TSM(Temporal Shift Module) 논문 리뷰
본 페이지에서는 TSM: Temporal Shift Module for Efficient Video Understanding논문에 대해서 말하고자 합니다.
1. 2D CNN VS 3D CNN
최근 들어 영상 스트리밍이 발전함에 따라 비디오의 양이 많아졌다.
이에 따라 종류를 분류해야할 영상도 많아지게 되었다.
기존의 2D CNN은 computational cost 측면에서 상대적으로 효율적이고 차원의 정보를 잘 활용할 수 있다는 점이 있지만, 시간적인 정보를 결합하지 못한다.
시간 적인 정보를 결합하지 못하는 점을 해결하고자 3D CNN을 생각해내 적용하였을 때 시간적인 정보는 잘 활용 하였지만 computational cost가 너무 크게 증가한다는 단점이 있다.
TSM은 2D CNN의 장점을 취하면서 시간축의 정보를 활용할 수 있도록 할 수 있게 하였다.
2. Temporal Information
기존에 이미지 분류에서 CNN은 차원의 정보를 잘 활용하였고 이미지 분류에서 좋은 성능을 내고 있다.
그러나 실제 생활에서 시간축의 정보는 굉장히 중요하다.
다음의 사진으로 예를 들어보겠다.

이 사진을 보았을 때 이 사진이 문을 가르키는 것은 알 수 있으나 문이 열리는 중인지 닫히는지 알 수 없다.
이전 프레임이 닫혀있는 프레임이라면 문이 열리는 상태인 걸 알 수 있다.
이처럼 2D CNN만을 이용한다면 문이라는 것만 알 수 있고 문의 상태는 알 수 없다.
3. Temporal Shift
기존의 2D CNN 은 BCHW의 형태에서 C축을 기준으로 정보를 추출하는 반면에 3D CNN은 BTCH*W의 형태에서 T축과 C축을 기존으로 정보를 추출한다.
앞서 말했듯 TSM 은 2D CNN을 활용하면서 시간 축으로 채널을 shift 하여 시간 축의 정보를 혼합하는 것이다.
이를 그림으로 보이면 다음과 같다.

(a) : 기존의 2D CNN을 보여준다. 시간 축의 정보는 사용되지 않으며 오직 채널 축으로만 정보를 정보를 추출한다.
(b),(c) : 2D CNN과 TSM 을 활용하였다. 시간 축을 위아래로 shift 해주는 연산을 통해 시간 축의 정보를 활용한다.이때 (b)와 (c)는 각각 시간 축의 정보를 양방향으로 혼합 하는 것과 단방향으로 혼합 하는 것이다.
(b)는 offline으로 classification을 진행하는 경우에 사용된다. 이 경우 저장되어 있는 동영상을 활용하는데 이는 현재 시점 이후의 프레임을 알고 있기에 가능한 것이다.
(c)는 online으로 classification을 진행하는 경우이다. 이 경우는 실시간으로 분류를 하기 때문에 미래 프레임에 대한 정보를 알 수 없으므로 단방향으로만 shift 해준다.
이때 shift 연산의 문제점은 다음과 같다.
1. shift 연산은 개념적으로는 FLOP이 0이지만 데이터의 이동에서 발생하는 computational cost는 무시할 수 없다.
2. 너무 많은 채널을 shift 해주는 경우에는 시간축의 정보를 많이 혼합할 수 는 있어도 채널의 정보를 오히려 잃을 수 있는 경우가 발생한다.이러한 점을 기준으로 TSM 모델에 대한 실험을 진행한다.
4. TSM: Temporal Shift Module
Convolution with Shift
CNN에서 1D CNN을 생각해본다고 하자.
입력 X는 하나의 무한 길이의 배열이라고 하고 가중치 W=(w1,w2,w3)라고 하자.
Convolution 연산을 식으로 설명하면 다음과 같다.
이를 shift 연산과 multiply-accumulate 두 과정으로 나눈다고 하면 다음 과 같다.
Shift 연산
Multiply-accumulate 연산
위 식을 간단한게 그림을 그려보면 다음과 같다.
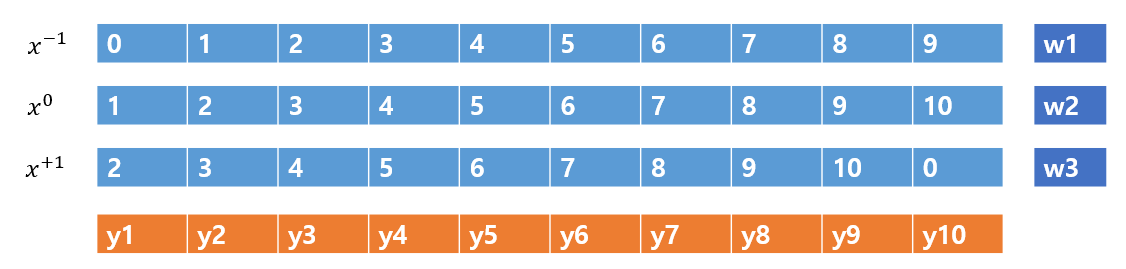
Temporal Shift Module도 이와 동일하다. 기존 3D CNN을 shift연산과 2D CNN으로 나누었다.(물론 조금 더 추가적인 연산이 필요)
Partial Shift
앞서 말했듯이 너무 많은 채널에 Shift 연산을 해주는 것은 차원의 정보를 잃어버리게 만든다.
또한 이 문제 뿐만 아니라 많은 데이터를 Shift 해줌에 따라 데이터 전환이 많이 발생하게 되어 추가적인 computational cost가 발생한다.
이를 실험으로 나타낸 표는 다음과 같다.
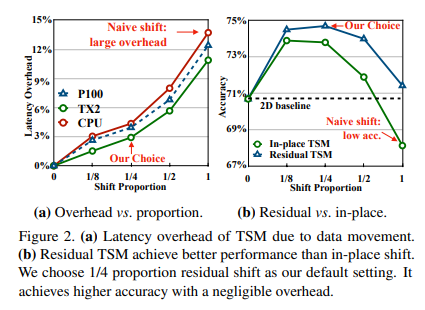
위의 그림에서 x축은 Shift 비율로 이 비율이 1인 경우는 전체를 Shift 해준다는 것이다.
좌측은 latency 우측은 성능과 관련되어 있다.
또한 우측의 inplace와 residual은 ResNet에서 TSM이 위치한 곳에 따라 달라지며 다음과 같다.
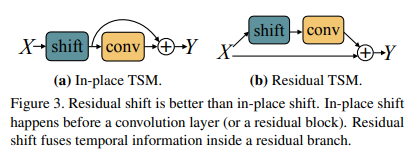
inplace의 경우 residual block을 들어가기 전에 시간 축으로 shift 연산을 하기 때문에 차원의 정보를 손실을 그대로 가져가게 된다.
residual의 경우는 shift 전의 정보를 가지고 있기 때문에 차원의 정보의 손실을 방지하게 되어 inplace보다 더 학습이 잘 된다.
이때 residual shift에서 성능은 shift 비율이 1/4일 때 가장 좋았다.
비율이 1/4라고 함은 각 방향으로 전체의 1/8씩 shift 하는 것이다.(bi면 전체의 1/8을 +1 shift를 1/8을 -1 shift를 하는 것이다. uni라면 전체의 1/4를 shift 하는 것)
Running Process
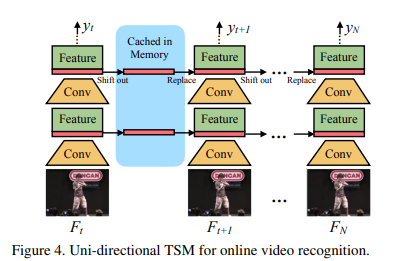
TSM의 작동 방식은 다음과 같다.
1. ResNet의 입력으로 B*T*C*H*W 가 들어온다면 (B*T)*C*H*W 로 전환하여 첫 특징 추출을 한다.
2. 각 stage의 residual block에 들어가면서 conv 연산 전에 shift 연산을 진행해준다. shift 연산은 (B*T)*C*H*W -> B*T*C*H*W 처럼 전환 하고 T축을 기준으로 shift 연산 후에 다시 (B*T)*C*H*W 바꾸어준다.
3. 이후 T개의 프레임에 대한 각각의 출력 결과가 나오는데 이 출력 결과를 평균을 내어 하나의 출력을 낸다.5. 코드구현
PyTorch
import torch
import torch.nn as nn
class bottleneck_block(nn.Module):
def __init__(self,i,o,s,e,stage):
super(bottleneck_block,self).__init__()
self.conv1 = nn.Conv2d(i,o,1,s)
self.bn1 = nn.BatchNorm2d(o)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(o,o,3,1,1)
self.bn2 = nn.BatchNorm2d(o)
self.conv3 = nn.Conv2d(o,o*e,1,1)
self.bn3 = nn.BatchNorm2d(o*e)
if s == 2 or i==o:
self.identity = nn.Sequential(
nn.Conv2d(i,o*e,1,s),
nn.BatchNorm2d(o*e)
)
else :
self.identity = nn.Sequential()
def shift(self,x,frame=8,div=8):
bt,c,h,w = x.size()
b = bt//frame
t = frame
div_c = c//div
x = x.view(b,t,c,h,w)
ret = torch.zeros_like(x)
#bi-shift
ret[:,:-1,:div_c,:,:] = x[:,1:,:div_c,:,:]
ret[:,1:,div_c:div_c*2,:,:] = x[:,:-1,div_c:div_c*2,:,:]
ret[:,:,div_c*2:,:,:] = x[:,:,div_c*2:,:,:]
ret = ret.view(bt,c,h,w)
return ret
def forward(self,x):
identity = self.identity(x)
out = self.shift(x)
out = self.conv1(out)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self,e=4,num_layers=[3,4,6,3]):
super(ResNet,self).__init__()
def n_blocks(i,o,s,stage):
layers = []
layers.append(bottleneck_block(i,o,s,e,stage))
for _ in range(1,num_layers[stage]):
layers.append(bottleneck_block(o*e,o,1,e,stage))
return nn.Sequential(*layers)
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,7,2,3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(3,2,1)
)
self.stage1 = n_blocks(64,64,1,0)
self.stage2 = n_blocks(64*e,128,2,1)
self.stage3 = n_blocks(128*e,256,2,2)
self.stage4 = n_blocks(256*e,512,2,3)
self.F = nn.AdaptiveAvgPool2d(1)
self.FC_cls = nn.Sequential(
nn.Linear(512*e,101)
)
def forward(self,x,cls_label=None):
b,t,c,h,w = x.size()
out = x.view(b*t,c,h,w)
out = self.conv1(out)
out = self.stage1(out)
out = self.stage2(out)
out = self.stage3(out)
out = self.stage4(out)
out = self.F(out)
out = out.view(out.size(0),-1)
cls = self.FC_cls(out)
cls = cls.view(b,t,-1)
out_cls = cls.mean(1)
return out_cls