Modern Convolutional Neural Networks
ILSVRC
- ImageNet Large-Scale Visual Recognition Challenge
- Classification / Detection / Localization / Segmentation 에서 주로 사용
AlexNet
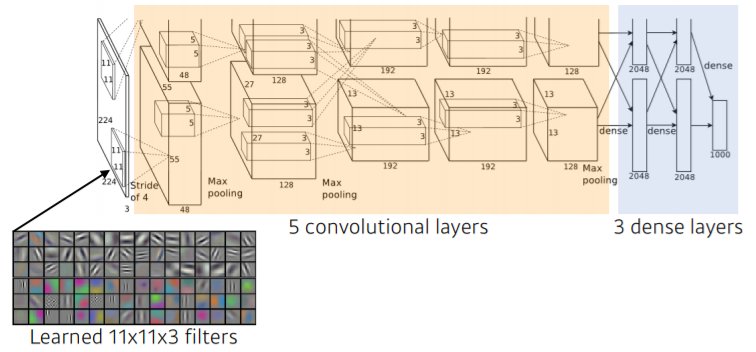
- 입력은 같지만 network가 두 개로 나뉘는 것은 GPU 부족을 해결하기 위함
- AlexNet의 성공 요인
- GPI 충족 (2 GPUs)
( Not Linear하기 때문에 마지막 scope의 값이 1이 되므로 network가 쌓였을 때 망칠 수 있는 요인이 되지 않음 )
- GPI 충족 (2 GPUs)
- 특정 입력 공간에서 response 많이 나오면 죽여버리는 Local Response Normalization, Overlapping Pooling
- Data augmentation
- Dropout (Neuron 중에서 몇 개 0으로 변환)
ReLu Activation
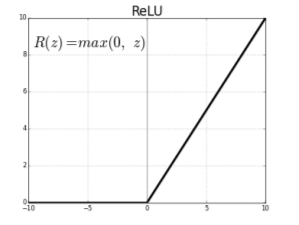
- linear model이 갖는 좋은 성질(gradient가 activation 값이 커도 gradient 값 그대로 가짐)들을 유지
- 학습에 용이함
- 좋은 Generalization
- Vanishing gradient problem 극복
- neuron의 값이 크면(0에서 많이 벗어나면) activation 기준하는 gradient slope가 0에 가까워지는 activation funciton 사용의 문제 발생하지 않게 됨
VGGNet

- 3x3 convolution filter로만 depth를 늘려간다
- fully connected layer들에게는 1x1 convolution을 사용함
- layer의 개수에 따라 VGG16, VGG19도 존재
왜 3x3 convolution?
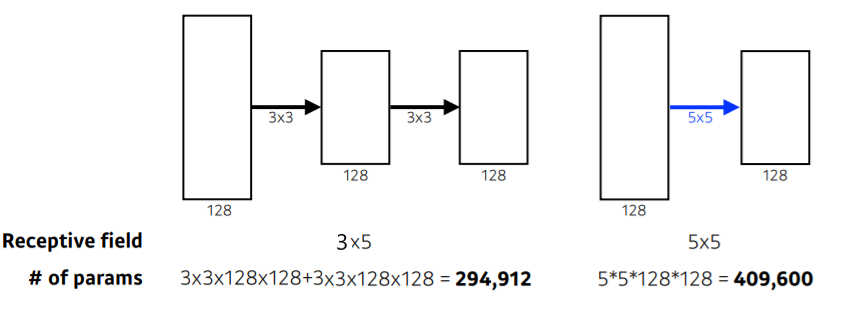
- 하나의 convolution feature map 값을 얻기 위해서 고려할 수 있는 입력의 spatial dimension을 나타내는 Receptive Field
- 3x3이 두 번 이뤄질 경우 receptive field는 5x5가 됨. 그러나 receptive field 차원에서는 3x3 쓰나 5x5 쓰나 똑같음
- Receptive Field는 각 단계의 입력 이미지에 대해 하나의 필터가 커버할 수 있는 이미지 영역의 일부 - layer를 두 개 쌓음으로써 parameter set가 2배로 늘어나게 되어 3x3과 5x5 사이 parameter 개수 차이가 1.5배정도 나게 됨
- 비교했을 때 5x5 = 25, 3x3+3x3=18로 3x3 두 개 사용하는 것이 parameter 개수를 더 줄일 수 있는 방법
GoogLeNet

- 비슷해보이는 network들의 반복 (Network In Network)
Inception Blocks

- 하나의 입력이 들어왔을 때 여러 개로 펼쳐졌다가 하나로 다시 합쳐짐
- 전체적인 network parameter의 개수를 줄여줌
- 하나의 입력에 대해 여러 개의 receptive field를 갖는 filter를 거치고, 이거를 통해 여러 개의 response들을 concatenate하는 효과를 가짐
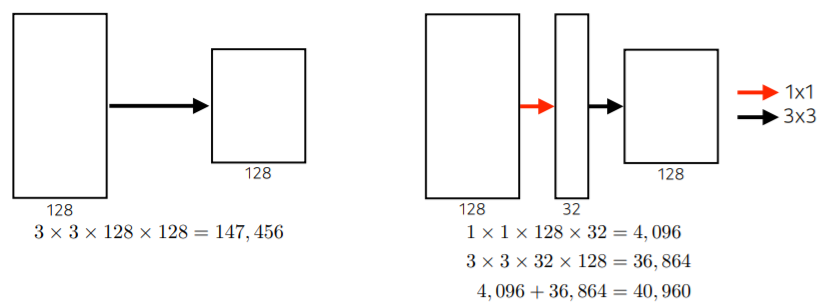
- convolution은 각각의 spatial 위치에 더해지는 convolution filter가 동일하기 때문에, paramter 숫자와 spatial dimension은 연관이 없음
- 3x3으로 충분히 parameter 줄였으나 더 줄이고 싶을 때 1x1 convolution 사용
- 1x1 convolution은 spatial dimension은 그대로 둔 상태로 channel 방향 정보를 줄임으로써 parameter 개수를 줄임
ResNet
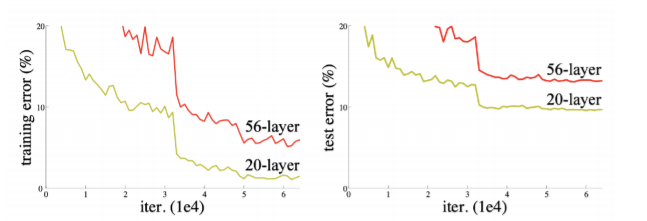
- Neural network가 깊어질수록 train하기 어려워진다
- training error와 test error 모두 줄어들긴 했으므로 overfitting은 아님
- Overfitting : trainig error가 줄어들지만 test error가 커지는 경우
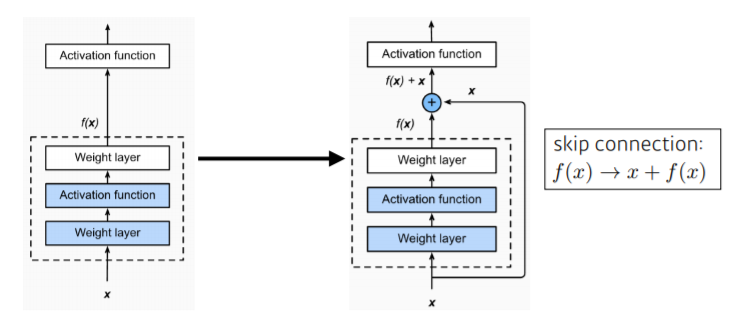
- input이 밑에서부터 위로 올라가는 identity map 추가
- 학습 layer가 학습하고자 하는 quantity는 residual(차이)만 학습하게 됨
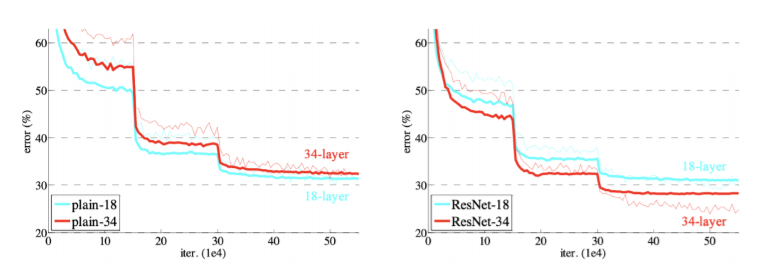
- 이전과 비교해 결과적으로 학습 자체를 더 잘 시킬 수 있게 됨
- network를 deep하게 더 쌓을 수 있는 가능성 보임
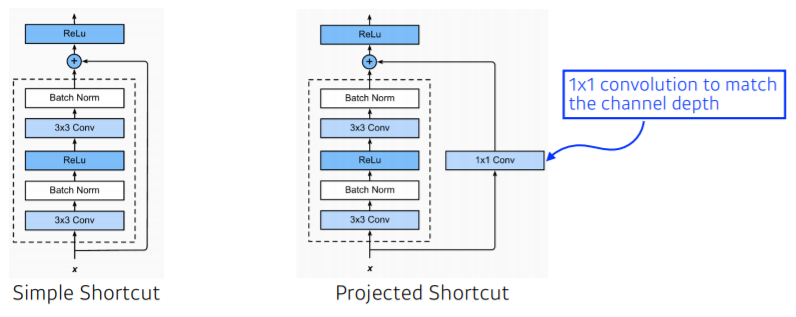
- identity map을 nonlinear activation 이후에 추가하고, batch normalization을 convolution 이후에 추가함
- 그 사이에 차원을 맞춰주기 위해 1x1 convolution 사용
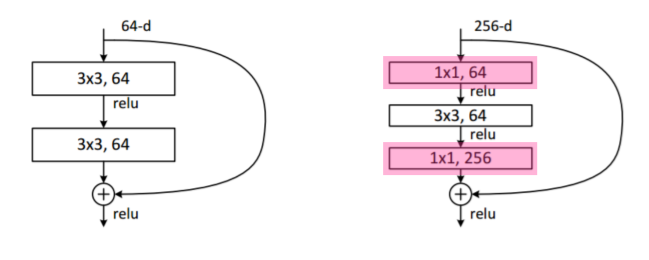
- 1x1 convolution으로 channel 줄이고
- 줄어든 channel에서 3x3(또는 5x5) convolution 수행함으로써 receptive field 키우고
- 다시 1x1 convolution으로 원하는 channel로 맞춰줌
- input channel 줄임으로써 전체적인 parameter 개수를 줄였다가 이후에 다시 늘림
- 최종적으로 bottleneck architecture 형태가 됨
- bottleneck layer : 이전 layer와 비교했을 때 더 적은 layer를 가지고 있는 것 - Dimension의 Reduction과 Expansion 효과로 연산 시간 감소 성능 얻어냄
- parameter 수 줄임과 동시에 network 깊게 쌓음으로써 depth(receptive field)를 늘이고자 함
PERFORMANCE INCREASES while PARAMETER SIZE DECREASES
DenseNet
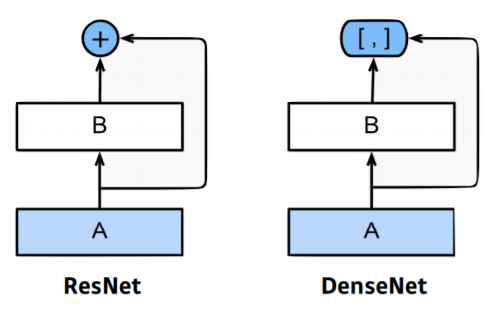
- ResNet과 다르게 DenseNet은 이미 channel과 spatial dimension이 같으므로 두 개의 값이 섞이는 addition 대신 concatenation을 사용

- concatenation 사용하기 때문에 channel이 점점 커짐
- 뒤에 있는 것은 앞에 있는 것 모두를 다 concatenate하기 때문에 기하급수적으로 커짐
- convolution의 feature map의 channel 크기와 parameter 개수도 같이 커짐

- Dense Block으로 feature map을 계속 키워서 convolution map을 키움
- 중간에 channel을 한 번씩 줄여줘야 함
- Transition Block으로 convolution feature map size를 줄임
- 1 → 2의 반복 수행
Summary
- VGG : 반복되는 3x3 block
- GoogLeNet : 1x1 convolution
- ResNet : skip-connection
- DenseNet : concatenation

세진니의 눈물 가득 블로그