
1. Pandas
- 파이썬에서 사용하는 데이터분석 라이브러리
- 대용량의 데이터들을 처리하는데 사용하는 도구
#Package Loading import pandas as pd
1) 외부 데이터 읽어오기
(1) txt
data = pd.read_table(filepath_or_buffer = 'directory/filename.txt',
sep = ' ' or ',' or '\t',
header = 'infer' or 0 or None,
encoding = 'EUC-KR')- sep = txt 파일 데이터 간 구분 방식에 맞추어 설정
- header = 테이블의 열의 이름 설정

(2) csv; comma separated value
data = pd.read_csv(filepath_or_buffer = 'directory/filename.txt',
header = 'infer' or 0 or None,
encoding = 'EUC-KR')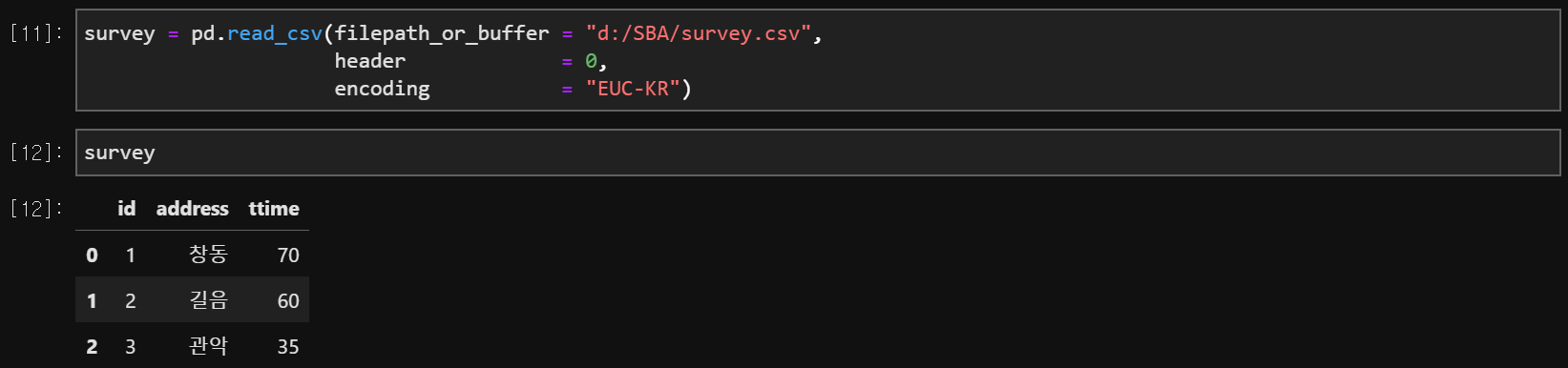
(3) xls, xlsx
data = pd.read_excel(io = 'directory/filename.txt',
sheet_name = 'sheet name' or sheet_index,
header = 'infer' or 0 or None)- sheet_name = 엑셀 데이터 시트명 (왼쪽 아래 위치)

2) Data Handling
(1) 데이터 보기
- 원하는 형태로 데이터 보기
data.head(), data.head(n = )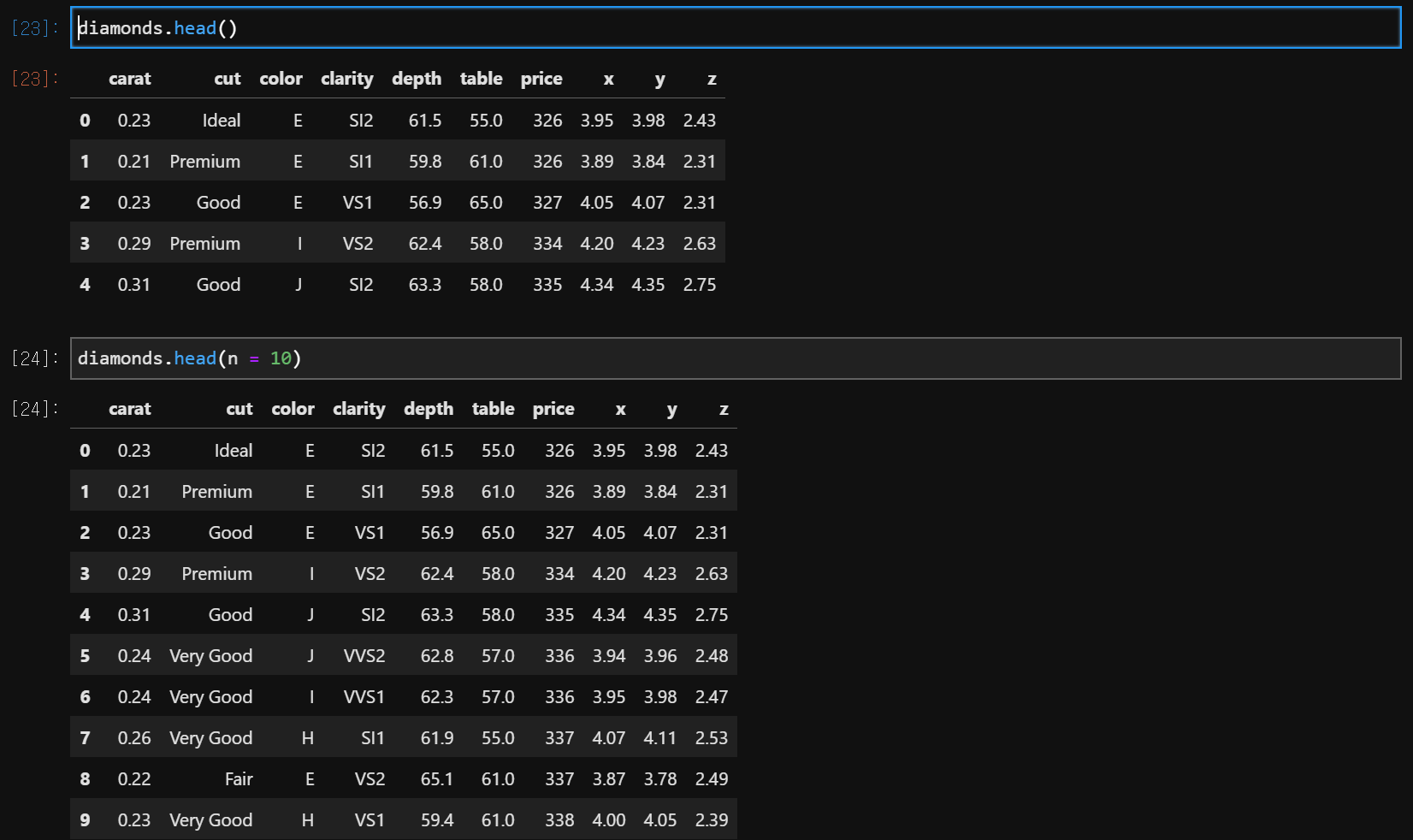
data.tail(), data.tail(n = )
(2) 데이터의 속성
type(data) # 데이터의 형태
data.shape # 데이터의 모양 : 행의 개수와 열의 개수
data.dtypes # 데이터의 유형 : 데이터가 가지는 값이 무엇으로 되어 있는지
data.columns # 열 = 변수 = Feature(Label)의 이름
data.index # 행 = Index
data.info() # 데이터의 정보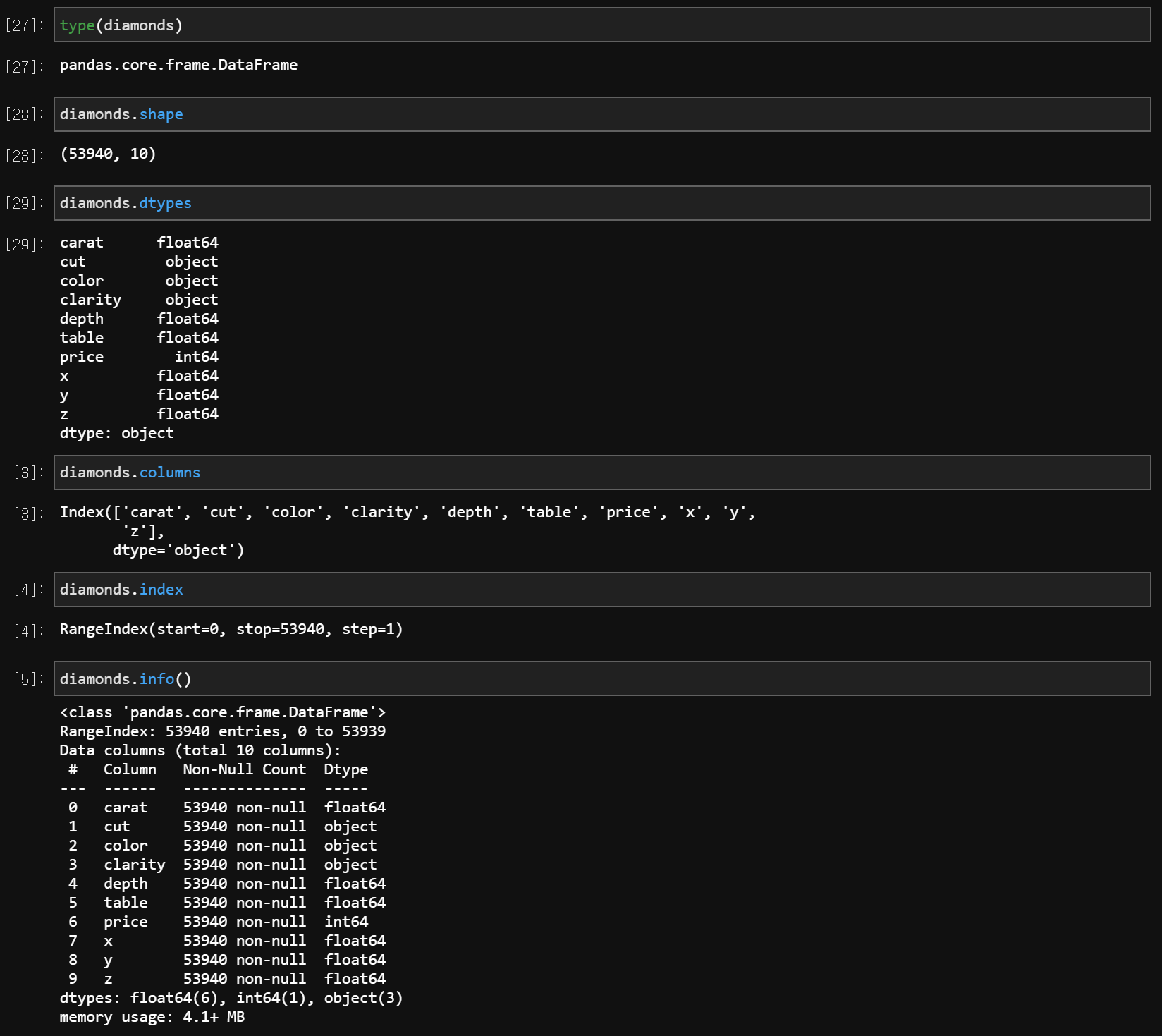
3) Data Slicing
(1) 행, 열 기준으로 자르기
data['variable'] # 특정 Column만 잘라내기
data[['variable1', 'variable2']] # 특정 두 개의 Columns 잘라내기
data.iloc[: [index]] # Columns의 순서로 잘라내기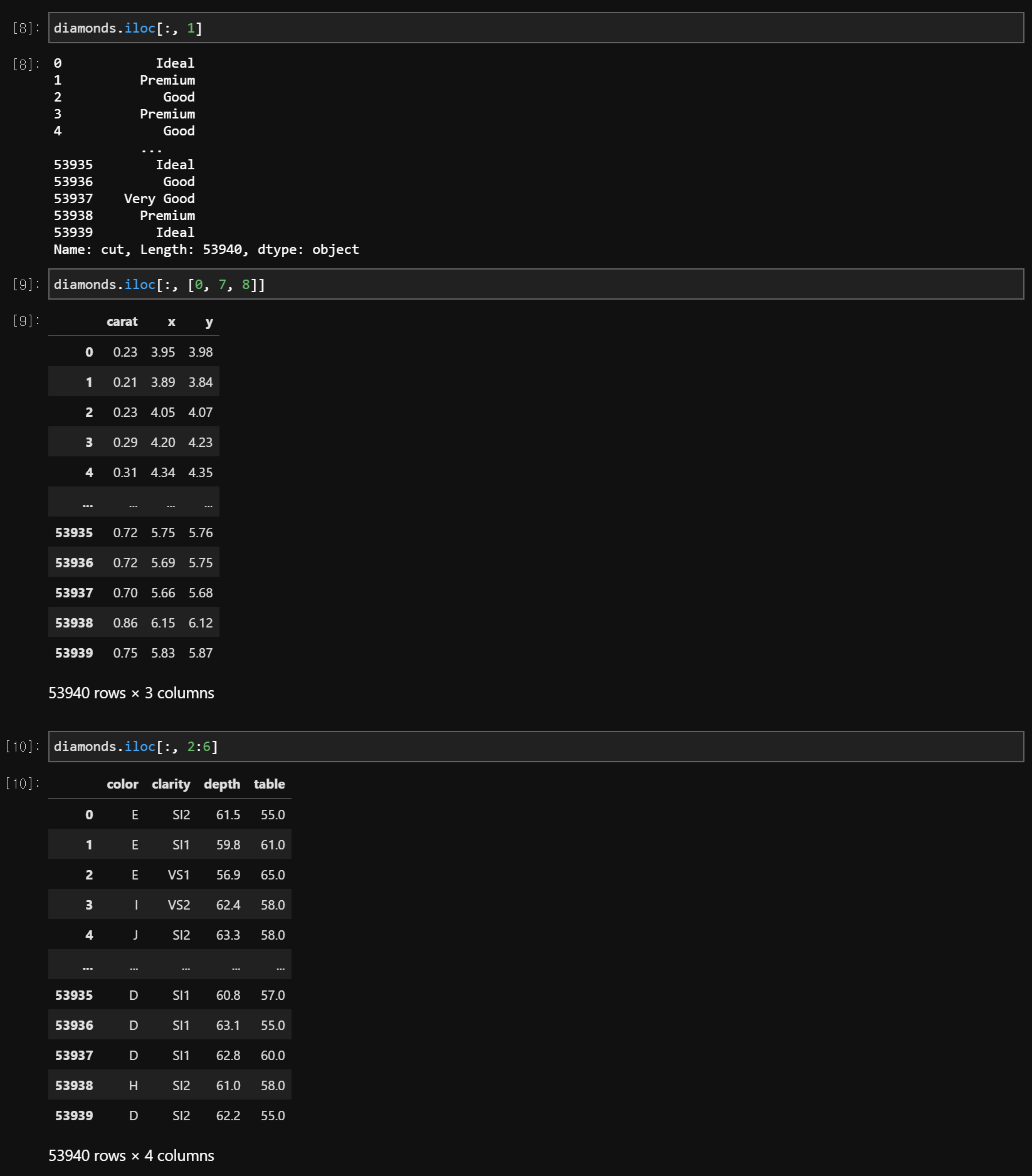
data.loc[조건, :] # 행의 위치를 알고 조건을 만족하는 행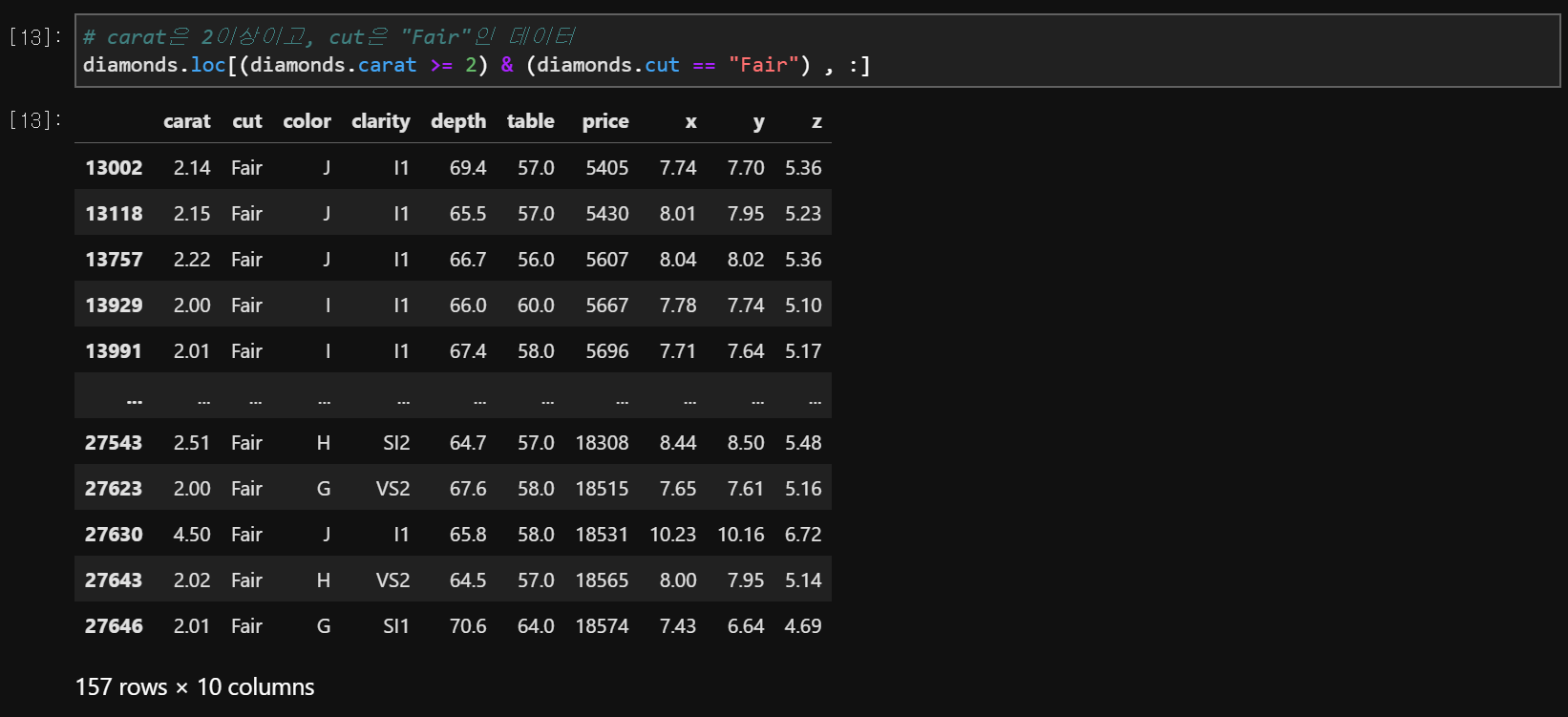
data.loc[조건, 열] # 조건을 만족하는 열
data.iloc[index, :] # 행의 위치를 알 때
data.iloc[row_index, col_index] # 위치를 알 때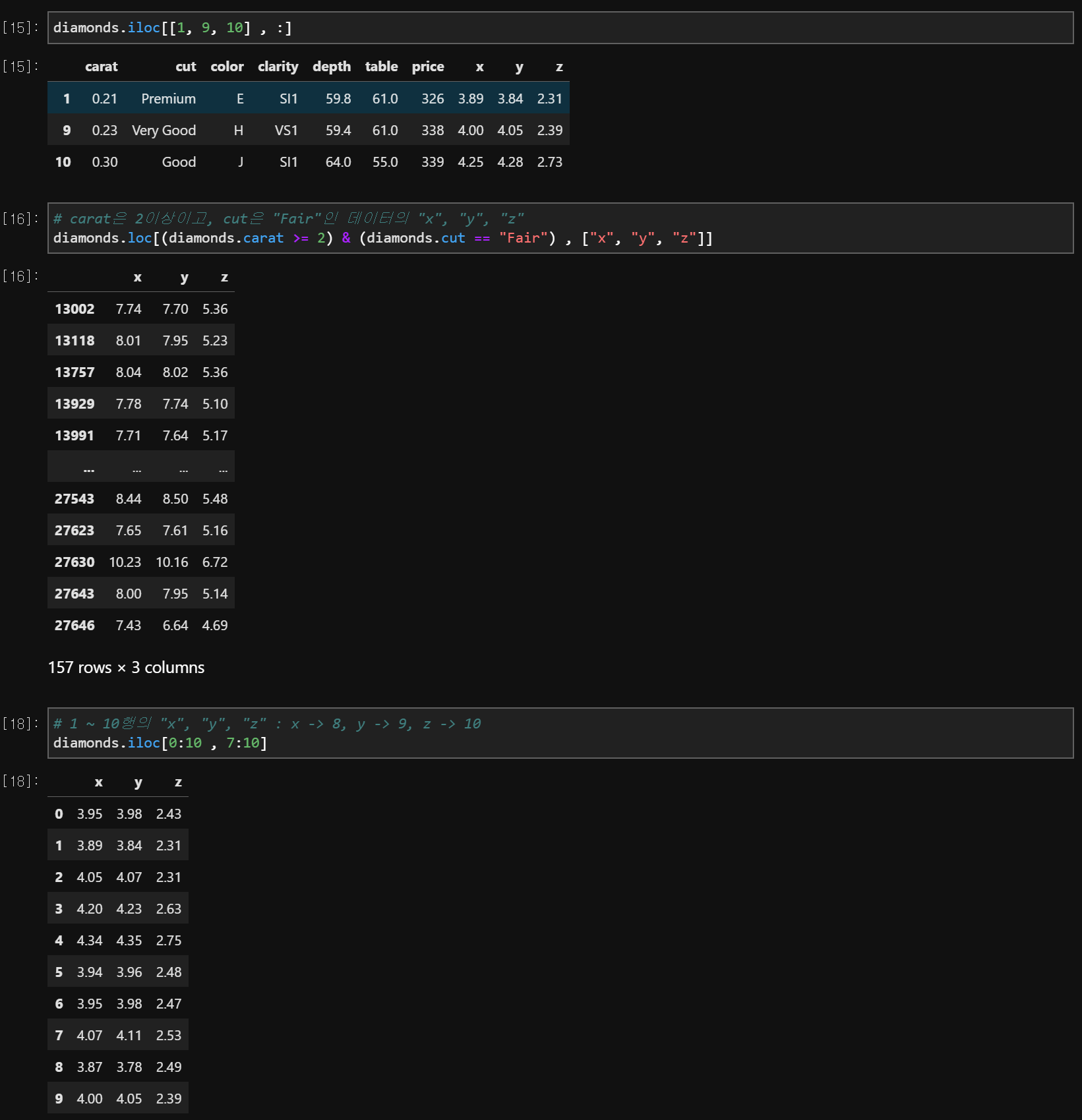
loc
: 조건을 알 때, 사용
iloc
: 위치를 알 때, 사용
(2) 새로운 열 (변수) 만들기
data['new_variable'] = 연산 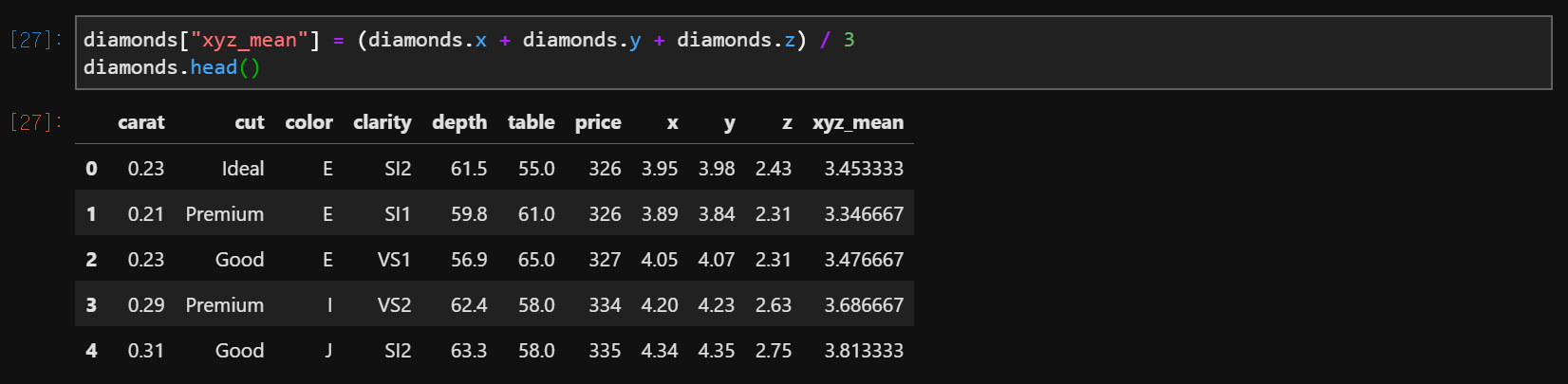
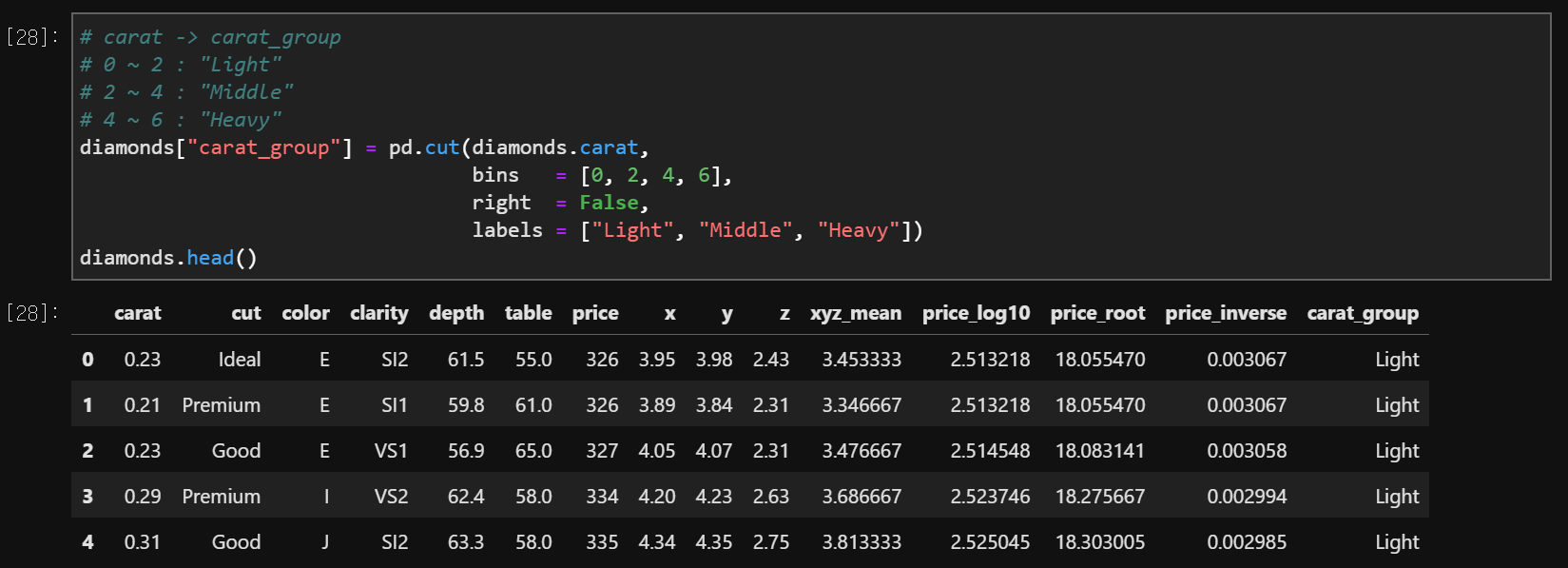
(3) 양적 자료(수치형) -> 질적 자료(범주형)
data['new_variable'] = pd.cut(data.variable,
bins = [int range],
right = True or False #bins 숫자들의 각 오른쪽 포함 여부
labes = ['범주 이름','']right = false
: 0 < x =< 10
(4) 열 삭제하기
del data['variable']
data.drop(['variable1', 'variable2'], #두 개 이상의 열
axis = 0 or 1, #0 : 행, 1 : 열
inplace = True or False) # 삭제 후의 결과를 원 데이터에 적용할지 안할지 결정
(5) 데이터 정렬하기
data.sort_values(by = 'variable', ascending = True or False)
# ascending : True = 오름차순, False = 내림차순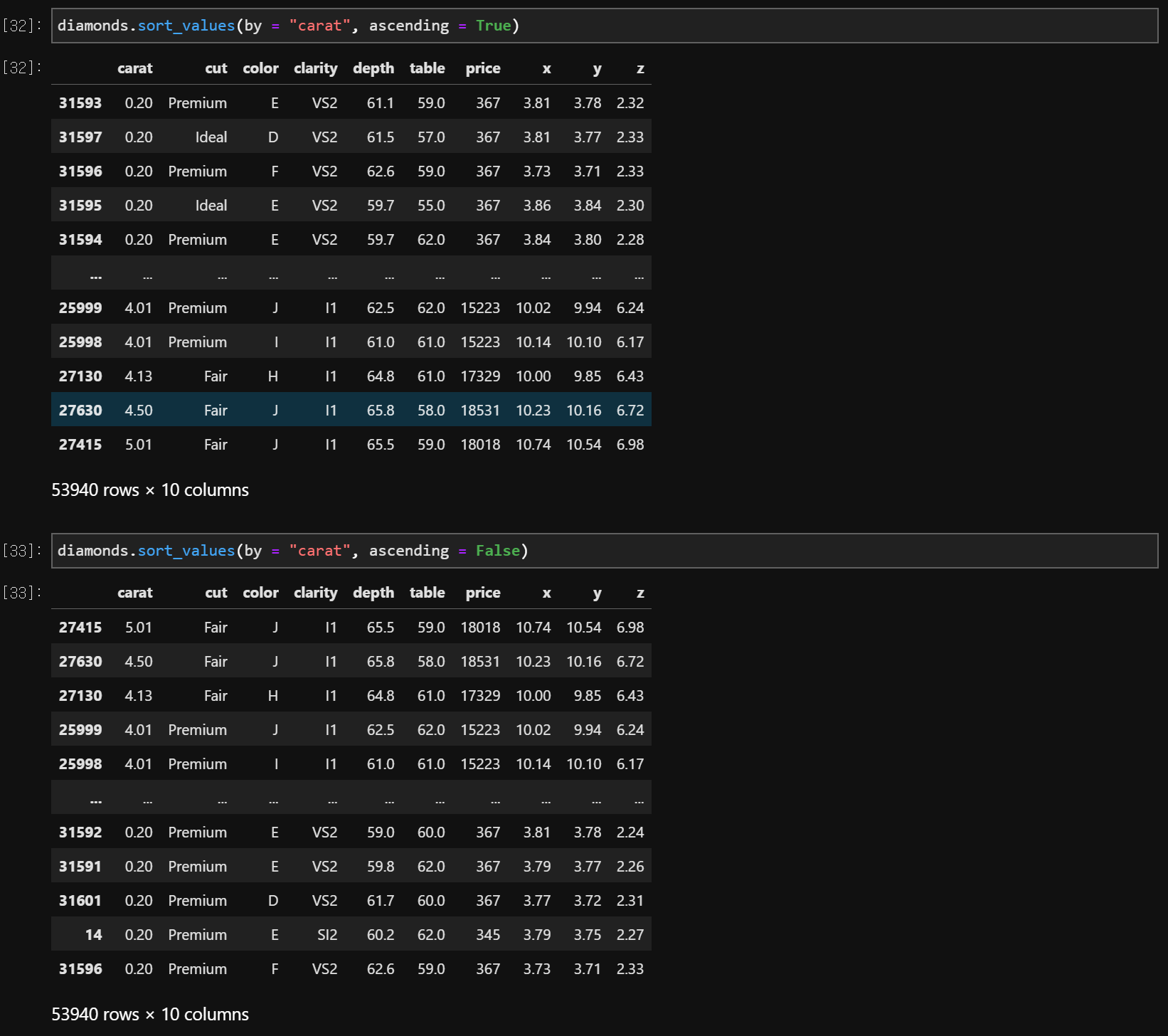
#두 개의 열 오름차순, 내림차순
data.sort_values(by = ['variable1', 'variable2'], ascending = True or False)
data.sort_values(by = ['variable1', 'variable2'], ascending = [True, False])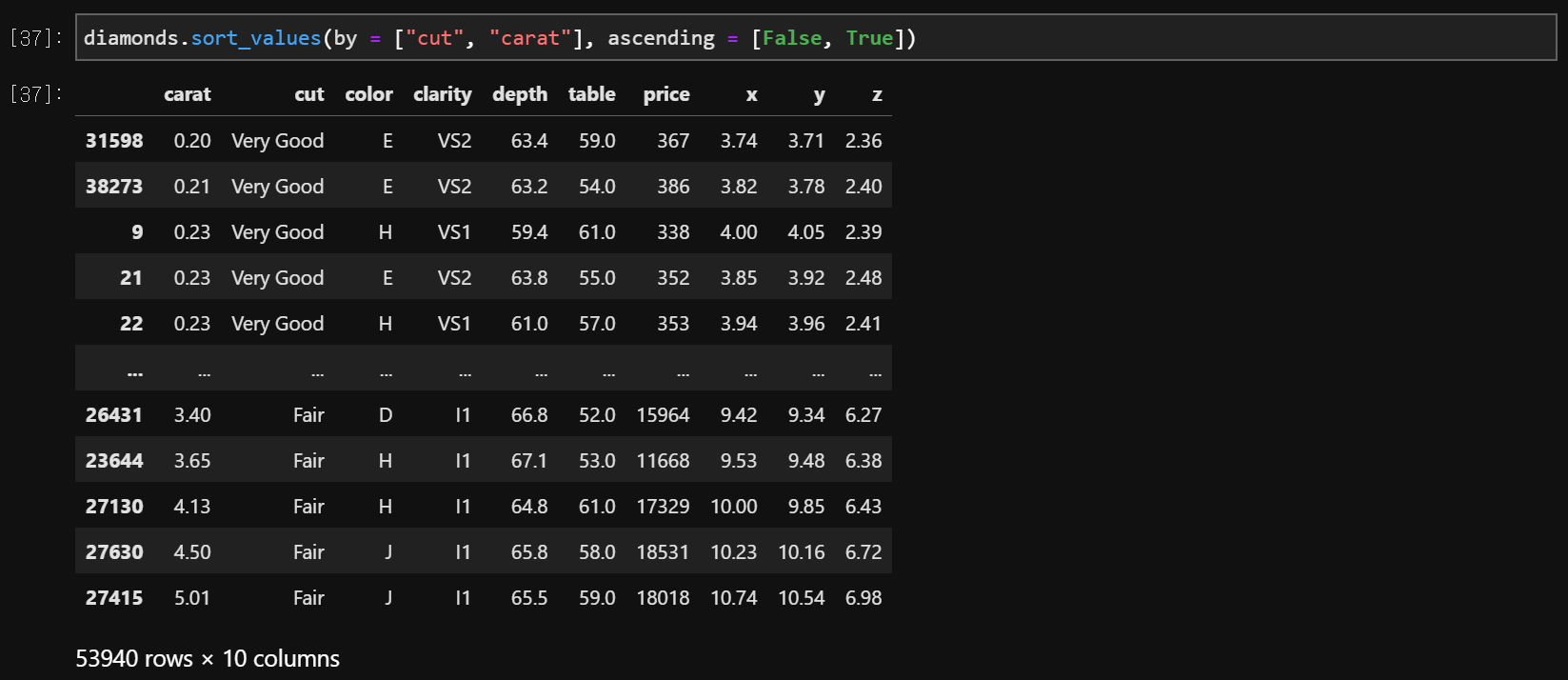
4) 데이터 합치기
(1) Merge
pd.merge(data1, data2, on = 'primary_key', how = 'inner', 'outer', 'left', 'right')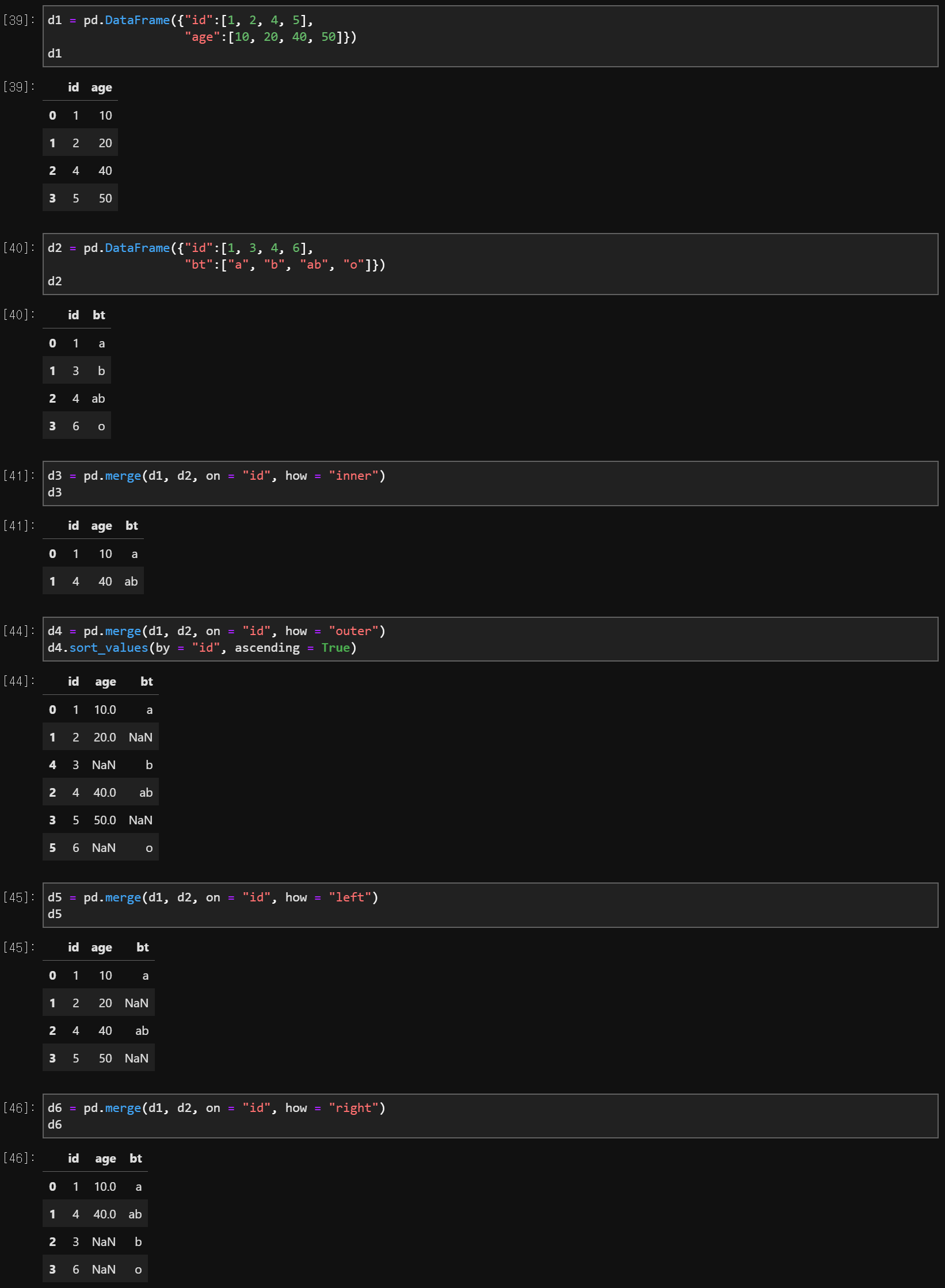
(2) Concat
pd.concat(objs = [data1, data2], axis = 0] #위, 아래
pd.concat(objs = [data1, data2], axis = 1] #왼쪽, 오른쪽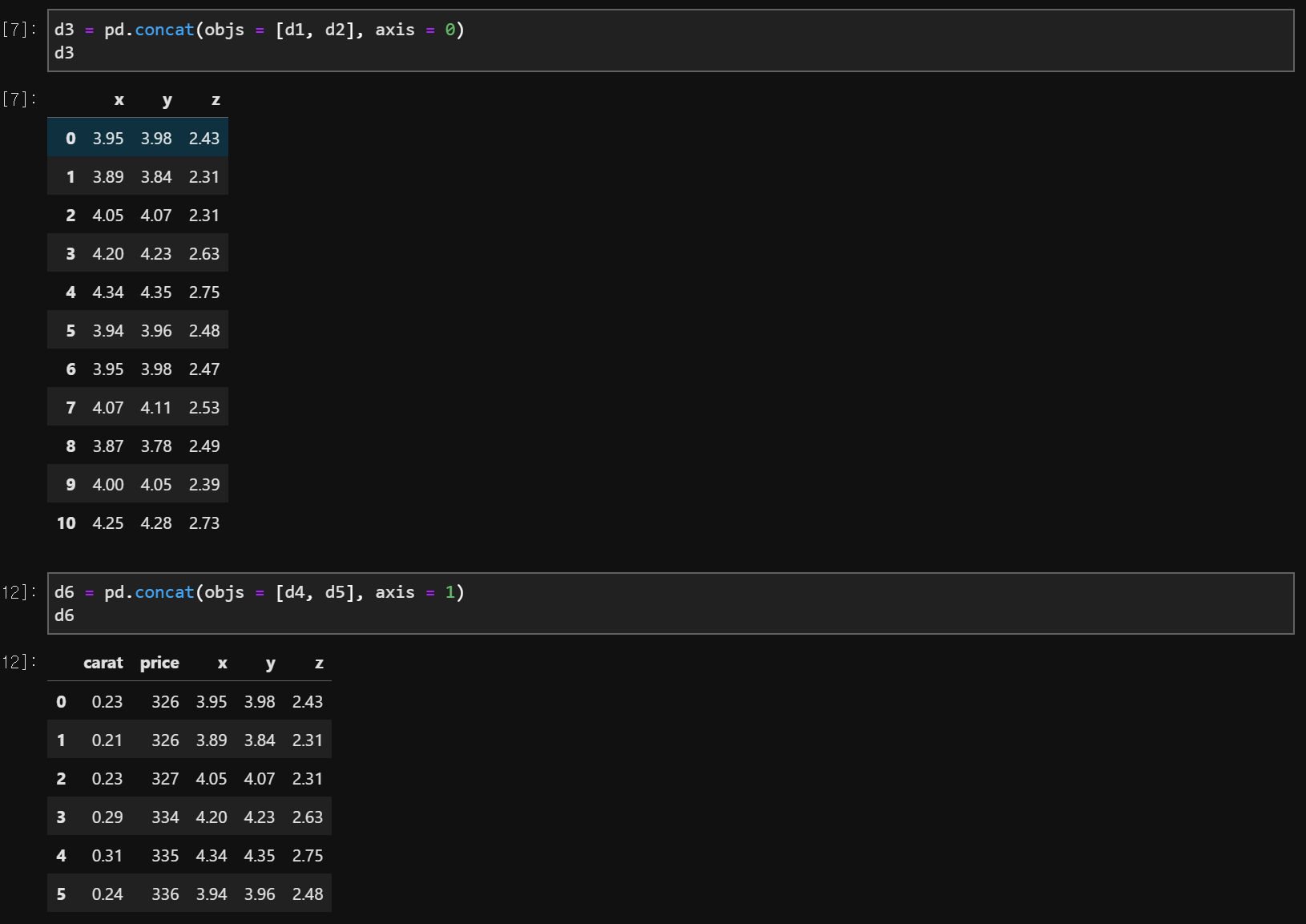
5) 외부 데이터로 저장하기
(1) txt
data.to_csv(path_or_buf = 'directory/filename.txt',
sep = ' ' or ',' or '\t',
header = Ture,
index = Flase)(2) csv
data.to_csv(path_or_buf = 'directory/filename.txt',
header = Ture,
index = Flase)(3) xls, xlsx
data.to_excel(excel_writer = 'directory/filename.txt',
sheet_name = ' ' or ',' or '\t',
header = Ture,
index = Flase)
Back-end, Python, Data