여러분 supabase 혹시 들어보셨나요? 이미 알고 계신 분들도 계실 수 있고, 모르시는 분들도 계실 텐데요. 저는 이번에 진행하는 사이드 프로젝트에서 사용해 봤습니다. 저에겐 꽤나 만족스러운 경험이었기에 supabase가 어떤 기능을 제공하는지 소개해 보고자 합니다.
1. supabase를 알기 전
저는 개인적으로 사이드 프로젝트를 몇 번 진행한 적이 있습니다. 데이터 저장소가 필요할 때 주로 두 가지 방식으로 진행했었습니다. 관계형 데이터베이스(= RDB)가 필요한 경우 도커 이미지를 받아서 EC2 인스턴스에 올리는 방식으로 진행하거나, RDB가 필요 없는 경우엔 파이어베이스를 사용해서 진행했습니다.

직접 인스턴스에 올려서 작업하는 방식은 몇 가지 어려운 점이 있었습니다. FE 개발자이다 보니 현업에서 DB에 작업할 수 있는 업무를 맡아 본 적이 없어 매번 셋팅할 때마다 이렇게 해도 되나 잘 모르겠더군요. 예를 들면, MySQL에서 데이터 저장 포맷을 utf8mb4로 바꾸는 작업이던지, root 계정이 아닌 사용자 계정을 분리하는 작업 등 말이죠.
저장할 데이터가 비정형인 경우에는 파이어베이스를 사용하기 편리했습니다. 그래서 종종 사용했었는데요. 다만 RDB를 사용하는게 유리한 데이터를 억지로 No-SQL에서 작업하려다 보니 쉽지 않았어요. 예를 하나 들어볼까요?
우리에게 상점 목록이 있고, 상점 카테고리가 있다고 생각해 보죠. 하나의 상점에는 여러 개의 상점 카테고리가 있을 수 있겠죠.
상점 A = ["중식", "포장 가능", "배달 가능"]
상점 B = ["분식", "포장 가능"]
// 이걸 json 형태로 저장한다고 하면,
const shopList = [
{ name: "상점 A", categories: ["중식", "포장 가능", "배달 가능"] },
{ name: "상점 B", categories: ["분식", "포장 가능"]
]이 정도는 No-SQL로 저장할 수 있죠. 그런데 만약 상점의 개수가 십만 개 이상일 때, 카테고리 이름을 변경하고 싶다고 가정해 볼까요? 혹은 카테고리의 종류를 모두 확인해 보고 싶다고 하면 어떻게 해야 할까요?
저는 그래서 한번 파이어베이스에서 RDB처럼 데이터를 관리해 보려고 했는데요. 전혀 좋지 않은 개발 경험이었습니다. 억지로 하다 보니 계속 머릿속에는 한 가지 생각만 강하게 들었어요.
“파이어베이스처럼 편리한데 RDB를 제공해 주는 서비스는 어디 없나…”
2. supabase 폼 미쳤다

이번에 프로젝트를 진행하면서 적당한 개발 스택을 찾던 중에 supabase를 알게 되었어요. 예전에 “오픈 소스 버전의 파이어베이스” 정도로만 들어본 적이 있었는데, 이번 프로젝트에서 사용해 보니 정말 훌륭한 서비스라고 느껴졌어요. 그중 몇 가지를 이번에 소개해 보고자 합니다.
2.1. PostgreSQL 지원
PostgreSQL는 객체-관계형 데이터베이스 시스템(ORDBMS)입니다. 이 글에선 PostgreSQL를 소개하고자 하는 글은 아니기에 자세한 내용은 이 링크에서 한번 읽어보시면 좋겠습니다. supabase에선 PostgreSQL을 모든 기능을 지원한다고 합니다. 제가 기존에 해당 DB로 작업한 적이 없어서 정말로 모든 기능을 지원하는지 확인하지는 못했지만, 프로젝트를 진행하는데 불편한 점은 하나도 없었습니다. 오히려 MySQL에서 경험해 본 적 없던 새로운 기능들을 마주치며 놀라기만 했습니다. 그 기능들은 잠시 뒤에 소개 드리겠습니다.
2.2. 편리한 콘솔 UX/UI
supabase 웹 사이트에서 프로젝트를 관리하는 콘솔에 들어가면, 두 종류의 에디터를 통해 프로젝트 내 DB와 DB 안의 데이터들을 관리할 수 있었어요. 바로 "Table Editor"와 "SQL Editor"입니다.
먼저 "SQL editor"는 SQL 쿼리를 웹 페이지에서 작성, 저장 및 실행까지 할 수 있게 합니다. 별도의 third-party 프로그램을 사용하지 않아도 된다는 것이죠. 실제로 이 에디터를 통해 테이블 스키마를 손쉽게 한 번에 생성할 수 있었습니다.
"Table editor"는 데이터베이스 안에 있는 데이터를 스프레드시트(=엑셀)처럼 볼 수 있어요. 특정 값 수정도 스프레드시트처럼 가능하고, 가장 놀랐던 건 특정 컬럼의 데이터 타입이나 기본값, nullable on-off 등등도 UI에서 편집이 가능했던 점입니다. 어떻게 알게 되었냐면, 유저 테이블의 생성 날짜가 클라이언트에서 가져와서 읽으면 로컬 시간과 동떨어져서 보이더라고요. 그때 컬럼 타입이 timestamp였는데 timezone 정보도 같이 포함하려면 timestamptz로 타입을 바꿔줘야 하더라고요. SQL 쿼리를 어떻게 작성해야 할지 고민하던 중에 이 에디터에서 해당 컬럼의 편집 아이콘을 눌렀더니 변경할 수 있게 사이드바가 노출되더라고요. 실제로 반영도 잘되고 아까의 이슈도 사라졌습니다. 정말 놀라운 경험이었어요.
2.3. 훌륭한 개발자 경험(DX)
콘솔에서 테이블을 생성했다면 클라이언트나 서버에서 작업을 시작할 수 있게 됩니다. supabase는 클라이언트, 서버 환경 두 곳에서 동일한 방식으로 작업할 수 있게 isomorphic JavaScript 라이브러리(@supabase/supabase-js)를 제공합니다. 이걸 쉽게 설명하기 위해 next.js 프로젝트를 예시로 들어보겠습니다.
// lib/supabase/client.js
import { createClient } from '@supabase/supabase-js'
// The unique Supabase URL which is supplied when you create a new project in your project dashboard.
const supabaseUrl = ...
// The unique Supabase Key which is supplied when you create a new project in your project dashboard.
const supabaseKey = ...
export const supabase = createClient(supabaseUrl, supabaseKey)
// pages/api/users.js
import { supabase } from 'lib/supabase/client'
export default function (req, res) {
...
// ✅ it works!
const { data, error } = await supabase
.from('users')
.select()
...
}
// pages/users.js
import { supabase } from 'lib/supabase/client'
function UsersPage() {
...
// ✅ it also works!
useEffect(() => {
supabase
.from('users')
.select()
.then(({ data, error }) => {
...
})
}, [])
return ...
}위의 코드를 보면 알 수 있듯이, lib 폴더에서 생성한 supabase 인스턴스를 서버 코드에서 import하여 사용하거나, 브라우저에서 import하여 사용하더라도 별 다른 설정없이도 정상적으로 실행되고 원하는 결과를 얻을 수 있습니다. 이렇게 구현해 보니 "isomorphic"이 무엇인지 저에겐 잘 이해되었어요.
그리고 TypeScript를 사용하시는 분들에게는 더 좋은데요. 타입 생성 및 추론 기능도 강력했습니다. 우선 데이터베이스 테이블을 보면서 일일이 타입을 생성할 필요 없이 supabase-cli로 간단하게 만들 수 있습니다.
// terminal에서 아래를 실행하면..!
npx supabase gen types typescript --project-id {project-id} --schema public > lib/supabase/schema.ts위의 커멘드처럼 터미널에서 project-id와 저장할 위치를 변경해서 실행하면 아래와 같은 스키마 타입 파일이 자동으로 생성됩니다.
// lib/supabase/schema.ts
// 짜잔..!
export type Json = string | number | boolean | null | { [key: string]: Json } | Json[];
export interface Database {
public: {
Tables: {
users: {
Row: {
created_time: string;
id: number;
nickname: string;
oauth_id: string;
profile_image: string | null;
};
Insert: {
created_time?: string;
id?: number;
nickname: string;
oauth_id: string;
profile_image?: string | null;
};
Update: {
created_time?: string;
id?: number;
nickname?: string;
oauth_id?: string;
profile_image?: string | null;
};
};
...
}그리고 생성된 Database interface를 supabase 인스턴스 생성할 때 제네릭에 주입해주면 강력한 타입 추론을 경험할 수 있습니다.
// lib/supabase/client.ts
import { Database } from './schema'
...
// 제네릭에 Database를 주입해주면 됩니다!
export const supabase = createClient<Database>(supabaseUrl, supabaseKey)
...
// 그럼 응답값인 data의 타입 추론은 잘될까요?
const { data, error } = supabase.from('users').select('*')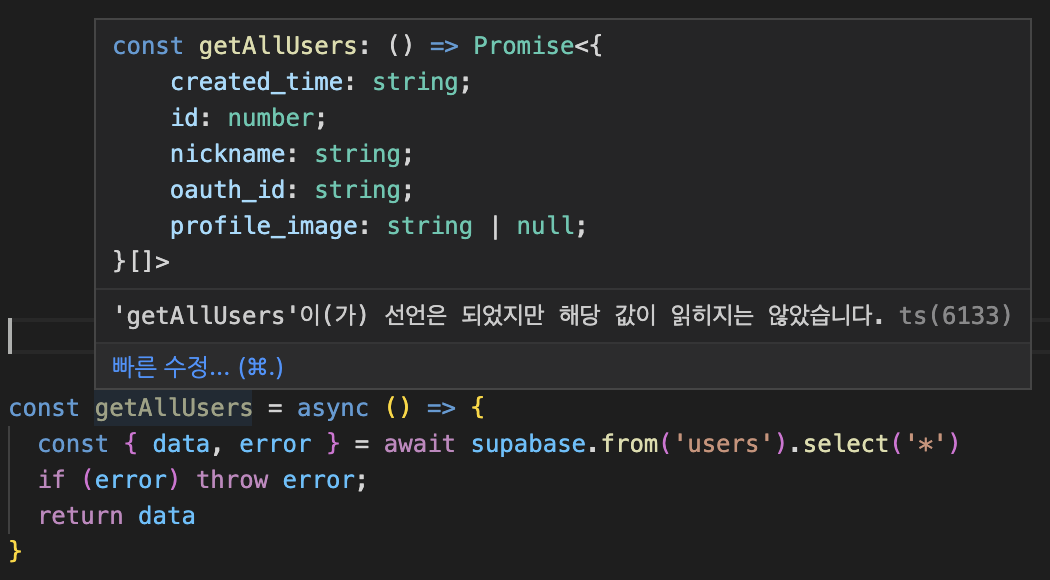
네 자동으로 잘 추론되네요! 그런데 더욱 놀라운 건 select에 입력한 문자열에 따라 data의 타입을 알아서 추론해 줍니다. 우리가 유저 목록에서 id만 가져오고 싶다고 해보죠. 이번에는 어떻게 될까요?
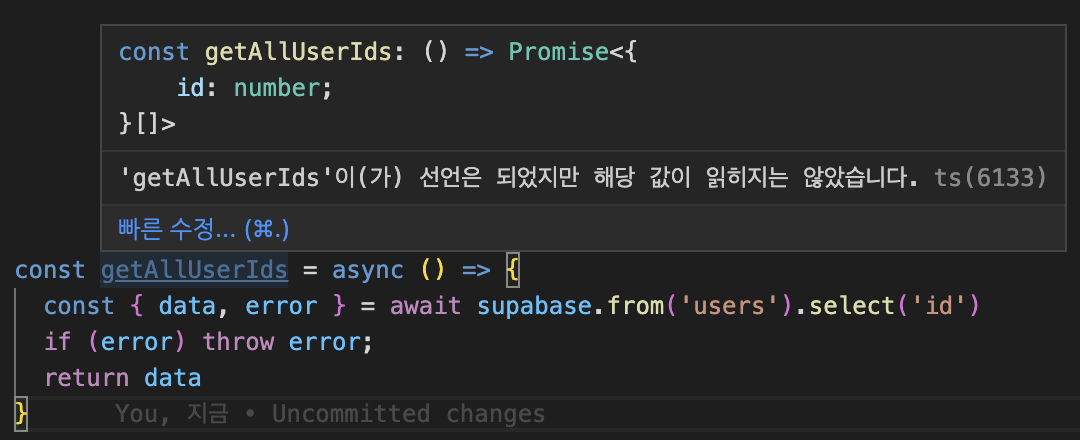
컬럼 이름에 대한 별칭을 주어도 자동으로 추론되고, 없는 컬럼 이름을 입력하면 unknown 타입 처리를, 잘못된 문자열을 입력하면 파싱 에러 타입으로 추론됩니다.
그리고 가장 놀라운 경험은 외래키를 통해 JOIN 문을 명시적으로 작성할 필요가 없습니다. 예를 들어보죠. 유저 테이블, 그룹 테이블이 존재하고 유저와 그룹은 N 대 N 관계라고 생각해 봅시다. 특정 유저가 속한 그룹의 이름 리스트를 가져오려면 어떻게 해야 할까요?
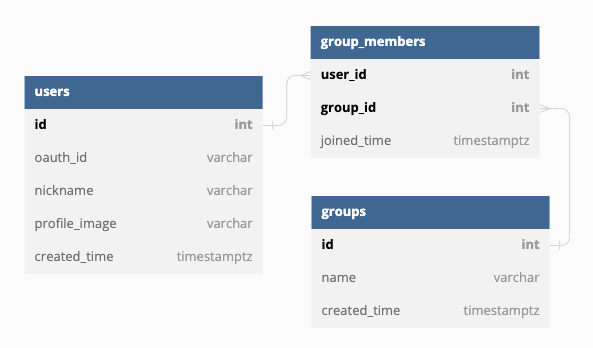
직접 쿼리를 작성해야 한다면, 유저 아이디를 통해 group_members 테이블에서 대응되는 group_id를 찾고 그 아이디로 groups 테이블에서 검색해 name을 반환하는 식으로 작성해야 할 겁니다. 그런데 supabase에선 그런 식의 작업이 필요 없이 다음과 같이 작성하면 얻어 올 수 있습니다.
const getGroupNameListByUserId = async (user_id: number) => {
const { data, error } = await supabase
.from('users')
.select('*, groups (name)')
.eq('id', user_id)
if (error) throw error
return data
}정말 놀랍지 않나요? 이제 JOIN 문을 작성하는 것에 대해 부담을 느낄 필요가 없습니다. 알아서 가져와주고 타입 추론까지 알아서 해줍니다.
이 외에도 정말 많은 기능을 제공합니다. 나머지 기능에 대해서는 한번 라이브러리 문서(https://supabase.com/docs/reference/javascript/introduction)를 읽어보시면 좋을 것 같습니다.
2.4. RLS(Row Level Security)
supabase를 어떻게 사용하면 될지 알아봤으니 이제 보안을 고려해볼 필요가 있습니다. 만약 아무런 보안 설정없이 supabase를 웹 클라이언트에서 그대로 사용한다면 심각한 보안 위험에 노출됩니다. 왜냐하면 바로 supabaseUrl과 supabaseKey(=public anon-key)가 network 단에서 그대로 노출된다는 점입니다. 이 경우 악의를 가진 사용자가 해당 값만 가지고 데이터베이스에 접속해 모든 데이터를 삭제할 수도 있습니다.
그럼 이러한 취약점에 어떻게 대처할 수 있을까요? 다른 여러 가지 방법이 있겠지만 저는 2가지 방식을 소개해드리고자 합니다.
첫 번째는 supabase 사용을 서버에서만 하는 겁니다. 마치 ORM처럼요. 이 방식의 장점은 supabase에서 별도의 인증 설정은 하지 않아도 된다는 점입니다. 앞의 두 키가 노출될 일만 없다면 정말 외부의 데이터베이스에 연결해서 사용하는 것과 별다를 바가 없는 거죠. 그렇다면 단점은 무엇일까요? 자신이 직접 API 호출하는데 있어 보안 정책을 별도로 구축해야 한다는 점과 서버에서 supabase 서버로 호출하게 될 때 발생할 네트워크 비용이 있을 것 같습니다. 또한 기능 별 API를 만들어서 관리해야 할 것이고요. 사실 이 부분은 단점이라기보단 약간 번거로운 점에 가까울 것 같습니다. 기존에 서버를 만들던 분들에게는 그마저도 아닐 것 같지만, 제가 단점이라 말한 이유는 뒤에 설명드릴 방법에서 이 단점을 모두 보완할 수 있기 때문입니다.
두 번째는 데이터베이스에 RLS(Row Level Security)를 설정하는 겁니다. PostgreSQL에서 제공하는 기능인데요. RLS를 사용하면 행(Row) 단위로 발생하는 조회, 수정 및 삭제 행위를 사용자별로 제한할 수 있습니다. 예를 들면, 자신이 속한 그룹의 데이터만 가져올 수 있게 제한할 수도 있습니다. 제한은 어떻게 적용해야 할까요? 바로 정책이란 단위로 기술해야 합니다. 정책은 기본적으로 SQL로 작성해야 하지만 supabase 콘솔에선 이 정책을 쉽게 추가할 수 있게 GUI를 제공합니다. 아래처럼요.
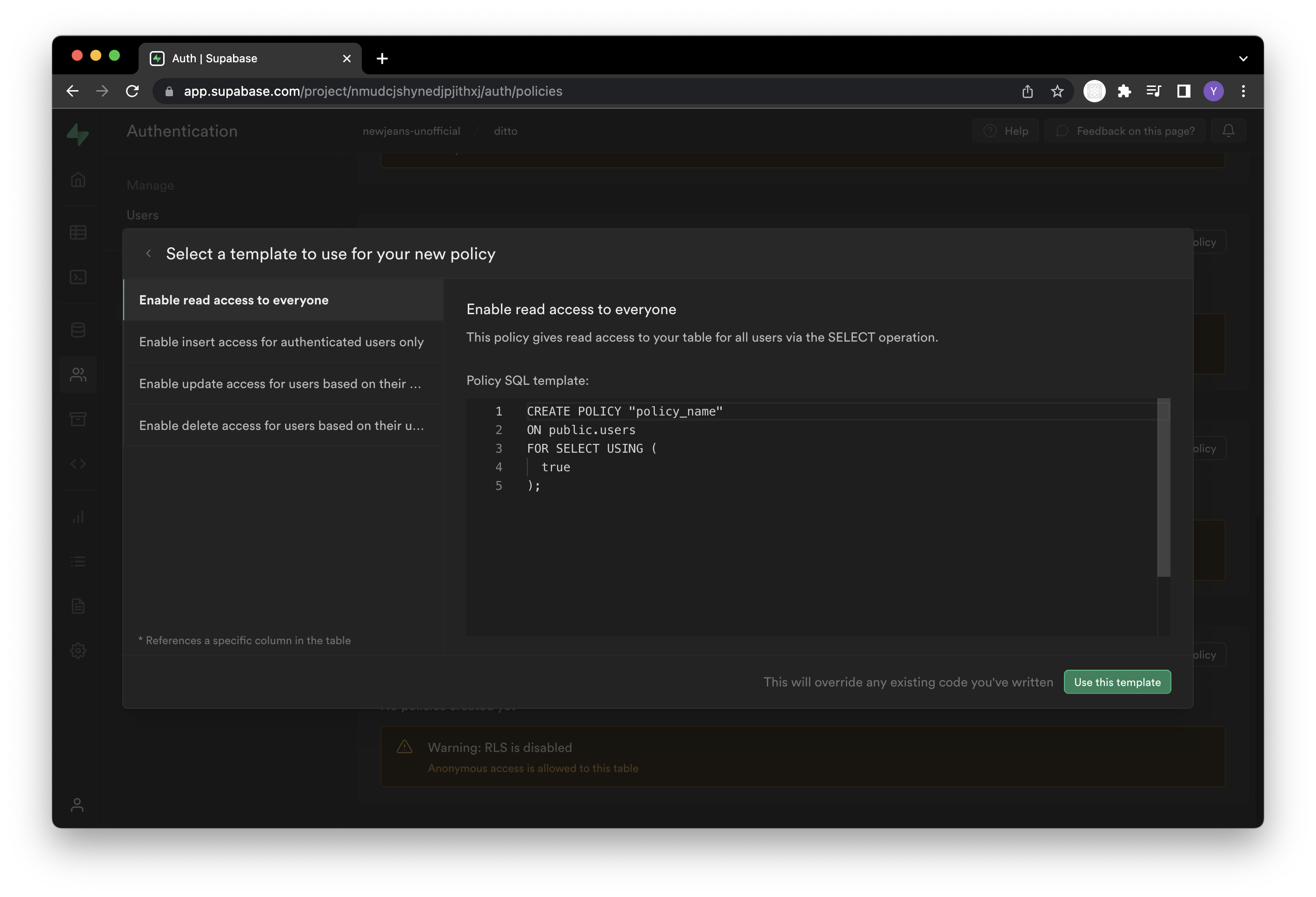
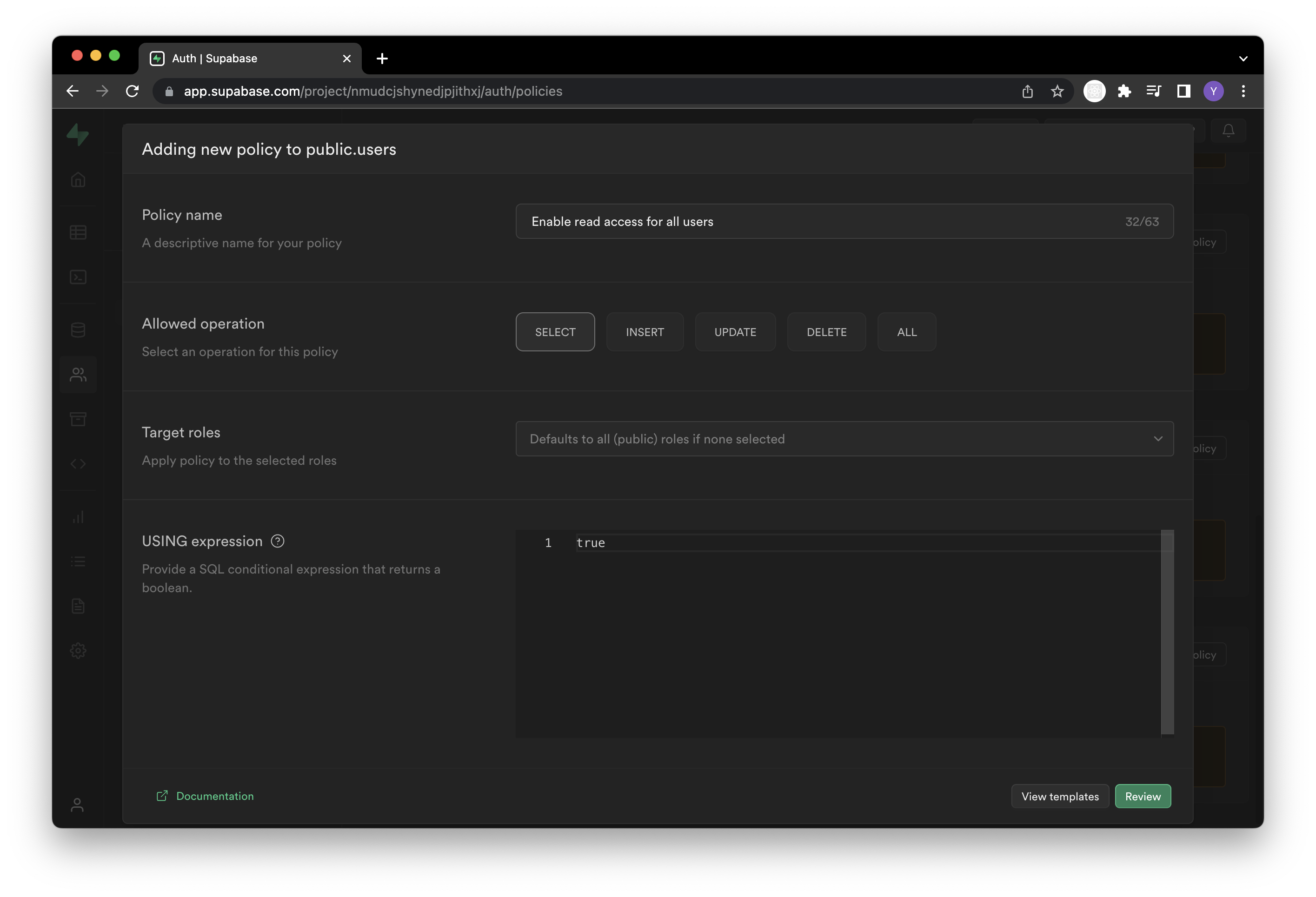
그런데 supabase에 누가 데이터를 요청하는 건지를 알려주려면 어떻게 해야 할까요? 요청 헤더에 해당 사용자의 id를 넣어줘야 하는 걸까요? 그렇게 할 수는 없습니다. 우리는 supabase의 Auth 기능을 사용해야 합니다.
supabase에서 제공하는 Auth 기능은 강력합니다. 이메일로 회원가입부터 구글, 애플, 깃허브 등 소셜 로그인까지 모두 지원합니다. 그리고 Auth를 통해 회원가입시킨 사용자가 로그인을 하면 이제 supabase로 요청을 보낼 때 해당 사용자가 누구인지 구분할 수 있게 됩니다.
RLS 설정해서 얻는 장단점은 어떤 게 있을까요? 우선 장점은 supabase에 개별적으로 요청을 해도 정교한 제한이 가능하기 때문에 서버를 구현하는 것에 대한 부담이 줄어듭니다. 또한 별도 서버를 거치지 않기에 응답 속도 역시 빨라질 수 있습니다. 그럼 단점은 어떤 게 있을까요? RLS를 설정하기 위해선 Auth 기능을 필수적으로 사용해야 합니다. 또한 정교한 정책을 작성하는게 어려울 수 있습니다. 자신이 사용하는 언어로 로직을 작성하는 것이 더욱 익숙한데 PostgreSQL로 정책을 작성하는건 더 어색하거나 어려울 수도 있기 때문입니다.
3. 마무리
지금까지 supabase에서 인상 깊었던 기능들에 대해 소개해 드렸으나, 사용해 본 적이 없어 소개 못 드린 기능들도 많습니다. 예를 들면 deno 환경에서 동작하는 edge function, beta이지만 graphQL API로 supabase 서버에 데이터를 요청하는 기능 등 너무 많습니다. 관심이 있으시다면 supabase 공식 문서를 한번 둘러보세요. 문서화가 꽤나 잘 되어있다고 생각합니다.
그리고 제가 사용했던 방식은 참고해주시면 좋겠습니다. 다양한 방식으로 적용할 수 있는데, supabase를 prisma와 연동해서 사용할 수도 있습니다. 다양한 기능이 존재하기 때문에 각자의 상황에 맞춰 유연하게 적용할 수 있을 거라 생각합니다.

여기까지 읽으셨다면 supabase에 대해 흥미가 생기셨을까요? 다음 사이드 프로젝트에선 한번 적용해보는 건 어떨까요? 만약 사용에 대해 주저하시는 분들이 있다면 강력하게 적용해보는걸 추천드리고자 합니다. 저는 좋은 개발자 경험을 했고, 이런 멋진 제품을 만들어보고 싶다는 성장에 대한 자극도 느낄 수 있었기 때문입니다.
이렇게 supabase에 대한 사용 경험을 나눠보았습니다. 다시 한번 아직 경험해 보지 못한 분들은 꼭 사용해 보시길 추천드리며 이 글을 마칩니다. 읽어주셔서 감사합니다.

2개의 댓글

안녕하세요 국내 Supabase 커뮤니티를 만들고 있습니다!
Supabase 공부하거나 사용하시는 분들 참여 부탁드립니다!
https://open.kakao.com/o/gyq8TWjf
cloudflare worker같은 edge 환경에서도 db 접속이 쉽다는 게 큰 장점