VGG-16
13 Convolution layers + 3 Fully-connected layers = 16 layers
convolution filters (stride = , padding = )
max pooling (stride = )
Architecture
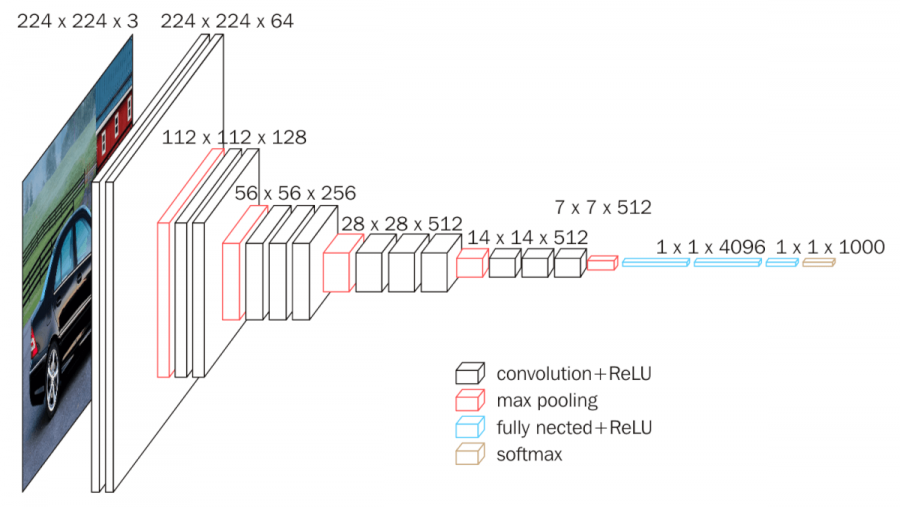
Input
image.
1) Conv 1_1
convolution : 64개의 kernels (stride = , padding = )
activate by ReLU
⇒ 64개의 feature maps
2) Conv 1_2
convolution : 64개의 kernels (stride = , padding = )
activate by ReLU
⇒ 64개의 feature maps
max pooling (stride = )
⇒ 64개의 feature maps
3) Conv 2_1
convolution : 128개의 kernels (stride = , padding = )
activate by ReLU
⇒ 128개의 feature maps
4) Conv 2_2
convolution : 128개의 kernels (stride = , padding = )
activate by ReLU
⇒ 128개의 feature maps
max pooling (stride = )
⇒ 128개의 feature maps
5) Conv 3_1
convolution : 256개의 kernels (stride = , padding = )
activate by ReLU
⇒ 256개의 feature maps
6) Conv 3_2
convolution : 256개의 kernels (stride = , padding = )
activate by ReLU
⇒ 256개의 feature maps
7) Conv 3_3
convolution : 256개의 kernels (stride = , padding = )
activate by ReLU
⇒ 256개의 feature maps
max pooling (stride = )
⇒ 256개의 feature maps
8) Conv 4_1
convolution : 512개의 kernels (stride = , padding = )
activate by ReLU
⇒ 512개의 feature maps
9) Conv 4_2
convolution : 512개의 kernels (stride = , padding = )
activate by ReLU
⇒ 512개의 feature maps
10) Conv 4_3
convolution : 512개의 kernels (stride = , padding = )
activate by ReLU
⇒ 512개의 feature maps
max pooling (stride = )
⇒ 512개의 feature maps
11) Conv 5_1
convolution : 512개의 kernels (stride = , padding = )
activate by ReLU
⇒ 512개의 feature maps
12) Conv 5_2
convolution : 512개의 kernels (stride = , padding = )
activate by ReLU
⇒ 512개의 feature maps
13) Conv 5_3
convolution : 512개의 kernels (stride = , padding = )
activate by ReLU
⇒ 512개의 feature maps
max pooling (stride = )
⇒ 512개의 feature maps
14) Fc1
feature maps을 flatten
⇒ neurons
Fc1의 4096개 neurons와 fully-connected.
Dropout 적용.
⇒ 4096개 neurons
15) Fc2
Fc2의 4096개 neurons와 fully-connected.
Dropout 적용.
⇒ 4096개 neurons
16) Fc3
Fc3의 1000개 neurons와 fully-connected. (※ = # of classes)
activate by softmax
Reference
[CNN 알고리즘들] VGGNet의 구조 (VGG16)
VGG16 – Convolutional Network for Classification and Detection
