Quick Sort
병합 정렬처럼 숫자를 나누면서 정렬이 진행이 되기에 시간복잡도는 O(NlogN)이 됩니다.
하지만 시간은 병렬 정렬보다 빠릅니다.
특징
참조지역성(locality of reference)
공간(spaital)지역성: 특정 클러스터의 기억 장소들에 대해 참조가 집중적으로 이뤄지는 경향으로 참조된 메모리 근처의 메모리를 참조합니다.
시간(temporal)지역성: 최근 사용된 기억 장소들에 집중적으로 엑세스가 되는 경향으로 참조했던 메모리는 빠른 시간에 다시 참조될 확률이 높다
순차(sequential)지역성: 데이터가 순차적으로 엑세스되는 경향으로 명령어가 순차적으로 구성이 되어있습니다.
한 번 결정된 pivot값은 이후의 연산에서 제외가 되기에 빠릅니다.(데이터의 수가 줄어듭니다) 그리고, pivot의 인덱스는 바뀔 수 있고 pivot기준으로 왼쪽은 작은 값 이고 오른쪽은 큰 값입니다.
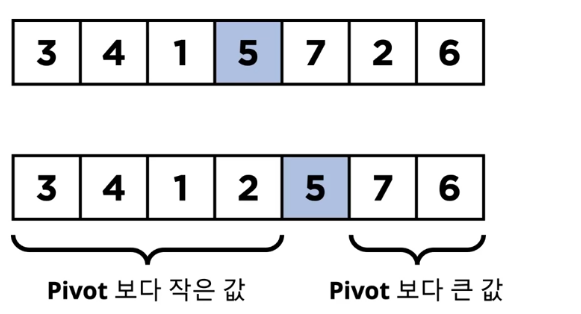
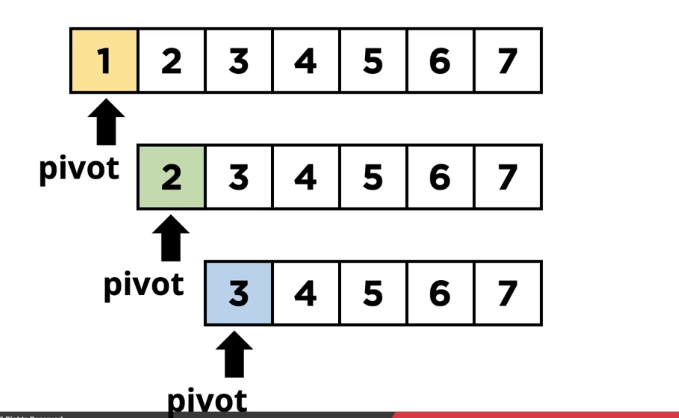
서브 리스트에서도 위에 했던 과정을 반복합니다.
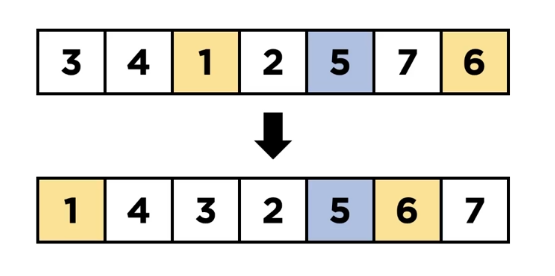
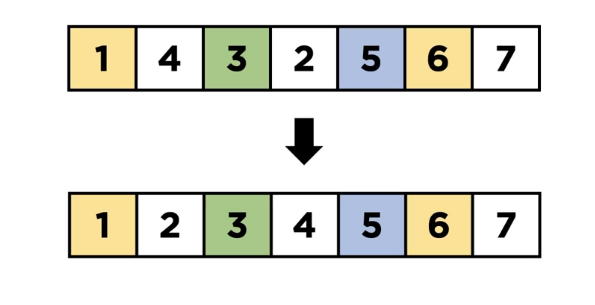
추가적인 메모리 사용 공간이 없습니다
한 번만 접근하고 나면 캐싱메모리로 처리하기에 추가 사용이 필요없습니다.
불안정 정렬입니다.
*시간복잡도
평균: O(NlogN)
최악은 정렬된 리스트:O(N^2)
CODE
def quick_sort(arr): #퀵 정렬
__sort(arr, 0 , len(arr) -1) #__sort에 배열, 인덱스 0, 전체길이 -1 이 들어있다
def __sort(arr, low, high): #__sort함수 정의
if low >= high: #low가 high보다 크다면
return #그냥 지나가라
pivot = (low + high) // 2 #pivot은 양 끝 점의 합/2 지점
pivot_val = arr[pivot] #pivo값은 배열의 부분(중간지점)
left, right = low, high #left = low, right = high할당
while left <= right: # left가 더 클 떄까지 진행
while arr[left] < pivot_val: #왼쪽값이 피봇보다 커질 때까지 진행
left += 1 #작은 상황이면 왼쪽으로 숫자 1개 생김
while arr[right] > pivot_val: #위의 상황이라면
right -=1 #오른쪽은 하나 줄어들죠
if left <= right:
arr[right], arr[left] = arr[left], arr[right]
left += 1
right -=1
__sort(arr, low, right) #__sort함수 적용
__sort(arr, left, high) #--sort함수 적용
if __name__ =="__main__": #main.py
arr = [9,1,6,3,7,2,8,4,5,0] #배열
quick_sort(arr) #퀵 정렬
print(arr) #결과값
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
성장을 도울 아카이빙 블로그