Abstract
- computing continuous vector representations of words from very large data sets 하는 두 가지 모델 구조 제시
- CBOW & SKIP-GRAM
- word similarity task에서 성능 측정
- better accuracy, less computiational cost
Introduction
-
Word를 각각 독립된 atomic unit으로 다룬다
- 단어 간 유사성 표현 X
- 장점
- Simplicty,
- Robustness,
- 간단한 모델에 많은 데이터 학습 > 복잡한 모델에 적은 데이터 학습
- N-Gram Model
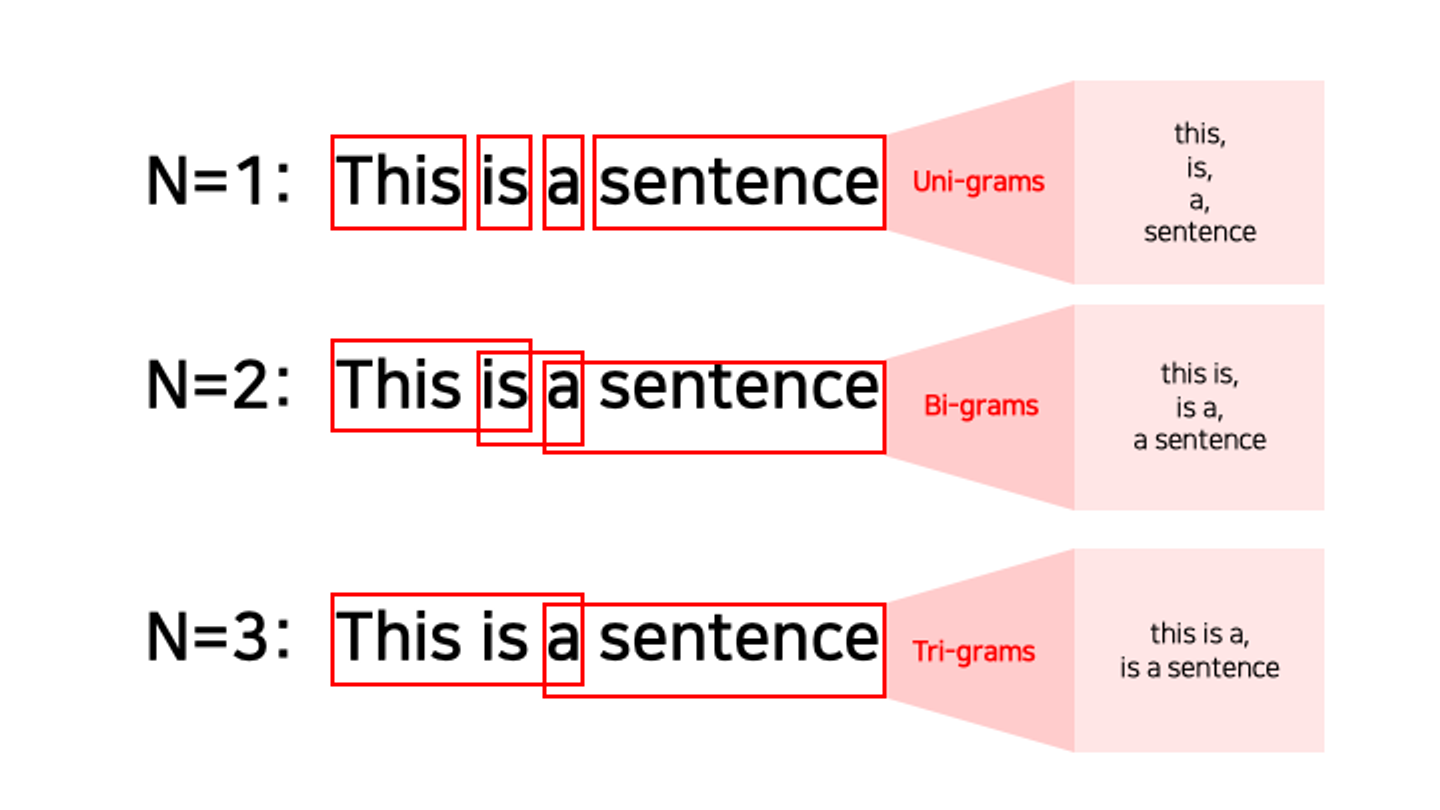
- 통계학적 언어 모델의 한계인 희소성(Spasity) 문제를 보완.
- 단어의 수가 매우 많은 어휘 집합에서 각 단어의 등장 빈도가 균등하지 않고, 대부분의 단어들이 제한된 데이터에서 드물게 나타나기 때문에 발생
- 다음 단어를 예측 시 모든 단어를 고려하지 않고 특정 단어 N개만 고려한다 → N개의 연속적인 단어를 한 token으로 간주
- 한계
- 전체 단어를 고려하는 언어 모델과 비교했을 때 정확도가 낮다
- 여전히 희소성 문제 존재
- N값에 따른 Trade-off
- 통계학적 언어 모델의 한계인 희소성(Spasity) 문제를 보완.
-
ML 기술 발전하면서 복잡한 모델에 많은 데이터 학습 가능해졌다 → 이전에 못해본 시도 가능
-
특히 Distributed Repersentations (분산 표현) 가능
- '비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다’는 가정 하에 만들어진 표현 방법
- 단어 벡터 간 유사도 계산 가능
-
근처에 위치한 단어의 유사성 뿐만 아니라 다양한 차원의 유사성(Multiple Degrees of Similarity)도 가진다
-
Syntatic regularities(구문론적 규칙성)도 찾아낸다
- King - Man + Woman = Queen
-
본 논문에선 단어 간 선형 규칙성을 유지하는 모델 구조를 개발하고, 구문론적,의미론적 규칙성을 측정할 수 있는 test set을 고안하고 이 규칙성이 높은 정확도로 학습될 수 있음을 보인다.
-
또한 단어의 차원과 데이터의 양이 학습 시간 및 정확도에 어떻게 영향을 주는지 이야기한다.
Previoud Work
- NNLM
- Feedforward Neural Network = Linear Projection Layer+ non-linear hidden layer
- word vector가 single hidden layer에서 학습된 후 NNLM을 train하는데 사용된다
- 즉 word vectors는 full NNLM을 구성하지않고 학습된다
- 본 논문은 이 구조를 확장시키고, word vector가 simple model을 사용해 학습되는 first step에 집중한다
Model Architecture
- Neural Network을 통해 분산 표현을 학습하는데 집중한다.
- Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA)보다 뛰어나다
- 복잡도 측정 방식
- O = E (Epochs) X T (Number of the words) X Q (Model Architecture)
- E = 3 ~ 50, T = 1B
- 모든 모델은 SGD 사용
- O = E (Epochs) X T (Number of the words) X Q (Model Architecture)
Feedforward Neural Net Language Model(NNLM)
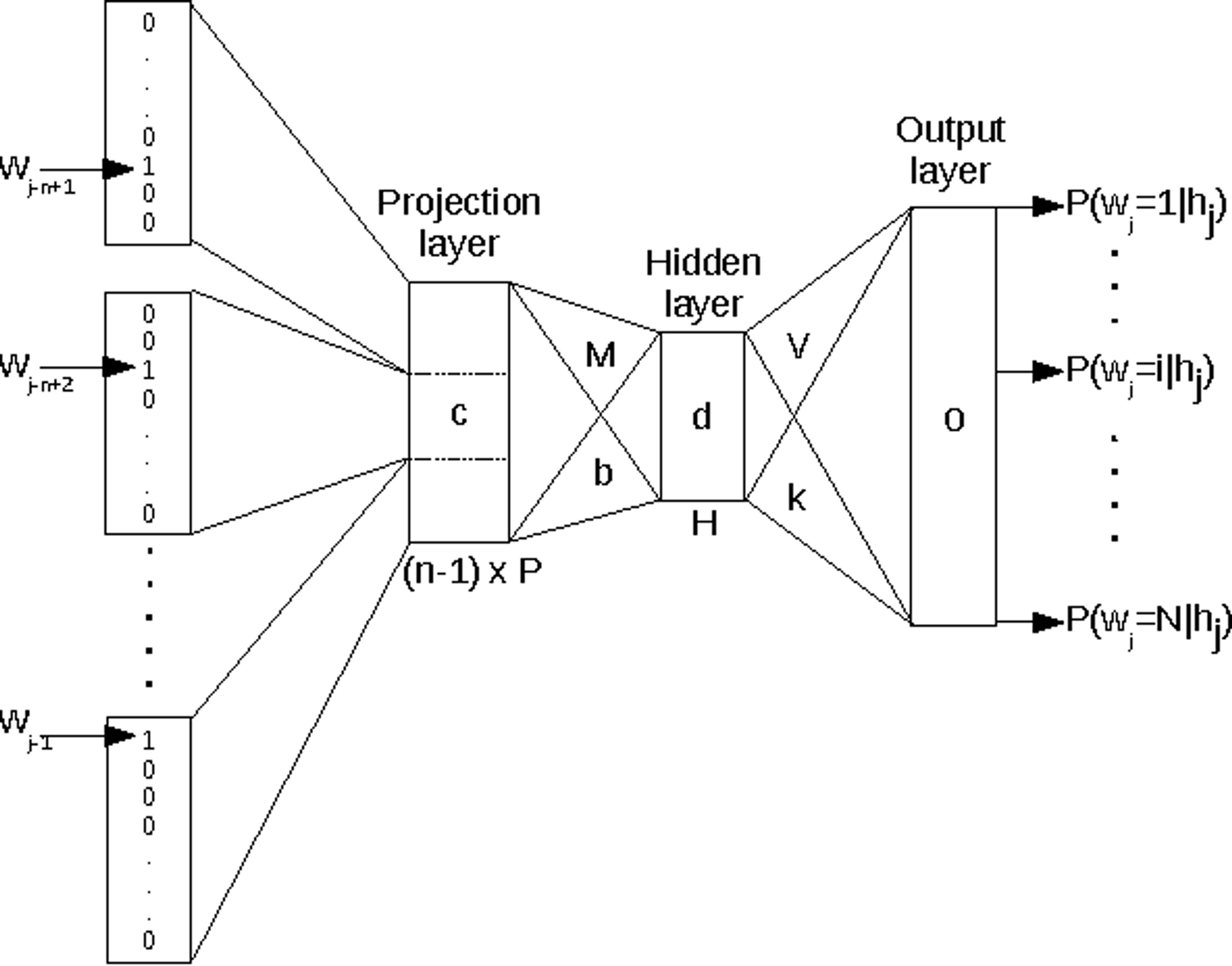

-
input, projection, hidden and output layers
-
Input Layer : 이전 N개 단어들이 one hot encoding 되어 있다. (전체는 V개)
-
input layer는 N X D 차원인 projection layer P로 Projection 된다
-
이 후 N X D 행렬이 D X H인 Hidden Layer 만나 N X H 출력
-
Q = N X D + N X D X H + H X V
-
Hierarchical Softmax 사용해 H X V → H X log(V)
- Huffman Binary Tree 사용
- frequent words on short binary codes ⇒ 빈도 수 높을 수록 root에 가깝게 위치
- 다른 방법으로는 Negative Sampling 있다.
-
따라서 N X D X H 가 Cost 결정.
-
한계
- 다음 단어를 예측하기 위해 모든 이전 단어를 참고하는 것이 아니라 정해진 n개의 단어만 참고 가능
Recurrent Neural Net Language Model (RNNLM)
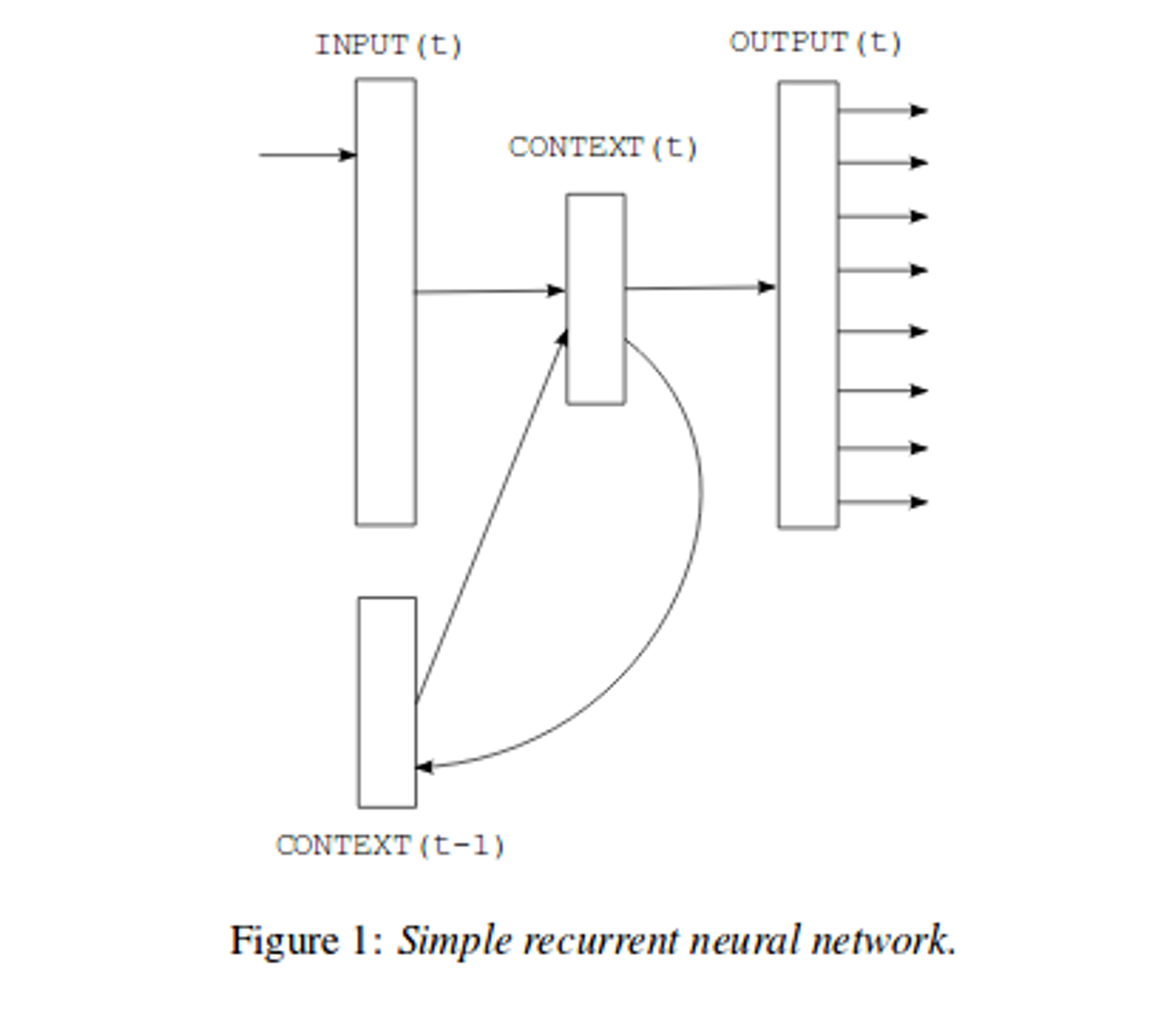
- RNN 사용해 얕은 구조로 복잡한 패턴 표현 가능
- Projection Layer없이 Input, Hidden, Output만 존재
- Time Delay를 이용해 Hideen Layer가 자기 자신에 연결 ⇒ Short Term Memory
- Q = H X H + H X V
- D X H == H X H : word representations인 D는 H와 같은 차원 가지기 때문.
- 역시 H X V → H X log(V) 가능 ⇒ H x H 에 의해 complexity 결정
Parallel Training of Neural Networks
- DistBelief 사용
- run multiple replicas of the same model in parallel
- 데이터 분산 처리라고 생각하면 될 듯
New Log-linear Models
- 이전 모델 구조에서 대부분의 complexity는 non-linear Hidden Layer가 원인

CBOW (Continuous Bag-of-Words Model)
-
주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측
-
non-linear Hidden Layer 제거
-
모든 단어가 Projection Layer를 공유 → 모든 단어가 동일한 행렬로 Projected
-
단어의 순서 (Order of words)가 영향을 미치지 않기 때문에 bag-of-words라고 부른다
-
예측하는 단어 = Center word(중심 단어), 예측에 사용되는 단어 = Context word(주변 단어)
-
Q = N X D + D X log(V)
Skip-Gram

- 중심 단어에서 주변 단어를 예측
- Q = C (Max Distance) X ( D + D X log(V) )
Result
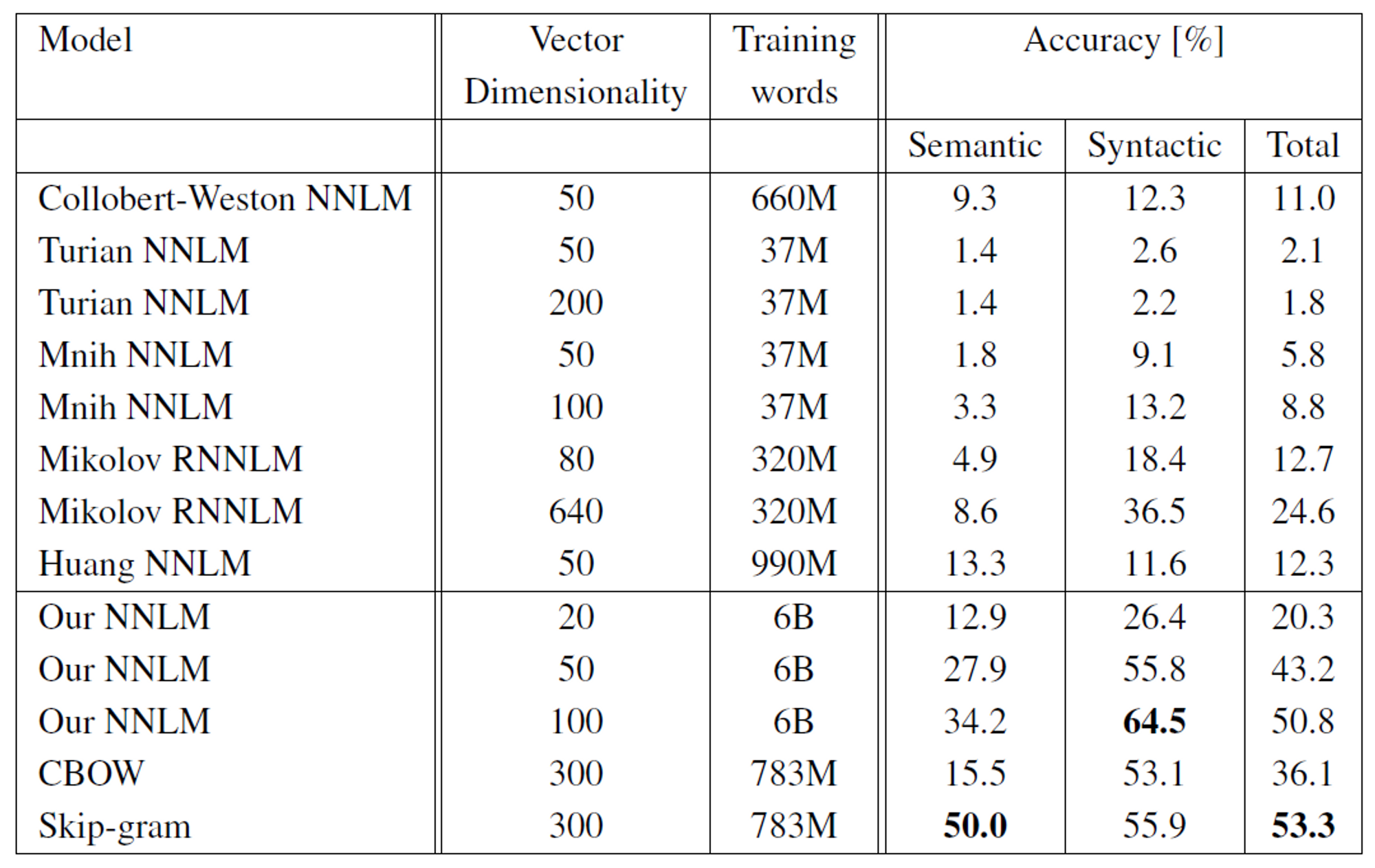
Examples of the Learned Relationships
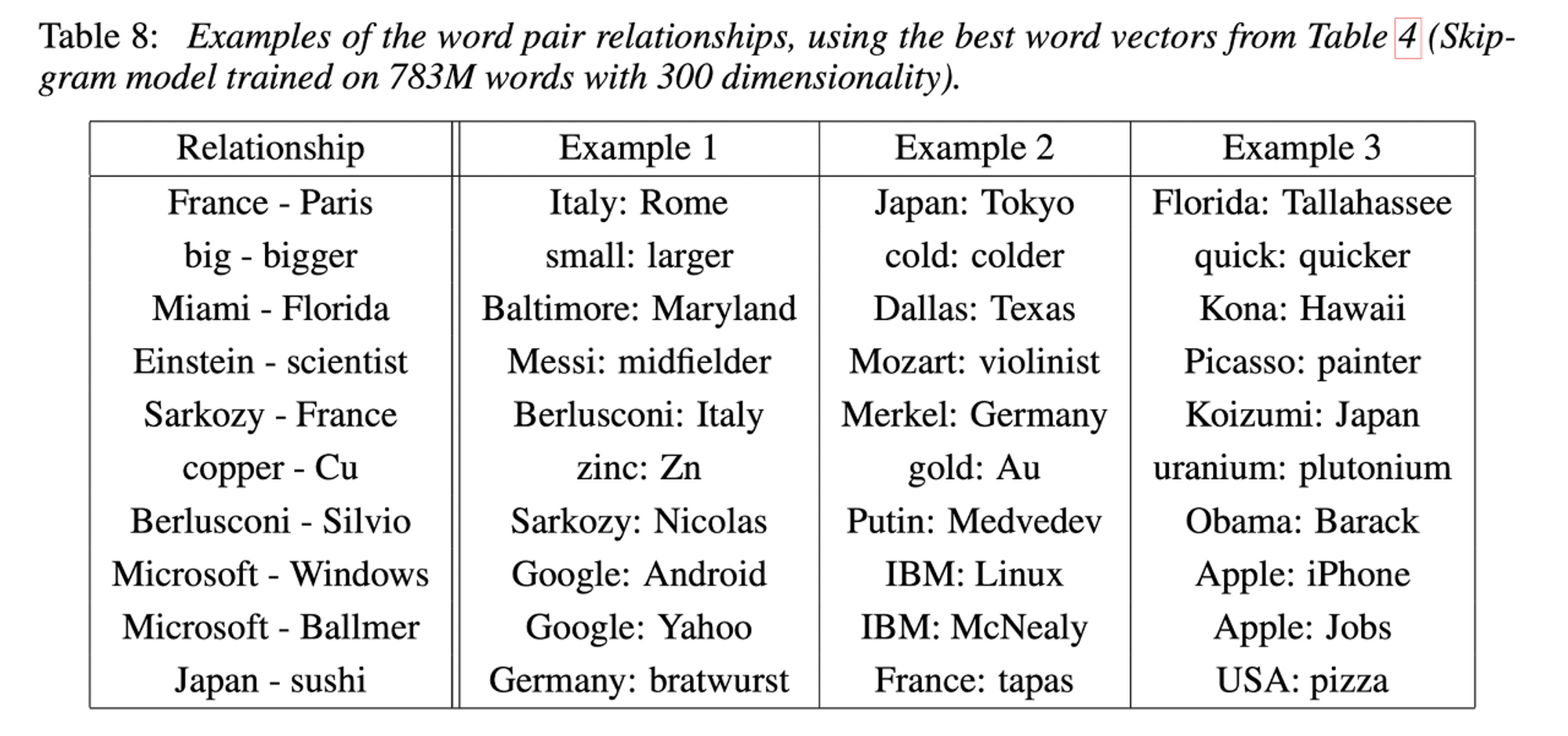
Conclusion
- vector representations of words에 대한 연구 성과
- 매우 간단한 모델 구조에서 높은 수준의 단어 벡터 학습 가능
