Optimization (최적화)
학습에 있어서 중요한 것은 틀리지 않은 방향으로 학습하는 것.
loss function의 최솟값을 찾는 것이 학습의 목표.
최솟값을 찾아가는 과정 : 최적화(optimization)
이 과정을 행하는 알고리즘 : 최적화 알고리즘(optimizer).
Objective vs Loss vs Cost
Objective function : 학습을 통해 최적화시키려는 함수.
Loss function : single input에 대한 y와 y^ 사이의 오차를 계산하는 함수.
Cost function : entire input에 대해서 오차를 계산하는 함수.
즉, Objective ftn > Loss ftn > Cost ftn
Gradient Descent
경사(Gradient)가 가파른 방향으로 이동하여 최솟값을 찾는 알고리즘.
목적함수 J(θ)의 최소화.
θt+1=θt−η×∇θJ(θ) where η is a learning rate.
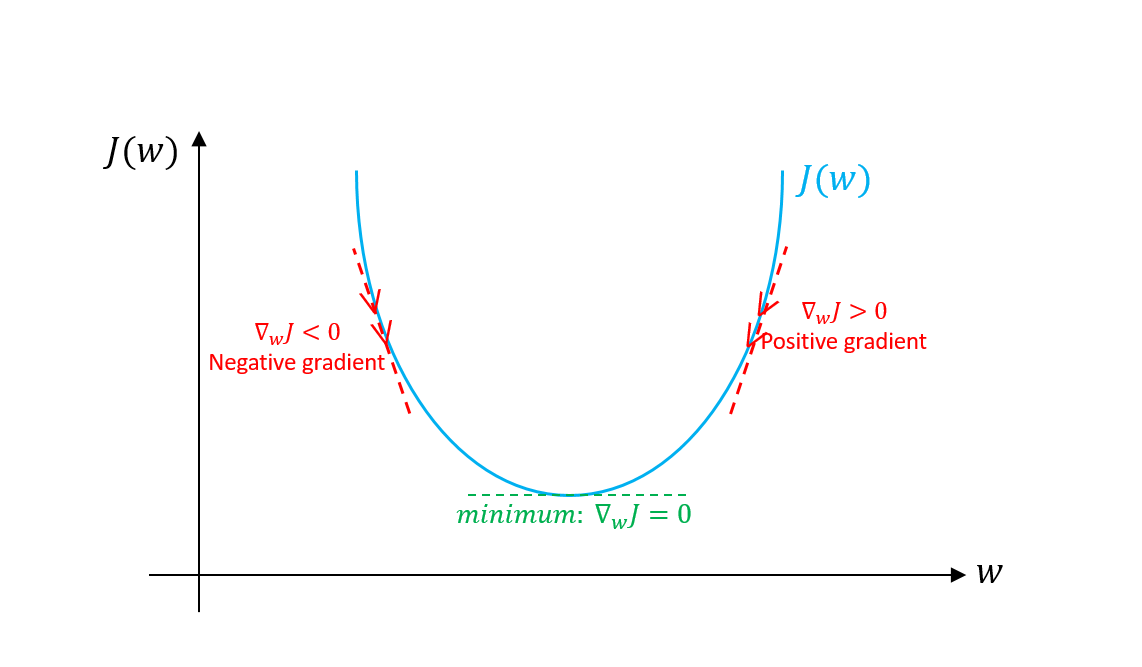
Gradient ∇θJ(θ)를 빼줌으로써 최솟값을 찾음.
Learning rate η
η가 작다면 수렴 속도가 느려짐.
η가 크다면 minimum을 지나쳐버릴 수 있고 발산할 수도 있음.
1) Batch Gradient Descent (BGD)
전체 학습 데이터를 하나의 batch로 묶어 학습.
전체 data set에 대한 error의 평균을 구하여 Gradient 계산.
장점
업데이트 횟수가 적음. (1 epoch당 1회 업데이트)
안정적인 수렴.
단점
학습이 오래 걸림.
local minimum에 빠지기 쉬움.
2) Stochastic Gradient Descent (SGD)
전체 학습 데이터 중 단 하나의 데이터를 이용하여 학습.
전체 data set 중 랜덤하게 하나의 데이터를 학습하므로 확률적.
장점
적은 데이터로 학습 가능.
1회 학습이 빠름.
local minimum에 잘 빠지지 않음.
단점
불안정적인 수렴.
saddle Point에서 학습 종료.
3) Mini-batch Gradient Descent (MGD)
BGD와 SGD의 절충안.
전체 학습 데이터를 batch size개로 나누어 학습.
장점
계산량이 BGD보다 적으므로 학습이 상대적으로 빠름.
SGD에 비해 정확도가 높음.
local minimum을 어느정도 피할 수 있음.
Mini-batch size
전체 데이터 크기를 n
1) Mini-batch size = n : Batch Gradient Descent
2) Mini-batch size = 1 : Stochastic Gradient Descent
3) Mini-batch size < m : Mini-batch Gradient Descent
Momentum
SGD의 gradient descent의 이동 과정에서 '관성' 부여.
과거의 이동 과정을 기억하여 추가적 이동.
mt=γmt−1+η∇θtJ(θt), γ∈(0,1)
∴θt+1=θt−mt
(γ는 gradient가 0일 경우, 서서히 줄어드는 역할. 주로 0.9.)
장점
관성을 이용하여 local minimum이나 saddle point에서 벗어남.
단점
overshooting.
θ 이외에도 과거의 관성을 저장해야하므로 메모리가 두 배 필요.
Nesterov Accelerated Gradient (NAG)
Momentum 방식을 기초로 하되, 미래를 먼저 보고 현재의 관성을 조절하여 학습.
overshooting을 막기 위해 미래를 먼저 가서 overshooting된 만큼 조절.
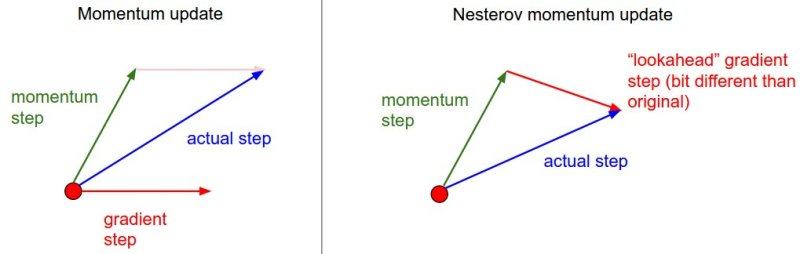
Momentum Update
momentum step (γmt−1)과 gradient step (η∇θtJ(θt))의 독립적 합산.
NAG Update
momentum step (γmt−1)을 먼저 이동한 후, 그 위치에서의 gradient step (η∇θtJ(θt−γmt−1))만큼 이동.
Why η∇θtJ(θt−γmt−1) ?
θt+1=θt−mt (미래)의 위치에서 gradient 계산.
mt를 알지 못하므로 γmt−1 사용.
즉, θt−γmt−1.
mt=γmt−1+η∇θtJ(θt−γmt−1), γ∈(0,1)
∴θt+1=θt−mt
장점
관성에만 의존하지 않고 momentum 방향으로 이동한 후, 방향을 결정.
AdaGrad (Adaptive Gradient)
SGD, Momentum, NAG는 모든 params에 동일한 learning rate 적용.
이는 sparse한 경우 비효율적.
⇒ params의 이전 gradient를 저장.
⇒ 각 params에 따라 step size를 다르게 함.
θt,i : t번째 step의 i번 param
gt,i=∇θtJ(θt,i)
Gt,i=g1,i2+g2,i2+ ⋅⋅⋅ +gt,i2 (곡면의 변화량)
∴θt+1,i=θt,i−(Gt,i+ϵ)1/2ηgt,i
변화 (gt,i)가 적음 ⇔ Gt,i↓ ⇔ step size↑
변화 (gt,i)가 큼 ⇔ Gt,i↑ ⇔ step size↓
단점
t가 증가할수록 Gt,i도 증가하므로, step size가 작아져서 learning rate가 소실.
RMSProp
Adagrad의 경우 learning rate 소실.
⇒ Gt,i를 지수 가중 이동평균으로 대체 (hyper param β).
⇒ learning rate가 소실되지 않으며, 상대적인 크기 유지.
E[g2]t=βE[g2]t−1+(1−β)gt2
(E[g2]t는 Gt의 가중 이동 평균; 최근 곡면의 변화량)
∴θt+1=θt−(E[g2]t+ϵ)1/2ηgt
지수 가중 이동평균
E[g2]t=βE[g2]t−1+(1−β)gt2 (β는 주로 0.9)
=βt−1E[g2]1+(1−β)(gt2+βgt−12+ ⋅⋅⋅ +βt−1g12)
최근 변화 (gt2)는 많이 반영, 오래된 변화 (βt−1g12)는 적게 반영.
변화 (gt)가 적음 ⇔ E[g2]t↓ ⇔ step size↑
변화 (gt)가 큼 ⇔ E[g2]t↑ ⇔ step size↓
단점
초기 경로의 편향 문제
Adam (Adaptive Moment Estimation)
Adam = Momentum (관성) + RMSProp (최근 곡면의 변화량)
즉, E[g]t (Momentum)과 E[g2]t (RMSProp) 업데이트.
Moment
확률변수 X의 n차 moment : E[Xn]
moment 값은 모수이므로 추정 (estimation)해야함.
mt=β1mt−1+(1−β1)gt (gradient의 1차 moment)
vt=β2vt−1+(1−β2)gt2 (gradient의 2차 moment)
∴θt+1=θt−(vt+ϵ)1/2ηmt
이는 학습 초기에 가중치들이 0으로 편향되는 경향.
Why?
m0=v0=0
v1이 작아지면서 θ1은 출발 지점 θ0과 멀어짐.
편향을 보정하기 위해,
mt^=1−β1tmt, vt^=1−β2tvt (β1=0.9,β2=0.99 사용)
∴θt+1=θt−(vt^+ϵ)1/2ηmt^
NAdam (Nesterov-accelerated Adaptive Memoment Adam)
NAdam = Nag + Adam
Nag 변형
mt=γmt−1+η∇θtJ(θt)
∴θt+1=θt−(γmt+η∇θtJ(θt))
∴θt+1=θt−mt+1
Adam 업데이트
θt+1=θt−(vt^+ϵ)1/2η(β1mt^+1−β1t(1−β1)gt)
Reference
[DL] 최적화 알고리즘 - SGD, Momentum, Nesterov momentum, AdaGrad
[DL] 최적화 알고리즘 - RMSProp, Adam
[딥러닝] 딥러닝 최적화 알고리즘 알고 쓰자. 딥러닝 옵티마이저(optimizer) 총정리
Gradient Descent Optimization Algorithms 정리
