self,d_model,num_head):
super(MHA,self).__init__()
d_k = d_model//num_head
d_v = d_model//num_head
self.h = num_head
self.d_k = d_k
self.d_v = d_v
self.q_linear = nn.Linear(d_model,d_k*num_head)
self.k_linear = nn.Linear(d_model,d_k*num_head)
self.v_linear = nn.Linear(d_model,d_v*num_head)
self.MHA_linear = nn.Linear(d_v*num_head,d_model)
def forward(self,x):
q = self.q_linear(x).view(x.size(0),x.size(1),self.h,self.d_k).transpose(1,2) #B,N,num_head*d_k -> B,N,num_head,d_k -> B,num_head,N,d_k
k = self.k_linear(x).view(x.size(0),x.size(1),self.h,self.d_k).transpose(1,2)
v = self.v_linear(x).view(x.size(0),x.size(1),self.h,self.d_v).transpose(1,2)
matmul1 = torch.einsum("...nd,...kd->...nk",q,k)
softmax = torch.softmax(matmul1/np.sqrt(self.d_k),-1)
matmul2 = torch.einsum("...nd,...dk->...nk",softmax,v)
concat = matmul2.transpose(1,2)
concat = concat.reshape(concat.size(0),concat.size(1),self.h*self.d_v)
out = self.MHA_linear(concat)
return out
class Transformer_Block(nn.Module):
def __init__(self,d_model,num_head,expansion=4):
super(Transformer_Block,self).__init__()
d_k = d_model//num_head
d_v = d_model//num_head
self.MHA = MHA(d_model,num_head)
self.MLP = nn.Sequential(
nn.Linear(d_model,d_model*expansion),
nn.ReLU(),
nn.Linear(d_model*expansion,d_model)
)
self.ln = nn.LayerNorm(d_model)
class Encoder(nn.Module):
def __init__(self,d_ff,d_model,d_k,d_v,num_head):
super(Encoder,self).__init__()
self.MHA = MHA(d_model,d_k,d_v,num_head)
self.MLP = nn.Sequential(
nn.Linear(d_model,d_ff),
nn.ReLU(),
nn.Linear(d_ff,d_model)
)
self.ln = nn.LayerNorm(d_model)
def forward(self,x):
out_MHA = self.ln(x)
out_MHA = self.MHA(out_MHA)
out_MHA += x
out_MLP = self.ln(out_MHA)
out_MLP = self.MLP(out_MLP)
out_MLP += out_MHA
return out_MLP
class MAE(nn.Module):
def __init__(self,height,width,num_encoder,num_decoder,in_channels,patch_size,d_encoder,d_decoder,num_head,expansion=4,masking_ratio=0.75):
super(MAE,self).__init__()
self.c = in_channels
self.p = patch_size
self.h = height
self.w = width
self.hp = height//patch_size
self.wp = width//patch_size
self.ratio = masking_ratio
layers_encoder = []
self.encoder_positional_encoding = nn.Parameter(torch.zeros((height*width)//(patch_size**2),d_encoder))
self.encoder_embedding = nn.Linear(in_channels*patch_size**2,d_encoder)
for i in range(num_encoder):
layers_encoder.append(Transformer_Block(d_encoder,num_head))
self.Encoder_Blocks = nn.Sequential(*layers_encoder)
self.Encoder_norm = nn.LayerNorm(d_encoder)
self.Decoder_norm = nn.LayerNorm(d_decoder)
self.decoder_embedding = nn.Linear(d_encoder,d_decoder)
layers_decoder = []
for i in range(num_decoder):
layers_decoder.append(Transformer_Block(d_decoder,num_head))
self.Decoder_Blocks = nn.Sequential(*layers_decoder)
self.mask_token = nn.Parameter(torch.zeros(1,1,d_decoder))
self.decoder_positional_encoding = nn.Parameter(torch.zeros((height*width)//(patch_size**2),d_decoder))
self.decoder_linear = nn.Linear(d_decoder,in_channels*(patch_size**2))
def patchify(self,x):
out = img.reshape(-1,self.c,self.h//self.p,self.p,self.w//self.p,self.p) # b,c,h//p,p,w//p,p
out = out.permute(0,2,4,1,3,5) # b, h//p,w//p,c,p,p
out = out.reshape(-1,self.n,self.c*self.p*self.p) # b,n,cpp
return out
def random_masking(self,x,ratio=0.75):
b,n,c = x.shape
noise = torch.randn((b,n))
ratio = int(n*(1-ratio))
idx_visible = torch.argsort(noise,-1).to(device)
idx_recover = torch.argsort(idx_visible,-1).to(device)
selected_visible = idx_visible[:,:ratio]
masked_patchs = torch.gather(x,1,selected_visible.unsqueeze(-1).repeat(1,1,c))
mask_infor = torch.ones((b,n)).to(device)
mask_infor[:,:ratio] = 0
mask_infor = torch.gather(mask_infor,1,idx_recover)
return masked_patchs, mask_infor, idx_recover
def Encoder(self,x):
out = self.patchfy(x)
out = self.encoder_embedding(out)
out += self.encoder_positional_encoding
masked_patchs, mask_infor, idx_recover = self.random_masking(out)
out_encoder = self.Encoder_Blocks(masked_patchs)
out_encoder = self.Encoder_norm(out_encoder)
return out_encoder, mask_infor, idx_recover
def Decoder(self,x,idx_recover):
b,n = idx_recover.shape
x = self.decoder_embedding(x)
mask_tokens = self.mask_token.repeat(b,n-x.shape[1]+1,1)
in_block = torch.cat([x,mask_tokens],1)
in_block = torch.gather(in_block,1,idx_recover.unsqueeze(-1).repeat(1,1,x.shape[2]))
in_block += self.decoder_positional_encoding
out_decoder = self.Decoder_Blocks(in_block)
out_decoder = self.Decoder_norm(out_decoder)
out_decoder = self.decoder_linear(out_decoder)
return out_decoder
def get_loss(self,original,output,mask_infor):
target = self.patchfy(original)
'''mean = torch.mean(target,-1,keepdim=True)
var = torch.var(target,-1,keepdim=True)
target = (target-mean)/(var+1e-5)'''
loss = (output-target)**2
loss = torch.mean(loss,-1)
loss = (loss*mask_infor).sum() / mask_infor.sum()
return loss
def forward(self,x):
out_encoder, mask_infor, idx_recover = self.Encoder(x)
out = self.Decoder(out_encoder,idx_recover)
loss = self.get_loss(x,out,mask_infor)
return loss, out, mask_infor