0. Abstract
컴퓨터 연산량은 유지하면서 depth와 width는 증가.
성능 최적화를 위해 Hebbian principle과 multi-scale processing 사용.
이 모델을 GoogLeNet이라 부르며, 22개의 layer로 구성.
The main hallmark of this architecture codnamed Inception is the imporved utilization of the computing resources inside the network.
1. Introduction
지난 3년 동안, 이미지 인식과 객체 탐지 능력이 향상.
이는 새로운 아이디어, 알고리즘, 그리고 발전된 네트워크 구조에 의한 결과.
※ AlexNet보다 12배 적은 params를 사용하였지만, 정확도가 더 높음.
모바일과 embedded 컴퓨팅으로, 전력과 메모리 사용 관점에서 알고리즘의 향상이 중요.
Network In Network 논문에서 코드네임 Inception 유래.
"we need to go deeper"
"deep"의 뜻
1) 'Inception module'의 형태로 새로운 수준 도입.
2) 네트워크의 depth 증가.
2. Related Work
CNN의 표준 구조 (GoogLeNet도 적용)
stacked convolutional layers(optionally contrast normalization and max-pooling)
one or more fully-connected layers
# of layers and layer size의 증가와 dropout to address overfitting
Network-In-Network
neural 네트워크의 표현력을 높임.
convolutional layer에 적용 시, MLP 적용처럼 convolutional layer와 ReLU 추가 적용.
NIN (Network-In-Network)
CNN의 conv. layer는 filter에 의해 특징을 추출해내는 능력이 뛰어나지만, filter는 선형성을 지니고 있기 때문에 비선형적인 특징을 추출하기에는 어려움.
이에 convolution을 위한 filter 대신 MLP (Multi Layer Perceptron) 사용.
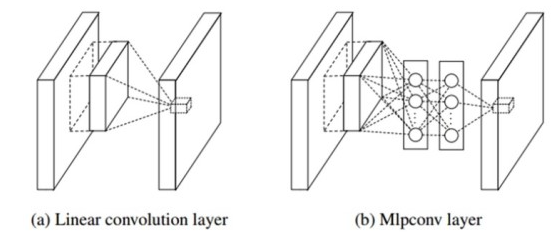
convolution의 목적
1) 컴퓨터 bottleneck을 제거하기 위해 차원 축소.
2) 네트워크의 크기 제한.
이는 성능 저하 없이 depth와 width 증가.
About Reference
VGGNet - 4.1 Single Scale Evaluation
3. Motivation and High Level Considerations
deep neural network의 성능 향상을 위한 방법은 size 키우기.
size : depth (# of levels) and width (# of units at each level)
이는 두 가지 단점이 존재.
1) Overfitting
size가 크다는 것은 params가 많다는 것.
특히 학습 데이터가 적을 경우, overfitting 발생.
세밀한 카테고리를 구별해야할 경우 (Figure 1), 품질의 훈련 데이터 생성은 어렵고 비용이 많이 듦 (Bottleneck).

2) Computational resource
네트워크 size 증가는 컴퓨터 연산량 증가를 초래.
컴퓨터 연산량은 한정적이므로, size의 무분별한 증가보다는 효율적인 연산량 분배가 중요.
해당 단점에 대한 해결책은 fully connected → sparsely connected.
dataset의 확률 분포가 더 크고 sparse하며 깊은 신경망으로 표현 가능하다면, layer간 상관관계를 분석하며 높은 상관관계 (fire)를 갖는 것끼리 연결 (wire)하는 것이 최적 (Dropout과 비슷).
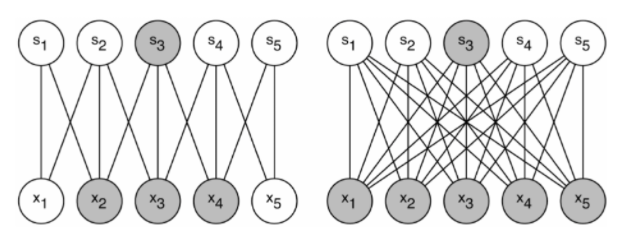
Hebbian principle
neuron 사이의 연결강도 (weight)를 조정.
두 개의 neuron 가 지속적으로 firing하여 한쪽 또는 양쪽 모두에 변화를 야기하면, firing의 연결강도 (weight) 증가.
'neurons that fire together, wire together'
당시 컴퓨팅 환경은 균일하지 않은 sparse 구조를 다루기에 비효율적.
대칭성을 깨고 학습을 향상시키기 위해 랜덤하고 sparse한 네트워크를 사용하였지만, 병렬 처리의 최적화를 위해 다시 fully connected 이용.
균일한 모델 구조, 필터의 수와 배치 사이즈의 증가는 dense 연산 가능.
※ dense 연산은 효율적이고 빠름.
이때, sparse matrix를 묶어 만든 상대적으로 dense한 submatrix가 좋은 성능을 보임.
matrix는 dense하게, network는 sparse하게
4. Architectural Details
Main idea는 최적의 local sparse 구조를 근사하고 dense component로 변환.
즉, 최적의 local sparse 구조를 찾고 공간적으로 반복.
Main Idea
성능 향상을 위해 depth 증가
→ Overfitting and Computational resource
→ Spasely Connected 구성
→ Sparse matrix를 묶어 Dense Submatrix 구성
→ Local sparse 구조 근사 후 Filter concatenation
(a) Inception module, naive version
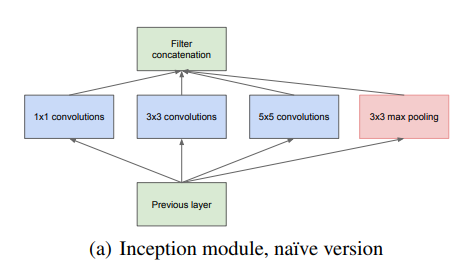
convolution과 pooling.
이렇게 다양한 convolution filter의 병렬 구조가 local sparse 구조라 함.
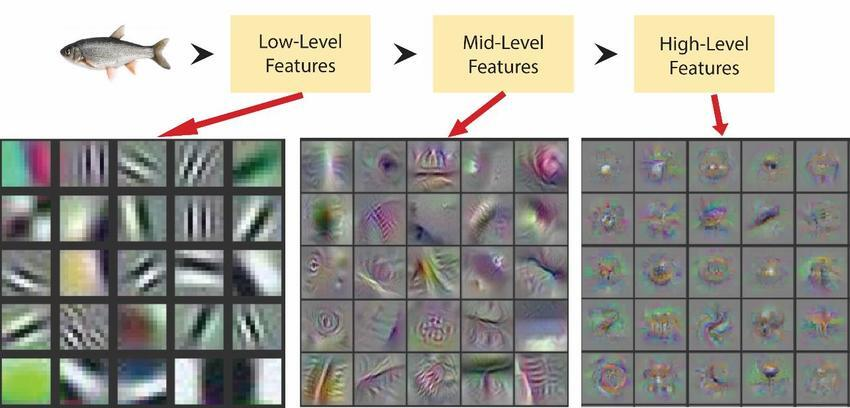
Low-Level (input과 가까움)의 경우, 특정 부분에 correlated unit 집중.
즉, 단일 영역에 많은 cluster 집중이므로 convolution.
High-Level의 경우, cluster 집중도가 낮기 때문에 더 넓은 영역의 convolutional filter로 correlated unit의 집중을 높임.
즉, convolution. 네트워크가 깊어짐에 따라 # of convolutions가 증가해야함.
문제는 convolution 연산 조차도 연산량이 많음.
(b) Inception module with dimension reductions
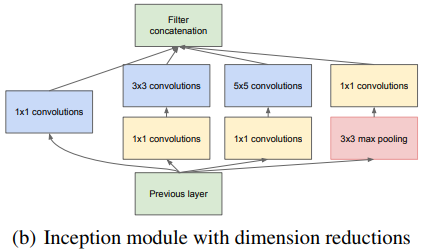
과 앞에 convolution을 하여 차원을 줄임.
이는 또한 ReLU 함수를 통해 비선형성 증가의 이점.
메모리의 효율성을 위해 low layer에서는 기존 CNN 모델, high layer에서는 Inception module 사용.
이는 다음과 같은 이점이 있음.
1) 차원 축소를 통해 input filter 조절. → 과도한 컴퓨터 연산없이 각 단계에서의 유닛 수 증가 (⇔ size 증가).
2) 시각 정보가 다양한 scale로 처리 및 통합되고, 이는 동시에 다른 scale에서 특징 추출.
