
어우 진짜,, 피곤하다. OS 과제에 아무 말이나 써재꼈는데도 뇌 제일 깊숙한 곳부터 쪽쪽 빨려나간 느낌이다.
Paging을 주제로 하는 세번째 장이다. 흐름을 대강 떠올려보자면,,
먼저 Paging을 처음 도입했을 때, 주소 공간을 빈틈 없이 분할하여 관리하기 때문에 External fragmentation이 발생하지 않으며, Segmentation보다 상대적으로 개념이 단순해 관리하기 좀 편하다는 장점이 있었다.
그러나 연결 정보를 Page Table에 저장하기 때문에 아무래도 페이지가 많아질수록 메모리를 엄청 잡아먹고, 이전에 배웠던 Base & Bound, Segmentation 기법과 달리 주소 변환 과정에서 Page table을 몽땅 뒤져본다던지, TLB Hit/Miss 관련 handling이 추가되어서 시간도 더 오래 걸렸다.
그래서 저번 장의 TLB(Translation Lookaside Buffer)를 통해 이 연결 정보를 Caching해서 Locality를 이용해 빠르게 주소 변환을 수행할 수 있는 것까지 공부했다.
이제 Page table 자체가 너무 많은 공간을 점유하는 이슈가 남았는데, Page Table이 대충 얼마나 크길래 이렇게 호들갑인건지, 저번에 계산했던 내용을 다시 읽어보자.
어림잡아 한 페이지가 4KB=2^12B인 32bit 주소 공간의 경우 Offset이 12비트이므로 VPN은 20비트가 된다. (헷갈리면 위의 설명을 천천히 다시 읽어보자.) 이 2^20=1,048,576개에 해당하는 연결 정보를 싹 저장하려면,,? 각각의 연결 정보 묶음(PTE, Page table entry) 하나당 4Byte가 필요하다고 가정했을 때 총 2^(20+2)Byte=4MB가 필요하다.
어우 프로세스 하나에 4MB라고? 프로세스가 100개면 Page Table만 자그마치 400MB다. 줄여보자.
20.1. Simple Solution: Bigger Pages
주소 공간의 비트 길이는 딱 정해져 있으므로, VPN과 Offset은 서로 한쪽이 커지면 한쪽이 그만큼 작아지는 관계이다. 왜 그런지는 18.1의 'Paging에서의 주소 변환'에 설명해 두었으니 혹시 기억이 안난다면 참고하자.
만약 주소 공간이 32bit이고, 페이지 크기를 4KB에서 16KB로 4배 늘어났다고 가정해보자.
원래 페이지의 크기와 같은 의미를 가지는 Offset이 총 (2+10)=12bit였으니, 여기서 페이지 크기가 4배 늘어난다고 하면 Offset이 14bit로 늘어나는 것이므로 VPN은 18bit로 줄어든다.
즉, 주소 공간 안에 페이지가 총 2^18개만큼 존재하게 되는 의미이므로 PTE의 크기를 4Byte로 잡으면 2^(18+2) = 2^20 = (2^10) * (2^10) = 1MB로 기존 크기의 1/4가 되었다. 왜냐? 페이지의 갯수가 1/4로 줄었으니까!
그러나 문제는,, 이렇게 페이지 크기를 너무 크게 잡아버리면 메모리를 무조건 페이지 단위로만 떼어 줘야 하기 때문에 주어진 페이지의 크기보다 페이지를 조금만 사용할 때 발생하는 Internal fragmentation이 더 심해진다. 이렇게 되면 페이지를 쪼금씩만 떼어 준 것 같은데 어느새 페이지를 몽땅 내어줘버리는데, 심지어 놀고 있는 공간이 많아지는 것이기 때문에 그다지 좋은 선택지는 아닐 것이다.
20.2. Hybrid Approach: Paging and Segments
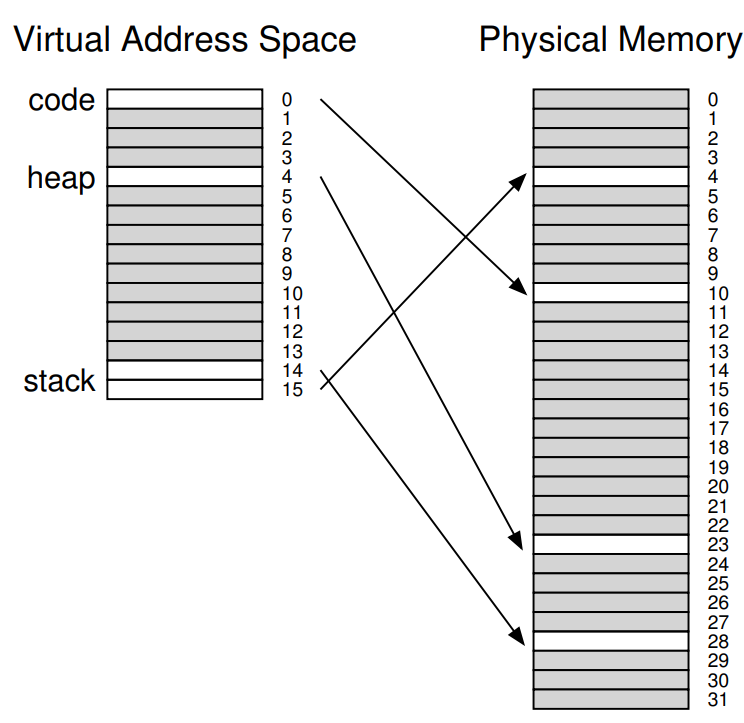
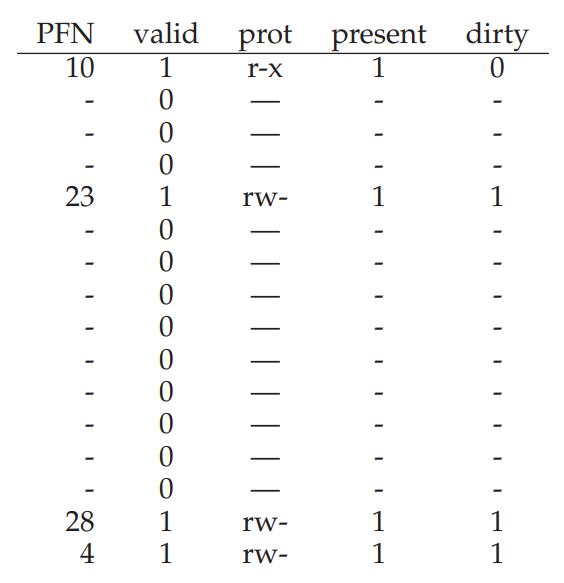
위의 16개의 1KB짜리 페이지를 가지는 주소 공간과 물리 메모리의 상태를 보면, Code, Heap, Stack에 해당되는 페이지를 다 합쳐도 4개의 페이지밖에 안되는데 무려 16개의 Page table을 점유하고 있는 상황임을 알 수 있다. 25%만을 위해 빈 연결 정보까지 몽땅 저장해야 한다니, 엄청 비효율적이지 않은가? 어우 0이 몇개여,,
어디서 많이 본 상황인데, 마치 Base & Bound에서 사용하지 않는 공간이 가운데 낑겨 있는 낭비인 Internal fragmentation 같지 않은가? 이걸 Segmentation으로 해결했었으니, Segmentation에서 아이디어를 빌려 Code, Heap, Stack을 따로 관리하도록 해보면 어떨까? 물론 관리 대상은 페이지일 것이다.

마치 Segmentation에서 각각의 Segment를 표현하기 위해 Base, Bound Register를 사용했듯 각각의 Code, Heap, Stack에 속하는 페이지가 저장된 영역을 위와 같이 2개의 Seg bit를 사용할 수 있을 것이다. (Code, Heap, Stack 영역을 표현하기 위한 Seg bit는 저번과 달리 각각 01, 10, 11로 하자. 00은 미사용!)
또한 Segmentation에서 그러했듯 HW에 각각의 영역을 표현하기 위한 Base, Bound 값을 저장할 레지스터를 사용한다고 가정하자. 그럼? 당연히 Page table 역시 영역별로 하나씩 총 3개로 늘어날 것이다.
SN = (VirtualAddress & SEG_MASK) >> SN_SHIFT
VPN = (VirtualAddress & VPN_MASK) >> VPN_SHIFT
AddressOfPTE = Base[SN] + (VPN * sizeof(PTE))
Segmentation에서 따온 특성들을 위와 같이 코드로 쓸 수 있는데, Bit masking과 shift는 이미 익숙할테니 넘기고 AddressOfPTE만 보자.
VPN은 익숙할테고, 보다시피 SN은 Segment bits로, 가상 공간 내의 어떤 Page segment(?) 영역에 해당 주소가 속해있는지를 표시하고 있고, Base[SN]을 해당 Segment의 Page table이 저장된 첫 시작 주소, (VPN * sizeof(PTE))를 Page table 내에서의 Offset이라 하면 AddressOfPTE도 뚝딱! 이해할 수 있다.
Base[SN]을 제외하면 다른건 다 비슷한데, 이전처럼 하나의 Linear한 table이 아니라 3개의 table을 관리해야 하기 때문에 Context switching 발생시 각각의 Page segment의 Base, Bound 정보 역시 저장/복구해야 한다는 점을 잊지 말아야 한다.
...
이 방법이 어떻게 메모리를 절약하고 있는건지 잘 와닿지 않을 수 있는데, Segmentation과 Paging을 적절히 섞은 이 Hybrid 방법의 제일 중요한 포인트인 Base, Bound 값에 주목해볼까?
그냥 Linear한 Page table만 있었을 때 Page table에서 미사용중인 엔트리를 위해 페이지 전체 갯수만큼 Row를 유지해주어야 하는 이유가 무엇이었는지 다시 떠올려보자. 배열에서 메모리를 쭈욱 연속적으로 할당해 놓으면 index를 통해 임의로, 그러니까 O(1)의 시간 복잡도로 접근할 수 있다는 장점이 있는데, 이를 이용해서 해당 Entry의 Valid bit를 확인해 Segmentation fault를 발생시킬지 말지 결정할 수 있었다. 의도는 좋았는데 생각보다 주소 공간을 많이 사용하지 않는 경우에 이게 낭비가 되었던거고,,
그런데 Hybrid 방법에서는 Base와 Bound, 그러니까 점유하고 있는 메모리의 경계를 저장해 놓고 사용하기 때문에 어떤 Segment에 속해 있는지(Seg bits), 어느 위치에 접근하려고 하는지(VPN, Offset) 알면 Invalid bit로 기록되어 있는 영역까지 표시할 필요 없이 그냥 Base & Bound로 알아낸 경계 안에 들어 있는지만 확인해서 Segmentation fault를 발생시키든, 정상적으로 메모리에 접근할 수 있도록 하든 할 수 있기 때문에 메모리가 기록하지 않은 Invalid entry의 수만큼 절약되는 것이다.
위의 예제의 경우 원래같았으면 16개의 Entry를 몽땅 관리해야 했겠지만, Hybrid 방식을 사용하면 Code에서 1개, Heap에서 1개, Stack에서 4개, 총 6개만 저장하면 된다! 무려 10개만큼 절약!
엥? 왜 Stack은 4개냐고? 구현하기 나름이겠지만 일단은 Segmentation과 마찬가지로 stack의 메모리가 거꾸로 크기 때문이라고 한다. Offset을 사용해서 실제 접근할 물리 주소를 계산하는 방법도 같다는 거지. 기억이 잘 안나면 Segmentation 부분을 다시 읽어보고 오자!
...
그런데 이 Hybrid 기법이 Segmentation으로부터 아이디어를 따오다 보니까 단점도 같이 들고왔다.
첫째로 주소 공간이 듬성듬성 사용되는 Sparse address space에서 사용하기에는 아직 충분히 유연하지 못하다는 점인데, Heap Page를 많이 할당해놨는데 생각보다 Memory allocation이 적은 경우 마찬가지로 wasting이 발생하는 문제를 예로 들 수 있겠다. 미세 콘츄롤이 안된달까,,
둘째로는 Bound가 자유분방한 특징(=Segment에 Page entry를 원하는 만큼 사용할 수 있다)으로 인해 다시 돌아온 External fragmentation 되시겠다. 주소 공간 안에서 Segment를 벗어난 부분은 다 버려?! 안되지!
20.3. Multi-level Page Tables
이렇듯 Hybrid 방식에도 한계가 분명하기 때문에 다른 방법으로 Page table의 크기를 줄여야 한다.
그래서 이번에 배울 방법이 바로 Multi-level Page Table 기법인데, 이름의 유래는 지금까지 사용하던 Linear한 Page table을 Single-level Page Table이라 생각하면 좀 더 와닿을 것 같다. Page table 구조를 트리로 표현한다는 것이다!
Multi-level page table에서는 마치 DB에서 Foreign key를 찾아가는 모양새와 비슷하다. 다만 다른점이 있다면 테이블의 요소가 다른 테이블의 요소를 가리키는게 아니라, 테이블의 요소가 다른 테이블을 참조하는 형태를 따른다는 점이다.
여기서 변환 정보에 접근하기 위해 가장 먼저 접근하는 자료 구조(테이블)를 Page Directory라 하는데, 이 테이블에는 요소로 가지고 있는 페이지 테이블의 위치와 사용 여부를 기록한다. 만약 Page Directory에서 사용하지 않는 페이지 테이블에 접근하려고 시도하면 Segmentation fault를 발생시키고, 실제로 사용중인 Page table임을 확인하면 이 Page Directory Entry(PDE)가 가리키는 Page table로 이동해 VPN으로 원하는 PFN을 찾아 주소 변환을 수행해주면 끝!
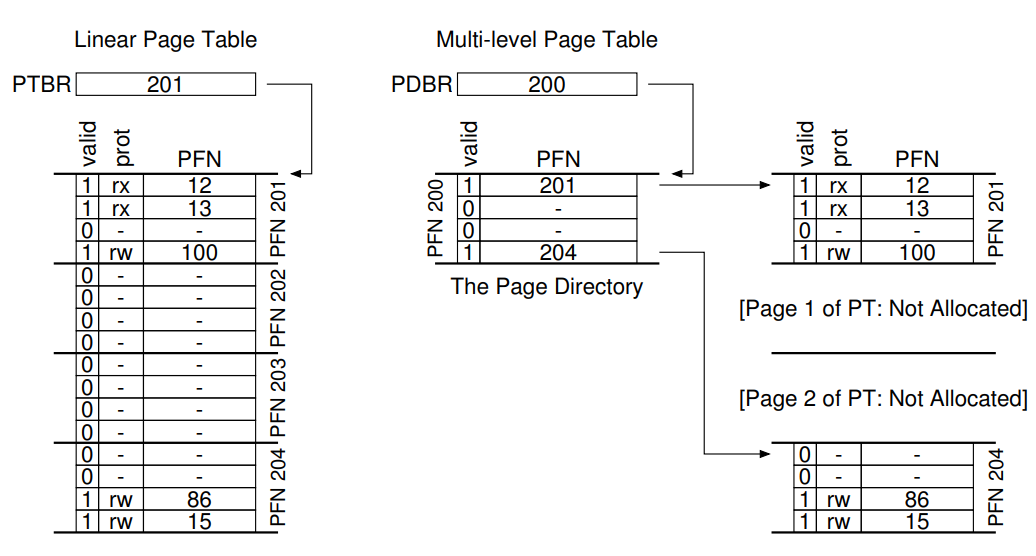
그림으로 보면 편한데, 선은 그려져 있지 않지만 왼쪽이 지금까지 쓰던 Linear Page Table이고, 오른쪽의 두 단계로 나뉘어진 그림이 Multi-level Page Table이다.
왼쪽의 single level page table을 유지하려면 실제로는 5개의 페이지만 사용하고 있으면서도 Invalid를 표시하기 위해 15개의 페이지에 대한 빈 칸까지 표시해야 했는데, 오른쪽을 보라! PFN 202과 203에 속하는 페이지를 사용하고 있지 않으니 아예 기록하지 않고, 실제로 사용중인(valid=1) 201, 204 페이지에 대한 연결 정보가 저장된 곳을 Page Directory에 기록하여 각각의 Page Table로 찾아가게 함으로써 총 5개의 Entry를 덜 저장하게 되었다. 지금이야 엥 5개밖에 안돼? 할 수 있겠지만 Sparse한 메모리 공간일수록 Multi-level page table의 강점이 더욱 부각될 것이다.
또한 이전의 TLB에서 Valid bit에서 그랬던 것처럼 Page Table에서 valid bit와 Page directory에서 valid bit의 의미가 좀 다르다는 것을 꼭 숙지해야 한다. 규모의 차이랄까?
그냥 Linear page table을 쓸 때에는 그냥 각각의 entry가 {가상 주소 <-> 물리 주소} 변환 정보에 해당하는 PTE였기 때문에 valid bit가 false이면 그냥 사용중인 공간이 아니라는 의미였는데, Page directory에서 valid bit는 해당 Entry가 가리키는 Page table을 사용하고 있지 않음을 표시한다는 점이 다르다. 즉 페이지의 사용 여부가 아니라, 페이지들을 포함하고 있는 일정 구간이 통째로 미사용중이라는 것!
또 하나, Single level page table에서는 MMU에 PTE가 저장되어 있는 Page table의 시작 주소를 PTBR(Page Table Base Register)에 기록해 놓고 Page table을 찾아갔는데, Multi level page table에서는 Page table을 직접 가리키는게 아니라 Page table이 저장된 위치와 사용 여부를 기록하는 Page directory를 먼저 가리키기 때문에 PDBR(Page Directory Base Register)에 값을 기록해 놓고 사용한다.
Multi-level Page Table의 장점
장점을 정리해보자.
-
언급했듯 이전의 Single-level Page Table과 달리 딱 사용하는 만큼에 최대한 가깝게 메모리를 사용해서 주소 공간을 표현할 수 있기 때문에 공간 측면에서 효율적이다.
-
Page table을 Entry로 취급하여 Page Directory에 저장하기 때문에 메모리 관리 측면에서 더 편하다.
왜냐? Single-level Page Table 같았으면 Entry 하나하나가 연속된 페이지를 의미하기 때문에 큰 크기의 공간을 할당받으려 할 때 연속된 큰 공간을 찾기가 쉽지 않았을텐데, 만약 Multi-level Page Table에서 연속된 빈 공간을 찾는다면 그냥 Page Directory에서 valid bit가 0인 Entry를 찾아다가 쓰라고 넘겨주면 된다. 어차피 해당 PDE가 가리키는 Page Table은 Page Directory까지만 봐도 미사용중임을 알 수 있기 때문이다.
Multi-level Page Table의 단점
장점이 있으면 단점도 있는법.
- 전에 배운 TLB를 사용한다고 할 때, TLB Miss가 발생하는 경우 이전에는 한 번만 메모리에 접근하면 됐지만 Multi-level Page Table을 사용하면 Page Directory에 한 번, PDE를 사용해서 Page Table에 한 번, 총 두 번의 메모리 액세스가 필요해진다. 공간을 줄인건 좋았는데, 메모리 액세스에 소요되는 시간이 꽤 길다보니 아무래도 좀 뼈아프다.
- 보면 알겠지만, Single-level Page Table에 비해 구현하기 복잡하다! 레지스터도 늘었고, 주소 변환 단계도 늘었고, Context switching시 저장/복구해야 할 데이터도 좀 더 복잡해졌고,,,
A Detailed Multi-Level Example
Multi-Level Page Table이 어떻게 생겼는지 배웠으니, 예제를 통해 주소 변환 과정을 따라해보자.
여기서는 64B짜리 페이지 256개를 가지는 16KB의 주소 공간을 가정한다. 페이지 크기가 64B니까 Offset은 6bit이고, 주소 공간이 2^14B니까 14bit 중 나머지인 8bit가 VPN으로 사용될 것이다.

가상 주소 공간은 위와 같이 생겼는데, 보다시피 0x00, 0x01은 code, 0x04, 0x05는 heap, 0xfe, 0xff는 stack으로 사용되고 있는, 매우 Sparse한 상태이다. 총 2^8개 페이지 중에 단 6개만 사용하고 있으니 사용률이 채 3%가 못된다.
이 주소 공간을 그럼 2-level page table을 사용해서 관리해보자!
일단 PTE 하나당 4Byte라고 가정하면, Linear page table을 사용하는 경우 얄짤없이 Page Table에 PTE가 모두 들어가기 때문에 크기가 256*4=1KB가 되었을 것이다. 물론 Page table도 메모리에 Page로 저장되기 때문에 페이지수를 계산해보면,, 1KB/64B=64이므로 총 16개의 Page로 구성될 것이다.
마침 페이지도 딱 16개니까, Page table을 16개로 쪼개보자.
즉 Page Directory 안에 16개의 PDE를 저장한다는 의미이므로, Page Directory에서 PDE를 각각 구분하려면 VPN중 총 4bit가 필요할 것이다.
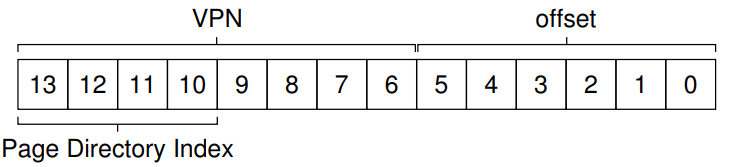
저 Page Directory Index를 PDIndex라 하면, PDEAddr = PageDirBase + (PDIndex * sizeof(PDE)) 식을 사용해 PDE가 저장된 주소를 찾을 수 있을 것이다.
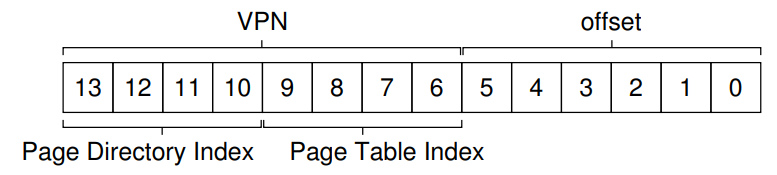
찾아낸 PDE를 참조해서 valid bit가 0이면 Segmentation fault를 발생시키고, 1이면 해당 PDE에 저장된 Page Table의 PFN을 받아다가 다시 Page Table로 찾아간다고 했는데, 이 경우 Page Table Index(줄여서 PTIdex)를 사용해 Page Table 안에서 어떤 PTE에 접근하려는건지 계산식 PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))에 의해 알 수 있게 되어, 비로소 주소 변환을 수행할 수 있게 된다.
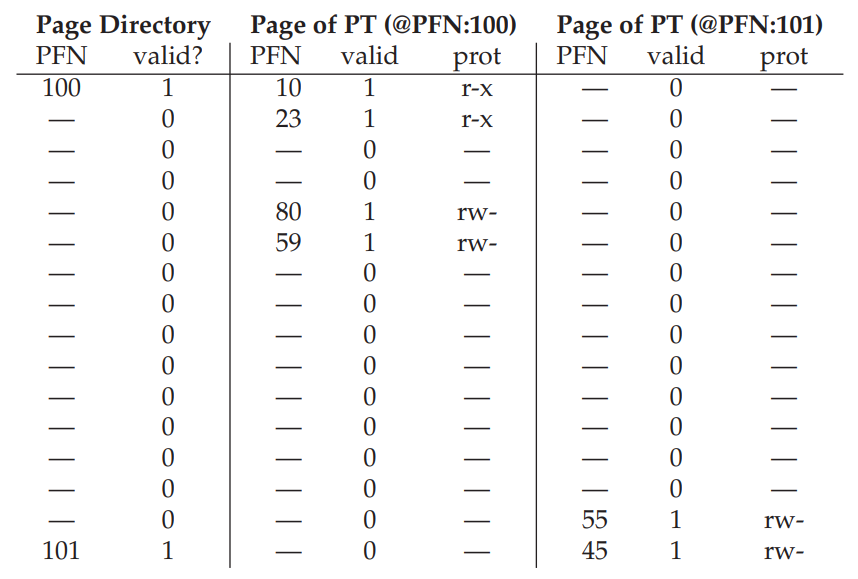
Page Directory가 8개의 PDE를 가지고 있고, 그 중 PDIndex가 0000, 1111인 Entry만 Valid 하므로 해당 PDE가 가리키는 PFN 100, PFN 101에 저장된 Page Table 내부에 소속된 각각의 PTE가 한 페이지(64Byte) 안에 저장되어 있는 상황이다.
여기에 실제 값을 넣어서 한 번 계산해보자. Stack 영역에 속하는 VPN 254의 시작 주소(000000)으로 해볼까?
VPN 254 = 1111 1110, Offset 000000이므로 가상 주소는 1111 1110 000000이다.
여기서 최상위 4bit는 PDIndex, 그 다음 4bit는 PTIndex, 나머지 6bit는 Offset이므로 일단 PDIndex 1111을 들고 Page Directory에 가본다.
똑똑! 1111 위치를 확인해 봤는데, PDE에 해당 Page Table이 표시하고 있는 공간이 Valid하다고 한다. 그럼 해당 PDE에 저장되어 있는 Page Table의 위치 PFN을 사용할 수 있다는 의미이므로 확인해본다. 101이네!
그럼 주어진 PFN 101을 참고해서 다시 메모리에 액세스하면 Page Table이 있을 것이다. 빙고!
여기서 아까 빼놓은 PTIndex 1110을 사용해 접근하려는 변환 정보가 저장된 PTE를 확인해 봤더니, valid bit가 1이므로 해당 연결 정보가 유효하다는 의미이다. 따라서, VPN 254와 연결된 PFN이 55임을 드디어 알게 되었다.
이제 얻어낸 PFN과 Offset을 합친 00 1101 1100 0000 = 0x0DC0이 최종적으로 실제 접근하고 싶은 물리 메모리 주소임을 알아내었다. 와!
More Than Two Levels
2-level page table이 가능하다면 그 이상의 계층도 가능하지 않을까?
512B 크기의 Page를 가지는 30Bit의 가상 주소 공간을 생각해보자. 페이지의 개수가 2^(30-9)=2^21개이므로 VPN은 21bit, Offset은 9bit를 사용할 수 있겠다.
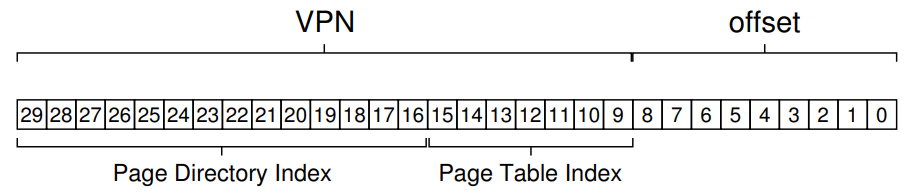
위에서 Page 단위로 Linear page table을 두 단계로 분할했듯, 일단은 한 페이지에 몇 개의 Entry를 저장할 수 있을지를 먼저 계산해야 그 위에서 몇 개의 계층을 만들지 정할 수 있다.
Entry 하나당 4Byte라고 하면, 한 페이지의 크기가 512B니까 페이지당 2^7=128개의 Entry가 들어갈 수 있으므로 VPN 21bit 중 하위 7bit는 PTIndex로 사용할 수 있을 것이다.
8bit는 안되냐고? 된다! 이때는 하나의 Page table에 저장된 entry의 개수가 2배인 256개가 되겠지? (여기서는 7bit만 쓰자.)
그럼 VPN중 PDIndex로 쓸 수 있는 bit가 14bit 남았는데, 이걸 그냥 Page Directory로 사용하는데 냅다 써버리면 Sparse한 메모리 공간의 경우 Invalid entry가 Valid entry보다 훨씬 많아지기 때문에 Multi-level paging의 본 취지와 어긋나게 된다.
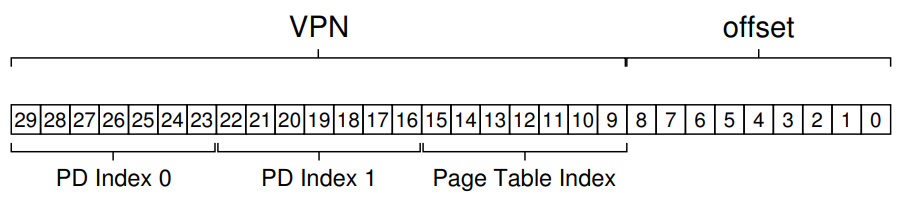
그래서! 여기서 2-level paging이 아니라 3-level paging으로 위와 같이 확장할 수 있다. 아까와 달리 두 번째로 접근하는 자료 구조가 Page Table이 아니라 Page Directory가 되었고, PDE에 두번, PTE에 한 번 접근해야 Physical Address를 계산할 수 있게 되었다.
The Translation Process: Remeber the TLB
HW-managed TLB, 2-level page table을 사용해 주소 변환을 수행하는 과정을 수도 코드로 표현하면 아래와 같다.
VPN = (VirtualAddress & VPN_MASK) >> SHIFT
(Success, TlbEntry) = TLB_Lookup(VPN)
if (Success == True) // TLB Hit
if (CanAccess(TlbEntry.ProtectBits) == True)
Offset = VirtualAddress & OFFSET_MASK
PhysAddr = (TlbEntry.PFN << SHIFT) | Offset
Register = AccessMemory(PhysAddr)
else
RaiseException(PROTECTION_FAULT)
else // TLB Miss
// first, get page directory entry
PDIndex = (VPN & PD_MASK) >> PD_SHIFT
PDEAddr = PDBR + (PDIndex * sizeof(PDE))
PDE = AccessMemory(PDEAddr)
if (PDE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else
// PDE is valid: now fetch PTE from page table
PTIndex = (VPN & PT_MASK) >> PT_SHIFT
PTEAddr = (PDE.PFN << SHIFT) + (PTIndex * sizeof(PTE))
PTE = AccessMemory(PTEAddr)
if (PTE.Valid == False)
RaiseException(SEGMENTATION_FAULT)
else if (CanAccess(PTE.ProtectBits) == False)
RaiseException(PROTECTION_FAULT)
else
TLB_Insert(VPN, PTE.PFN, PTE.ProtectBits)
RetryInstruction()PDE가 추가된 것 말고는 이전과 같으므로, 따로 일일이 부연 설명을 하지는 않겠다.
여기서 중요한건 TLB Miss가 발생한 경우 Memory Access가 2회 발생한다는 것이다. TLB Miss case만 추적해보자!
- VPN으로 TLB Lookup을 수행했으나, TLB에 해당 정보가 저장되어 있지 않아 TLB Miss가 발생
- VPN으로부터 PDIndex를, PDIndex와 PTBR을 사용해 Page Directory로부터 PDE를 얻어온다. (메모리 접근 발생)
- PDE로부터 Page Table이 저장된 위치를, VPN으로부터 PTIndex를 사용해 Page Table로부터 PTE를 얻어온다. (메모리 접근 발생)
- 얻어온 PTE으로부터 PFN을, 가상 주소로부터 Offset을 얻어와 Physical Address를 계산한다.
- 다시 명령어의 처음으로 돌아가서 TLB Hit -> 메모리 접근까지 완료한다.
만약 3-level paging을 사용했다면? Memory Access가 3회 발생했을 것이다.
20.4. Inverted Page Tables
지금까지 배운 Hybrid, Multi-level paging보다 더 참신한 메모리 절약 방법이 있는데, 바로 Inverted page table이다.
앞의 두 방식과 달리 Page table을 프로세스마다 하나씩 두어 여러개 관리하는게 아니라 시스템 전체에 걸쳐 있는 단 하나의 Inverted page table을 사용하는데, 이 테이블은 VPN을 PFN으로 변환하는게 아니라 PFN을 VPN으로 변환하는데 사용된다.
이게 뭔 소린가 싶은데,, 어차피 가능한 모든 VPN-PFN 연결 관계 중 사용하는건 일부이므로 Hash 같은 자료 구조를 사용해서 O(1)의 시간 복잡도로 빠르게 검색할 수만 있다면 Multi-level paging보다 더 많은 공간을 절약할 수 있다고 한다. 와! 어떻게 돌아가는 건지는 나중에 공부해보고 올리겠다.
20.5. Swapping the Page Tables to Disk
기억이나 날지 잘 모르겠지만, Memory virtualization 도입부에서 모든 데이터가 커널 소유의 물리 메모리 어딘가에만 존재한다고 가정했다. Page table도 마찬가지이고(중요하다).
위의 Hybrid, Multi-level, Inverted paging 방법 등을 총동원해서 꾸역꾸역 크기를 줄인다고 해도, 기술이 발전함에 따라 도저히 메모리에는 이 모든 정보들을 다 올릴 수 없는 지경에 이를지도 모른다.
그럴 때를 위하여 어떤 시스템들은 Page table들을 Kernal virtual memory(뭔지 잘 모르겠다)에 저장하거나, 디스크와 서로 Swap해가며 해결한다고 한다. Swap은 다음 장에 배운다. 어렵지만 재밌는 부분이니 오늘 공부한 내용부터 꼭 잘 숙지하자.
마무리
Paging의 단점 중 하나인 공간 문제를 지혜롭게 해결해 보았다. 이번 장에서 중점적으로 배운 Multi-level paging의 경우 공간은 절약했지만, 메모리 액세스가 Table 계층 수만큼 더 발생하기 때문에 TLB Miss에는 상대적으로 취약하므로 이전과 마찬가지로 여러 기술들 사이에서 어떤 것을 선택할지 신중하게 선택해야 할 것이다.
휘유! 살짝 졸면서 쓴 것 같다. 내일은 하늘이 두쪽난대도 꼭 남은 2개 강의까지 정복해야 한다.
좀만,, 힘내자,,
