Semantic Segmentation
Semantic Segmentation
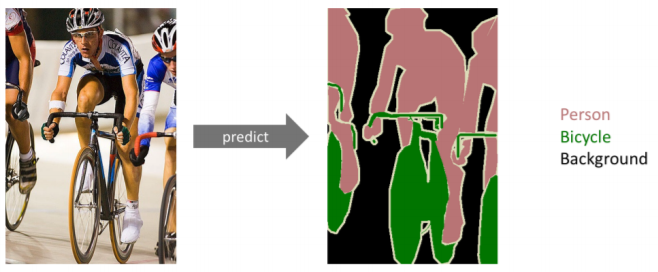
- same as Dense Classification, per pixel Classification
- 어떤 label에 속하는지 확인 위해 img의 pixel마다 분류 실행
- 자율주행에서 사용
Fully Convolutional Network
-
일반적인 CNN의 형태.
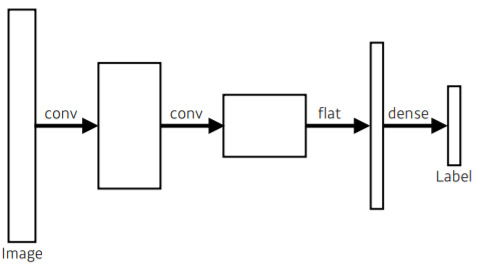
-
flat 과정을 통해 1차원인 vector로 만듦
-
Fully Convolutional Network
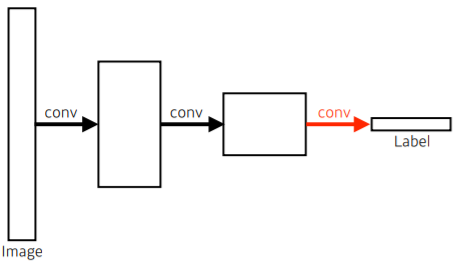
-
일반적인 CNN에서의 Dense Layer를 없애는 과정을 Convolutionalization
-
일반적인 CNN과 parameter가 정확하게 일치
-Fully Flatten을 통해 reshape하고 fully convolution으로 넘어가는 것은 convolution을 바꿨기 때문
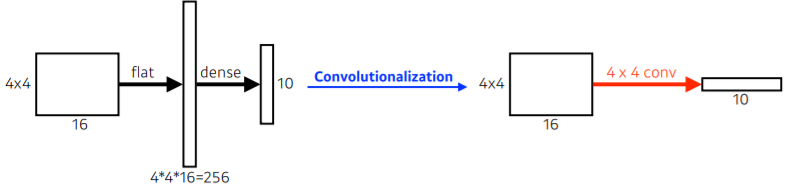
-
중간에 있던 게 20x20x1000이었던 것을 400,000짜리 vector로 바꾸는 것이 아니라 20x20x1000 feature filter로 만듦
-
그 kernel의 1x1x1000짜리 convolutional feature map 만듦
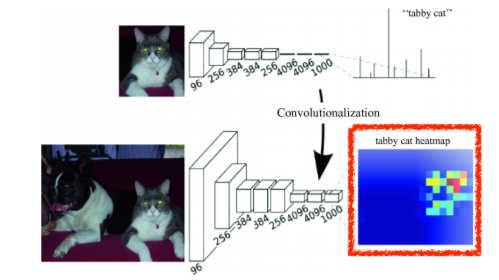
-
Fully Convolutional Network는 input의 spatial dimension에 independent
-
convolution이 가지는 shared parameter 성질 때문에 output이 커지면 그것에 비례하여 뒷단의 network와 spatial dimension이 커짐
-
어떠한 input size에서도 돌 수 있는 FCN에서, output dimension들은 subsampling을 통해 줄어들 수 있음
-
따라서, coarse한(space resolution이 낮은) output을 dense pixel로 바꿔줘야 함
Deconvolution (Convolution Transpose)

- convolution의 역연산
- parameter 숫자와 network architecture의 크기 계산할 때 편리
- convolution은 30x30 → 15x15, deconvolution은 15x15 → 30x30
- deconvolution을 통해 spatial dimension을 키워줌
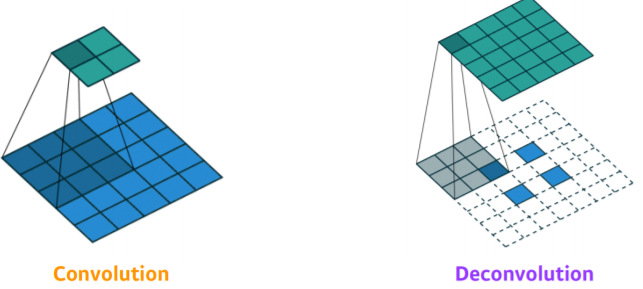
- convolution을 통해 5x5 → 2x2
- deconvolution을 통해 padding을 많이 줌으로써 2x2 → 5x5
- 이에 따른 결과
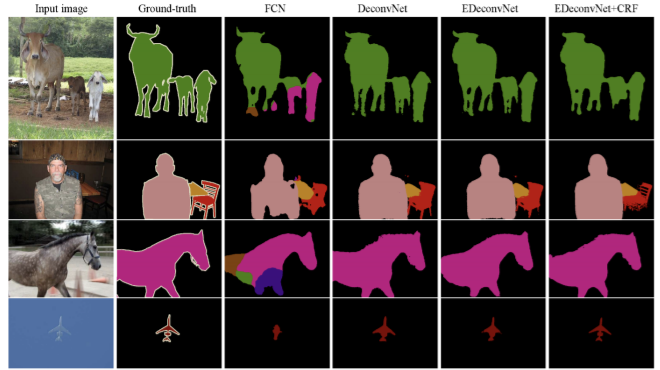
Detection
R-CNN
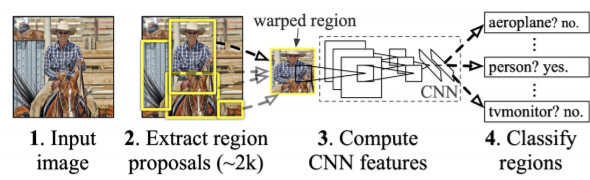
1. img 안에서 patch(부분)을 뽑아냄
2. CNN 돌기 위해 size를 똑같이 맞춰줌
3. support vector machine(SVM)으로 분류 수행
- softmax를 사용해도 되나, SVM을 썼을 때 실험결과가 더 높음

SPPNet

- R-CNN에서는 crop/warp의 수가 보통 2000 정도기 때문에 CNN이 2000번보다 더 많이 돌아야 함
- 반면에, SPPNet은 CNN이 한 번만 돌게됨
- image 안에서 bounding box 뽑고
- image 전체에 대해 convolution feature map 뽑고
- 뽑힌 그 bounding box 위치에 해당하는 convolution feature map의 tensor만 긁어옴
- tensor 한 번만 돌리지만, bounding box를 만들고 필요한 size만큼의 pooling으로 하나의 vector를 만들고 분류해줘야 하므로
사실 느림
Fast R-CNN
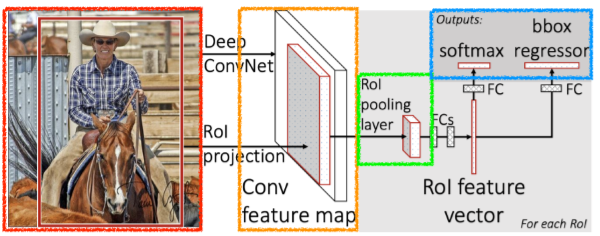
1. image 기반으로 input과 bounding box들을 가져온다
2. convolutional feature map을 한 번 뽑아낸다
3. 각 지역에 대해 ROI(Region of Internet)을 통해 고정된 길이의 feature를 가져온다
4. 최종적으로 Neural network를 통해 class와 bounding-box regressor 두 개의 결과를 얻어낸다
Faster R-CNN
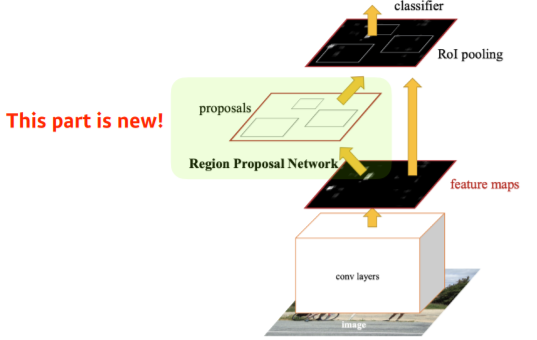
- Fast R-CNN에서 Region Proposal Network를 추가함
Region Proposal Network
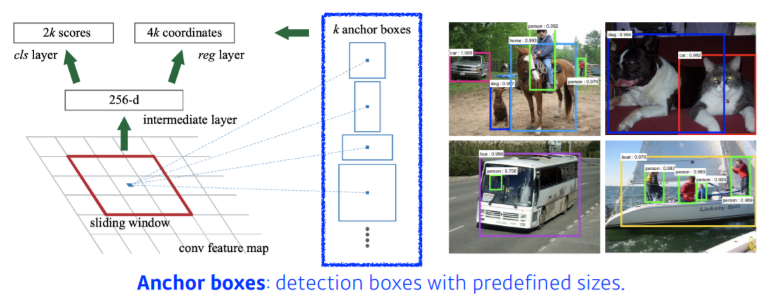
- img에서 특정 영역의 patch가 bounding box로써의 의미가 있을지/없을지 판단
- Anchor Box : 미리 정해놓은 bounding box의 크기
- 이 template들이 어떻게 바뀔지에 대한 offset 찾고 template 고정
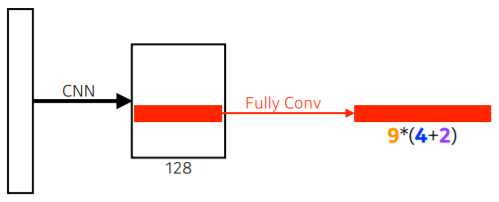
- fully convolution 통해 해당하는 영역에 물체가 존재 여부 확인
- 9(3x3) : 세 개의 다른 region size(128, 256, 512)와 세 개의 다른 비율(1:1, 1:2, 2:1)
- 4 : 네 개의 bounding box regression parameter (bounding box를 위아래&양옆 기준으로 얼마나 키우고 줄일지)
- 2 : box classification (해당 bounding box가 쓸모있을지 없을지) - 최대한 적은 bounding box 사용 위해
- Faster-CNN의 결과

YOLO

- 굉장히 빠른 object detection algorithm
- tensor에서 분류하고 하는 것이 아니라 그냥 한 img에서 바로 output 나올 수 있기 때문에 Faster R-CNN보다도 더 빠름 - bounding box와 class probability를 동시에 예측
- bounding box를 따로 뽑는 과정이 없으므로 더 빠름
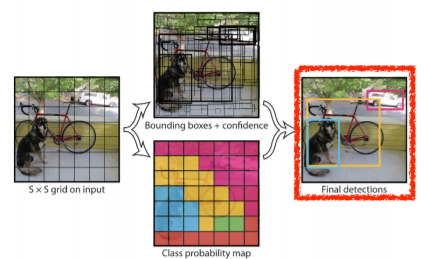
- img를 SxS grid로 나눔
- 찾고 싶은 물체의 중앙이 grid 안에 들어가게 될 경우, 해당 grid cell이 해당 물체에 대한 bounding box와 그 해당 물체가 무엇인지를 같이 예측
- 각 cell이 B bounding box들을 예측 (B=5)
- box 재정의 과정 (x, y, 높이, 너비 기준)
- 해당 object를 쓸지 말지 결정
- C class probability 예측 과정 거침
- 최종적으로 SxSx(Bx5+C) 크기의 tensor가 됨
- SxS : grid의 cell 개수
- Bx5 : offset(x, y, w, h)와 사용 여부를 포함하는 B bounding boxes
- C : class의 개수

