3월 15일 기준으로 GPT-4가 공개됐다.
발표에 따르면 GPT-3보디 압도적으로 향상된 성능을 보이는 것 같다.
따라가기 벅찰 정도로 빠르지만
하긴 해야 하잖아.
그래서 또 chatgpt와 먼저 대담을 나눈다.
What is Stochastic Gradient Descent?
- iterative optimization algorithm to find the minimum of a loss function
- selects a subset of data for each iteration, making it more efficient than batch gradient descent.
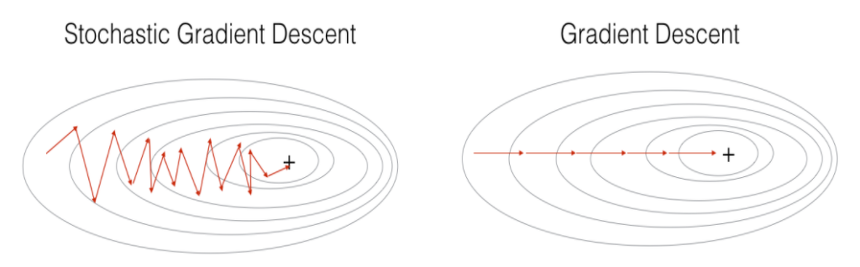
- Batch gradient descent has a smooth convergence trajectory, whereas stochastic gradient descent has a noisy convergence trajectory.
Why is SGD faster than GD?
- SGD can process one training example at a time, which requires less memory and computational resources compared to GD
- SGD can escape from local minima more easily than GD, because it takes a noisy step in each iteration, which can prevent the algorithm from getting stuck in local optima.
Stochastic Gradient Descent, 확률적 경사 하강법이다.
우리는 Loss fucntion의 최솟값을 찾기 위해 Gradient Descent를 사용했다.
식으로 표현하면 다음과 같다.
여기서 문제점이 매번 전체 데이터셋에 대하여 summation 계산을 해야 하는데
데이터셋이 커지면 커질수록 많은 리소스를 사용해야 하고 시간도 오래 걸린다.
이걸 문제를 해결하기 위해 SGD를 도입한다.
확률적이라는 말이 들어간 이유는
전체 데이터셋 중 subset을 골라 이것만을 이용해 parameters를 업데이트 하기 때문이다.
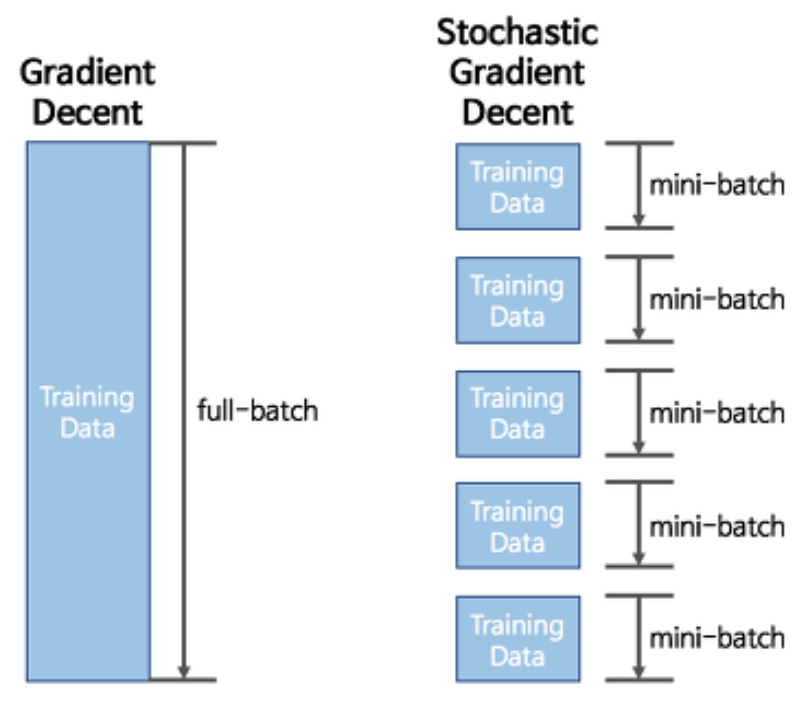
mini-batch 사이즈마다 계산하고 바로 반영하기를 반복하면서 최적해를 찾아간다.
전체 데이터를 대상으로 계산하는 것이 아니기 때문에 oscillates 하지만 훨씬 더 빠르다.
이 때, 최적해에 가까워 질수록 oscillate가 더 심해지는데 이를 보완하기 위해 Learning Rate를 조금씩 줄여나간다 -> Annealing (Learning Rate Scheduler 사용)
(momentum 이라는 개념도 사용하는데 추후 포스팅)

막상 하면 모르니까 일단 하자.