0. Abstract
큰 규모의 인식에 관해서 convolutional network depth에 초점을 맞춤.
depth를 늘리기 위해 convolution filter를 으로 사용.
이를 통해 weight layer를 16~19로 증가.
Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3X3) convolution filters.
1. Introduction
convolutional network는 큰 규모의 이미지 저장소 (ImageNet)와 높은 수준의 기술 (GPU or large-scale distributed clusters)로 큰 성공을 이룸.
이 논문에서는 depth에 주목함. 모든 layer에서 convolution filter를 사용함으로써, params를 고정하고 네트워크의 depth를 늘림.
2. Convnet Configurations
2.1 Architecture
Input image
(RGB) image.
전처리 작업으로는 RGB의 평균값을 뺌.
Conv layer
conv filter 사용 (상하좌우와 중심을 파악하는 최소한의 크기).
conv filter도 사용 (Configuration C).
stride = , padding =
Pooling layer
개의 max-pooling layer.
stride =
Fully-Connected layer
첫번째, 두번째 layer는 4096개 채널.
세번째 layer는 1000개 채널.
Final layer
soft-max layer
그 외 모든 hideen layer은 정류 비선형성 함수 (ReLU) 적용.
Local Response Normalization은 성능을 향상시키지 않고 메모리 소비와 연산 시간을 늘리므로 사용하지 않음.
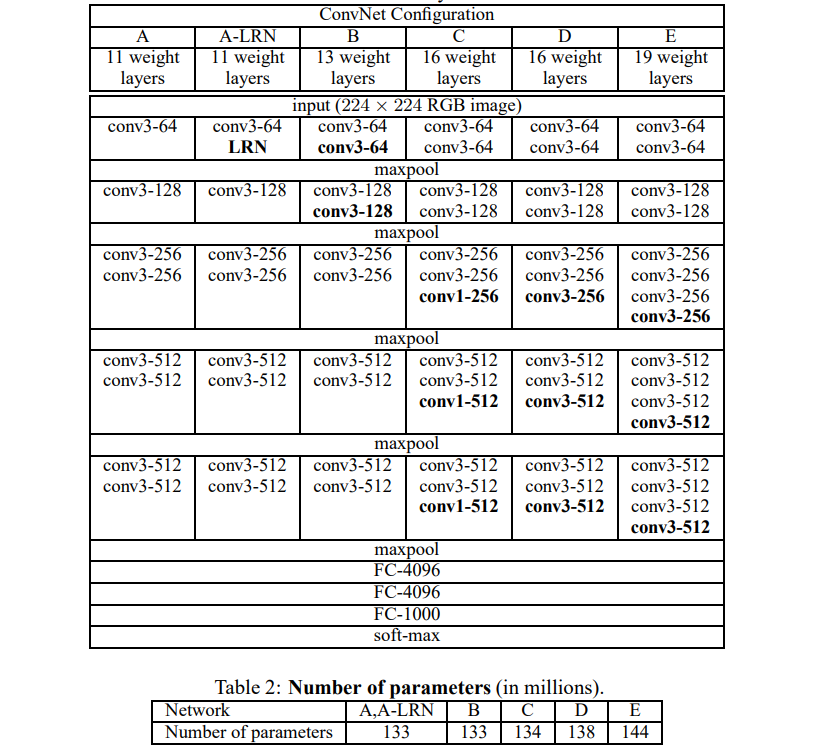
2.2 Configurations
모든 모델은 depth를 제외하고 전반적으로 같은 구조.
Model A (depth = ) ~ Model E (depth = )
Model A (# of channels = ) ~ Model E (# of channels = )
depth가 늘어나도 params의 수가 크게 늘어나지 않음.
2.3 Discussion
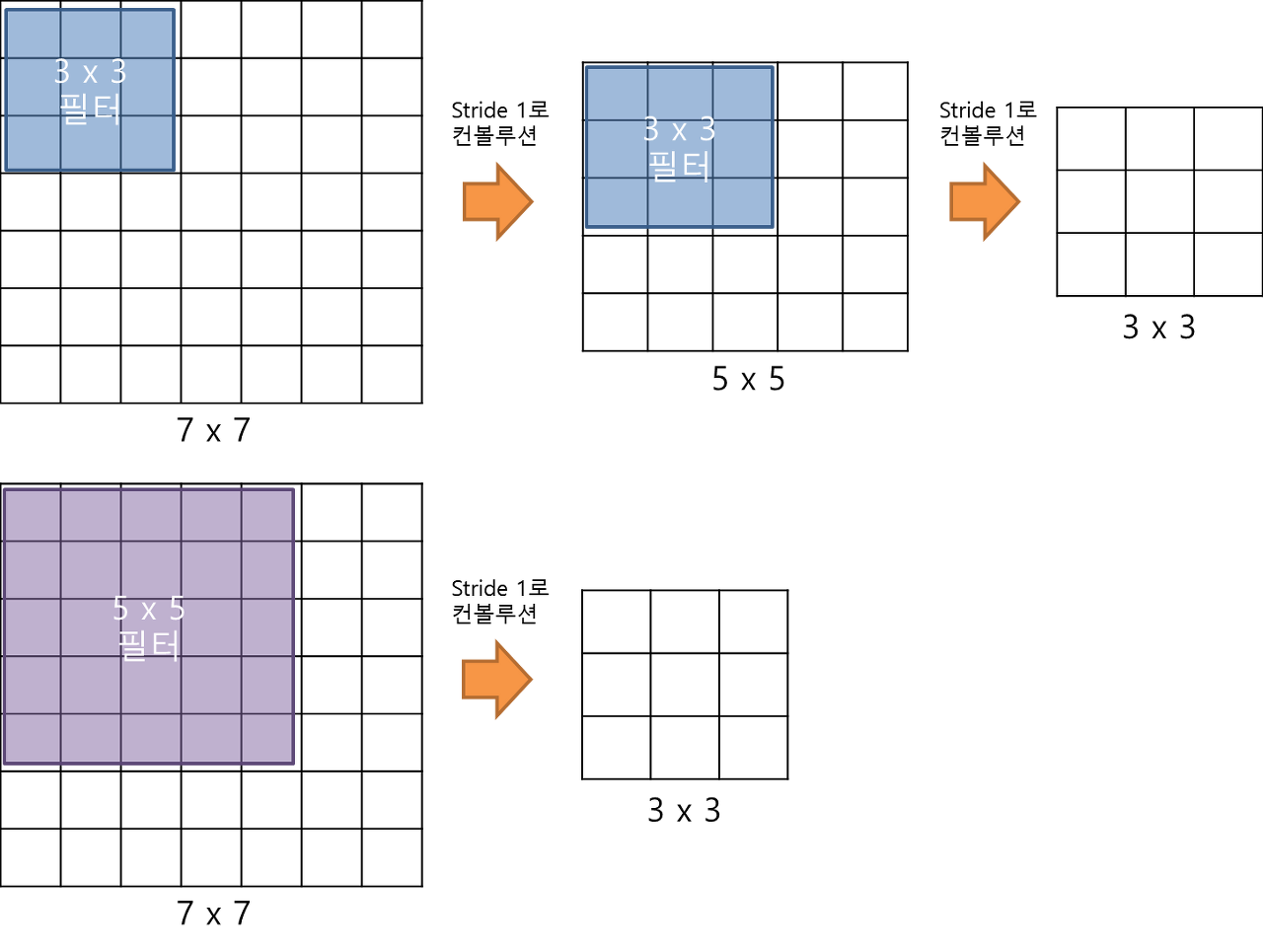
상대적으로 큰 크기의 필터가 아닌 작은 필터를 사용.
ex) 대신 개의 대신 개의
Why?
1) 더 많은 conv layer을 통과 = 더 많은 ReLU 함수 통과. 이는 non-linear한 의사결정에 유용.
2) params의 수가 줄어듦.
3. Classification Framework
3.1 Training
Cost function
Multinomial logistic regression objective = Cross entropy
Mini batch
size =
Optimizer
momentum =
Regularization
weight decay :
dropout =
Learning rate
learning rate = (decreased by a factor of )
AlexNet에 비해 params의 수도 많고 depth도 크지만, 수렴까지의 epoch는 적음.
Why?
1) Implicit regularisation
작은 필터 크기를 사용 ( 대신 3개의 사용).
2) Pre-initialisation
Configuration A의 처음 4개의 conv layer와 마지막 3개의 fc layer의 가중치를 이용하여 초기값 설정.
(첫 초기 가중치는 normal distribution with the zero mean and variance)
Training image size
를 훈련 이미지 (cropped)의 짧은 변이라 할 때, (training scale이라고도 함)
는 보다 커야하고 rescale 시에 isotropy를 유지해야함.
training scale 를 설정하는 두 가지 방법.
1) Single-scale training
를 또는 로 고정.
= 으로 훈련을 하고, 이때의 가중치 값을 = 모델의 초기 가중치 값으로 사용. learning rate는 으로 줄임.
2) Multi-scale training
각각의 훈련 이미지를 에서 랜덤하게 를 rescale함.
()
다른 크기의 이미지 훈련은 학습 효과에 도움이 됨. 이를 scale jittering에 의한 augmentation으로 보는 경우도 있음.
3.2 Testing … help
isotropical하게 이미지의 짧은 변 를 rescale (test scale이라고도 함).
※ 와 가 같을 필요없으며, 에 따른 다양한 값이 학습 향상에 도움.
Fully-convolutional net
첫번째 fully-connected layer은 conv. layer.
두번째, 세번째 fully-connected layer은 conv. layer.
About Reference
딥러닝 Segmentation(3) - FCN(Fully Convolution Network)
이를 전체 uncropped 이미지에 적용.
결과를 class score map이라 함.
class score map을 average pooling에 적용.
4. Classification Experiments
Dataset으로 ILSVRC-2012 사용.
분류 성능 평가를 위해 두 가지 척도를 사용.
1) top-1 error : multi-class classification error.
2) top-5 error : main evaluation criterion used in ILSVRC.
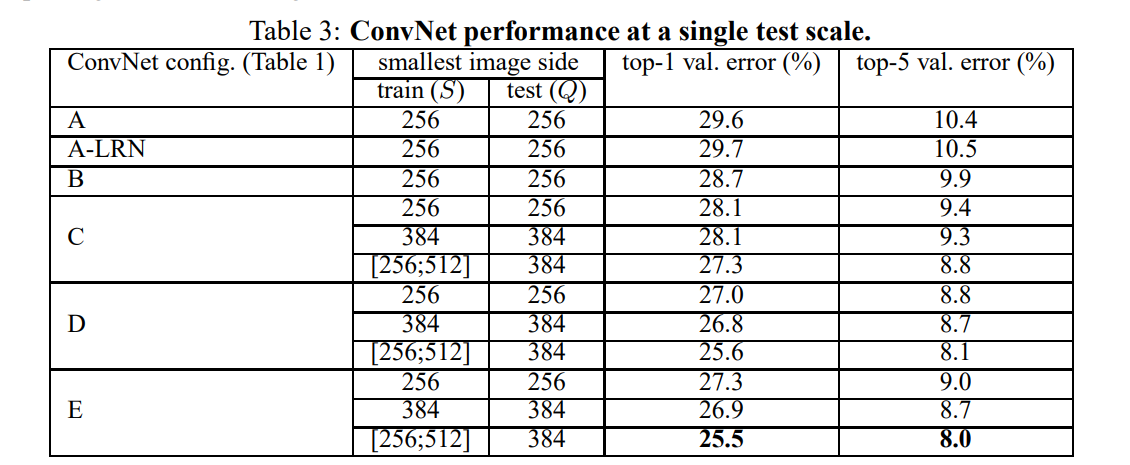
4.1 Single Scale Evaluation
Single scale : test size for fixed ( or ).
Multi scale : test size for jittered
1) LRN는 학습에 도움이 되지 않으므로, A-LRN 이후로 사용하지 않음.
2) error는 ConvNet의 depth가 증가함에 따라 감소. 또한 conv. layer가 conv. layer보다 비선형성을 더 부여하지만, conv. layer가 공간 정보를 더 잘 capture하므로 성능 우수.
3) scale jittering ()이 fixed 보다 성능 우수.
convolution의 의미
1) # of filters 조절
input의 # of channels보다 # of filters를 작게하여, output의 가로와 세로 크기는 유지하되 depth를 줄임.
2) 연산량 감소
# of filters의 감소는 연산량 감소. 이는 네트워크의 depth 증가.
※ Bottleneck 구조 : # of channels가 감소하였다가 증가하는 구조.
3) Non-linearity 증가
ReLU가 더 많이 사용되었으므로 비선형성 증가.
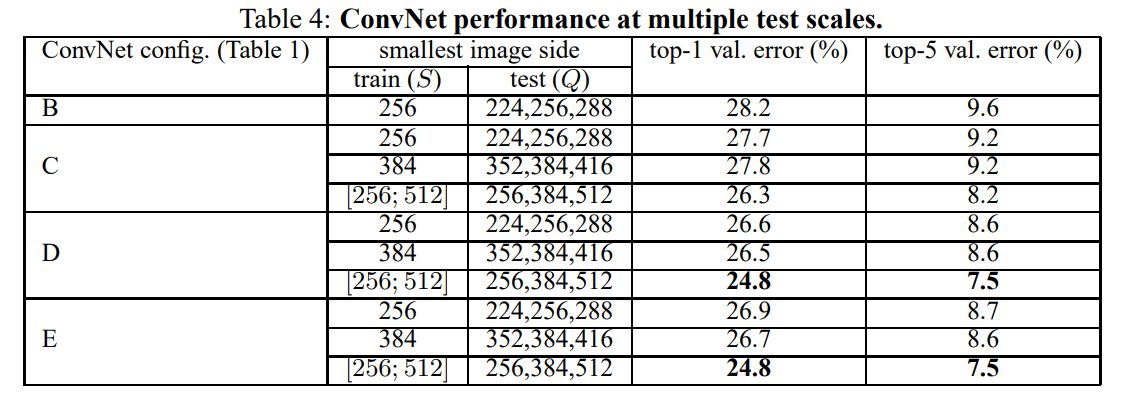
4.2 Multi-Scale Evaluation
Singe scale : test size
Multi scale : test size
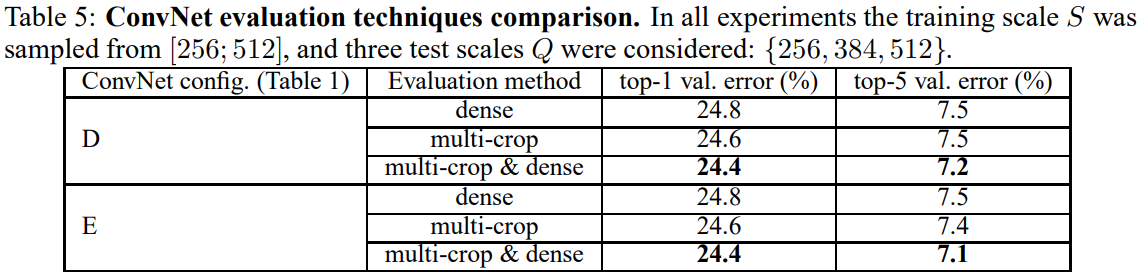
4.3 Multi-Crop Evaluation
dense < multi-crop < multi-crop & dense
5. Conclusion
The representation depth is beneficial for the classification accuracy.
Reference
VGGNet 논문
VGGNet (Very Deep Convolutional Networks for Large-Scale Image Recognition) 논문 리뷰
VGG16 논문 리뷰 — Very Deep Convolutional Networks for Large-Scale Image Recognition
[CNN 알고리즘들] VGGNet의 구조 (VGG16)
[DL - 논문 리뷰] Very Deep Convolutional Networks for Large-Scale Image Recognition(VGG)
FCN 논문 리뷰 — Fully Convolutional Networks for Semantic Segmentation
