ViTPose 정리하다가 ViTPose 살펴보고, 이미지 태스크에서 CNN 기반 모델과 ViT가 어떤 구조적 차이점이 있을까 살펴보다가 거슬러 여기까지 온 이야기
pose estimationd task에서 좋은 성능을 보이던 CNN 기반의 모델들을 Vision Transformer가 어떻게 뛰어넘었는지 궁금했다.
거슬러 온 순서 ···
1) ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
2) AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
(여기서 inductive bias가 나온다.)
3) Relational inductive biases, deep learning, and graph networks
Inductive Bias란?
일반적으로 모델이 갖는 일반화의 오류(Generalization Problem)는 불안정하다는 것(Brittle)과 겉으로만 그럴싸 해 보이는 것(Spurious)이 있다. 모델이 주어진 데이터에 대해서 잘 일반화한 것인지, 혹은 주어진 데이터에만 잘 맞게 된 것인지 모르기 때문에 발생하는 문제이다. 이러한 문제를 해결하기 위한 것이 바로 Inductive Bias이다. 주어지지 않은 입력의 출력을 예측가능하도록 모델이 가지고 있는 가정들의 집합을 의미한다. 즉, 일반화의 성능을 높이기 위해서 만약의 상황에 대한 추가적인 가정(Additional Assumptions)이라고 보면 된다.
모델이 학습하는 과정에서 학습 데이터 이외의 데이터들까지도 정확한 출력에 가까워지도록 추측하기 위해서는 추가적인 가정이 필수적이다. 그래서 성공적으로 학습하여 일반화가 잘 된 모델은 어떠한 Inductive Bias의 유형을 갖게 되는데, 이것들이 바로 일반화하기 위해 만들어진 가정이라고 볼 수 있다.
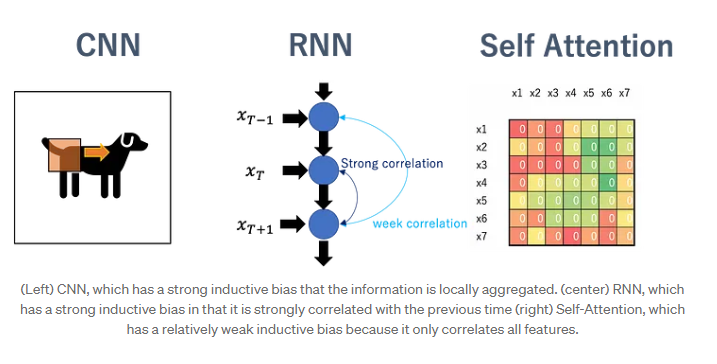
CNN의 경우 Locality(근접 픽셀끼리 종속성) & Translation Invariance(사물 위치가 바뀌어도 동일 사물 인식)를 가정하는 Inductive Bias를 갖기 때문에 이미지에 적합한 모델이 된다.
CNN이 공간의 개념을 사용한다면, RNN은 시간의 개념을 사용한다. RNN에서는 CNN의 Locality & Translation Invariance와 유사한 개념으로 Sequential & Temporal Invariance의 Relational Inductive Biases를 갖는다.
Transformer 같은 경우에는 self-attenion을 기반으로 하기 때문에 CNN 및 RNN보다 상대적으로 inductive bias가 낮다고 한다.
그림 출처
MLP, CNN, Transformer의 Inductive Bias 비교
일반적으로 머신러닝 모델은 특정 데이터셋에 대해 더 좋은 성능을 얻고자 Inductive bias를 의도적으로 강제해준다. 예를 들어 Vision 정보는 인접 픽셀간의 locality가 존재한다는 것을 미리 알고 있기 때문에 Conv는 인접 픽셀간의 정보를 추출하기 위한 목적으로 설계되어 Conv의 inductive bias가 local 영역에서 spatial 정보를 잘 뽑아낸다. RNN은 순차적인(Sequential) 정보를 잘 처리하기 위해 설계되었다.
반면 Fully connected(MLP)는 all(input)-to-all (output) 관계로 모든 weight가 독립적이며 공유되지 않아 inductive bias가 매우 약하다. Transformer는 attention을 통해 입력 데이터의 모든 요소간의 관계를 계산하므로 CNN보다는 Inductive Bias가 작다라고 할 수 있다. 따라서 Inductive Bias의 순서는 CNN > Transformer > Fully Connected 라고 예상할 수 있다.
Inductive bias와 데이터양과의 관계는?
' Vision Transformer 모델은 왜 데이터셋이 많아야 할까? '
Inductive Bias가 강할수록, 작은 데이터셋에 대해 학습 성능이 더 좋아지는 경향이 있다. 하지만 최신 딥러닝 알고리즘은 사전 표현 및 계산 가정을 최소화하는 End-to-End 설계 철학으로 만들어지는 경향이 있다.
따라서 최신 딥러닝 알고리즘은 Inductive bias를 낮추어서 generalization을 높이는 대신 data-intensive한 경향을 보인다. 이로 인해 Transformer가 부족한 Inductive bias 때문에 성능 향상을 위해 많은 양의 데이터셋이 필요한 대신, robust하게 동작하므로 NLP를 비롯한 다양한 task에서 좋은 성능을 보일 수 있는 것이다.
ViT논문에서는 ImageNet-1k에 학습했을 때, 비슷한 크기의 ResNet보다 낮은 정확도를 도출하는 것을 통해 ViT가 CNN보다 inductive bias가 낮은 것을 알 수 있다.
Inductive bias가 그래서 어떤 영향을 미치는 거야
머신러닝은 특정 문제를 풀기 위해 학습 데이터에 대해서 가장 loss가 작은 Hypothesis를 찾는다. 하지만 Hypothesis의 제한이 없다면 overfitting이 일어나므로 제한을 걸어주는데 이 제한이 바로 Inductive bias이다. 하지만 Inductive bias가 적절하지 못하거나 지나치게 강하면 학습을 통해 얻은 Hypothesis의 성능이 좋지 않을 수 있다.
Inductive Bias이 강하면 오히려 generalization(variance)이 떨어져 오히려 학습을 방해하여 성능을 저해할 요소가 될 수 있으므로 Inductive Bias과 generalization은 trade-off가 있다.
CNN 기반 vs ViT
위에서 얘기한 내용을 바탕으로 하면, ViT에서 MLP는 localiity와 translation equivariance가 있지만, Multi-head Self-attention이 global하기 때문에 CNN보다 image-specific inductive bias가 낮다.
ViT의 저자는 데이터 수가 적은 상황에서는 강한 inductive bias를 지닌 모델이 데이터에 대해 가정을 갖고 있기 때문에 약한 inductive bias를 지닌 모델보다 높은 성능을 보인다고 말한다.(그래서 데이터가 적을 때는 inductive bias가 강한 CNN 모델이 더 높은 성능을 보인다.) 하지만 데이터가 많은 상황에서는 이 강한 inductive bias가 오히려 방해물이 된다. 즉, ViT는 데이터가 많은 상황에서 CNN을 능가하는 성능을 보인다.
약한 inductive bias로 인해 좋은 정확도를 얻으려면 ImageNet(130만 데이터 세트)보다 큰 JFT-300M(3억 데이터 세트)이 필요하다. Vision Transformer는 약한 유도성 바이어스 덕분에 CNN을 능가할 수 있었지만, 반면에 약한 inductive bias를 활용할 만큼 데이터량이 많지 않으면 정확도가 떨어지게 된다.
ViT의 약한 inductive bias로 인한 개선연구
좋은 정확도를 얻으려면 큰 데이터셋이 필요한데, 이를 극복하기 위해 다양한 개선 방안이 제안되었다.
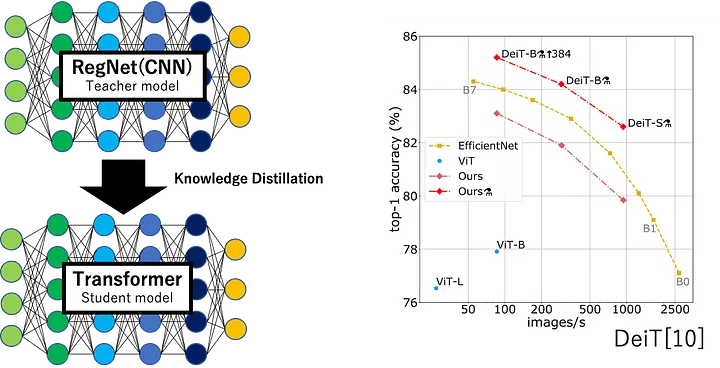
먼저 CNN을 사용하여 필요한 데이터의 양을 줄이려는 시도가 있다. DeiT는 CNN을 Teacher model로 사용하고 Transformer 모델에 지식을 전달하는 knowledge distillation 프레임워크를 사용한다. 이렇게 하면 ImageNet만 사용해도 ViT는 물론 EffcientNet도 능가하는 결과를 얻을 수 있다. 판단 경향도 크게 CNN에 가까워진 것으로 전해졌다.
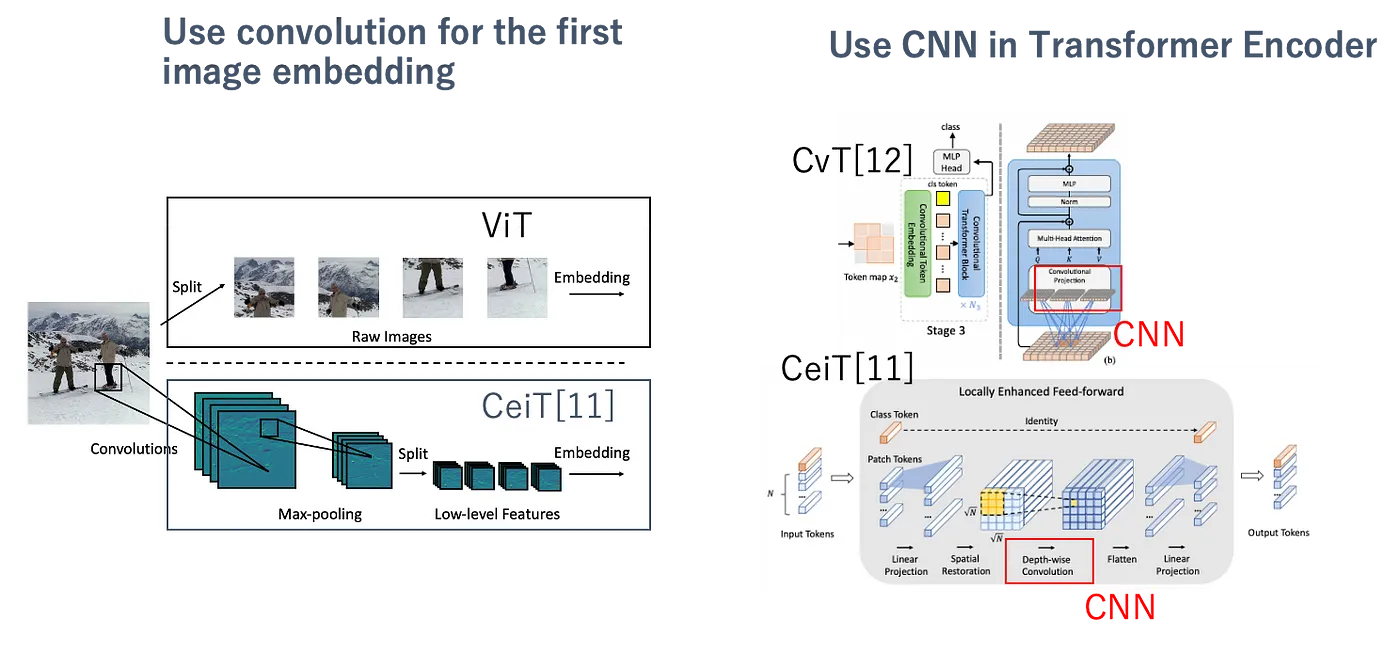
또한 Vision Transformer는 16x16 크기의 패치를 선형으로 투영하여 매우 간단한 방법으로 지역 정보를 다루기 때문에 거기에 지역 정보에 더 강한 CNN을 사용하는 연구가 진행되고 있다. ViT는 트랜스포머 내에서 조각화된 임베딩 표현을 사용하는 반면, CeiT는 CNN 컨볼루션을 사용한 추상적인 임베딩 표현을 사용해서 locality를 잘 획득하도록 했다.
VisionTransformer는 약한 inductive bias를 가지면서 큰 데이터셋으로 학습시켰기 때문에 좋은 성능을 보였을 뿐만 아니라, 새로운 데이터가 추가되어도 적응하는 일반적인 도메인 성능이 좋은 것 같다. 그래서 pose estimation에서 복잡한 디코더를 사용하지 않았음에도 SOTA를 달성할 수 있지 않았을까?
Reference
