
서울 코로나 확진 데이터분석
import pandas as pd
import numpy as np
import matplot.pyplot as plt
# !pip install koreanize-matplotlib
import koreanize_matplotlib
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'from grob import glob
glob("seoul*")
#서울 코로나 확진 파일
df_01 = pd.read_csv("seoul-covid19-2021-12-18.csv")
df_02 = pd.read_csv("seoul-covid19-2021-12-26.csv")데이터 합치기
df = pd.concat([df_01, df_02])
df.tail(2)
연번 환자 확진일 거주지 여행력 접촉력 퇴원현황
18644 200002 562971 2021-12-18 중구 - 기타 확진자 접촉 NaN
18645 200001 561831 2021-12-18 중구 - 기타 확진자 접촉 NaN
df.head(2)
연번 환자 확진일 거주지 여행력 접촉력 퇴원현황
0 200000 561465 2021-12-18 중구 - 기타 확진자 접촉 NaN
1 199999 562278 2021-12-18 구로구 - 구로구 소재 요양시설 관련('21.11.) NaN
중복 제거
df = df.drop_duplicates()
df.dropna().head(2)
연번 환자 확진일 거주지 여행력 접촉력 퇴원현황
15 199985 562335 2021-12-18 중구 - 기타 확진자 접촉 퇴원
21 199979 561753 2021-12-18 강서구 - 감염경로 조사중 퇴원
인덱스 값 설정
df["연번"].nunique()
# 인덱스 값 연번으로 변경
df = df.set_index("연번")
#인덱스 값 기준으로 정렬
df = df.sort_index(ascending=False)
df.head(2)
환자 확진일 거주지 여행력 접촉력 퇴원현황
연번
218646 611159 2021-12-26 노원구 - 감염경로 조사중 NaN
218645 610703 2021-12-26 노원구 - 감염경로 조사중 NaN
데이터 요약
df.info()
# 결측치
df.isnull()
# 평균을 통한 결측치 비율
df.isnull().mean() * 100#기술 통계값
df.describe()
환자
count 218646.000000
mean 322462.160977
std 173903.371149
min 2.000000
25% 168409.250000
50% 336181.500000
75% 470149.500000
max 611669.000000
df.descibe(include='object')
확진일 거주지 여행력 접촉력 퇴원현황
count 218646 218646 218646 218646 163497
unique 671 34 183 1417 2
top 2021-12-14 송파구 - 기타 확진자 접촉 퇴원
freq 3165 13235 215575 90055 161849
날짜 데이터 타입 변경
df['확진일'] = pd.to_datetime(df['확진일'])
df['확진일'].head(1)
연번
218646 2021-12-26
Name: 확진일, dtype: datetime64[ns]파생변수
연, 월, 일, 요일
df['연도'] = df['확진일'].dt.year
df["월"] = df["확진일"].dt.month
df["일"] = df["확진일"].dt.day
df["요일"] = df["확진일"].dt.dayofweek
df[["확진일", "연도", "월", "일", "요일"]].head(2)
확진일 연도 월 일 요일
연번
218646 2021-12-26 2021 12 26 6
218645 2021-12-26 2021 12 26 6
연도-월
df["연도월"] = df["연도"].astype(str) + "-" + df["월"].astype(str)
df[["확진일", "연도월"]].sample(3)
확진일 연도월
연번
60958 2021-07-23 2021-07
138937 2021-11-19 2021-11
96274 2021-09-25 2021-09요일
dayofweek = "월화수목금토일"
# 1) 함수 생성 후 사용
def find_dayofweek(day_no):
dayofweek = "월화수목금토일"
return dayofweek[day_no]
find_dayofweek(0)
=> '월"
df["요일명"] = df["요일"].map(find_dayofweek)
df[["요일", "요일명"]].sample(5)
# 2) 익명함수 사용
df["요일명"] = df["요일"].map(lambda x : "월화수목금토일"[x])
요일 요일명
연번
184969 6 일
6203 3 목
192890 2 수
94671 3 목
51890 0 월
수치 변수 히스토그램 시각화
df.hist(bins=50, figsize=(12,10));
빈도수 (value_counts)
df["연도"].value_counts()
2021 199253
2020 19393
Name: 연도, dtype: int64
# '연도' 컬럼의 비율 구하기
df['연도'].value_counts(normalize=True) * 100
2021 91.130412
2020 8.869588
Name: 연도, dtype: float64year_month = df['연도월'].value_counts().sort_index()
year_month
2020-01 7
2020-02 80
2020-03 391
2020-04 156
2020-05 229
2020-06 459
2020-07 281
2020-08 2415
2020-09 1306
2020-10 733
2020-11 2904
2020-12 10432
2021-01 4878
2021-02 4060
2021-03 3897
2021-04 5803
2021-05 6030
2021-06 6258
2021-07 14504
2021-08 15193
2021-09 21382
2021-10 18840
2021-11 36267
2021-12 62141
Name: 연도월, dtype: int64연도월 시각화
year_month.plot(kind='area', title='연도월 확진 수');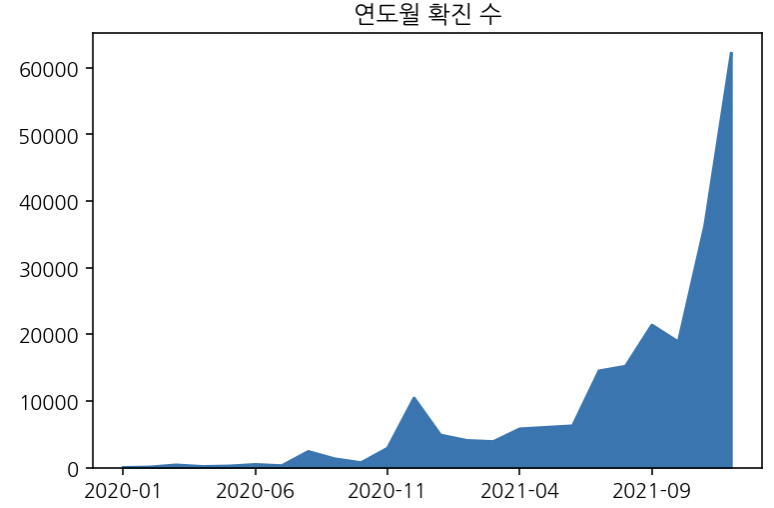
# 막대그래프
year_month.plot(kind="bar", title="연도월 확진 수");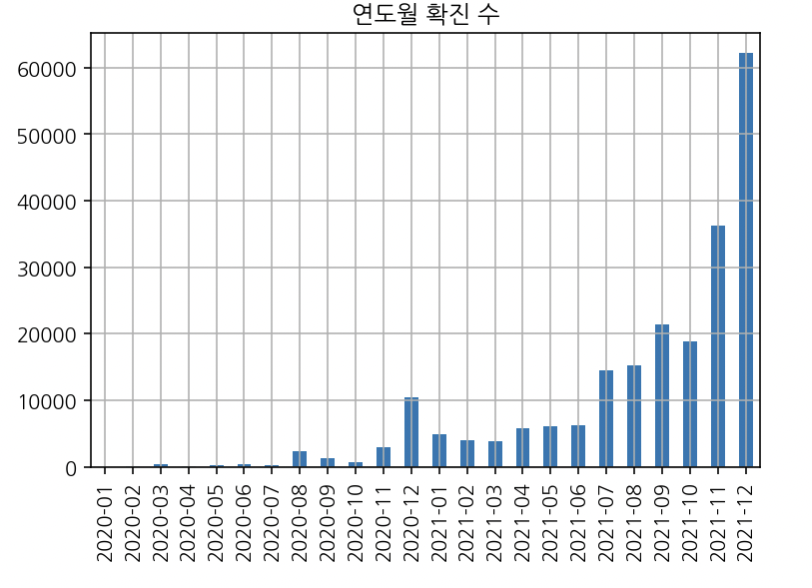
요일별 빈도수
weekday_count = df["요일"].value_counts().sort_index()
weekday_list = [i for i in "월화수목금토일"]
weekday_count.index = weekday_list
weekday_count.plot(kind='bar', rot=0, figsize=(10, 3), title='요일별 확진 수')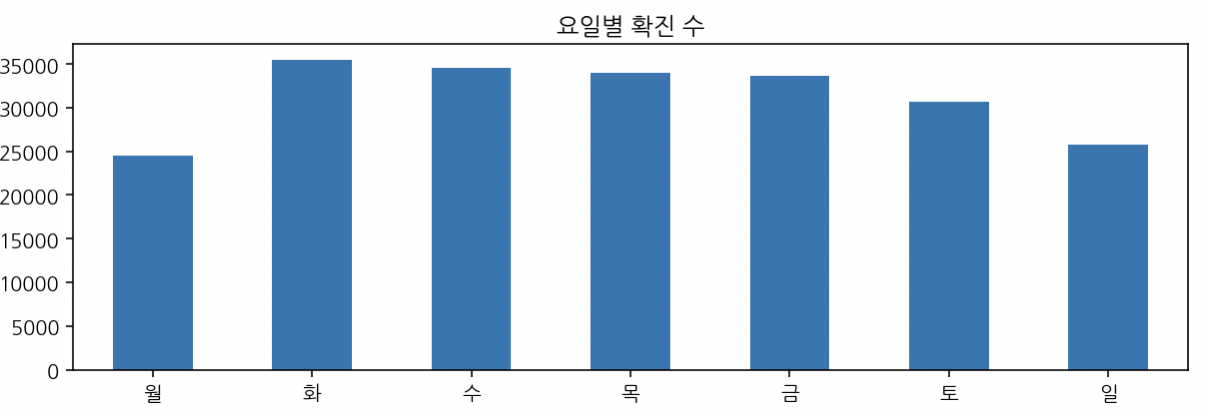
확진일 빈도수
day_count = df['확진일'].value_counts().sort_index()
day_count.plot(title="일자별 확진 수", figsize=(10, 3))
plt.axhline(1500, c="r", lw=0.1, ls="--")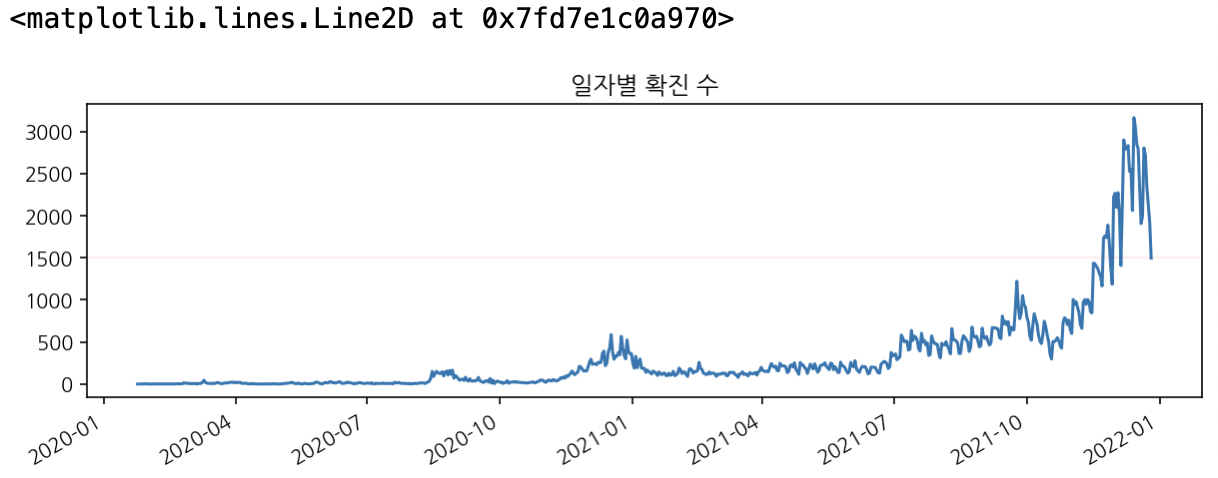
전체 확진일 데이터
day_count.index = day_count.index.astype(str)
day_count[:30].plot.bar(figsize=(10,2), rot=80)
day_count
2020-01-24 1
2020-01-30 3
2020-01-31 3
2020-02-02 1
2020-02-05 2
...
2021-12-22 2719
2021-12-23 2346
2021-12-24 2123
2021-12-25 1917
2021-12-26 1496
Name: 확진일, Length: 671, dtype: int64
첫 확진일, 마지막 확진일, 기간
last_day = df.iloc[0]["확진일"]
first_day = df.iloc[-1]["확진일"]
all_day = pd.date_range(start=first_day, end=last_day)
df_all_day = all_day.to_frame()
day_count
=>
2020-01-24 1
2020-01-30 3
2020-01-31 3
2020-02-02 1
2020-02-05 2
...
2021-12-22 2719
2021-12-23 2346
2021-12-24 2123
2021-12-25 1917
2021-12-26 1496
Name: 확진일, Length: 671, dtype: int64day_count.index = pd.to_datetime(day_count.index)
df_all_day['확진수'] = day_count
df_all_day
확진수 누적확진수
2020-01-24 NaN 1
2020-01-25 NaN 1
2020-01-26 NaN 1
2020-01-27 NaN 1
2020-01-28 NaN 1
... ... ...
2021-12-22 NaN 210764
2021-12-23 NaN 213110
2021-12-24 NaN 215233
2021-12-25 NaN 217150
2021-12-26 NaN 218646
# 0 컬럼 삭제
del df_all_day[0]결측치 채우기
df_all_day['확진수'] = df_all_day['확진수'].fillna(0).astype(int)
# 30개 데이터 슬라이싱
df_all_day[:30].plot(kind="bar", figsize=(10,3))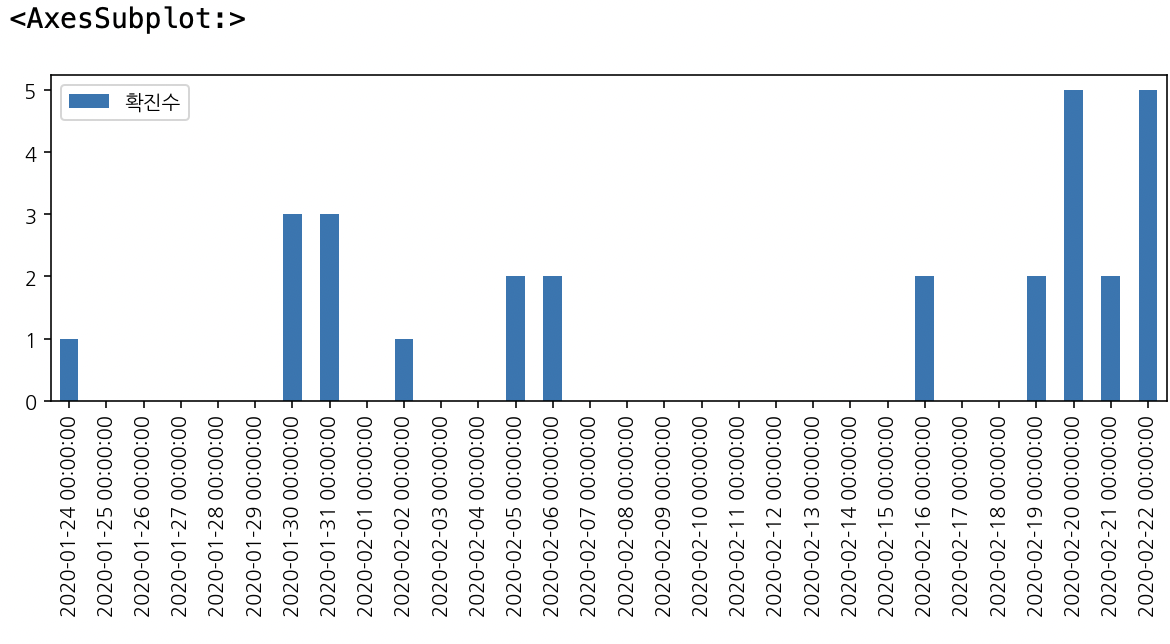
누적 확진 수
df_all_day['누적확진수'] = df_all_day['확진수'].cumsum()
df_all_day['누적확진수']
2020-01-24 1
2020-01-25 1
2020-01-26 1
2020-01-27 1
2020-01-28 1
...
2021-12-22 210764
2021-12-23 213110
2021-12-24 215233
2021-12-25 217150
2021-12-26 218646
Freq: D, Name: 누적확진수, Length: 703, dtype: int64누적 확진 수 시각화
df_all_day.plot(secondary_y="확진수", figsize=(10,3))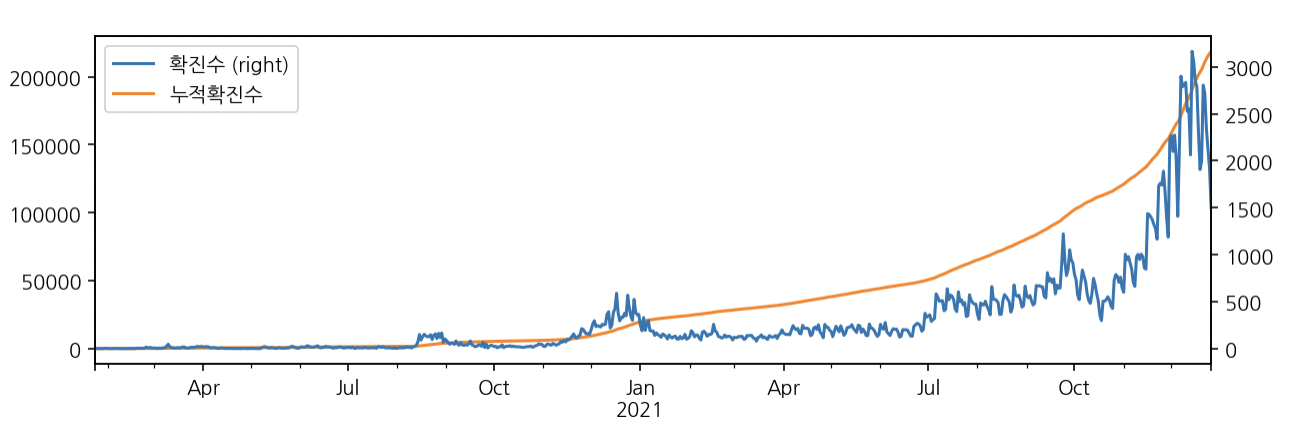
거주지
df_home = df["거주지"].value_counts()
df_home
송파구 13235
강남구 12150
타시도 11320
관악구 10992
구로구 10346
영등포구 10225
강서구 10150
은평구 9393
노원구 9327
성북구 9142
동대문구 9091
강동구 8882
동작구 8558
중랑구 8236
서초구 8087
양천구 7709
마포구 7370
광진구 6819
도봉구 6501
강북구 6449
서대문구 5946
금천구 5635
성동구 5530
용산구 5137
기타 4995
종로구 3838
중구 3570
양천구 5
용산구 2
동작구 2
강동구 1
마포구 1
금천구 1
타시도 1
Name: 거주지, dtype: int64df['거주구'] = df['거주지']
df['거주구'] = df['거주구'].str.strip()
df['거주구'].unique()
=>
array(['노원구', '송파구', '중랑구', '강북구', '성북구', '도봉구', '종로구', '영등포구', '타시도',
'금천구', '성동구', '관악구', '마포구', '은평구', '서초구', '중구', '광진구', '서대문구',
'강동구', '강서구', '용산구', '양천구', '강남구', '동대문구', '구로구', '동작구', '기타'],
dtype=object)# 타시도 -> 기타 변경
df['거주구'] = df['거주구'].str.replace('타시도', '기타')
# 거주구 빈도수
gu_count = df['거주구'].value_counts()
# 거주구 빈도수 시각화
gu_count.plot(kind='bar', figsize=(12,4), rot=70)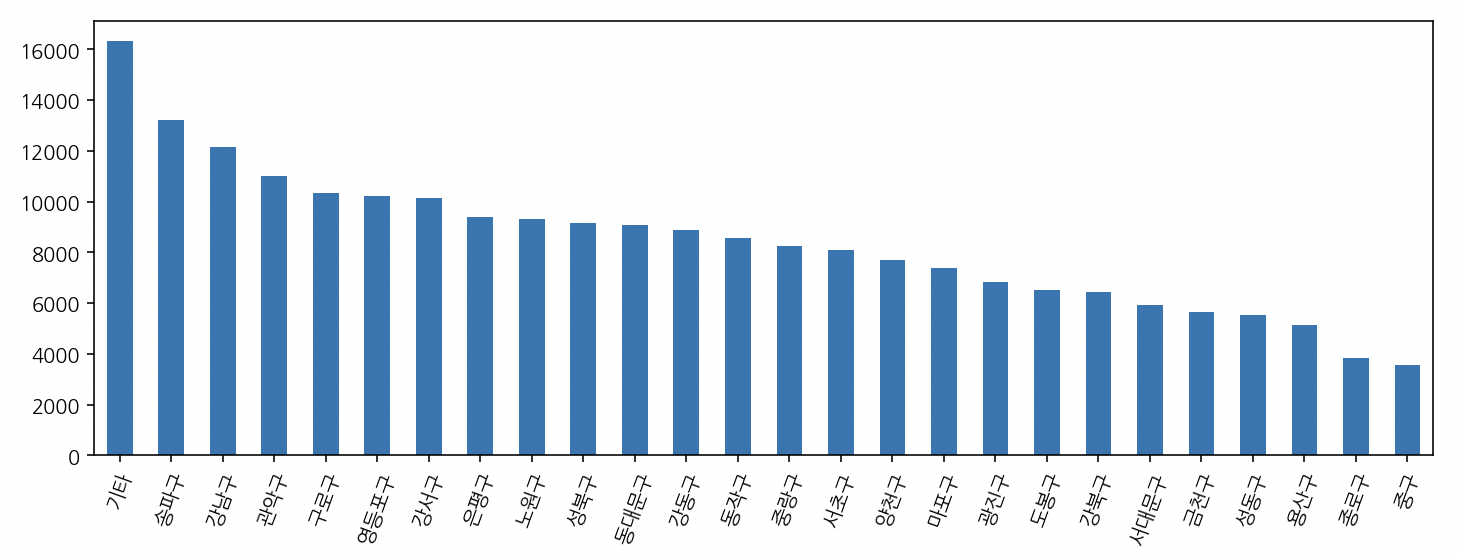
두 개의 변수 빈도수
연도, 퇴원현황 빈도수
pd.crosstab(index=df['연도'], columns=df['퇴원현황'])
퇴원현황 사망 퇴원
연도
2020 308 19085
2021 1340 142764# 빈도 비율
pd.crosstab(index=df['연도'], columns=df['퇴원현황'], normalize=True) * 100
퇴원현황 사망 퇴원
연도
2020 0.188383 11.672997
2021 0.819587 87.319033연도, 월 빈도수
ym = pd.crosstab(index=df['연도'], columns=df['월'])
ym.T.plot(kind='bar', row=0, figsize=(10,3))
연도, 요일 빈도수
yw = pd.crosstab(index=df['연도']. columns=df['요일'])
weekday_list = [day for day in "월화수목금토일"]
yw.columns = weekday_list
yw
월 화 수 목 금 토 일
연도
2020 2626 2896 2890 3462 2701 2676 2142
2021 21890 32575 31658 30568 30954 28016 23592
yw.T.plot(kind='bar', rot=0, figsize=(12,3))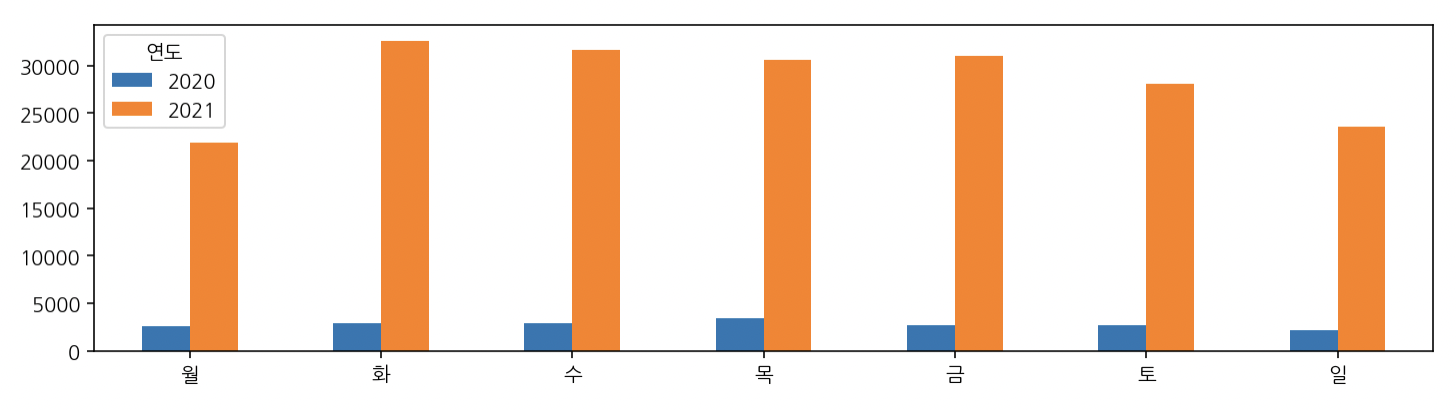
거주구, 연도월 빈도수
gu_ym = pd.crosstab(index=df['거주구'], columns=df['연도월'])
gu_ym.iloc[:5, :5]
연도월 2020-01 2020-02 2020-03 2020-04 2020-05
거주구
강남구 0 7 34 23 11
강동구 0 4 6 3 11
강북구 0 0 5 0 9
강서구 1 1 20 4 19
관악구 0 4 30 9 16
gu_ym.style.bar(cmap='BuPu')
indexing 이용한 조건 값 찾기
# 강남구에서 일요일 확진 데이터
df.loc[(df['거주구'] == '강남구') & (df['요일명'] == '일')][['확진일', '접촉력', '요일명']]
확진일 접촉력 요일명
연번
218406 2021-12-26 기타 확진자 접촉 일
218397 2021-12-26 기타 확진자 접촉 일
218382 2021-12-26 감염경로 조사중 일
218318 2021-12-26 기타 확진자 접촉 일
218315 2021-12-26 기타 확진자 접촉 일
... ... ... ...
430 2020-03-29 감염경로 조사중 일
429 2020-03-29 해외유입 일
428 2020-03-29 해외유입 일
126 2020-03-08 EZHLD 일
90 2020-03-01 감염경로 조사중 일# 거주지가 강남구이며 여행력이 일본인 데이터
df.loc[(df['거주구'] == '강남구') & (df['여행력'] == '일본'), ["접촉력", "요일명"]]
접촉력 요일명
연번
47099 해외유입 수
31135 감염경로 조사중 수
15746 해외유입 수
str.contains
# 접촉력에서 PC방 포함한 데이터 빈도수
df['접촉력_대문자'] = df['접촉력'].str.upper()
df.loc[df['접촉력_대문자'].str.contains("PC"), "접촉력"].value_counts()
용산구 소재 PC방 관련 82
강북구 소재 PC방 관련 35
강남구 소재 PC방 관련 32
강북구 소재 pc방 관련 23
동대문관련(교회pc방) 20
성동구 소재 PC방 관련 10
금천구 소재 PC방 관련 9
Name: 접촉력, dtype: int64isin
df.loc[df['거주구'].isin(['강남구', '서초구', '송파구']), '접촉력']
연번
218644 감염경로 조사중
218643 감염경로 조사중
218642 감염경로 조사중
218641 감염경로 조사중
218640 감염경로 조사중
...
31 타시도 확진자 접촉
30 타시도 확진자 접촉
26 타시도 확진자 접촉
23 타시도 확진자 접촉
9 해외유입
Name: 접촉력, Length: 33472, dtype: object
여행력
접촉력, 해외유입
df['접촉력'].str.contains('해외유입')
df.loc[df['접촉력'].str.contains('해외유입'), '해외유입'] = '해외'
df.loc[~df['접촉력'].str.contains('해외유입'), '해외유입'] = '국내'
df[['접촉력', '해외유입']].tail()
접촉력 해외유입
연번
5 기타 확진자 접촉 국내
4 해외유입 해외
3 종로구 집단발병 국내
2 해외유입 해외
1 해외유입 해외# 거주구, 해외유입 빈도수
gu_oversea = pd.crosstab(df['거주구'].df['해외유입'])
# 비율
gu_oversea['비율'] = (gu_oversea['해외'] / gu_oversea['국내']) * 100
gu_oversea.head()
해외유입 국내 해외 비율
거주구
강남구 11920 230 1.929530
강동구 8817 66 0.748554
강북구 6430 19 0.295490
강서구 10035 115 1.145989
관악구 10924 68 0.622483# 해외유입 막대그래프
gu_oversea.iloc[:, :2].plot(kind='bar', stacked=True, figsize=(12,3))
연도, 퇴원현황
pd.crosstab(df['연도'], df["퇴원현황"]. normalize=True) * 100
퇴원현황 사망 퇴원
연도
2020 0.188383 11.672997
2021 0.819587 87.319033y_count = pd.crosstab(df['연도']. df['퇴원현황'])
# 치사율 구하기
y_count['치사율'] = (y_count['사망'] / (y_count['퇴원'] + y_count['사망'])) * 100
y_count
퇴원현황 사망 퇴원 치사율
연도
2020 308 19085 1.588202
2021 1340 142764 0.929884pivot_table
거주구별 해외유입 여부 빈도수
gu_over_count = pd.pivot_table(data=df, index="거주구",
columns="해외유입",
values="환자",
aggfunc="count")
gu_over_count.head(3)
해외유입 국내 해외
거주구
강남구 11920 230
강동구 8817 66
강북구 6430 19 거주구별 요일 빈도수
weekday_list = list('월화수목금토일')
gu_weekday = pd.pivot_table(data=df, index="거주구",
columns="요일명",
values="환자",
aggfunc="count")
gu_weekday = gu_weekday[weekday_list]
gu_weekday.head(3)
요일명 월 화 수 목 금 토 일
거주구
강남구 1487 1969 1960 1791 1892 1626 1425
강동구 892 1510 1414 1392 1335 1300 1040
강북구 905 969 957 1031 939 881 767거주구에 따른 요일 빈도수 시각화
gu_weekday[weekday_list].style.bar()
groupby
거주구, 해외유입으로 그룹화 하여 환자 빈도수
df_group = df.groupby(by=['거주구', "해외유입"])["환자"].count()
df_group.head()
거주구 해외유입
강남구 국내 11920
해외 230
강동구 국내 8817
해외 66
강북구 국내 6430
Name: 환자, dtype: int64groupby의 unstack()
unstack() 마지막 인덱스를 컬럼으로 만든다.
df_group = df.groupby(by=['거주구', "해외유입"])["환자"].count().unstack()
df_group.head()
해외유입 국내 해외
거주구
강남구 11920 230
강동구 8817 66
강북구 6430 19
강서구 10035 115
관악구 10924 68df_group_m = df.groupby(by=['연도', '월'])[['환자']].count()
df_group_m.head()
환자
연도 월
2020 1 7
2 80
3 391
4 156
5 229df_group_m = df.groupby(by=['연도', '월'])['환자'].count().unstack()
df_group_m
월 1 2 3 4 5 6 7 8 9 10 11 12
연도
2020 7 80 391 156 229 459 281 2415 1306 733 2904 10432
2021 4878 4060 3897 5803 6030 6258 14504 15193 21382 18840 36267 62141
df_group_m = df.groupby(by=['연도', '월'])['해외유입'].describe()
df_group_m.head()
count unique top freq
연도 월
2020 1 7 2 국내 4
2 80 2 국내 71
3 391 2 국내 262
4 156 2 해외 111
5 229 2 국내 204
Ⓓ🅰️🅣🄰 ♡♥︎