Keyword
Self-Attention
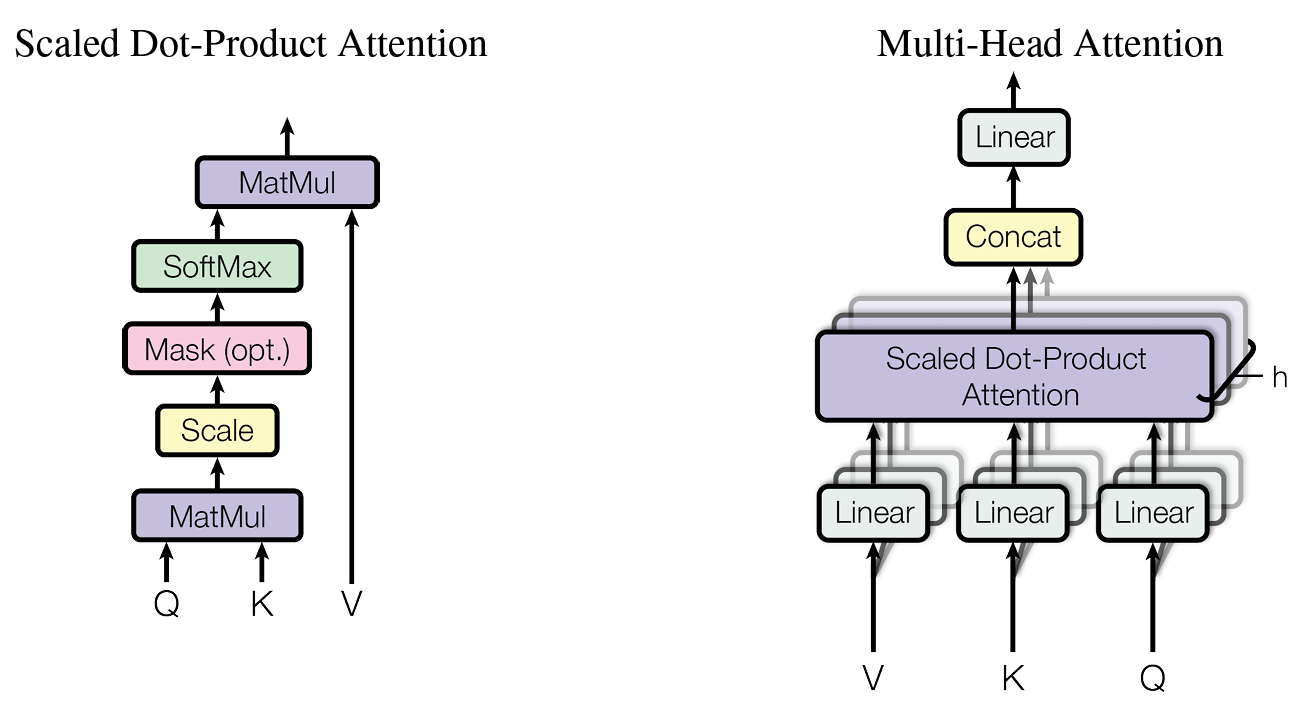
Scaled Dot-Product Attention
Multi-Head Attention
Positional Encoding
Abstract

- 이전 시퀀스 변환 모델은 RNN이나 인코더-디코더 포함한 CNN 기반
- 한계 많아 ex) 병렬화 X, Sequence 길어지면 처리 힘들어
- 본 논문은 오로지 Attention 기반
- 병렬화 및 일반화 성능 뛰어남
Introduction

(Abstract에 나온 내용 보충 설명)
- 기존 RNN, LSTM, GRU 등이 Sequence modeling에서 SOTA였지만 앞서 말한 문제 있어
- 병렬화 안돼 → 긴 sequence에 치명적 → 리소스 많이 들어
Background

Self-Attention
- 하나의 입력 Sequence 내에서 각 단어 간의 상관 관계를 파악하는 데 사용한다
Model Architecture

모델 전체 구조

- 좋은 성능 가진 Sequence model은 대부분 인코더-디코더 구조, Transformer도 마찬가지
- self-attention과 fully connected layer로 이루어짐

Encoder
- 본 논문은 6개 layer 쌓음
- 각 Layer는 2개의 sub-layer로 구성
- multi-head + feed forward
- Reisdual Connection 사용
- ∵ 각 sub layer 출력이 LayerNorm(x+Sublayer(x))
Decoder
- 인코더와 거의 유사, 동일하게 6개 쌓음
- 단 각 layer가 3개의 layer로 구성됨
- multi-head + multi-head + feed forward
- Residual Connection 사용
- Masking
- 각 포지션보다 뒤에 있는 단어에 대해 알지 못하게

- Query : 물어보는 주체
- Key : 대상
- Value :
- Query가 Key에 대해 질문한다


막상 하면 모르니까 일단 하자.