Sequence to Sequence 논문 리뷰
본 페이지에서는 Sequence to Sequence의 등장배경과 특징에 대해서 말하고자 합니다.
1. Intro
기존의 Deep Neural Network은 좋은 성능을 보이고 있다.
비록 DNN이 많은 Labeling된 데이터 셋을 사용하는 경우에 잘 학습되고는 하지만 Sequence로부터 sequence로 mapping은 잘 하지 못한다.
DNN은 고정된 차원의 입출력에서만 작동하기 때문에 연속형 데이터에서는 잘 작동하지 못하는 것이다.
이러한 문제를 LSTM의 구조를 통해 해결하였고 실제로 좋은 성능을 보여준다.
본 논문에서는 sequence 구조에서 minimal한 assumption을 가능하게 하는 sequnece learning에 일반적인 end to end 방식을 보여준다.
본 논문에서는 LSTM(Long Short Term Memory) 구조를 다음과 같이 활용했다.(다중 레이어 LSTM과 deep LSTM은 같습니다.)
1. deep LSTM을 이용해 입력 sequence를 고정된 차원의 vector로 mapping 한다.(입력 LSTM이라고 한다.)
2. 또 다른 deep LSTM을 이용해 vector로부터 목표 sequence로 decode한다.(출력 LSTM이라고 한다.)
3. 기존의 LSTM 구조에서 레이어를 더 추가하여 4개의 레이어로 만들었고 이를 Deep LSTM이라고 한다. 또한 레이어를 추가하면서 성능을 향상 시켰다.
4. 입력 문장의 순서를 바꾸어 가며(출력 단어의 순서는 변경하지 않음) 학습을 하여 성능을 향상 시켰다.2. RNN and LSTM
Sequence to Sequence를 설명하기 위해 RNN과 LSTM의 특징을 먼저 설명하겠습니다.
2.1 RNN(Recurrent Neural Network)
RNN은 순환 신경망이라고도 하며 주로 순서에 따라 의미나 결과가 달라지는 연속형 데이터를 처리하고자 하는 네트워크 입니다.
이러한 특성 때문에 주로 자연어 처리에 자주 사용되는 네트워크 입니다.
간단한 구조를 살펴보면 다음과 같습니다.
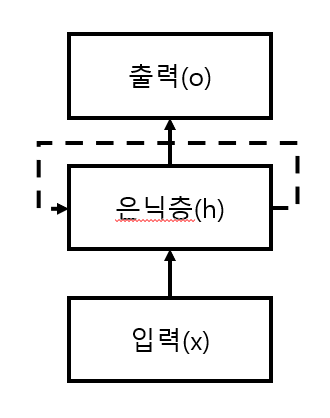
기존의 네트워크는 은닉층의 정보를 가공해서 출력층으로 전달해 출력을 내는게 끝이었지만 RNN의 경우는 은닉층의 정보를 다시 재활용하는 구조를 가지게 되었습니다.
이를 연속형 데이터에 맞게 구조화 해서 보이면 다음과 같습니다.
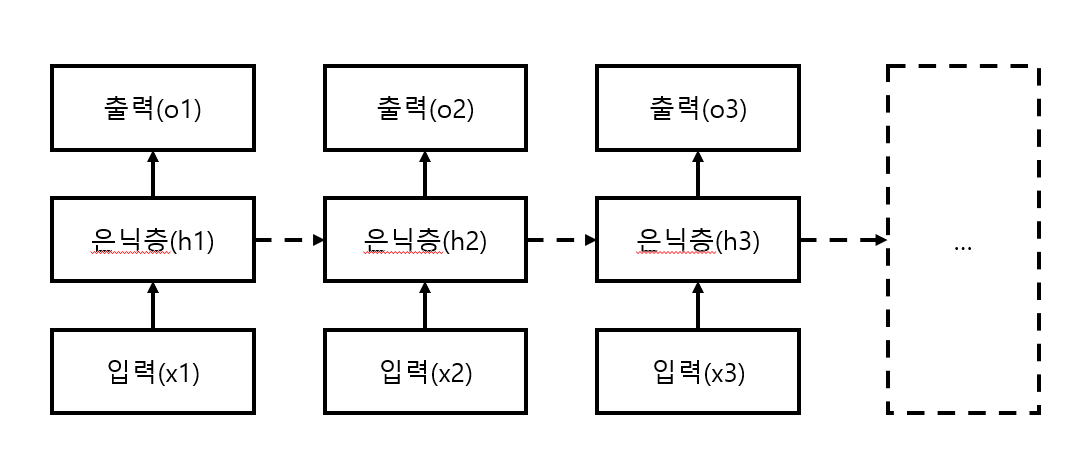
이전 은닉층의 정보를 다음 입력과 함께 은닉층에 넣어주어 출력을 내는 과정을 거치게 됩니다. 이때 은닉층의 정보는 다음 은닉층으로 넘겨주게 됩니다.
이러한 네트워크의 구조 때문에 RNN 이라는 이름이 붙게 되었습니다.
네트워크 한 시점의 은닉층 내부를 살펴보면 다음과 같습니다.
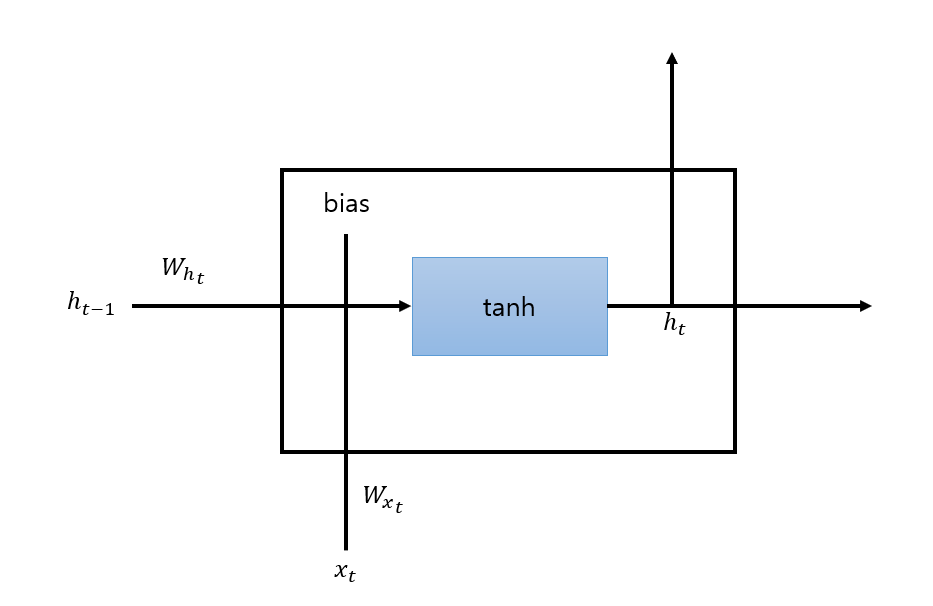
이를 수식으로 전개하면 다음과 같습니다.
네트워크의 구조 자체는 매우 간단하고 네트워크의 특성상 이전 입력에 대한 결과가 다음 상태로 전달 되기 때문에 이전에 상태 또한 현재 상태에 영향을 미친다는 장점이 있습니다.
하지만 네트워크가 길어지게 된다면 back propagtation 과정에서 연속된 tanh 활성 함수 때문에 gradient가 소실(vanishing)되는 경우와 폭발(exploding) 발생하게 되고 학습이 잘 되지 않을 수 있게 됩니다.
이러한 이유 때문에 장문에서 RNN의 성능이 안좋아지게 된다.
이를 개선하고자 한 구조가 아래의 LSTM 구조 입니다.
2.2 LSTM(Long Short Term Memory)
RNN은 실제로 문장에 대해서 학습할 때 문장이 길어지면 이전에 말했던 이유로 학습이 잘 되지 않는다.
LSTM은 기존의 RNN의 구조에서 은닉층에 있는 구조를 다음과 같이 변경했다.
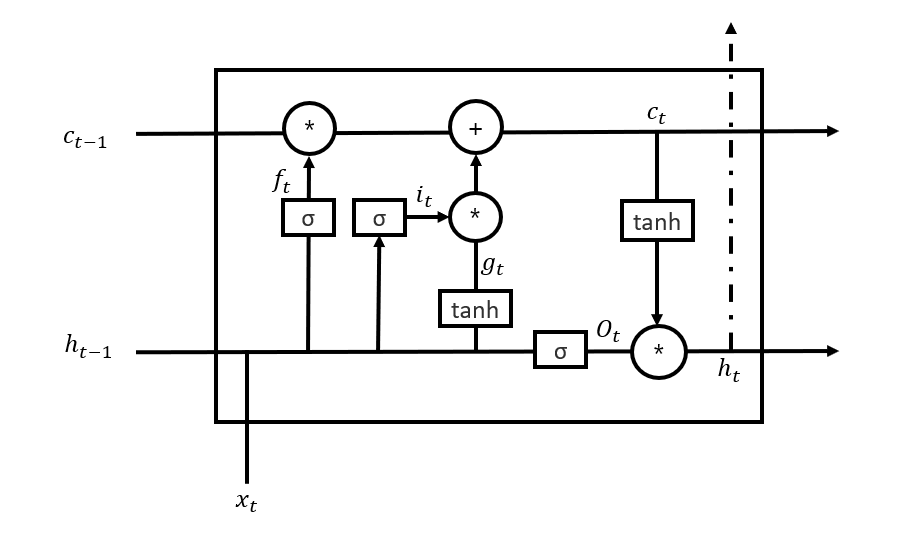
그림에 대해서 설명하면 σ는 sigmoid를 의미하고 tanh는 기존과 같이 하이퍼볼릭 탄젠트를 의미하고 +와 *는 픽셀별 더하기와 곱하기를 의미한다. 다른 이외의 것들은 아래를 보면 된다.
$x_{t}$ : 입력
기존의 RNN과 동일한 입력
$h_{t}$ : Hidden state
기존의 RNN과 은닉층의 정보
$c_{t}$ : Cell state
최종적으로 필터링된 정보(필터링이라고 한 이유는 지금 상태에서 이전의 정보들을 얼마나 사용할지 결정하고 새로 만든 정보를 얼마나 활용할지를 결정하고 이를 활용하기 때문이다.)
$f_{t}$ : Forget gate
이전 정보와 현재 정보를 활용해 전체 정보를 얼마나 활용할지 결정
$g_{t}$ : Memory cell
기존의 RNN의 $h_{t}$ 에 해당하는 부분 (새로운 정보 생성)
$i_{t}$ : 입력 gate
이전 정보와 현재 정보를 활용해 새로운 정보를 얼마나 저장할지 결정
$O_{t}$ : 출력 gate
이전 정보와 현재 정보를 활용해 최종 결과( $c_{t}$ )가 얼마나 다음 은닉층이나 출력으로 이어질지 결정이때 LSTM의 f,i,o,g에서 에 곱해지는 가중치는 각각 다르다.
본 구조에서 Cell state가 제일 중요한데 Cell state로 인해서 gradient 소실과 폭발 문제를 해결하고 이전 정보를 얼마나 활용할지를 필터링 할 수 있다.
3. Sequence to Sequence
위의 LSTM 구조의 특성 때문에 본 논문에서는 LSTM을 활용하여 가변적인 문장에서도 잘 작동하고 기존의 자연어 처리 모델들과는 다르게 장문에서도 잘 작동하였다.
그 이유는 LSTM은 다양한 길이의 입력 문장을 고정된 차원의 표현 벡터로 mapping하는 것을 배운다는 것은 LSTM의 특성 때문이다.
또한 LSTM은 단어 순서에 민감하고 무언가에 상대적으로(?) 불변하는 문장과 단어 표현에 민감하게 학습한다.
또한 문장의 순서를 뒤집어 LSTM의 성능을 많이 향상시켰다.
Sequence to Sequence의 작동과정을 이미지로 표시하면 다음과 같다.
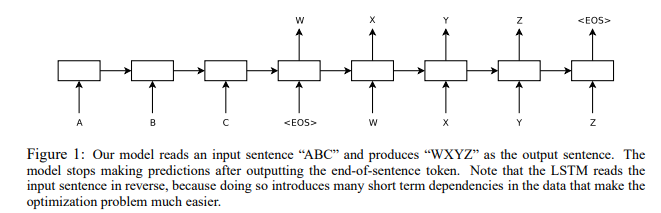
입력 문장이 ABC라고 하고 이에 대한 출력이 WXYZ라고 한다면 EOS(End Of Sentence)를 출력하여 끝낸다.
특히 본 논문에서 말하는 LSTM은 기존에도 여러 연구가 있었지만 기존과는 다르게 장문에서도 잘 작동했다. 그 이유는 입력 문장의 순서를 뒤집고 출력(라벨) 문장의 순서는 뒤집지 않고 학습을 하였기 때문이다.
이렇게 하면서 단기 의존 문제를 해결했고 이에 따라 optimization 문제를 더 간단하게 만들어주었다.
이때 LSTM이 출력단어를 선택하는 과정은 주어진 입력 x1,x2,...,xT 에 대한 y1,y2,...,yT'의 조건부 확률을 계산하는 것이다.
입력 LSTM
이를 수식으로 나타내면 다음과 같다.
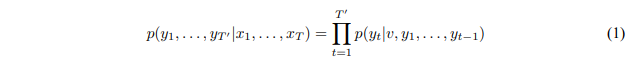
이때 v는 입력 Sequence들이 입력 LSTM을 지나 생성된 고정된 차원의 표현 벡터이다.
위 식에서 p(yt|v,y1,...,yt-1)는 사전에 있는 단어 전체에 대한 softmax 분포이다.
이때 학습 하는 과정은 다음과 같은데
학습 데이터셋에서 원본 문장을 S, 정확한 번역 문장 T라고 할 때 주어진 S문장에 대해서 T가 나올 확률을 극대화 하는 방향으로 학습을 한다.
그래서 목적 함수는 다음과 같다.
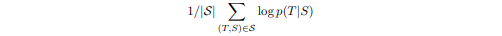
이후 학습을 종료하게 되면 LSTM에 입력 문장 S에 대해서 번역될 문장 T 중에서 확률이 제일 높은 문장을 선택해 출력하게 된다. 이를 수식으로 나타내면 다음과 같다.
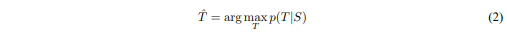
작은 수의 B개의 partial hypotheses(몇몇의 번역에서 접두사를 말한다.)만을 유지하는 간단한 left-to-right beam search decoder 방법을 사용해 번역을 하였다.
기존에는 각각의 time step 마다 partial hypotheses를 연장했는데 이는 hypotheses의 수를 증가시키게 된다. 그래서 모델의 log 확률에 따라서 B개의 hypotheses만 남기고 나머지는 버렸다.
\<EOS>가 htpotheses에 붙여지면 더 이상 hypotheses를 붙이지 않는다.
이러한 방법은 본 논문에서 제안한 구조에서 잘 작동하는데 beam size가 1~2에서도 잘 작동하였다. 이는 아래에 테이블을 보면 확인 할 수 있다.
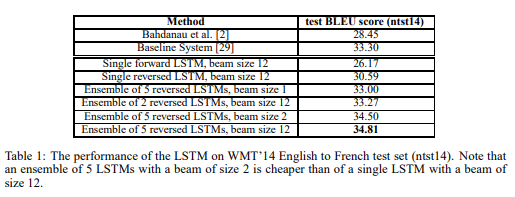
이 방법 외에도 계속 언급했듯이 입력 단어의 순서를 바꾸면서도 성능을 향상시켰다.
논문에서는 이 이유를 완전히 설명할 수는 없다고 한다.
대신 데이터셋의 단기 의존 문제에 의해서 발생했다고 믿는다.
원천 문장에서 각각의 단어는 목표 문장에서 대응되는 단어와 멀다.
예를들면 "너를 내가 사랑한다."라는 입력 문장을 번역하면 "I love you."가 된다.
이 두 문장을 붙여보면 "너를 내가 사랑한다. I love you."가 되고 대응되는 단어인 너와 you 자체의 거리는 멀어지게 된다.
이를 그림으로 보이면 다음과 같다.
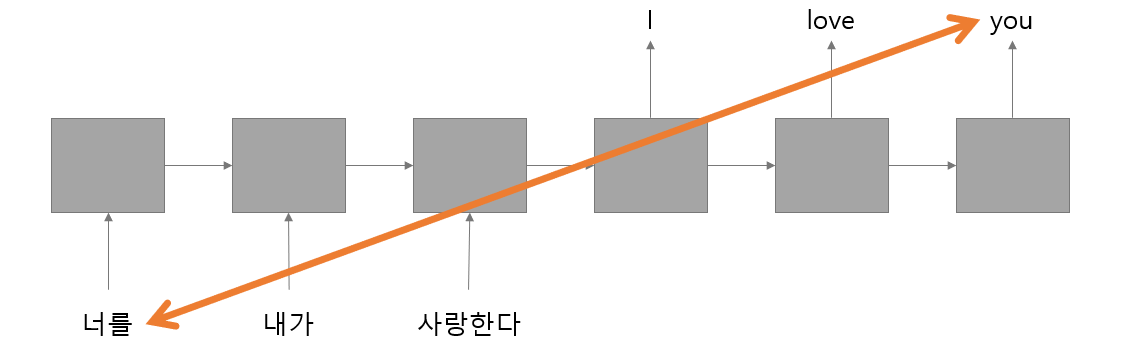
RNN과 LSTM의 특성상 입력이 오래 반복될 경우 초기 입력 상태는 점점 잊혀지게 되는데 위의 두 문장을 보게되면 "너"라는 단어가 점점 잊혀져 "you"라는 단어로 번역되기가 힘들어질 것이다.
이를 해결하는 방법으로 입력 문장의 순서를 다음과 같이 바꾸는 것이다.
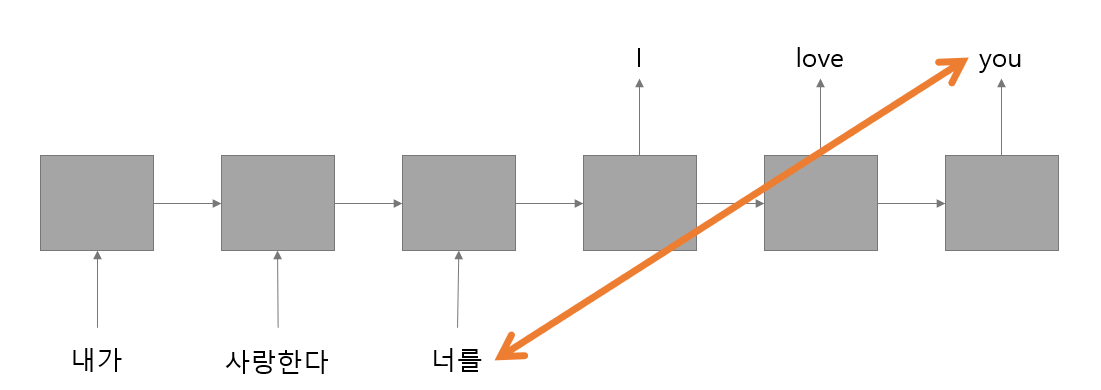
문장의 의미는 크게 변하지는 않지만 "너를" 이라는 단어와 대응되는 "you"와의 거리가 좁혀지기 때문에 "너를"이라는 단어가 잊혀지지 않고 "you"와 대응 될 가능성이 높아지게 되는 것이다.
이 방식을 통해 성능이 크게 향상되었다.
