본 페이지에서는 SegFormer: Simple and Efficient Design for Semantic
Segmentation with Transformers 논문에 대해서 말하고자 합니다.
1. Intro
본 논문은 ViT계열의 Segmentation 모델인 SegFormer 모델을 발표를 합니다.
기존 Segmentation 모델들은 FCN을 이어 여러 CNN을 활용한 Segmentation 모델들이 발전 해왔습니다.
과거에 Segmentation은 주로 두 방법에 의해 연구가 되었습니다.
-
특징을 잘 추출하기 위한 Encoder 모델 즉, Backbone 모델을 개선하여 성능을 향상시키는 방법
-
이미지 내의 문맥 정보를 효율적으로 추출하기 위한 모듈과 연산을 추가하여 성능을 향상시키는 방법
이후 ViT의 등장으로 ViT를 Segmentation에 활용하고자 ViT를 Encoder에 CNN을 Decoder에 사용하는 방식으로 좋은 성능을 내는 SETR의 등장이 있었지만 다음과 같은 문제가 있었습니다.
- ViT는 CNN과 달리 하나의 저해상도 특징들만을 사용한다.
CNN은 Convolution 연산과 Pooling 연산을 통해 이미지의 여러 해상도를 사용하는 것과 달리 ViT는 고정된 크기의 해상도만들 사용하는 것을 말합니다.
- 이미지 크기에 따라 크게 증가하는 연산량
ViT는 동일한 패치크기를 사용할 때 이미지의 크기가 커지면 패치가 그만큼 늘어나게 되고 모든 패치들과의 유사도를 계산하는 Self-Attention의 특성상 연산량이 제곱배로 늘어나게 된다.
이를 해결하기 위해 여러 PVT, Swin Transformer, Twins 등 여러 방법론들이 등장했지만 주로 Encoder에 대한 것을 다룰 뿐 Decoder는 전혀 다루지 않았습니다.

SegFormer의 주요 특징은 다음과 같습니다.
-
계층적 구조의 Transformer Encoder를 사용하여 다양한 Scale의 특징들을 활용할 수 있다고 합니다.
-
Positional Encoding을 사용하지 않았고 이에 따라 학습 때 사용한 데이터의 이미지의 해상도와 다른 크기의 이미지를 사용한다고 하여도 성능감소가 크지 않았습니다.
-
간단한 구조의 Decoder를 사용하며 Encoder의 여러 계층에서 얻어낸 특징들을 통합하여 사용하였고 이로 인해 Global한 문맥정보와 Local한 정보를 모두 잘 활용할 수 있다고 합니다.
2. SegFormer
SegFormer는 다음과 같은 특징을 가집니다.
-
계층적 구조의 Encoder : 고해상도의 Coarse 특징들과 저해상도의 Fine-Grained 특징들을 추출합니다. 특히 Positional Embedding을 사용하지 않았고 이에 따라 추론시 다른 크기의 이미지를 사용해도 성능이 크게 감소하지 않습니다.
-
경량화된 Decoder : 더 적은 연산량을 가지며 Encoder에서 얻어낸 모든 특징들을 모두 활용해 최종 출력을 얻어냅니다.
구조에 대한 그림은 다음과 같습니다.
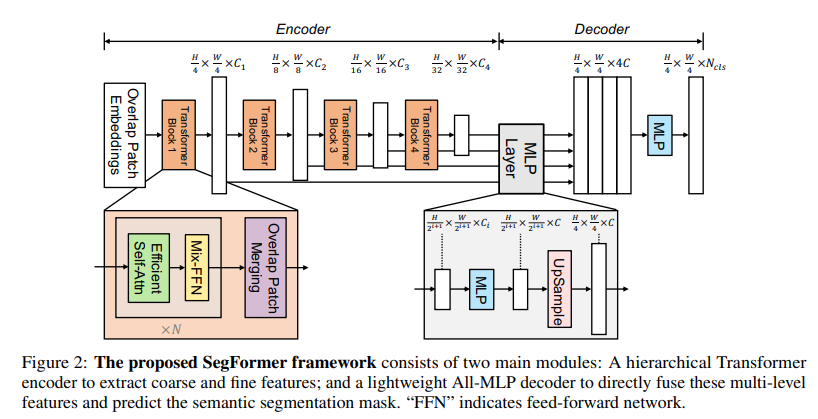
간략한 구조 설명은 다음과 같습니다.
-
입력이미지에 대해 크기의 패치로 나눕니다.
-
계층적 구조의 Encoder에 넣어 원본 이미지 크기의 {1/4, 1/8, 1/16, 1/32}의 특징맵을 얻어냅니다.
-
Encoder에서 얻어낸 모든 특징맵을 활용해 Decoder를 통해 최종 결과를 출력합니다
2.1 Hierarchical Transformer Encoder
본 논문에서 Transformer Encoder의 이름을 Mix Transformer(MiT)라고 지었습니다.
MiT의 주요 특징을 자세히 설명하면 다음과 같습니다.
Hierarchical Feature Representation
ViT의 구조는 다음과 같습니다.
각 격자는 하나의 Patch라고 가정합니다.
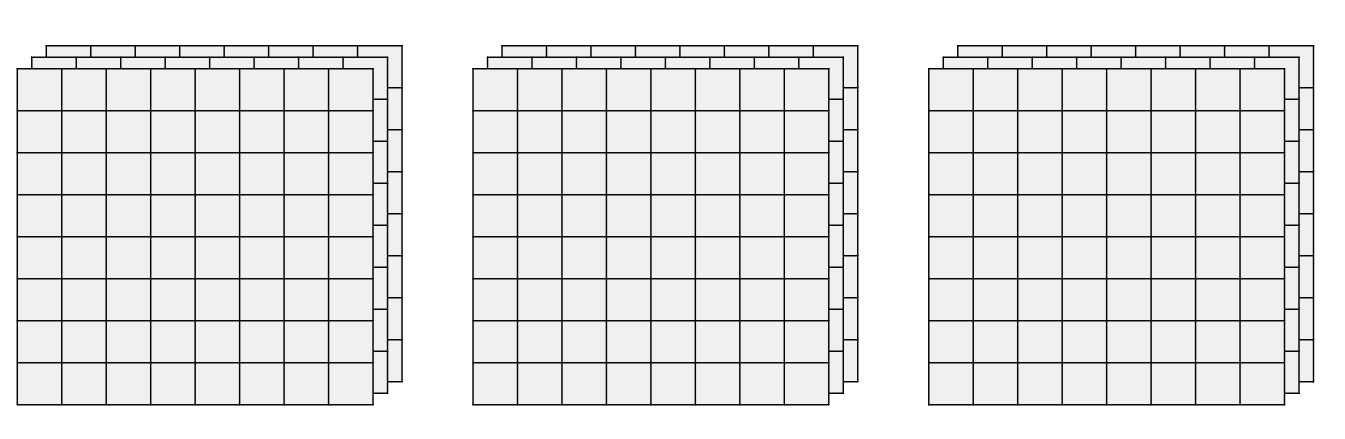
동일한 수의 Patch를 토대로 연산을 진행하며 Patch의 수가 변하지 않습니다.
MiT의 구조는 다음과 같습니다.
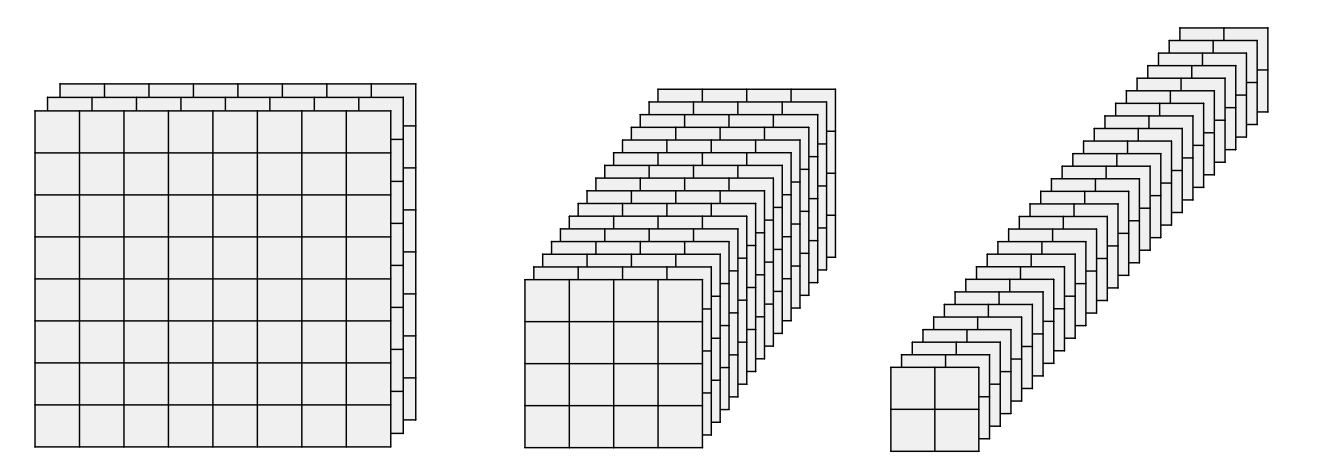
이 구조는 CNN과 유사한 형태로 고해상도의 Coarse한 특징들과 저해상도의 Fine-Grained 특징들을 얻어 Segmentation에서 더욱 좋은 성능을 낼 수 있다고 합니다.
Overlapped Patch Merging
기존의 ViT 계열의 모델들에서 사용되던 Patch Merging은 인접한 Patch들을 붙이는 방법으로만 작동 됐습니다.
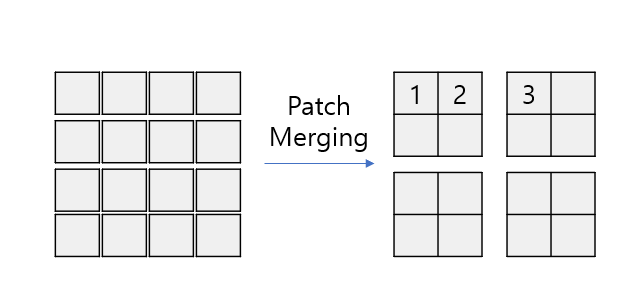
이러한 구조 때문에 다른 부분으로 병합된 다른 패치와의 정보는 단절되게 됩니다.
이를 해결하기 위해 Overlapped Patch Merging을 고안하여 다른 패치와의 정보를 교환할 수 있도록 합니다.
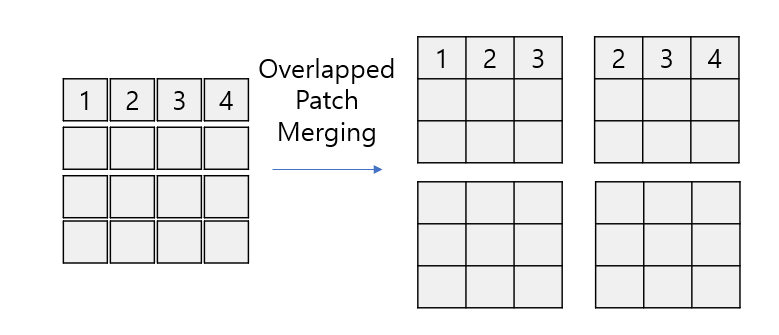
위와 같이 왼쪽 위의 패치에서는 1, 2, 3번 패치 오른쪽 위에서는 2, 3, 4번 패치와 각각 Self-Attention을 진행하기 때문에 정보가 단절되지 않습니다.
Conv 연산과 비슷하게 Kernel Size(K), Stride(S), Padding(P)를 정의하여 비슷한 원리로 Patch를 병합합니다.
논문에서 사용한 (K, S, P) 는 각각 (7, 4, 3) , (3, 2, 1) 입니다.
Efficient Self-Attention
Encoder의 연산에서 병목이 되는 주요한 원인 중 하나는 Self-Attention 레이어의 연산량 입니다.
Atention 연산은 다음과 같은 수식으로 이루어집니다.
이 때 패치의 수가 이라면 시간 복잡도는 이 됩니다.
따라서 이를 해결하기 위해 본 논문에서는 Reduction Ratio 을 사용하여 시간 복잡도를 줄이고자 합니다.
그 과정은 다음과 같습니다.
이로 인해 Attention 연산의 시간 복잡도는 에서 로 줄어듭니다.
본 논문에서 은 stage-1 ~ stage-4에서 각각 [64, 16, 4, 1]로 설정됩니다.
Mix-FFN
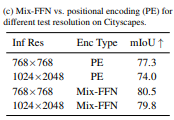
기존의 ViT는 Positional Encoding을 사용하여 각 패치에 위치정보를 제공하였습니다.
이 방식은 결국 모델에 다른 해상도의 이미지가 들어올 경우 성능이 크게 감소되는 결과를 야기합니다.
본 논문에서는 이를 해결하기 위해 Mix-FFN을 소개합니다.
Mix-FFN은 지역 정보를 유출하는 Zero Padding의 영향을 고려하여 기존의 Feed Foward Network에 직접적으로 Conv연산을 적용합니다.
변경된 FFN의 식은 다음과 같습니다.
본 논문에서는 Conv 연산으로 인해 Positional Encoding을 충분히 대체할 수 있다고 합니다.
또한 Depth-Wise Conv를 사용하였고 이로 인해 파라미터의 수를 줄이고 효율성을 증가시켰다고 합니다.
2.2 Lightweight All-MLP Decoder
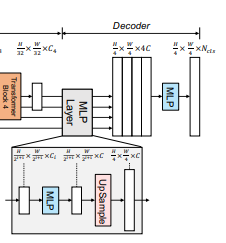
기존의 방법론들과는 다르게 SegFormer는 Decoder 부분에도 변화를 주었습니다.
SegFormer는 매우 경량화된 Decoder를 사용함에도 좋은 성능을 내게 됩니다.
이 이유는 계층적 구조의 Transformer Encoder가 CNN보다 넓은 Effective Recpetive Field(ERF)를 가지고 있기 때문이라고 합니다.
Decoder의 수식은 다음과 같습니다.
이때 는 각 Encoder의 출력이며 는 각 Encoder의 채널 수입니다.
Effective Receptive Field Analysis
Semantic Segmentation에서 넓은 Receptive Field를 가지면서 문맥 정보를 파악하는 것은 가장 큰 문제였습니다.
본 논문은 Receptive Field에 대해서 시각화를 하였는데 다음과 같습니다.

DeepLab V3+ 모델과 SegFormer의 ERF를 시각화한 것입니다.
Deeplab V3+의 ERF를 살펴보면 Stage-4가 될때 까지 SegFormer보다 상대적으로 작습니다.
SegFormer의 Receptive Field 특징은 빈 부분이 없이 골고루 인식하며 이로 인해 Encoder만으로도 Global Context 또한 잘 인식할 수 있다는 점이 장점입니다.
결국 CNN Encoder의 제한된 Receptive Field로 인해 ASPP와 같은 무거운 모듈을 사용해야 비어있는 Receptive Field를 반영하여 문맥 정보를 잘 파악할 수 있습니다.
하지만 SegFormer는 MiT Encoder의 골고루 퍼진 Receptive Field 때문에 간단한 Decoder 하나만으로도 넓은 Receptive Field를 가진다고 합니다.
2.3 Relationship to SETR
이 부분은 SegFormer와 SETR의 차이점과 장점을 얘기합니다.
-
SETR과는 달리 더 작은 Imagenet-1K로 사전학습을 하였습니다.
-
SegFormer의 Encoder는 계층적 구조를 가지고 있기 때문에 고해상도의 Coarse한 특징과 저해상도의 Fine한 특징을 잘 얻을 수 있습니다.
-
Positional Embedding을 사용하지 않았고 이에 따라 추론시 다른 크기의 이미지를 사용해도 성능이 크게 감소하지 않습니다.
-
가벼운 Decoder의 사용으로 더 적은 연산량을 가집니다.
3. Model Architecture
실험 내용들
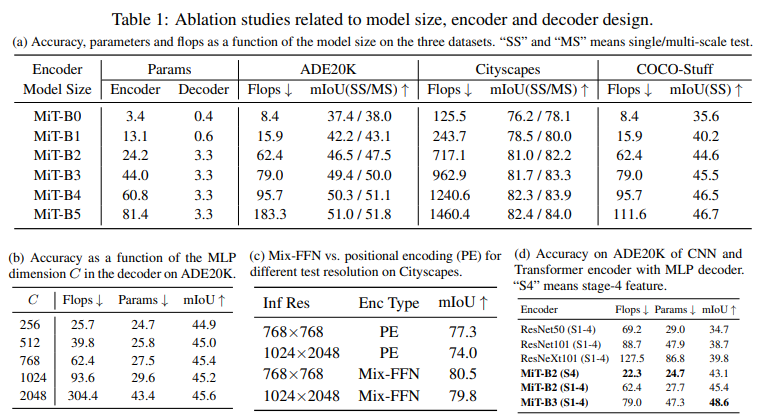
다른 모델들과의 성능 비교
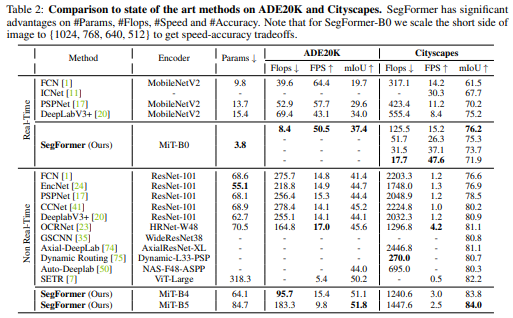
Encoder 크기에 따른 하이퍼 파라미터
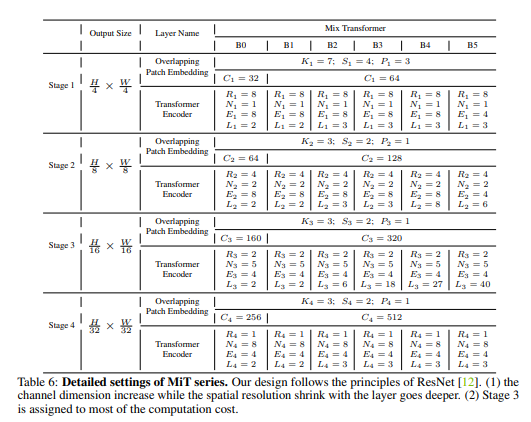
4. 마무리
Segmemtation 분야에서 그동안의 ViT 계열의 모델들과는 달리 Decoder 구조에도 신경을 쓴 점과 Positional Encoding을 없앤 점이 인상 깊은 논문 입니다.
대부분의 실험 내용에 대해서는 잘 나와있지만 Self Attention에서 하이퍼 파라미터 에 대한 실험 결과가 없는 것이 조금 아쉬운 거 같습니다.
그럼에도 Transformer를 사용하면서도 CNN계열보다 더 나은 FPS와 더 나은 성능을 제공한다는 점이 크게 매력으로 다가오는 것 같습니다.
