
국가 & 권역별 전산업 소재부품 장비 산업별 수출, 수입
라이브러리 import
import pandas as pd
import numpy as np
import seaborn as sns
import plotly.express as px
import matplotlib.pyplot as plt
# 한글폰트 사용을 위해 설치
!pip install koreanize-matplotlib
import koreanize_matplotlib
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'파일 불러오기
from glob import glob
file_name = glob('data/kosis*.csv')[0]
raw = pd.read_csv(file_name, encoding='cp949')
raw.head(2)
국가및권역별 전산업·소재부품장비산업별 항목 단위 2012.01 월 2012.02 월 2012.03 월 2012.04 월 2012.05 월 2012.06 월 ... 2021.11 월 2021.12 월 2022.01 월 2022.02 월 2022.03 월 2022.04 월 2022.05 월 2022.06 월 2022.07 월 Unnamed: 131
0 아시아 전산업 수출액[$] $ 23745190192 25861715382 27042203441 24836676895 26371848084 26499484039 ... 36346715452 37023197693 32765720364 32142243305 38202799098 33731657051 35060245380 33257938412 34407442491 NaN
1 아시아 전산업 수입액[$] $ 18220312420 18433708853 19946987738 18971147138 18423759290 18244097495 ... 27607486829 28970294456 28015516969 24779680062 29877276004 28088134473 29513619417 29156633254 28277360345 NaN
2 rows × 132 columnsraw.shape
(208, 132)
raw.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 208 entries, 0 to 207
Columns: 132 entries, 국가및권역별 to Unnamed: 131
dtypes: float64(1), int64(127), object(4)
memory usage: 214.6+ KB결측치
raw.isnull().sum().sum()
sns.heatmap(raw.isnull(), cmap="Greys")
melt() 이용한 Tidy data
raw.columns()
Index(['국가및권역별', '전산업·소재부품장비산업별', '항목', '단위', '2012.01 월', '2012.02 월',
'2012.03 월', '2012.04 월', '2012.05 월', '2012.06 월',
...
'2021.11 월', '2021.12 월', '2022.01 월', '2022.02 월', '2022.03 월',
'2022.04 월', '2022.05 월', '2022.06 월', '2022.07 월', 'Unnamed: 131'],
dtype='object', length=132)
df = raw.melt(id_vars=raw.columns[:4], var_name="연월", value_name="달러")
df.shape
(26624, 6)df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 26624 entries, 0 to 26623
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 국가및권역별 26624 non-null object
1 전산업·소재부품장비산업별 26624 non-null object
2 항목 26624 non-null object
3 단위 26624 non-null object
4 variable 26624 non-null object
5 value 26416 non-null float64
dtypes: float64(1), object(5)
memory usage: 1.2+ MBdf.head()
국가및권역별 전산업·소재부품장비산업별 항목 단위 연월 달러
0 아시아 전산업 수출액[$] $ 2012.01 월 2.374519e+10
1 아시아 전산업 수입액[$] $ 2012.01 월 1.822031e+10
2 아시아 소재·부품·장비산업 수출액[$] $ 2012.01 월 1.387728e+10
3 아시아 소재·부품·장비산업 수입액[$] $ 2012.01 월 1.011782e+10
4 일본 전산업 수출액[$] $ 2012.01 월 3.270842e+09
# 결측치 제거
df = df.dropna()
df.shape
(26416, 6)텍스트 전처리
정규표현식
# 항목에서 액[$] 제거 -방법 (1)
df['항목'] = df['항목'].str.replace('[액\[\$\]]', "", regex=True)
# -방법 (2)
df['항목'].str.replace("액[$]", "", regex=False)
# -방법 (3)
df['항목'] = df['항목'].str.replace('[^수입출]', "", regex=True).head(2)
0 수출
1 수입
Name: 항목, dtype: object
# 연월에서 월 제거
# 방법(1)
df['연월'] = df['연월'].str.replace('월', '').str.strip()
# 방법(2)
df['연월'].str.split(".", expand=True)[0].astype(int).iloc[0]
df['연월'].str.split(".", expand=True)[1].astype(int).iloc[0]
# 방법(3)
df['연월'].str.split(".").str[0].astype(int)
df['연월'].str.split(".").str[1].astype(int)# 연, 월 파생변수
df['연'] = df['연월'].map(lambda x : int(x.split(".")[0]))
df['월'] = df['연월'].map(lambda x : int(x.split(".")[1]))
df.sample(3)
국가및권역별 전산업·소재부품장비산업별 항목 단위 연월 달러 연 월
12858 남아프리카공화국 소재·부품·장비산업 수출 $ 2017.02 2.386921e+07 2017 2
9410 중동 소재·부품·장비산업 수출 $ 2015.10 1.046140e+09 2015 10
4867 영국 소재·부품·장비산업 수입 $ 2013.12 2.237594e+08 2013 12컬럼명 변경
df.columns
Index(['국가및권역별', '전산업·소재부품장비산업별', '항목', '단위', '연월', '달러', '연', '월'], dtype='object')
df = df.rename(columns={'국가및권역별': '국가권역', '전산업·소재부품장비산업별':'산업'})
df.head(2)
국가권역 산업 항목 단위 연월 달러 연 월
0 아시아 전산업 수출 $ 2012.01 2.374519e+10 2012 1
1 아시아 전산업 수입 $ 2012.01 1.822031e+10 2012 1기술통계
df.describe()
달러 연 월
count 2.641600e+04 26416.000000 26416.000000
mean 2.285932e+09 2016.803150 6.362205
std 4.809561e+09 3.061218 3.436024
min 1.623000e+03 2012.000000 1.000000
25% 1.133350e+08 2014.000000 3.000000
50% 3.995205e+08 2017.000000 6.000000
75% 1.801346e+09 2019.000000 9.000000
max 3.820280e+10 2022.000000 12.000000df.describe(include="O")
국가권역 산업 항목 단위 연월
count 26416 26416 26416 26416 26416
unique 52 2 2 1 127
top 아시아 전산업 수출 $ 2012.01
freq 508 13208 13208 26416 208
df.hist(figsize=(12, 5), bins=30);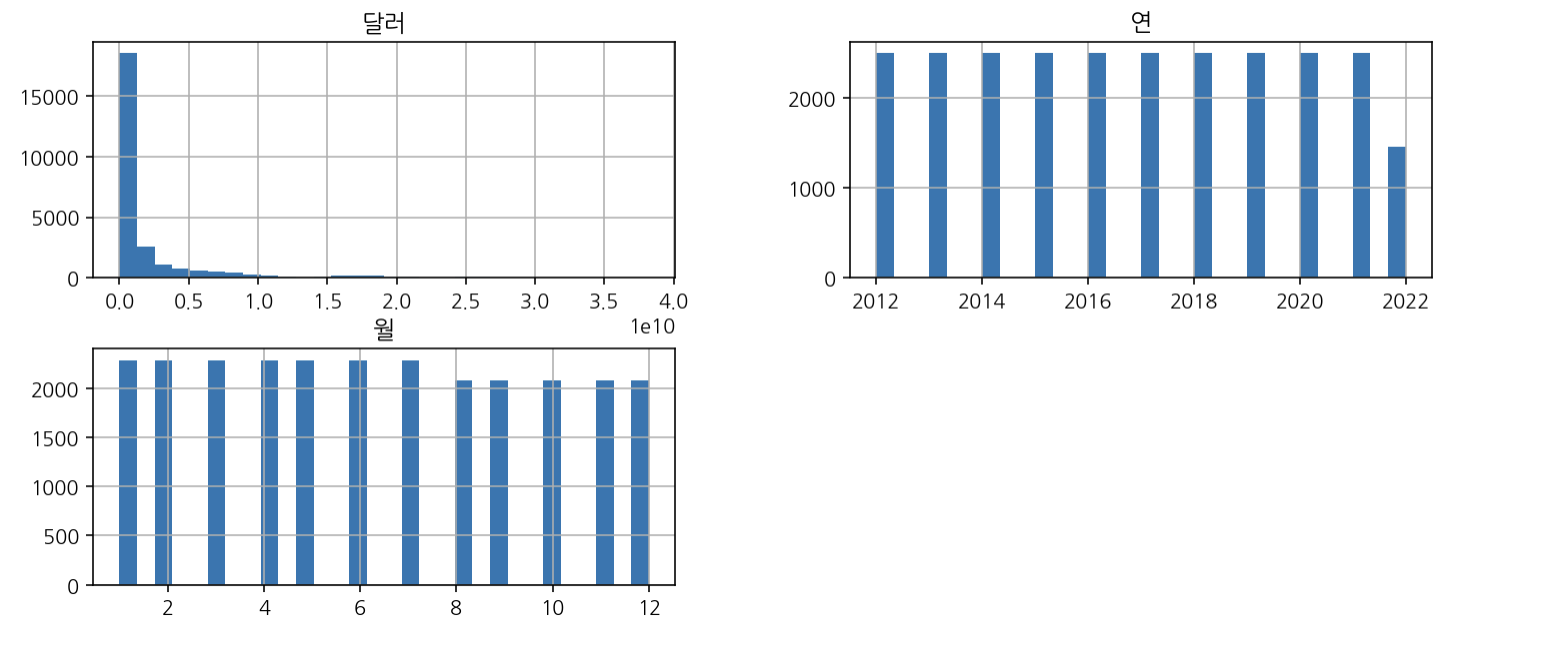
국가권역
df['국가권역'].unique()
array(['아시아', '일본', '대만', '필리핀', '홍콩', '말레이지아', '싱가포르', '인도네시아', '태국',
'인도', '베트남', '중국', '중동', '사우디아라비아', '아랍에미리트', '유럽', '프랑스', '이탈리아',
'독일', '네덜란드', '영국', '벨기에', '스페인', '스위스', '오스트리아', '노르웨이', '스웨덴',
'핀란드', '폴란드', '체코공화국', '루마니아', '불가리아', '러시아', '북미', '캐나다', '미국',
'중남미', '멕시코', '아르헨티나', '칠레', '브라질', '아프리카', '남아프리카공화국', '오세아니아',
'기타지역', 'EU(27)', 'OECD', 'ASEAN', 'LAIA', '선진국', 'OPEC', '개발도상국'],
dtype=object)world = ['아시아', '중동', '유럽', '북미',
'중남미', '아프리카','오세아니아',
'기타지역', 'EU(27)', 'OECD',
'ASEAN', 'LAIA', '선진국', 'OPEC', '개발도상국']
df_world = df[df['국가권역'].isin(world)]
df_country = df[~df['국가권역'].isin(world)]df_world['국가권역'].unique()
array(['아시아', '중동', '유럽', '북미', '중남미', '아프리카', '오세아니아', '기타지역', 'EU(27)',
'OECD', 'ASEAN', 'LAIA', '선진국', 'OPEC', '개발도상국'], dtype=object)
-------------------------------------------------
df_country["국가권역"].unique()
array(['일본', '대만', '필리핀', '홍콩', '말레이지아', '싱가포르', '인도네시아', '태국', '인도',
'베트남', '중국', '사우디아라비아', '아랍에미리트', '프랑스', '이탈리아', '독일', '네덜란드',
'영국', '벨기에', '스페인', '스위스', '오스트리아', '노르웨이', '스웨덴', '핀란드', '폴란드',
'체코공화국', '루마니아', '불가리아', '러시아', '캐나다', '미국', '멕시코', '아르헨티나', '칠레',
'브라질', '남아프리카공화국'], dtype=object)# 국가권역 달러 합계 금액 상위 20개
top_20 = df_country.groupby(['국가권역'])['달러'].sum().nlargest(20)
top_20
국가권역
중국 4.249903e+12
미국 1.947230e+12
일본 1.423401e+12
베트남 9.151544e+11
대만 6.289901e+11
홍콩 5.841850e+11
독일 4.690268e+11
싱가포르 3.971087e+11
사우디아라비아 3.786500e+11
인도 3.352609e+11
말레이지아 2.912736e+11
인도네시아 2.745638e+11
러시아 2.708896e+11
멕시코 2.453923e+11
태국 2.186187e+11
필리핀 2.171541e+11
아랍에미리트 2.024930e+11
네덜란드 1.766564e+11
영국 1.693959e+11
브라질 1.677749e+11
Name: 달러, dtype: float64시각화
px.histogram(df_country, x='달러', y='국가권역', histfunc='sum')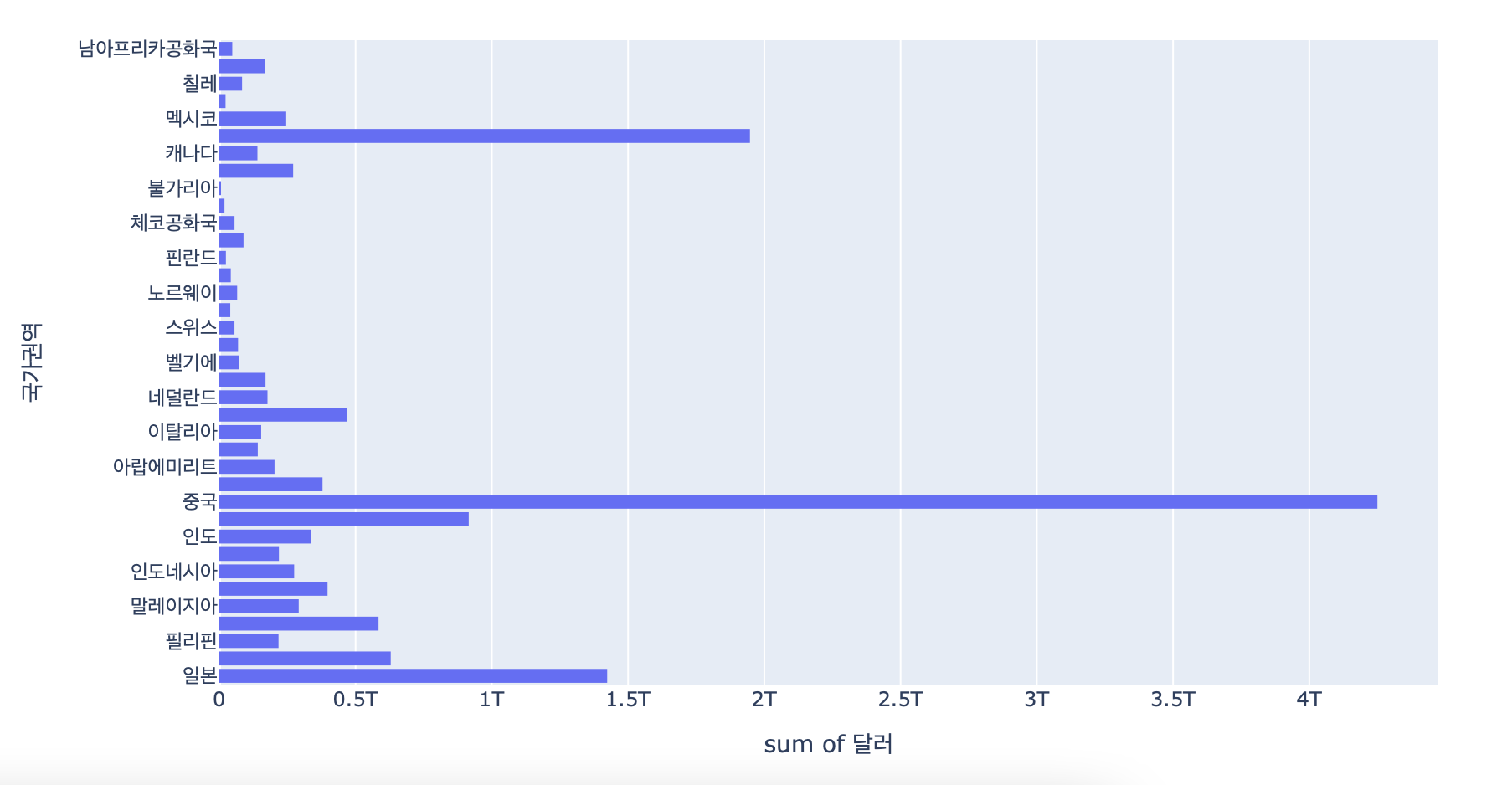
px.histogram(df_country, x='달러', y='국가권역', histfunc='sum', color='항목')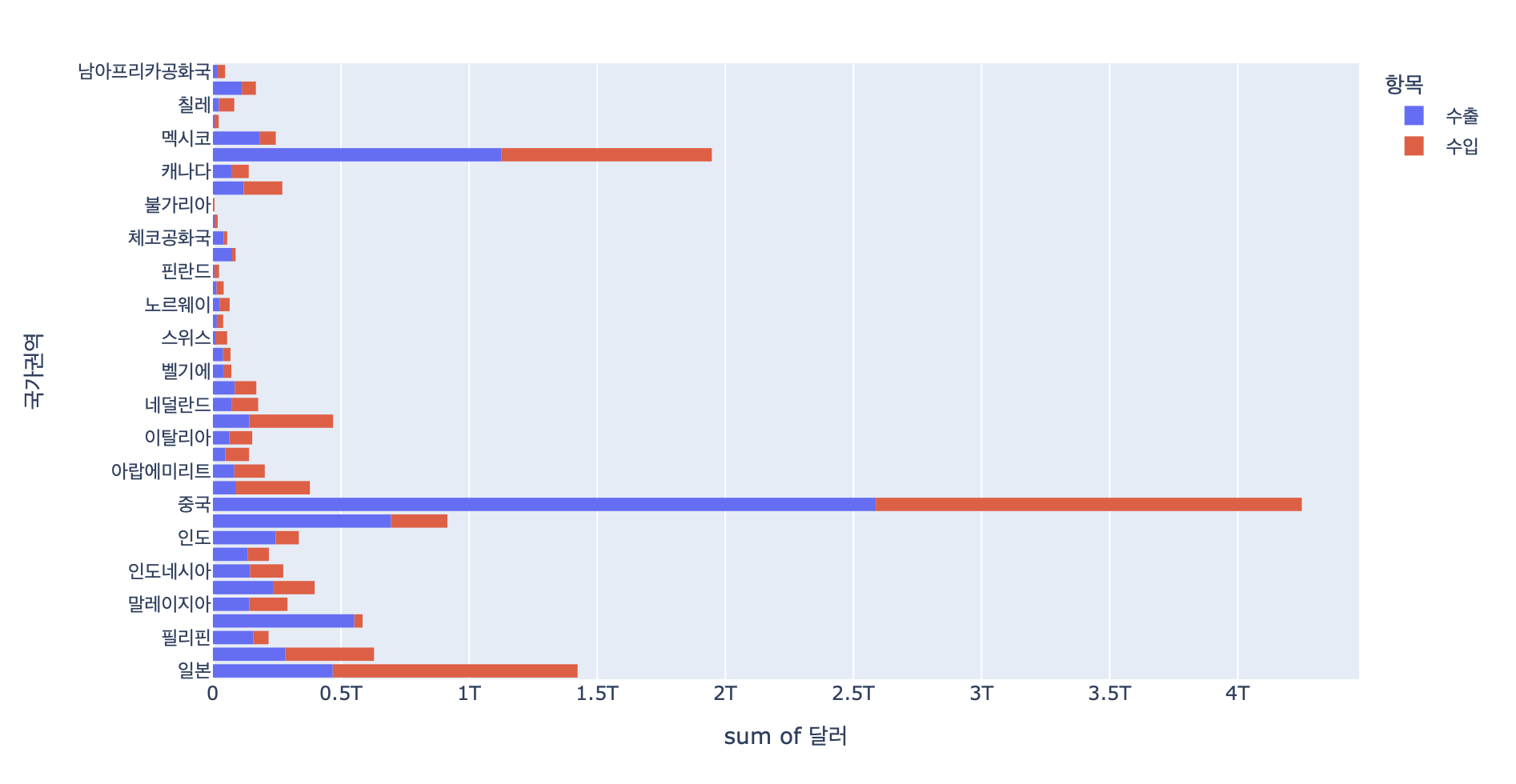
px.histogram(df_country, x='달러', y='국가권역', histfunc='sum', color='항목',
facet_col='산업')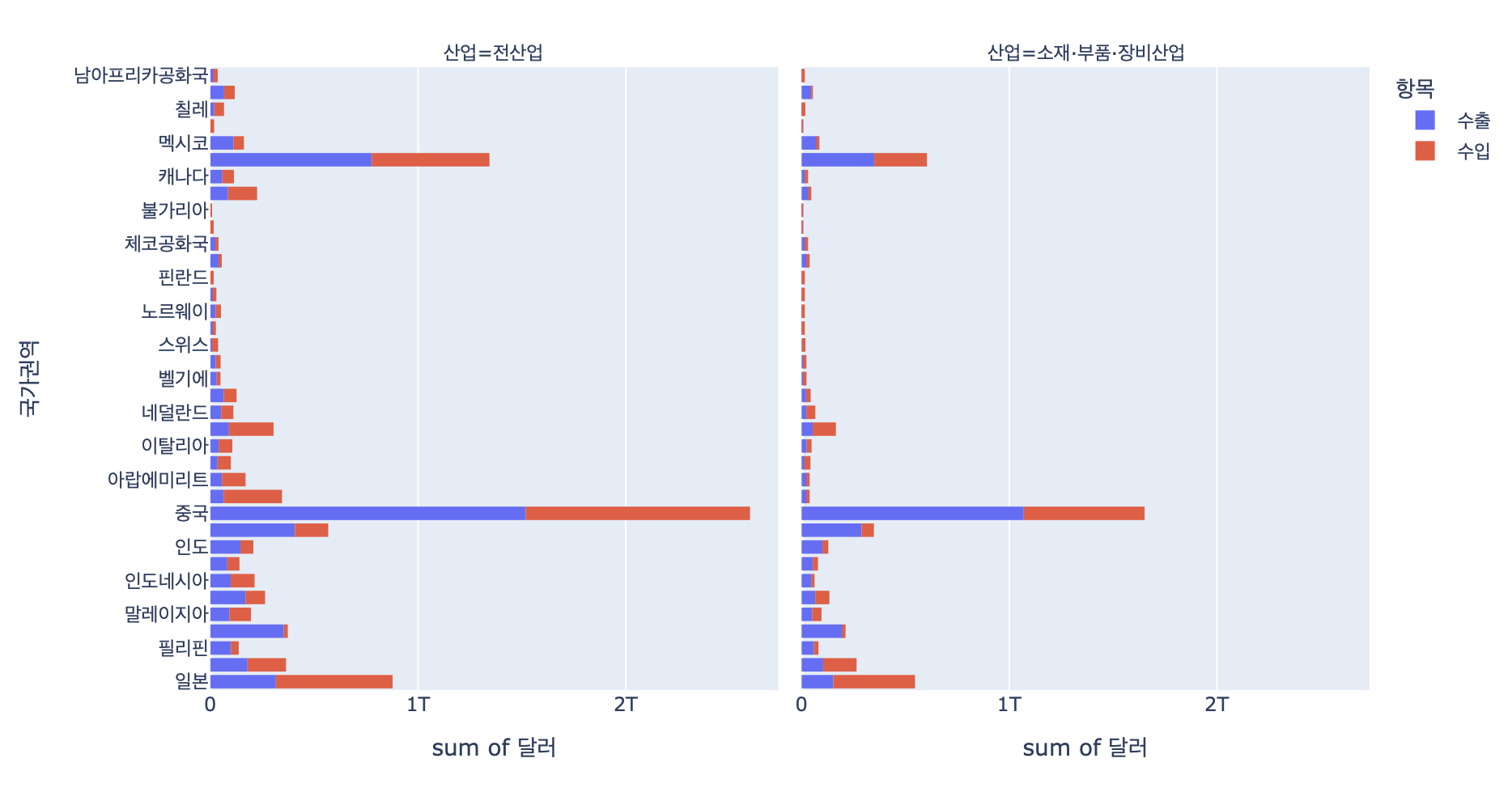
sns.catplot(data=df_country, x='연', y='달러', hue='항목', col='산업',
estimator=np.sum, col_wrap=2, kind='bar', ci=None)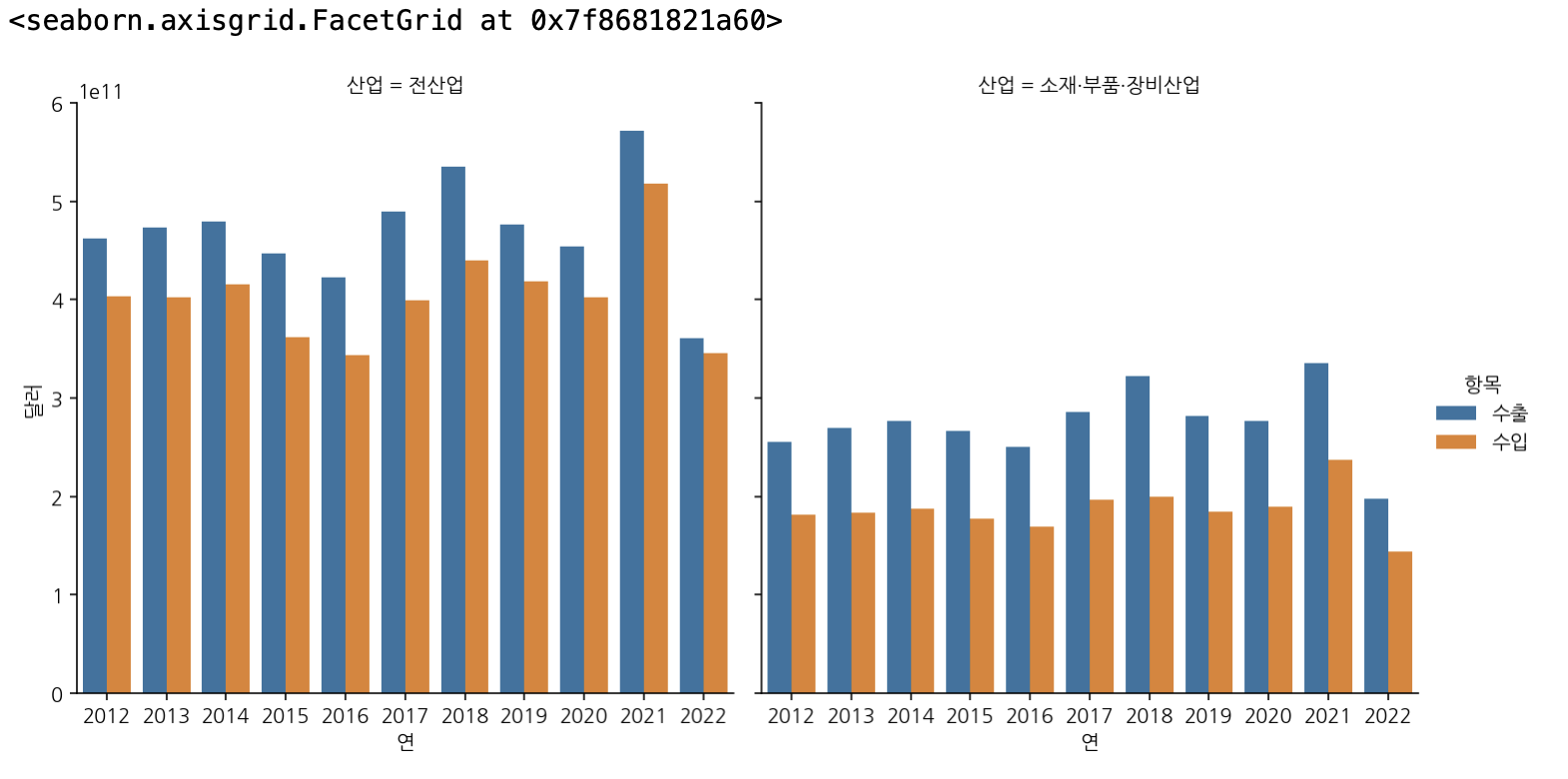
df_country_20 = df_country[df_country['국가권역'].isin(top20.index[:10])]
sns.catplot(data=df_country20, x='연', y='달러', hue='항목', col='국가권역',
estimator=np.sum, col_wrap=4, kind='point', ci=None)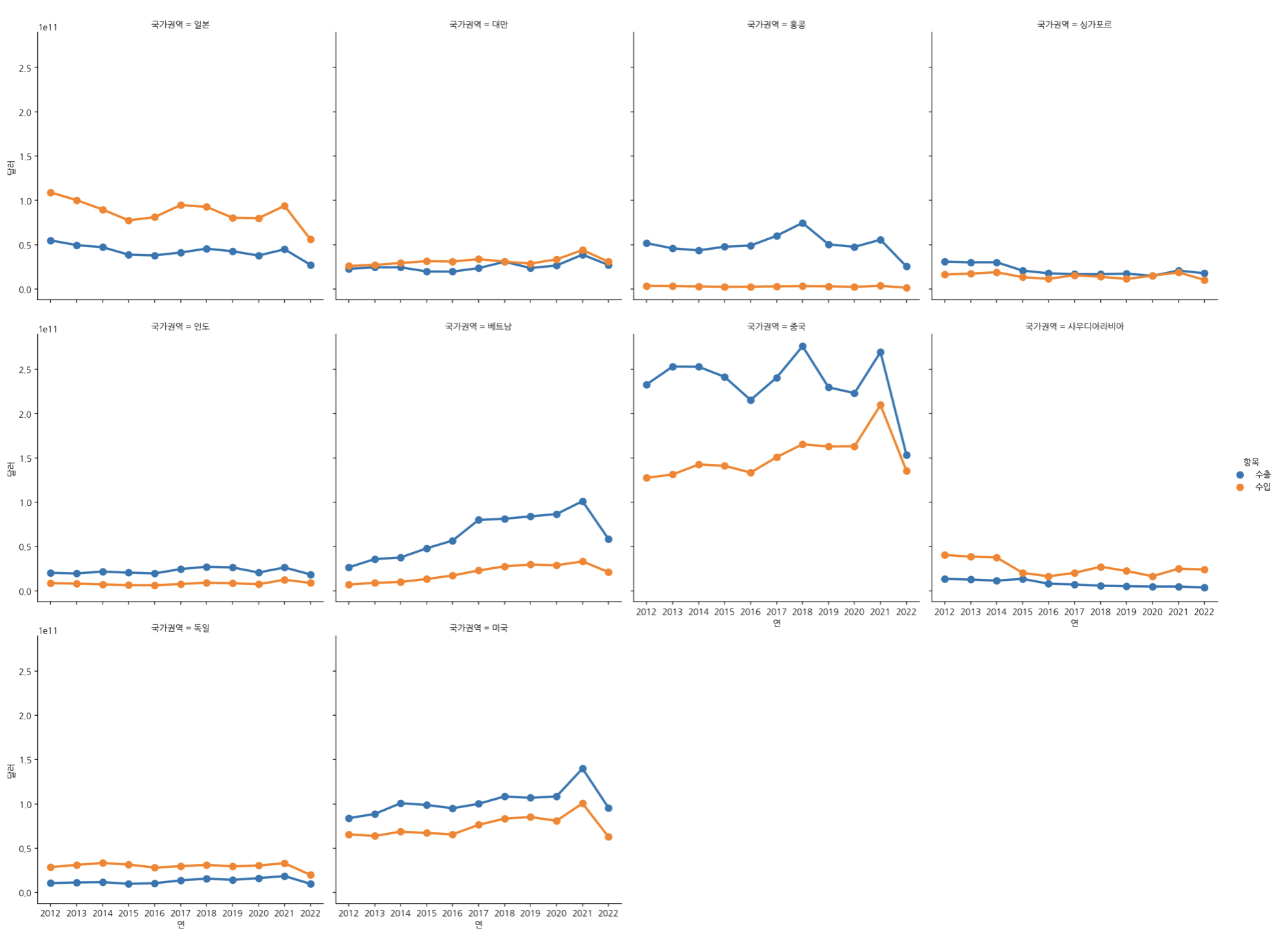

Ⓓ🅰️🅣🄰 ♡♥︎