LSTM의 장기 의존성 문제의 해결을 유지하면서 은닉 상태의 업데이트에 대한 계산을 줄임.
GRU는 LSTM과 유사하지만 구조를 단순화.
Architecture
LSTM은 Input, Output, Forget Gate로 구성.
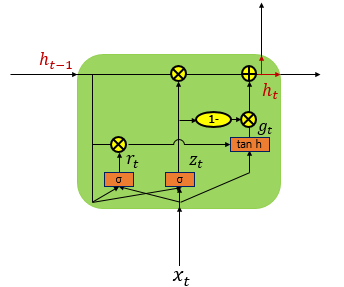
GRU는 Update, Reset Gate로 구성.
LSTM보다 학습 속도는 빠르고 성능은 비슷.
LSTM과 GRU의 절대적 비교는 불가능.
데이터 양이 많다면 LSTM의 성능이 더 우수.
LSTM의 장기 의존성 문제의 해결을 유지하면서 은닉 상태의 업데이트에 대한 계산을 줄임.
GRU는 LSTM과 유사하지만 구조를 단순화.
LSTM은 Input, Output, Forget Gate로 구성.
GRU는 Update, Reset Gate로 구성.
LSTM보다 학습 속도는 빠르고 성능은 비슷.
LSTM과 GRU의 절대적 비교는 불가능.
데이터 양이 많다면 LSTM의 성능이 더 우수.
