Vision Transformer(ViT) 논문 리뷰
본 페이지에서는 Vision Transformer의 등장배경과 특징에 대해서 말하고자 합니다.
Attention, Transformer, BERT의 개념이 포함되어 있기 때문에 아래의 글을 읽고 보시면 몇몇 개념들에 대한 이해가 쉬우실 겁니다.
1. Intro
본 논문은 Vision Transformer(ViT)라는 모델을 발표를 한다.
최근 자연어 분야에서 Transformer라는 모델이 지배적인 상황이며 이 모델을 Computer Vision 분야에 적용하려는 시도는 많이 있었지만 매우 제한적이었다.
기존에는 Attention 매커니즘을 CNN과 접목시키려 하였었다.
Transformer에 사용되는 Multi-Head Attention 매커니즘의 원리와 작동방식은 무시할 수 없을만큼 매력적이며 이 매커니즘을 Computer Vision에 접목시키려는 노력은 많이 있었다.
Attention 매커니즘을 이미지 내의 전체 픽셀에 적용하려고도 하였고, 이웃한 local에 대해 적용하려고도 하는 등의 여러 방법이 존재했다.
본 논문은 이미지를 여러 패치로 나누어 패치 자체를 단어처럼 보며 CNN에 의존하지 않고 Classification 작업에 적용하였다.
이러한 Transformer는 데이터가 적은 경우에는 ResNet보다 성능이 떨어지는 특징을 보였지만 데이터가 충분한 경우에는 ResNet보다 성능이 높은 결과를 보인다.
이 이유는 Transformer에는 CNN과는 달리 Translation과 locality과 같은 Inductive bias가 부족하기 때문에 불충분한 데이터의 양으로는 Generalize가 잘 되지 않는다고 합니다.
Inductive Bias에 대한 것은 이후에 자세히 다루겠습니다.
2. Vision Transformer(ViT)
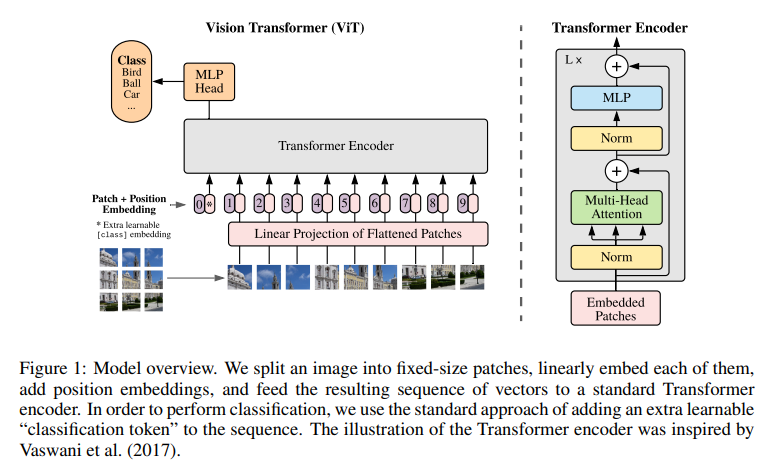
위의 사진은 ViT의 모델 구조입니다.
Transformer Encoder는 기존의 Transformer와 비슷하다고 보시면 됩니다.
Multi Head Attention의 구조는 기본적으로 Transformer의 형식을 따릅니다.
2.1 Embedding for Transformer
기존 Transformer는 1차원의 토큰 Embedding들의 Sequence를 입력으로 받습니다.
이미지는 2D이기 때문에 2D이미지를 1차원으로 변환하기 위한 작업(Patch Embedding)을 합니다.
다음의 사진을 통해 보이면 다음과 같습니다.
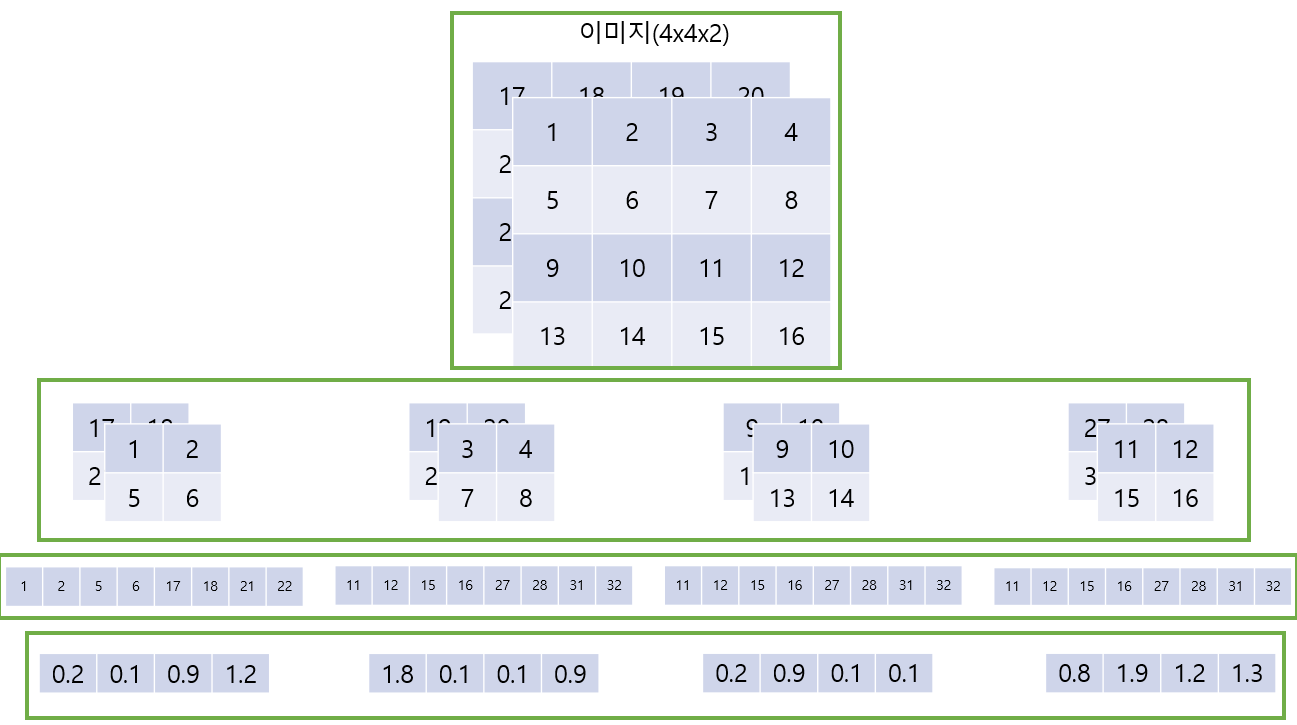
위의 예시는 의 이미지를 크기의 패치로 나누는 것으로 크기의 벡터로 임베딩하는 것이다.
-
( 높이, 너비, 채널) 에 해당하는 이미지를 크기의 패치로 나누어 줍니다.
-
Flatten 작업을 해주어 로 만들어줍니다.()
-
이후 각 패치의 크기를 크기의 벡터로 임베딩 하도록 합니다.
-
각 출력을 이라고 정의한다.
추가적으로 자연어 처리 분야에서 BERT라는 모델에서 사용되는 [Class] 토큰과 비슷하게 Input Embedding 맨 앞에 [Class] Patch를 넣어 줍니다.
BERT에서 [Class] 토큰은 입력할 때 의미를 가지고 있지 않은 토큰으로 모델 내부에서 다른 토큰들과의 정보를 주고받게되고 최종적으로 해당 문장에 대한 문맥 정보를 담는 토큰이 되어 이를 글 내에서의 감정 Classification과 같은 문제에 사용됩니다.동일하게 [Class] Patch는 이후 Transformer Encoder의 출력() 중 맨 앞()에 대응되며 이는 Classification Head(MLP Head)에 입력으로 들어가 Classification 작업에 사용됩니다.
최종적으로 각 Embedding된 Patch들이 Encoder에 들어가기 전에 학습 가능한 Position Embedding을 더하여 각 Patch Embedding들에 위치에 대한 정보를 추가해줍니다.
이를 그림으로 표현하면 다음과 같습니다.
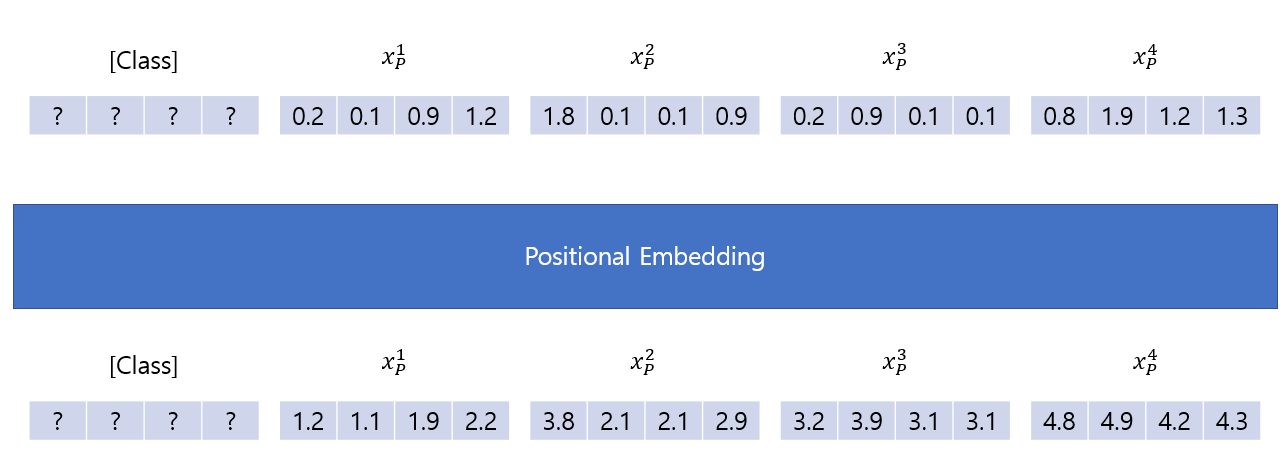
위의 예시에서 Positional Embedding 작업은 각 패치에 대한 벡터에 인덱스 값을 더해주는 것으로 간단히 예를 들었습니다.
[Class] Patch의 값들은 임의로 랜덤하게 초기화 해주시면 됩니다.
최종적으로 위의 동작을 식으로 나타내면 다음과 같습니다.
2.2 Inductive Bias
Inductive Bias을 직역하면 유도 편향이라고 한다.
이러한 Inductive Bias는 학습에 사용되지 않은 데이터에 대해서 어떤 것에 대해 예측할 때 정확한 예측을 위해 사용하는 추가적인 가정입니다.
Transformer에서 대표적으로 제시한 Locality와 Translation Equivariance는 다음과 같습니다.
- Translation Equivariance : Computer Vision에서 어떠한 객체를 검출하고자 할 때 해당 객체의 위치가 달라져도 동일하게 검출할 수 있도록 하는 것이다. 즉, 입력의 위치가 달라져도 출력은 동일하다라는 것입니다.
-
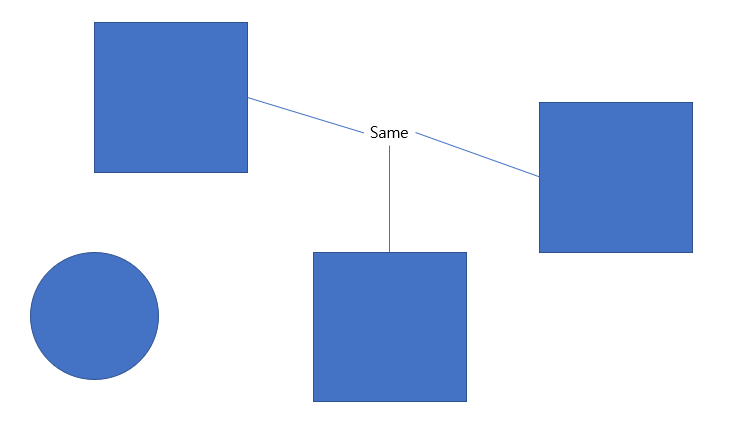
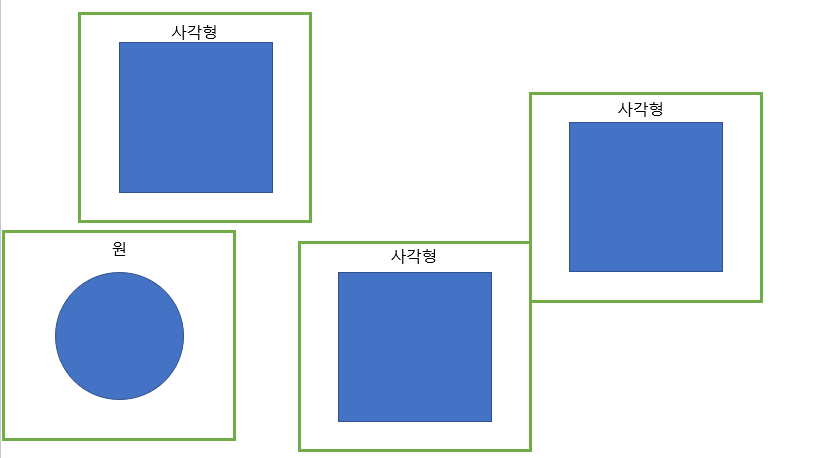
Locality : 말 그대로 지역성이라는 개념으로 이미지 내에서 정보는 특정 지역에 담겨져 있으며 이 지역적인 특징을 담기 위해서 CNN에서는 여러 크기의 필터를 통해 지역적인 정보를 담는다.
위의 그림에서 전체적인 하나의 지역을 보면 원과 사각형이라는 것을 알 수 있지만 하나의 픽셀개념으로 살펴보면 원인지 사각형인지 알 수 없다.
Inductive Bias에 대한 설명은 Locality에 대해 얘기를 하면 다음과 같다. CNN의 Conv연산 자체는 Locality의 특성을 고려해 여러 크기의 필터를 통해 한 픽셀에 인접한 여러 픽셀에 대한 정보를 활용한다.
특히 하나의 필터가 한 차원 내의 모든 부분을 Sliding Window 형식으로 지나가기 때문에 이미지 내에 있는 동일한 사람의 위치가 옮겨지더라도 필터를 통해 사람만을 찾아낼 수 있기 때문에 Translation Equivariance의 특성을 고려했다고 볼 수 있습니다.
그렇다면 ViT에서는 위와 같은 Inductive Bias가 부족하다고 하는 것일까?
우선 CNN의 필터가 Sliding Window처럼 이미지의 모든 영역을 스캔하는 방식과 비슷하게 작동하는 것과는 다르게 ViT는 이미지를 패치로 나누어 작동하며 MLP는 한 패치 내부에서만 Fully Conneted형식으로 작동하기 때문입니다.
Fully Connect은 픽셀에 대한 가중치로 연산을 하기 때문에 Convolution 연산과는 달리 Translation Equivariance 특성이 사라지게 됩니다.
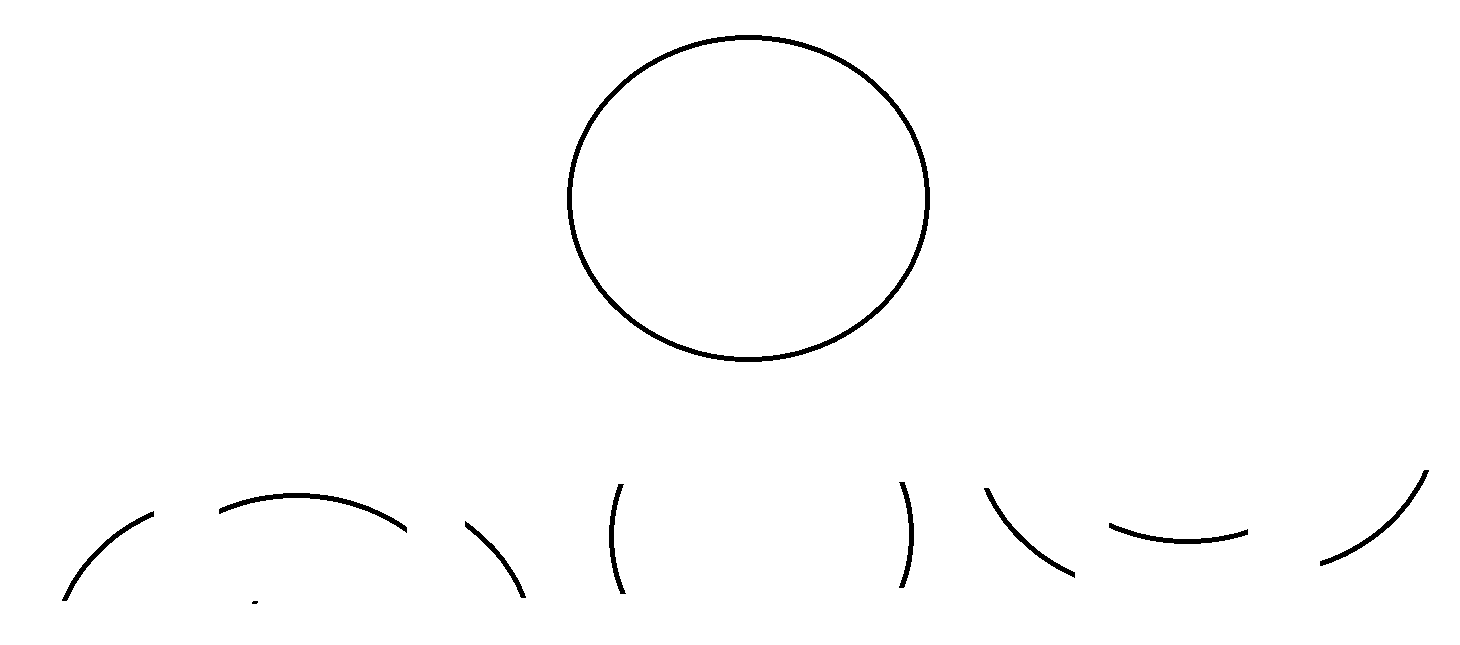
또한 Patch를 사용하게 되면 지역성이 조금 깨지는 경우가 발생 할 수 있습니다.
가령 패치를 여러개로 나누게 될 때 이미지의 일부가 잘려나가 해당 패치만을 고려할 때 어떤 부분인지는 알 수 없게 됩니다.
ViT에서는 이러한 이유로 CNN에 비해서 Inductive Bias가 더 적다고 하는 것 입니다.
ViT에서는 MLP에서는 각 패치가 무얼 의미하는지에 대한 정보를 추출하도록 하고 이 정보를 기반으로 MSA에서 각 패치들과의 연관성을 고려하도록 하면서 이러한 단점을 극복하도록 합니다.
2.3 Hybrid Architecture
이미지를 패치로 나누는 것만 하는 것 대신에, 입력 Sequence를 CNN으로 부터 얻어낸다.
이 경우에 CNN으로부터 추출된 Feature Map에 Patch Embedding 벡터 를 적용시킨다.
패치는 크기의 차원을 가질 수 있으며,Feature Map들을 Flattening 하여 이후 Transformer의 입력에 맞게끔 차원의 크기의 벡터로 Projection 하는 것이 가능하다는 것을 의미한다.
3 Experiments
본논문은 SOTA CNN 모델과 비교하며 , ViT가 기존의 모델들보다 Large Scale 데이터셋을 이용하여 사전학습 하면 성능이 더 좋음을 보이고자 한다.
그래서 ResNet,ViT,Hybrid 세 모델을 이용해 성능을 비교하려고 한다.
-
데이터 요구사항을 이해하기 위해 각 모델을 다양한 크기의 데이터셋으로 사전학습한 것에 대한 성능 비교
-
사전학습에 필요한 Computational cost에 대한 비교 실험
3.1 Model Variants
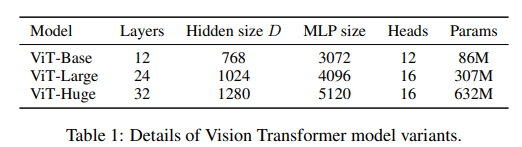
BERT에서 제안된 모델과 동일하게 ViT-Base,ViT-Large 모델을 구성하고 따로 ViT-Huge 모델을 구성한다.
본 논문에서 소개된 모델 이름 정하는 방법은 다음과 같다.
L은 ViT 모델의 크기로 Large를 의미하며 Patch의 크기가 임을 의미한다.
CNN의 기초모델은 ResNet을 사용하며 Batch Normalization을 Group Normalization으로 대체한다.
이렇게 수정을 하게 되면 전이 학습이 더 잘된다고 하며 이러한 ResNet을 BiT(Big Transfer)라고 한다.
Hybrid 모델은 Feature map들을 한 픽셀 크기의 Patch로 ViT에 입력한다.
3.2 Data Requirements
ViT는 JFT-300M Dataset으로 사전학습시켰을 때 성능이 가장 좋았다.
그만큼 데이터 셋이 많으면 성능이 좋다는 것인데, 그럼 얼마나 많은 데이터셋이 필요한지에 대한 실험이다.
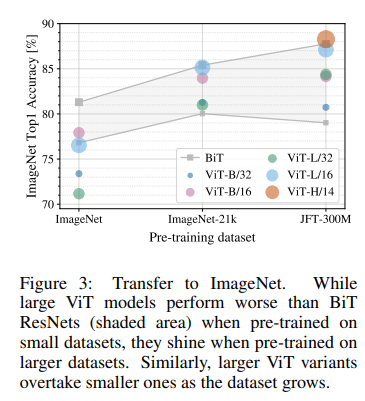
위의 사진은 사전학습 시킨 데이터셋 별로 이후 같은 데이터셋(ImageNet)으로 Fine-Tuning한 성능 비교표이다.
X축의 좌측부터 우측으로 데이터셋의 크기가 증가한다.
추가적으로 아래는 데이터셋의 크기에 따른 사전 학습 후 전이 학습 성능 비교이다.
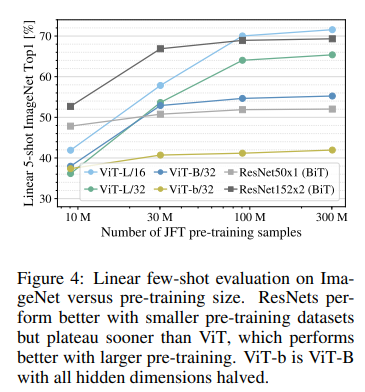
ResNet에 비해 데이터의 크기가 커지면 커질 수록 ViT의 성능 향상이 급격하게 증가됨을 보여준다.
3.3 Scaling Study
이번에는 각 모델별로 사전 학습을 하는데에 필요한 Cost에 대한 비교 실험을 진행한다.
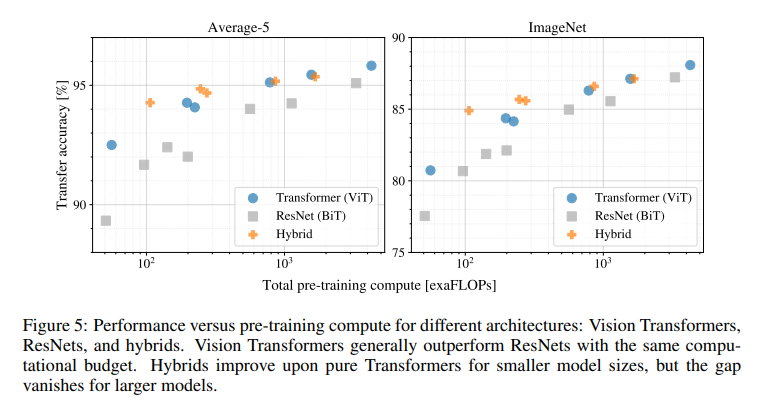
두 표에서 모두 비슷한 양상을 보이며 같은 성능을 내기 위해 ViT가 BiT에 비해 약 2~4배정도의 적은 FLOPs를 소비한다.
Hybrid 모델에서는 적은 Computational Cost에서는 ViT보다 성능이 좋지만 이후 차이는 점점 줄어든다.
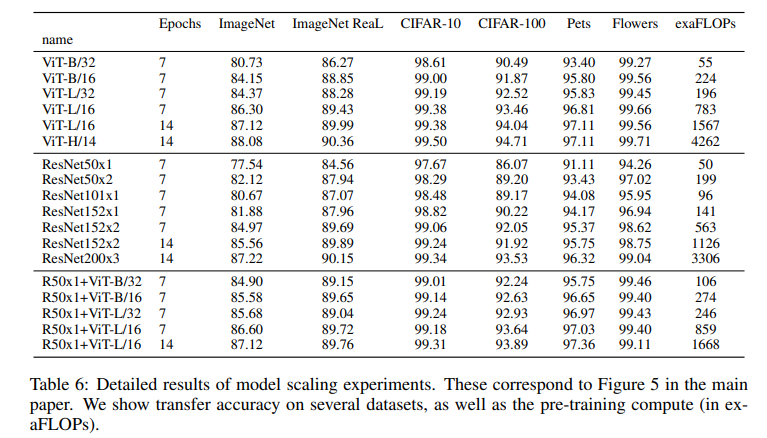
모델별 자세한 성능 표는 다음과 같다.
3.4 Inspecting Vision Transformer
이 절은 ViT가 어떻게 이미지 데이터를 처리하는지에 대한 분석입니다.

위의 사진은 학습한 ViT를 기반으로 모델이 어느곳을 집중 하는지에 대해 시각화 한 부분으로 각 이미지에 대해서 적절한 부분에 집중하여 결과를 출력함을 보여줍니다.
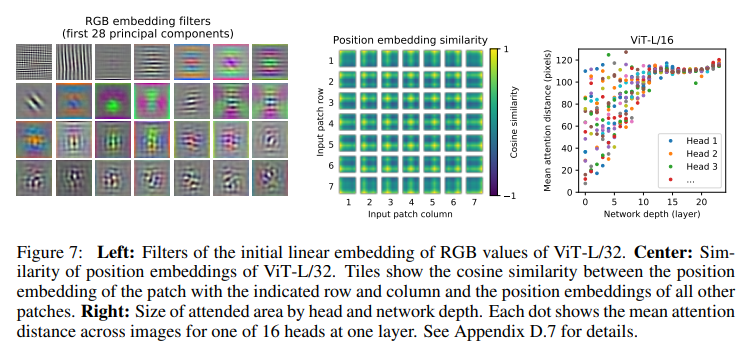
왼쪽은 각 패치에 대하여 학습된 필터들 중 주요한 필터를 보여줍니다. 이는 실제로 CNN의 Convolution 필터와 유사한 모습을 보입니다.
중앙은 학습된 Positional Embedding에 대한 Cosine 유사도에 대한 Heatmap 보여주는데 각 패치별 실제 위치와 비슷하게 유사도가 높은 것을 확인할 수 있습니다.
우측의 목적은 우선 Self Attention이 얼마나 전체적인 정보를 잘 통합하는가에 대해서 확인 하기 위함이다.
이를 확인하기위해 이미지 공간에서 각 헤드들이 Attention 가중치에 의해서 어떤 정보와 통합이 되었는지에 대한 평균 거리를 계산하여 시각화한 것이다.
이러한 Attention Distance는 CNN에서의 Receptive field의 크기와 동일하다고 볼 수 있다.
초기 레이어의 Head들의 Attention Distance를 확인해보면 거리가 먼 것은 Global하게 정보를 통합했다고 볼 수 있고 가까운 것은 Local에 대한 정보를 Attend 했다고 볼 수 있다.
적은 거리에 대한 Attend는 Transformer이전에 Resnet을 결합한 Hybrid에서는 덜 보인다.
즉, Local에 대한 Attend는 CNN에서의 초기 Convolution layer와 비슷한 역할을 한다고 볼 수 있는 것이다.
더 나아가 레이어의 깊이가 증가할 수록 Attention distance는 증가하고 이는 모델이 Classification에 의미론적으로 유의미한 지역에 Attend함을 의미하고 이는 Figure 6에서 보여진다.
3.5 Self-Supervision
Transformer 모델이 NLP에서의 혁신을 불러왔지만, 모델만으로 성능 향상이 이루어진 것은 아니다.
특히 BERT 모델에서는 Self Supervised 사전학습을 통해 성능이 더 향상됨을 얘기했다.
ViT에서도 BERT와 동일하게 Patch의 일부를 마스킹하는 방식을 사용하면서 성능을 향상시키려 하였다.
모든 패치 중 절반에 해당하는 패치는 정상적으로 두고, 나머지 절반은 다음의 비율로 마스킹하거나 대체하거나 그대로 둔다.
-
마스킹 : 80%를 [mask]로 Embedding한다.
-
대체 : 10%를 무작위로 다른 Patch로 embedding한다.
-
불변 : 10%를 해당 패치 그대로 둔다.
최종적으로 Encoder의 출력 중 마스킹 된 Patch에 해당되는 출력 결과는 다음의 세가지 방법으로도 사용이 가능하다.
-
패치의 색을 평균을 내어 3bit 색상을 예측(512()개의 색상에 대한 한개의 출력)
-
크기의 패치를 로 크기를 줄인 버전에 대해서 1번과 동일하게 각각 평균을 내어 3bit 색상으로 출력(512개의 색상에 대한 16개의 출력)
-
패치에 대해서 L2로 Regression을 해준다.(3개의 RGB 채널에 대한 256개의 Regreesion)
세가지 모두 잘 작동 했으나 3번째 방법은 오히려 성능이 안좋았다.
최종적으로 1번을 사용했는데 그 이유는 1번이 Few Shot에서 좋은 성능을 냈기 때문이다.
4. 코드구현
PyTorch
Patchify 구현에 대한 얘기는 여기를 보시면 됩니다.
class Patch_Embedding(nn.Module):
def __init__(self,in_channels,height,width,patch_size,d_model):
super(Patch_Embedding,self).__init__()
self.n = (height*width)//(patch_size**2)
self.p = patch_size
self.c = in_channels
self.projection = nn.Linear(in_channels*patch_size**2,d_model)
self.positional_encoding = nn.Parameter(torch.zeros((height*width)//(patch_size**2)+1,d_model))
def patchify(self,x):
out = img.reshape(-1,self.c,self.h//self.p,self.p,self.w//self.p,self.p) # b,c,h//p,p,w//p,p
out = out.permute(0,2,4,1,3,5) # b, h//p,w//p,c,p,p
out = out.reshape(-1,self.n,self.c*self.p*self.p) # b,n,cpp
return out
def forward(self,x):
out = self.patchfy(x)
out = self.projection(out)
out = torch.cat([torch.zeros((out.size(0),1,out.size(2))),out],1)
out += self.positional_encoding
return out
class Hybrid_Embedding(nn.Module):
def __init__(self,in_channels,height,width,patch_size,d_model):
super(Hybrid_Embedding,self).__init__()
self.conv = nn.Conv2d(in_channels,d_model,patch_size,patch_size)
self.positional_encoding = nn.Parameter(torch.zeros((height*width)//(patch_size**2)+1,d_model))
def forward(self,x):
out = self.conv(x).flatten(2).transpose(1,2)
out = torch.cat([torch.zeros((out.size(0),1,out.size(2))),out],1)
out += self.positional_encoding
return out
class MHA(nn.Module):
def __init__(self,d_model,d_k,d_v,num_head):
super(MHA,self).__init__()
self.h = num_head
self.d_k = d_k
self.d_v = d_v
self.q_linear = nn.Linear(d_model,d_k*num_head)
self.k_linear = nn.Linear(d_model,d_k*num_head)
self.v_linear = nn.Linear(d_model,d_v*num_head)
self.MHA_linear = nn.Linear(d_v*num_head,d_model)
def forward(self,x):
q = self.q_linear(x).view(x.size(0),x.size(1),self.h,self.d_k).transpose(1,2)
k = self.k_linear(x).view(x.size(0),x.size(1),self.h,self.d_k).transpose(1,2)
v = self.v_linear(x).view(x.size(0),x.size(1),self.h,self.d_v).transpose(1,2)
matmul1 = torch.einsum("...nd,...kd->...nk",q,k)
softmax = torch.softmax(matmul1/np.sqrt(self.d_k),-1)
matmul2 = torch.einsum("...nd,...dk->...nk",softmax,v)
concat = matmul2.transpose(1,2)
concat = concat.reshape(concat.size(0),concat.size(1),self.h*self.d_v)
out = self.MHA_linear(concat)
return out
class Encoder(nn.Module):
def __init__(self,d_ff,d_model,d_k,d_v,num_head):
super(Encoder,self).__init__()
self.MHA = MHA(d_model,d_k,d_v,num_head)
self.MLP = nn.Sequential(
nn.Linear(d_model,d_ff),
nn.ReLU(),
nn.Linear(d_ff,d_model)
)
self.ln = nn.LayerNorm(d_model)
def forward(self,x):
out_MHA = self.ln(x)
out_MHA = self.MHA(out_MHA)
out_MHA += x
out_MLP = self.ln(out_MHA)
out_MLP = self.MLP(out_MLP)
out_MLP += out_MHA
return out_MLP
class ViT(nn.Module):
def __init__(self,num_layer,height,width,in_channels,out_channels,patch_size,d_model,d_ff,d_k,d_v,num_head,hybrid=False):
super(ViT,self).__init__()
if hybrid:
self.Embedding = Hybrid_Embedding(in_channels,height,width,patch_size,d_model)
else :
self.Embedding = Patch_Embedding(in_channels,height,width,patch_size,d_model)
layers = []
for i in range(num_layer):
layers.append(Encoder(d_ff,d_model,d_k,d_v,num_head))
self.Encoder = nn.Sequential(*layers)
self.MLP_head = nn.Sequential(
nn.LayerNorm(d_model),
nn.Linear(d_model,out_channels)
)
def forward(self,x):
out = self.Embedding(x)
out = self.Encoder(out)
out = self.MLP_head(out[:,0,:]) # b,n,d_model - > b, d_model - > b,out_channels
return out