
전국 아파트 분양가격 분석
- 형태가 다른 두 개의 데이터 전처리 후 병합
- 수치형 데이터와 범주형 데이터 처리
- 데이터 형식에 따른 시각화 차이
library 호출
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
# 한글 폰트
!pip install koreanize-matplotlib
import koreanize_matplotlib
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'최신 데이터 로드
from glob import glob
file_paths = glob("data/apt*.csv")
file_paths
['data/apt주택도시보증공사_전국 신규 민간아파트 분양가격 동향_20210930.csv',
'data/apt전국 평균 분양가격(2013년 9월부터 2015년 8월까지).csv']# 최근 데이터 파일 불러오기
df_last = pd.read_csv(file_paths[0], encoding="cp949")
df_last.head(2)
지역명 규모구분 연도 월 분양가격
0 서울 모든면적 2015 10 5841
1 서울 전용면적 60제곱미터이하 2015 10 5652'
df_last.tail(2)
지역명 규모구분 연도 월 분양가격
6118 제주 전용면적 85제곱미터초과 102제곱미터이하 2021 9 NaN
6119 제주 전용면적 102제곱미터초과 2021 9 7727이전 데이터 로드
df_first = pd.read_csv(file_paths[1], encoding="cp949")
df_first.head(2)
지역 2013년12월 2014년1월 2014년2월 2014년3월 2014년4월 2014년5월 2014년6월 2014년7월 2014년8월 ...
0 서울 18189 17925 17925 18016 18098 19446 18867 18742 19274 ...
1 부산 8111 8111 9078 8965 9402 9501 9453 9457 9411 ... 결측치 보기
df_last.isnull().sum()
지역명 0
규모구분 0
연도 0
월 0
분양가격 479
dtype: int64
# 결측치 시각화
sns.heatmap(df_last.isnull(), cmap="gray")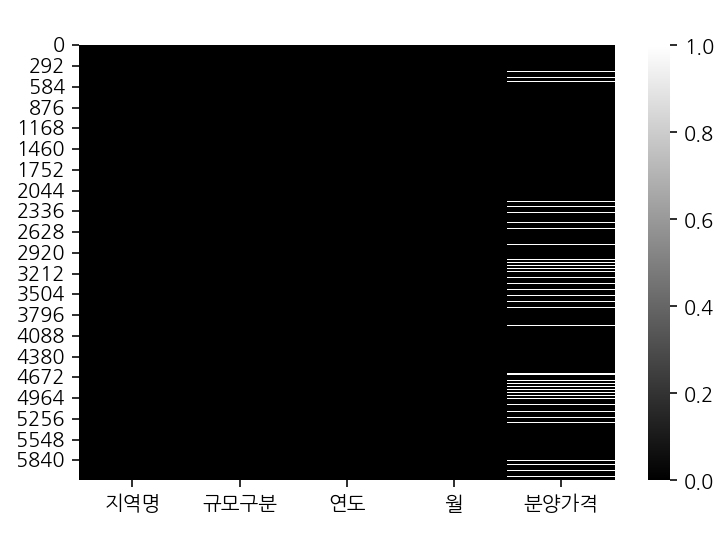
데이터 타입 변경
# 숫자를 제외한 문자를 빈문자로 변경하는 정규표현식
df_last['분양가격'] = df_last['분양가격'].str.replace("[^0-9]", "", regex=True)
# errors="coerce" : 문자가 포함되어 있으면 강제로 NaN 값으로 변경
df_last['분양가격'] = pd.to_numeric(df_last['분양가격'], errors="coerce")
df_last['분양가격'].describe()
count 5625.000000
mean 3459.317867
std 1411.776054
min 1868.000000
25% 2574.000000
50% 3067.000000
75% 3922.000000
max 13835.000000
Name: 분양가격, dtype: float64# 2013년 이후 데이터는 평당분양가격 기준
# 데이터를 맞춰주기 위해 평당분양가격 구하기
df_last['평당분양가격'] = df_last['분양가격'] * 3.3
df_last.head(2)
지역명 규모구분 연도 월 분양가격 평당분양가격
0 서울 모든면적 2015 10 5841.0 19275.3
1 서울 전용면적 60제곱미터이하 2015 10 5652.0 18651.6
# 규모구분을 전용면적으로 변경
df_last['규모구분'].unique()
=>
array(['모든면적', '전용면적 60제곱미터이하', '전용면적 60제곱미터초과 85제곱미터이하',
'전용면적 85제곱미터초과 102제곱미터이하', '전용면적 102제곱미터초과'], dtype=object)# 규모구분을 전용면적으로 변경
df_last["전용면적'] = df_last["규모구분"].str.replace("전용면적|제곱미터이하", "", regex=True)
df_last['전용면적'] = df_last['전용면적'].str.replace("제곱미터초과", "~")
df_last['전용면적'] = df_last['전용면적'].str.replace(" ", "")
df_last['전용면적']
0 모든면적
1 60
2 60~85
3 85~102
4 102~
...
6115 모든면적
6116 60
6117 60~85
6118 85~102
6119 102~
Name: 전용면적, Length: 6120, dtype: object# 필요없는 컬럼 제거
df_last = df_last.drop(columns=['규모구분', '분양가격'])
df_last.sample(3)
지역명 연도 월 평당분양가격 전용면적
2420 세종 2018 2 10431.3 모든면적
1572 세종 2017 4 8903.4 60~85
4186 대구 2019 11 14401.2 60수치데이터 시각화
df_last.hist(figsize=(10, 5), bins=50)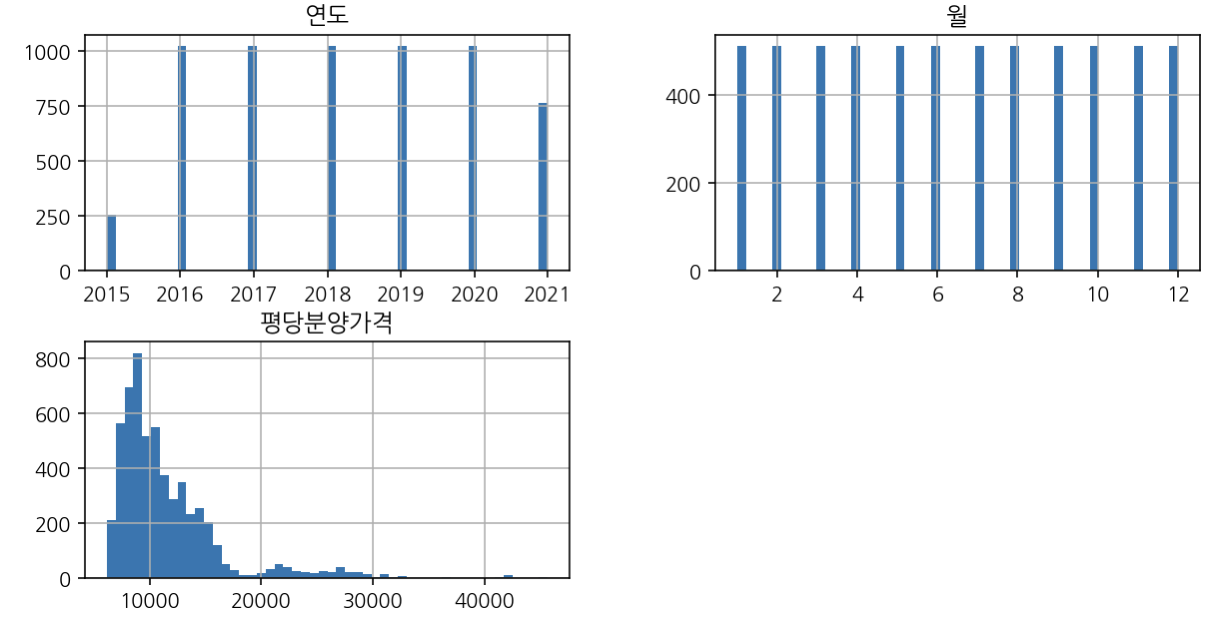
sns.pairplot(df_last, hue='지역명')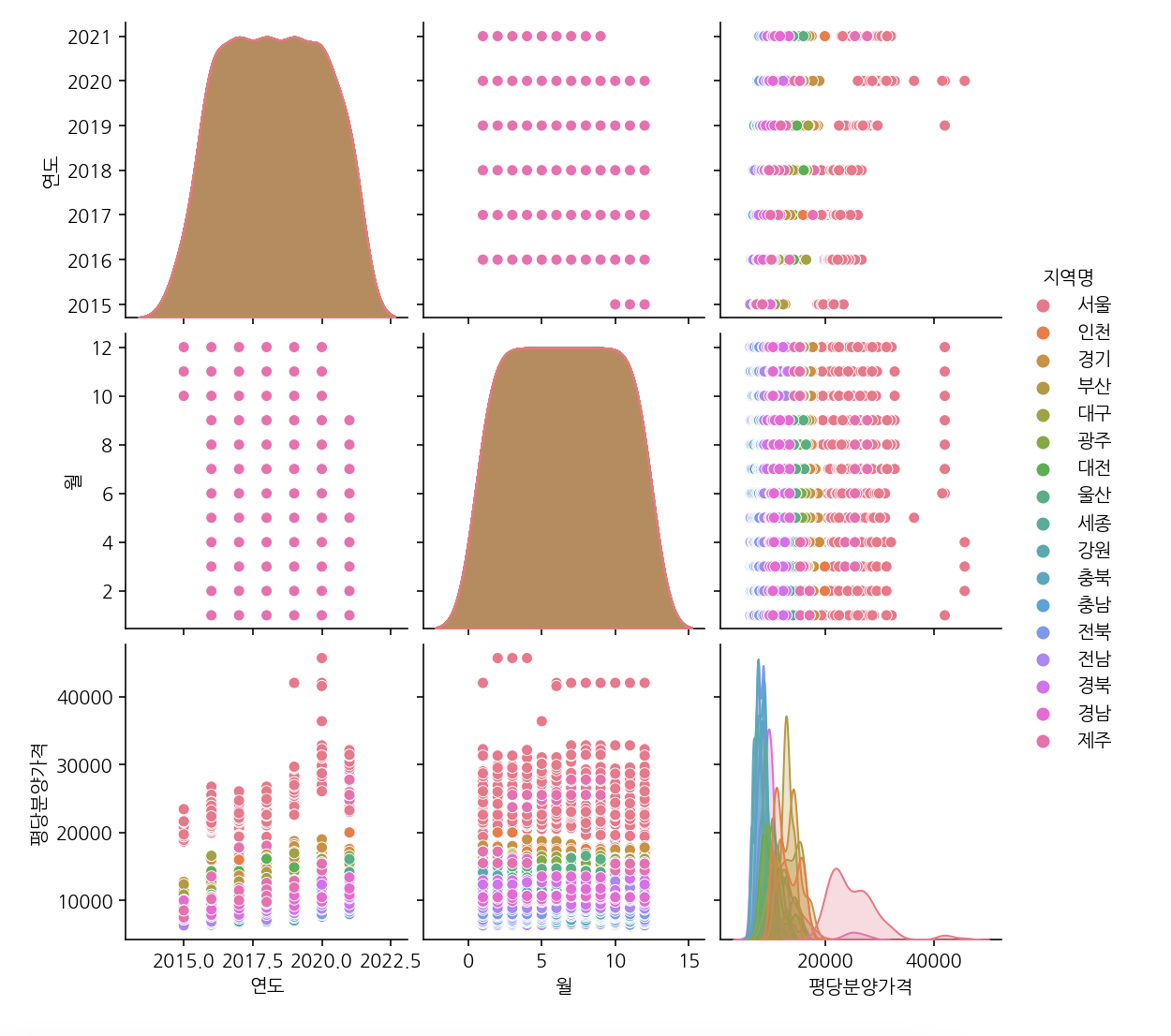
2015년 8월 이전 데이터
# 모든 컬럼 출력
pd.options.display.max_columns = None
df_first.head(1)
지역 2013년12월 2014년1월 2014년2월 2014년3월 2014년4월 2014년5월 2014년6월 2014년7월 2014년8월 2014년9월 2014년10월 2014년11월 2014년12월 2015년1월 2015년2월 2015년3월 2015년4월 2015년5월 2015년6월 2015년7월 2015년8월
0 서울 18189 17925 17925 18016 18098 19446 18867 18742 19274 19404 19759 20242 20269 20670 20670 19415 18842 18367 18374 18152 18443# 결측치 확인
df_first.isnull().sum().sum()
0melt로 Tidy data 만들기
df_first_melt = pd.melt(df_first, id_vals="지역")
df_first_melt.head(2)
지역명 기간 평당분양가격
0 서울 2013년12월 18189
1 부산 2013년12월 8111연도와 월 분리
data = df_first_melt['기간']
# 연도 분리 방법 (1)
df_first_melt['연도'] = df_first_melt['기간'].str.split("년", expand=True)[0].astype(int)
# 연도 분리 방법 (2)
df_first_melt['연도'] = df_first_melt['기간'].map(lambda x : int(x.split("년")[0]))
0 2013
1 2013
2 2013
3 2013
4 2013
... # 월 분리 방법 (1)
df_first_melt['월'] = df_first_melt['기간'].str.split("년", expand=True)[:-1].astype(int)
# 월 분리 방법 (2)
df_first_melt['월'] = df_first_melt[기간].map(lambda x : int(x.split("년")[1][:-1])
연도 월 분리 함수
def parse_year(date):
return int(date.split("년")[0])
def parse_month(date):
return int(date.split("년")[1][:-1])
df_first_melt["연도"] = df_first_melt['기간'].apply(parse_year)
df_first_melt['월'] = df_first_melt['기간'].apply(parse_month)df_last 와 df_first 컬럼명 동일화
df_first_melt.columns.tolist()
cols = ['지역명', '연도', '월', '평당분양가격']
# df_last와 병합하기 위해서는 컬럼명이 같아야함
# df_first 데이터에는 df_last['전용면적']이 없으니까 모든면적 값으로 통일
df_last_prepare = df_last.loc[df_last['전용면적'] == '모든면적', cols]
df_last_prepare.head(2)
지역명 연도 월 평당분양가격
0 서울 2013 12 18189
1 부산 2013 12 8111
------------------------------------------
df_first_prepare = df_first_melt[cols]
df_first_prepare.head(2)
지역명 연도 월 평당분양가격
0 서울 2013 12 18189
1 부산 2013 12 8111concat()
df = pd.concat([df_first_prepare, df_last_prepare])
df.head(2)
지역명 연도 월 평당분양가격
0 서울 2013 12 18189.0
1 부산 2013 12 8111.0
-------------------------------
df.tail(2)
지역명 연도 월 평당분양가격
6110 경남 2021 9 10873.5
6115 제주 2021 9 27574.8
# 연도별 데이터 빈도수
df['연도'].value_counts().sort_index()
2013 17
2014 204
2015 187
2016 204
2017 204
2018 204
2019 204
2020 204
2021 153
Name: 연도, dtype: int64groupby 데이터 집계
avg = df.groupby(by=['지역명'])['평당분양가격'].mean()
avg.sort_values(ascending=False).plot(kind='bar',
rot=0, figsize=(10, 2),
title="2013~ 평균 평댱 분양가격")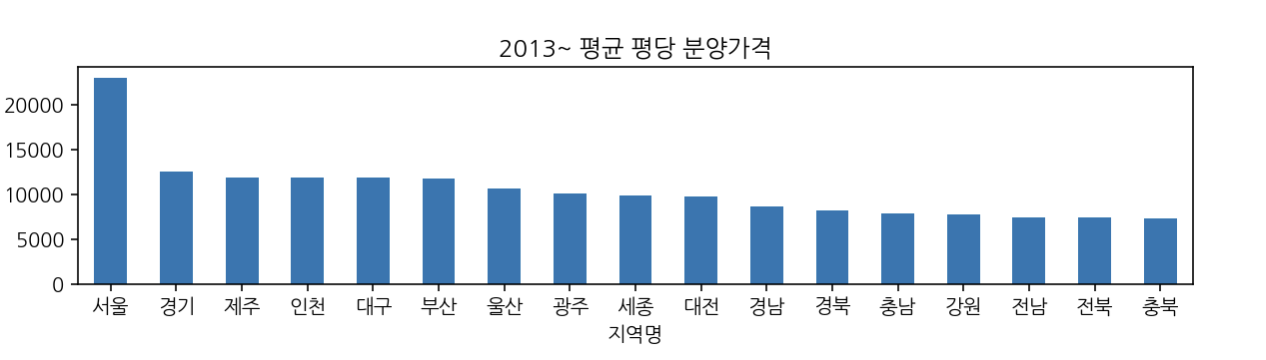
y_local = df.groupby(by=['연도', '지역명'])['평당분양가격'].mean().unstack()
y_local.plot()
plt.legend(bbox_to_anchor=(1, 1))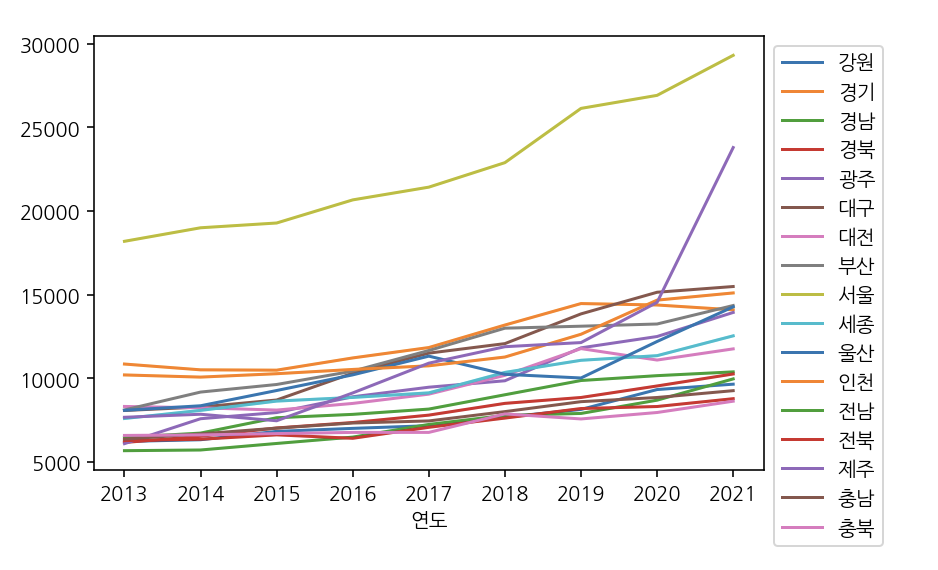
y_local[['서울', '경기', '인천', '제주']].plot(figsize=(10, 2))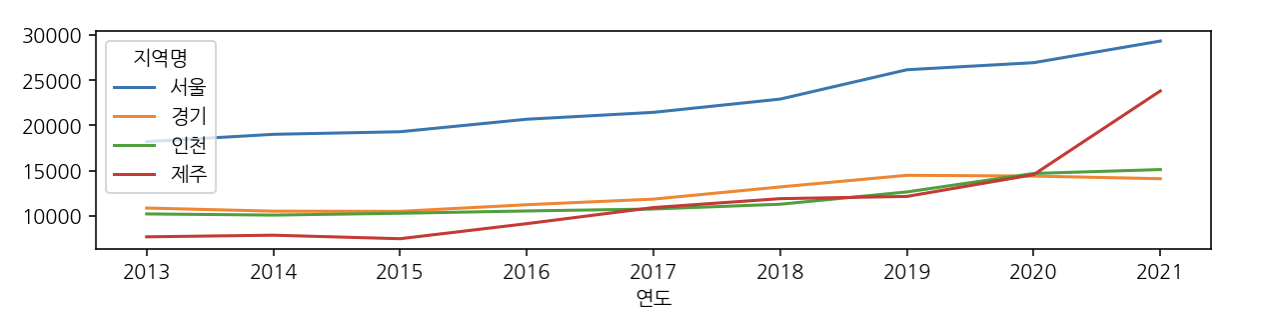
pivot_table
pd.pivot_table(data=df, index="지역명", values='평당분양가격').plot(kind='bar', figsize=(10,2), rot=0)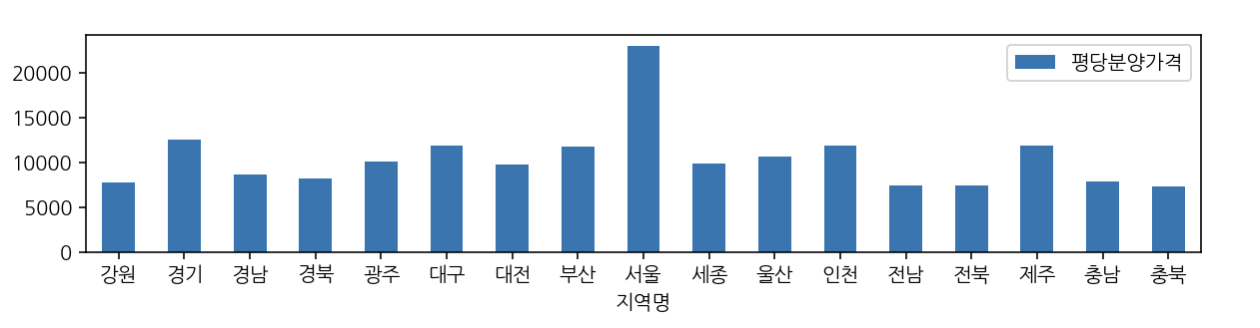
y_local = pd.pivot_table(data=df, index="연도", columns="지역명", values="평당분양가격")
plt.figure(figsize=(15, 5))
sns.heatmap(y_local.T, annot=True, fmt=",.0f", cmap="BuPu")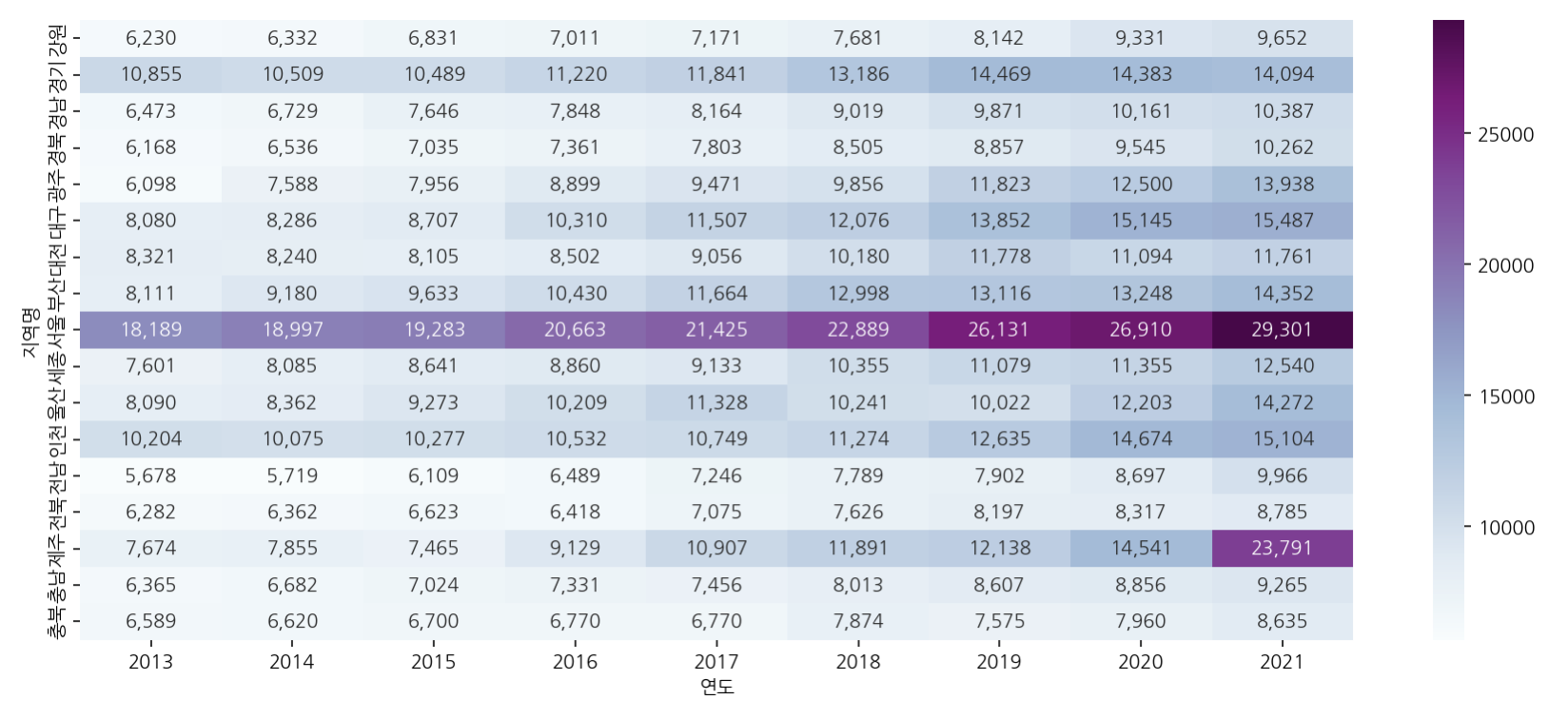
데이터 시각화
# 연도별 평당분양가격
plt.figure(figsize=(10, 3))
sns.barplot(data=df, x="연도", y="평당분양가격", ci=None)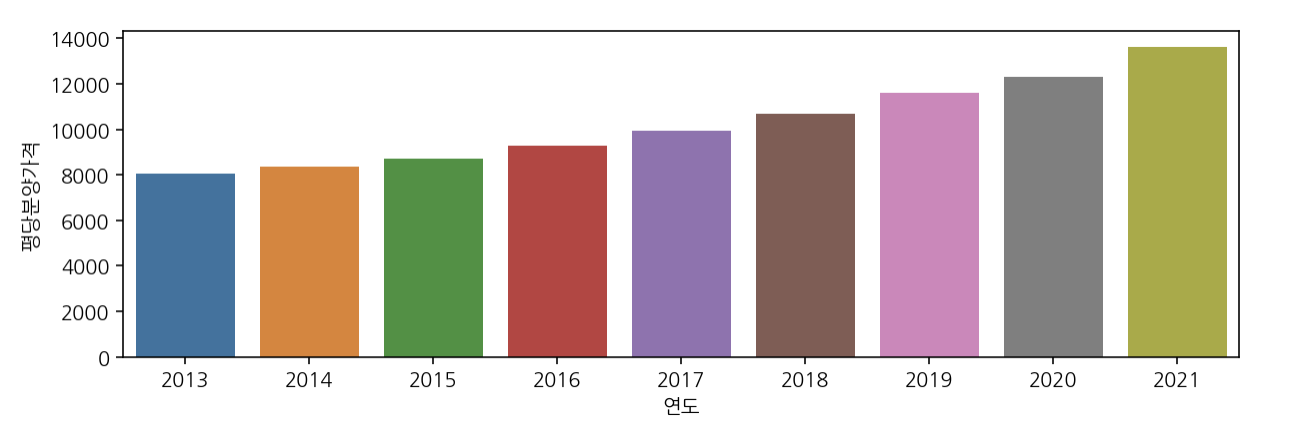
# 지역별 평당분양가격
local_table = pd.pivot_table(data=df, index="지역명", values="평당분양가격).sort_values(
'평당분양가격', ascending=False)
plt.figure(figsize=(10, 3))
sns.barplot(data=local_table, x=local_table.index, y='평당분양가격')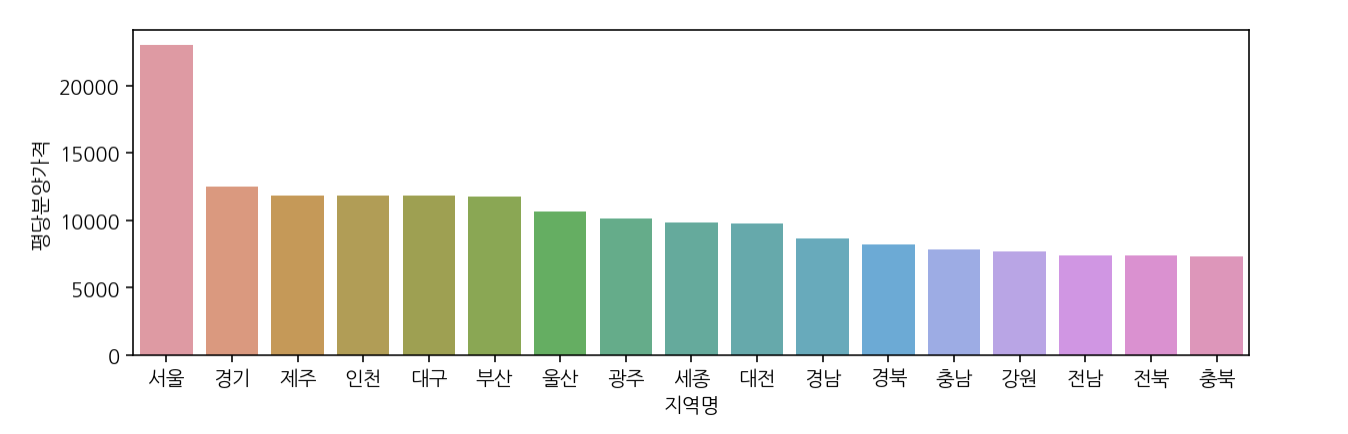
# catplot
sns.catplot(data=df, x='연도', y='평당분양가격', col='지역명',
col_wrap=4, kind='point',
hue='지역명', ci=None)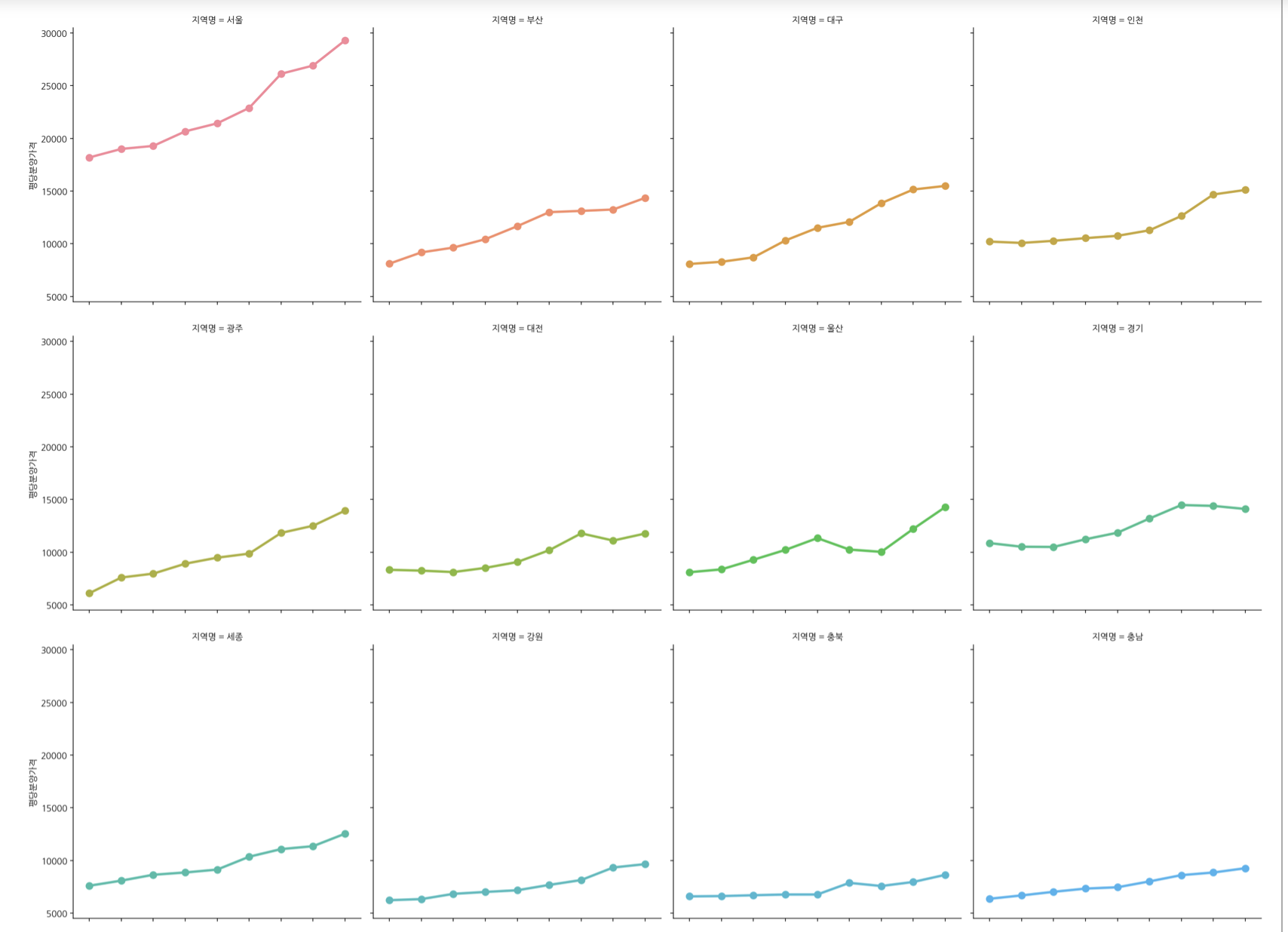

Ⓓ🅰️🅣🄰 ♡♥︎