5. GoogLeNet
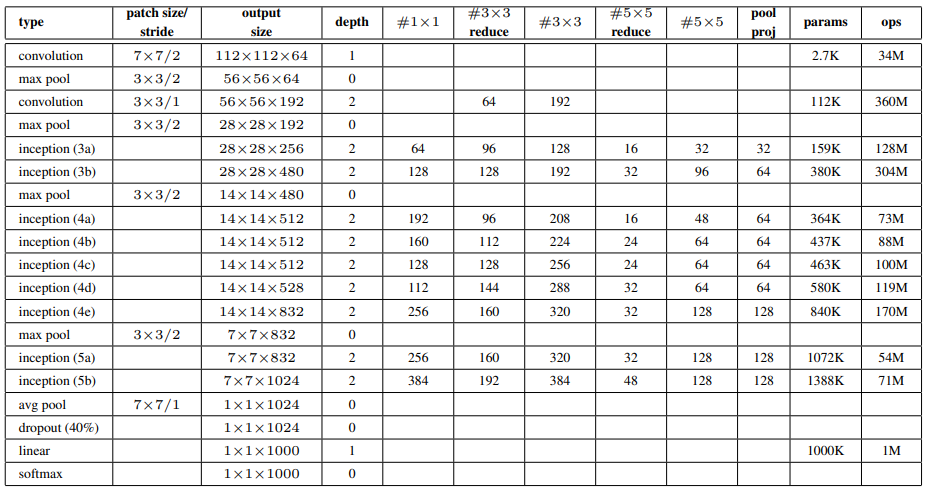
Inception module을 포함한 모든 convolution/reduction/projection layer에는 ReLU 적용.
"# reduce"과 "# reduce"는 과 convolution 이전의 # of filters.
"pool proj"는 max pooling 이후의 filter의 수.
Input
(with mean substraction)
Part 1. Low Layer
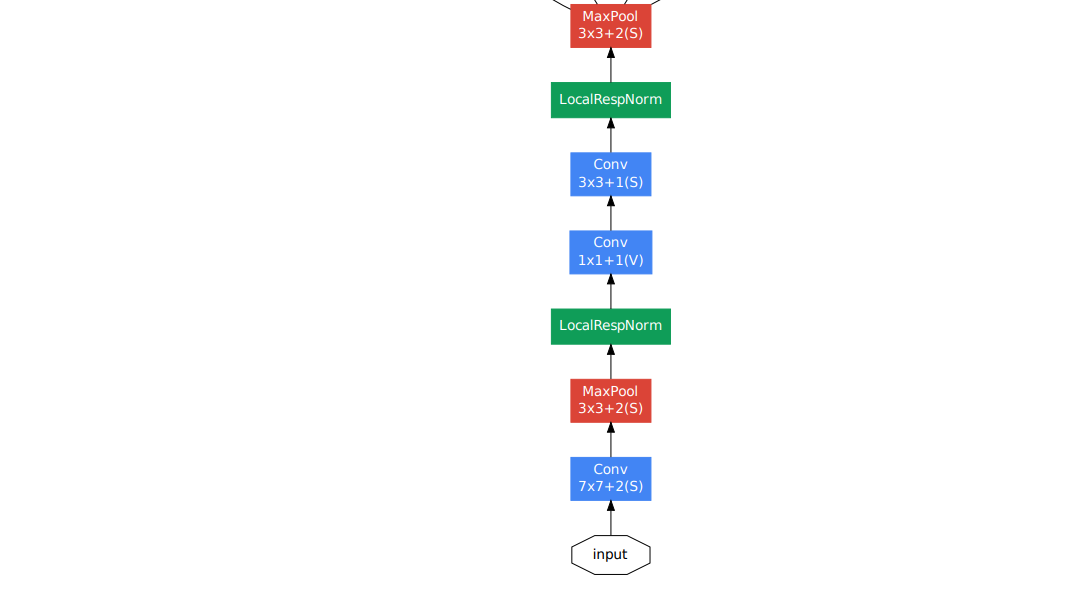
메모리의 효율성을 위해 low layer에서 기본 CNN 모델 사용.
Part 2. Inception Module
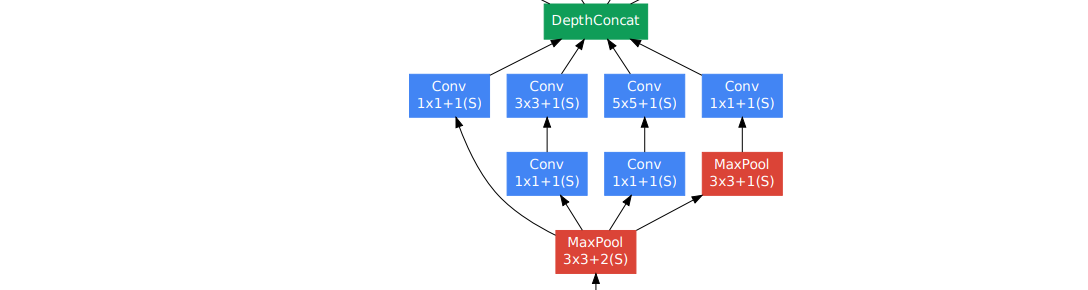
차원의 축소를 위해 convolution.
, , convolution 병렬적 연산 (Local sparse 구조).
효율적인 dense 연산을 위해 DepthConcat.
Part 3. Auxiliary Classifier
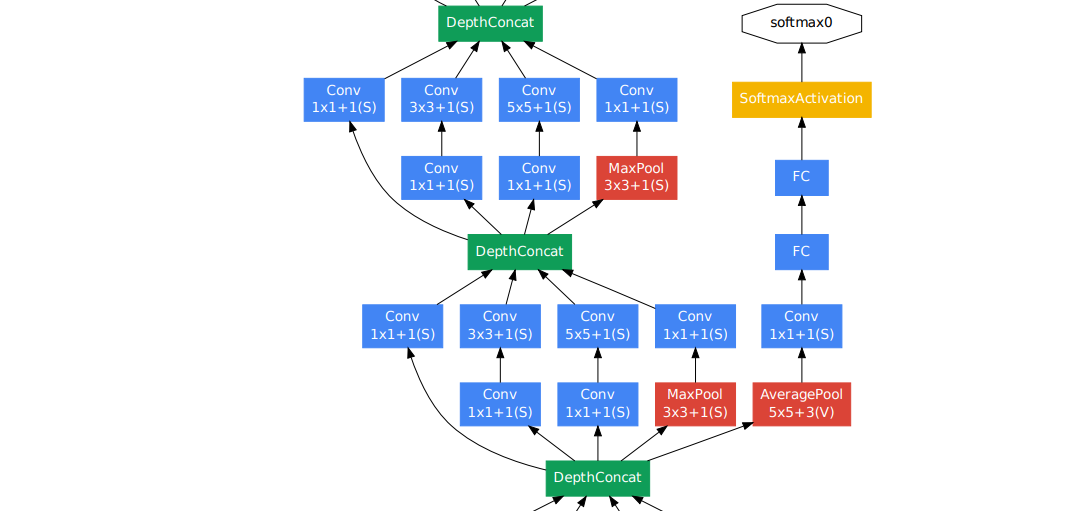
depth가 커질수록, back propagation시 gradient vanishing 발생.
상대적으로 얕은 신경망의 강한 성능을 이용.
중간 layer에 auxiliary classifier를 추가하여, back propagation에서의 gradient 전달과 추가적인 정규화 효과.
지나친 영향을 방지하고자 loss에 0.3 곱함.
Total_Loss = Real_Loss + Aux_Loss1 + Aux_Loss2
테스트 시에 auxiliary network 제거.
Part 4. Global Average Pooling
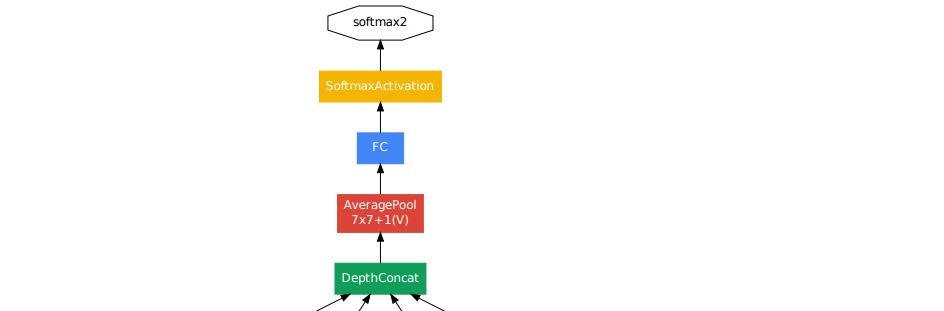
최종 classfier 이전에 Global Average Pooling을 적용 (auxiliary classifier에도 적용).
fully connected layer에서 global average pooling으로의 변화는 정확도를 높여줌.
fully connected layer을 삭제하여도 dropout은 적용.
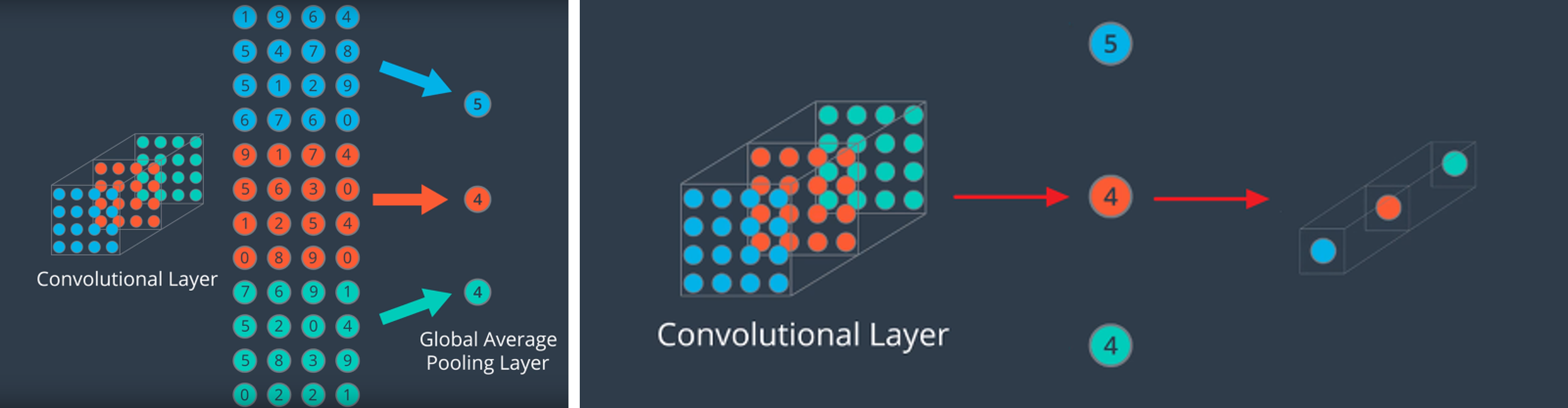
Global Average Pooling (GAP)
GAP의 목적은 feature map을 1차원 벡터로 변환.
→
FC layer을 없애기 위해 도입.
FC layer는 # of params가 증가하며 input size가 고정.
GAP는 input size의 제한이 없음.
6. Training Methodology
Stochastic gradient descent
momentum =
Learning rate
decreasing by 4% per every 8 epochs.
Image size
aspect ratio 3 : 4 또는 4 : 3 유지.
본래 사이즈의 8% ~ 100%.
Photometric distortions
9. Conclusions
Inception 구조는 sparse 구조를 dense 구조로 근사하여 성능을 개선.
Reference
GoogLeNet 논문
GoogLeNet (Going deeper with convolutions) 논문 리뷰
Inception Module과 GoogLeNet
7. CNN 구조 2 GoogleNet
[IT에 한걸음 더 다가가기] SMAC의 분석 부문, 지능화를 지향하는 Machine Learning (4편)
Global Average Pooling 이란
GAP(Global Average Pooling) vs FCN(Fully Convolutional Network)
