
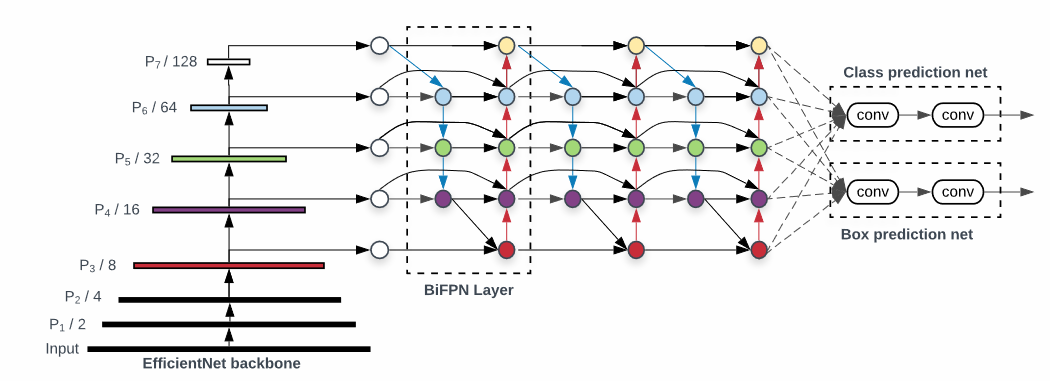
- BackBone -> Neck -> Head 로 이뤄져있다.
- Compound Scaling : 모두 합치면 더 좋은 것을 만들 수 있다.
- 기존 FPN 에서 BiFPN으로 대체 하였다.
EfficientDet개요
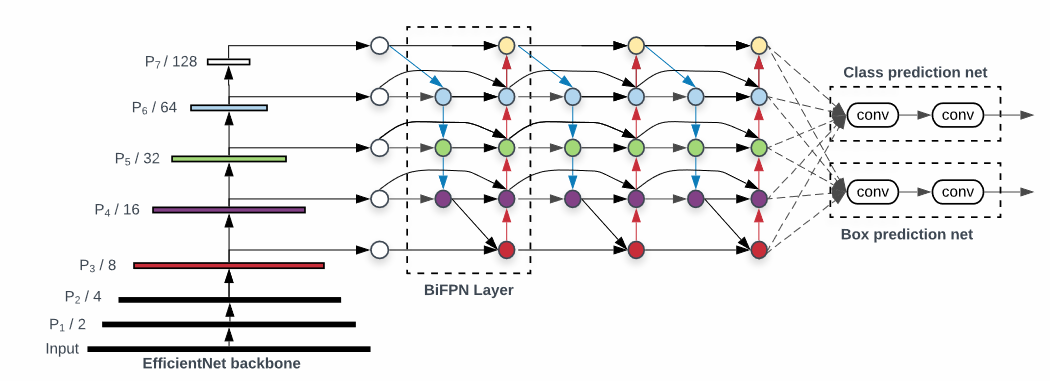
BiFPN(bi-directional FPN)
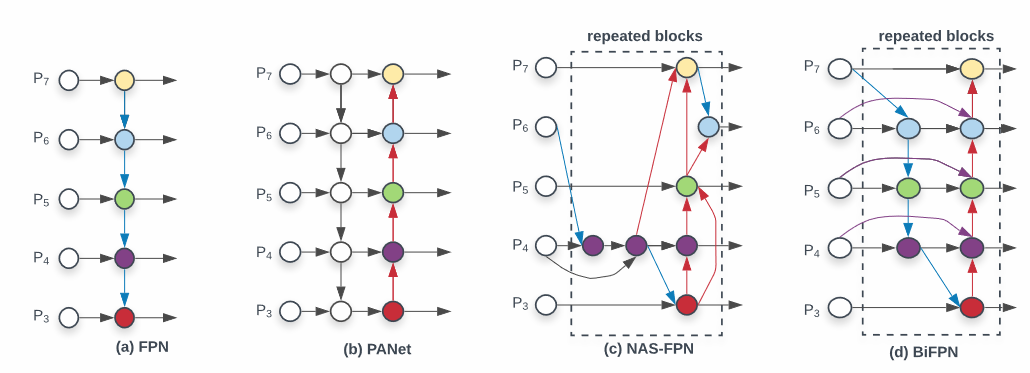
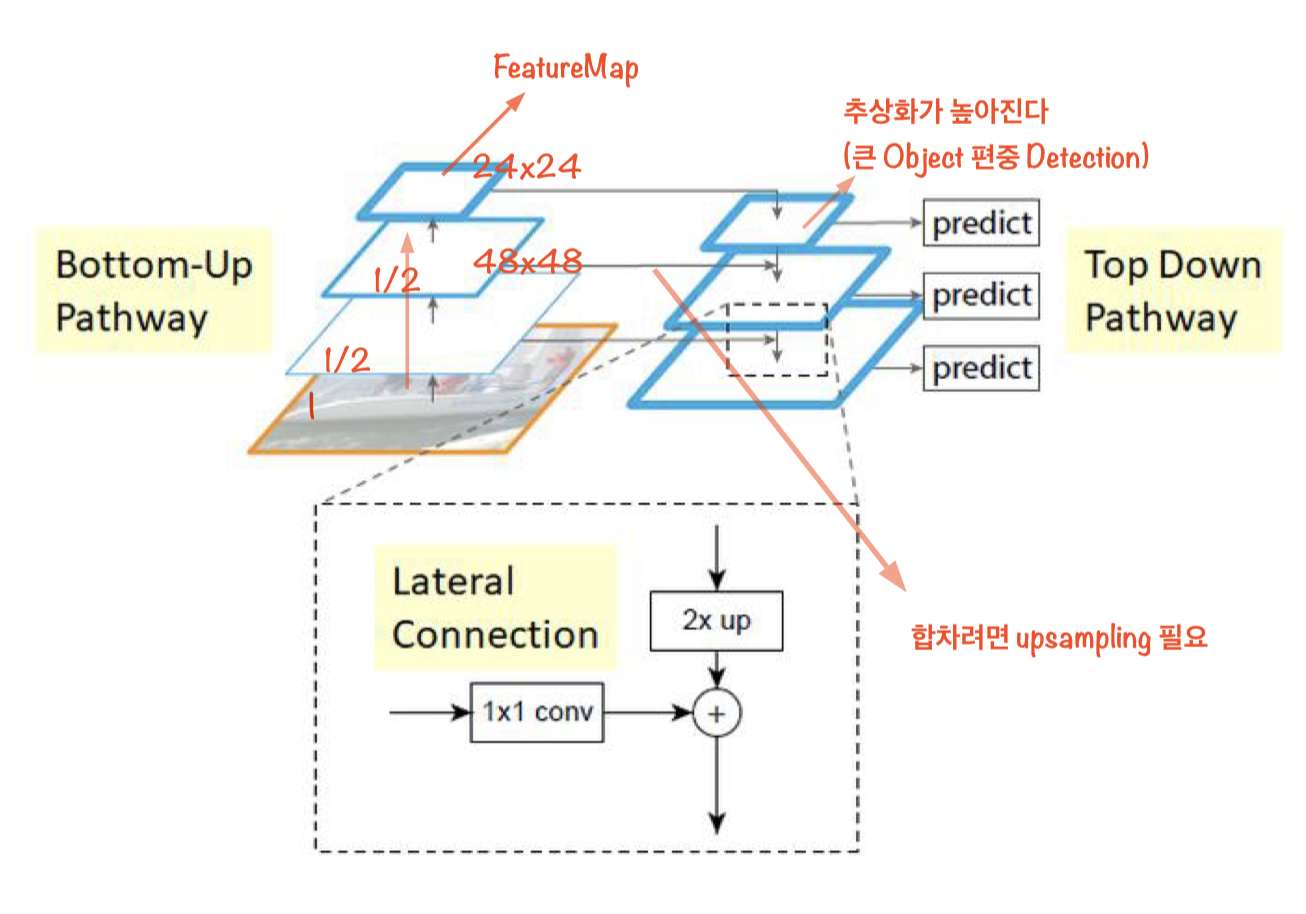
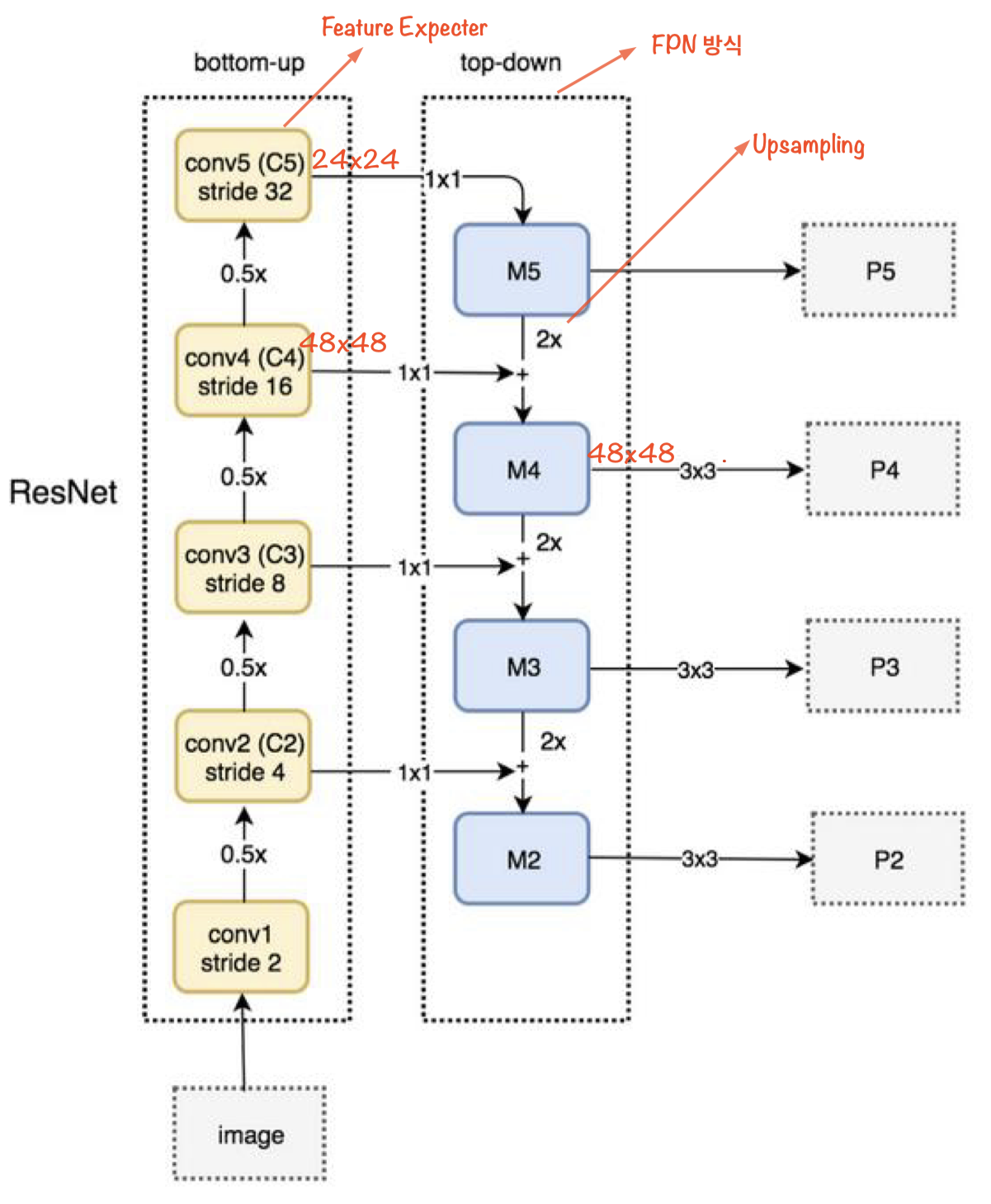
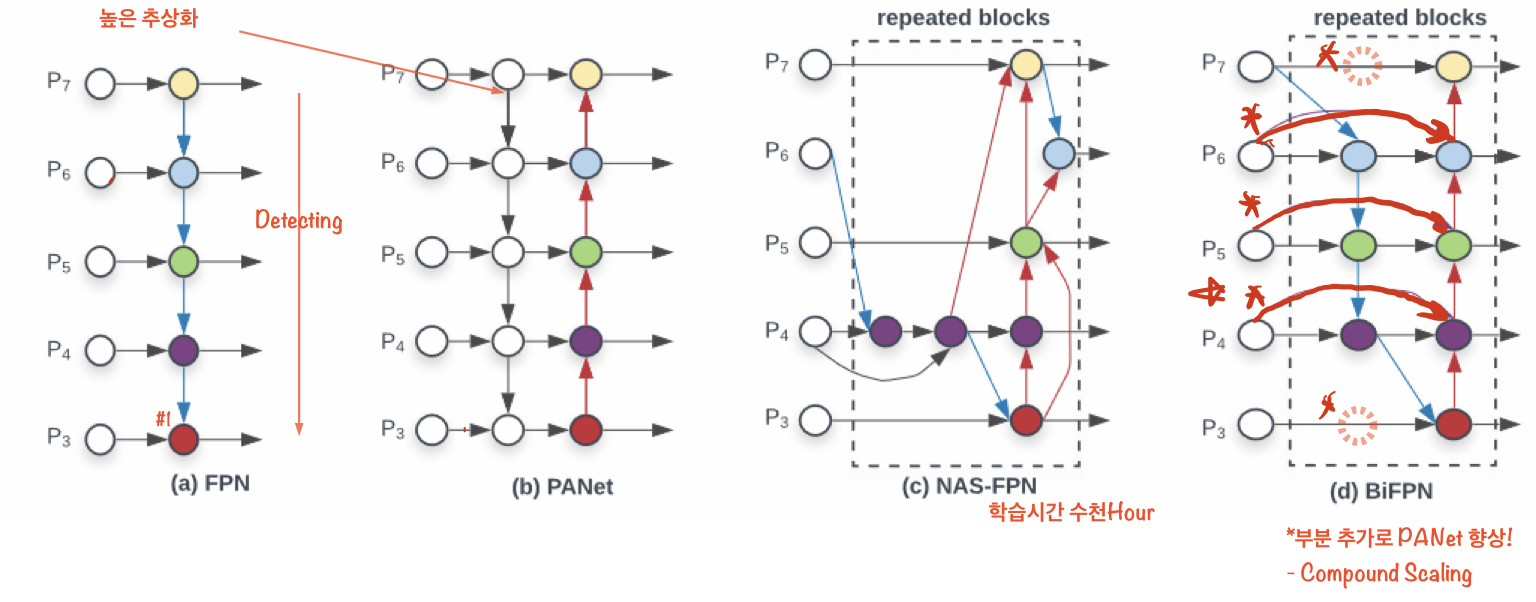
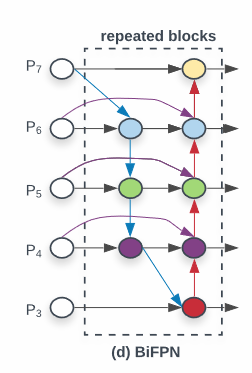
- (a)FPN : Upsampling하면서 직렬로 내려온다.
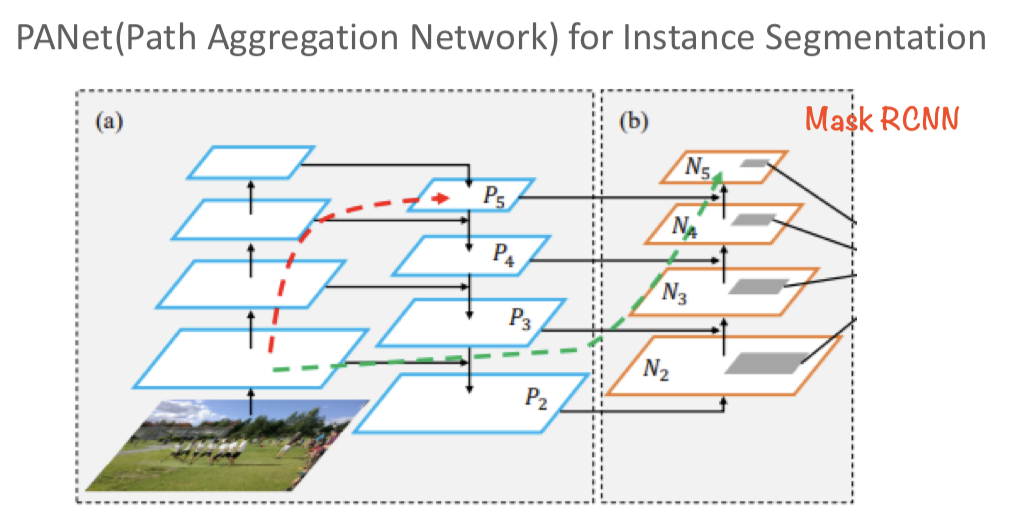
- (b)PANet : Top-down방식에 bottom-up 하나 추가 fusion을 진행하는 구조
- (c)NAS-FPN : Neural Architecture Search를 FPN 구조에 적용하여 점선의 부분을 사람이 직접 구상하지 않고 neuron network를 도입하여 진행합니다. 하지만 nas-fpn은 시간이 오래걸리고 구조가 복잡하다는 단점
- (d)BiFPN : PANet과 비교해 상하 두개의 노드가 없다.
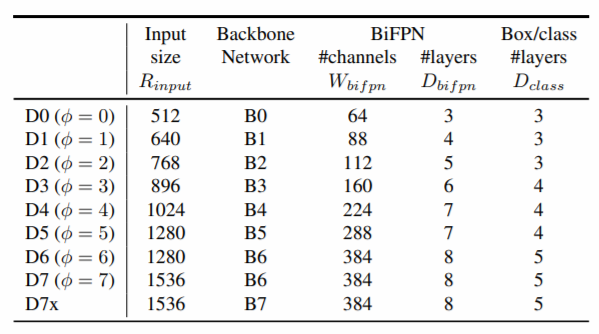
Compound Scaling(Backbone, BiFPN, Box/Classification Network)
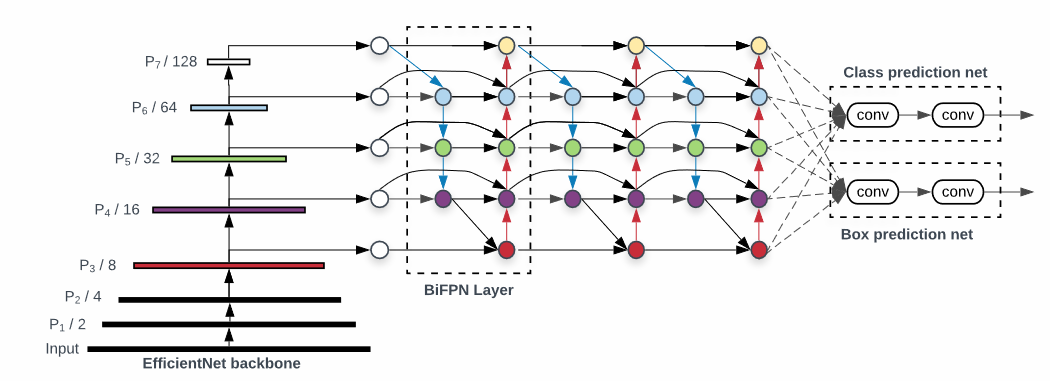
- 내용 추가

- 네트웍의 깊이(Depth), 필터 수(Width), 이미지 Resolution 크기를 함께 최적으로 조합하여 모델 성능 극대화
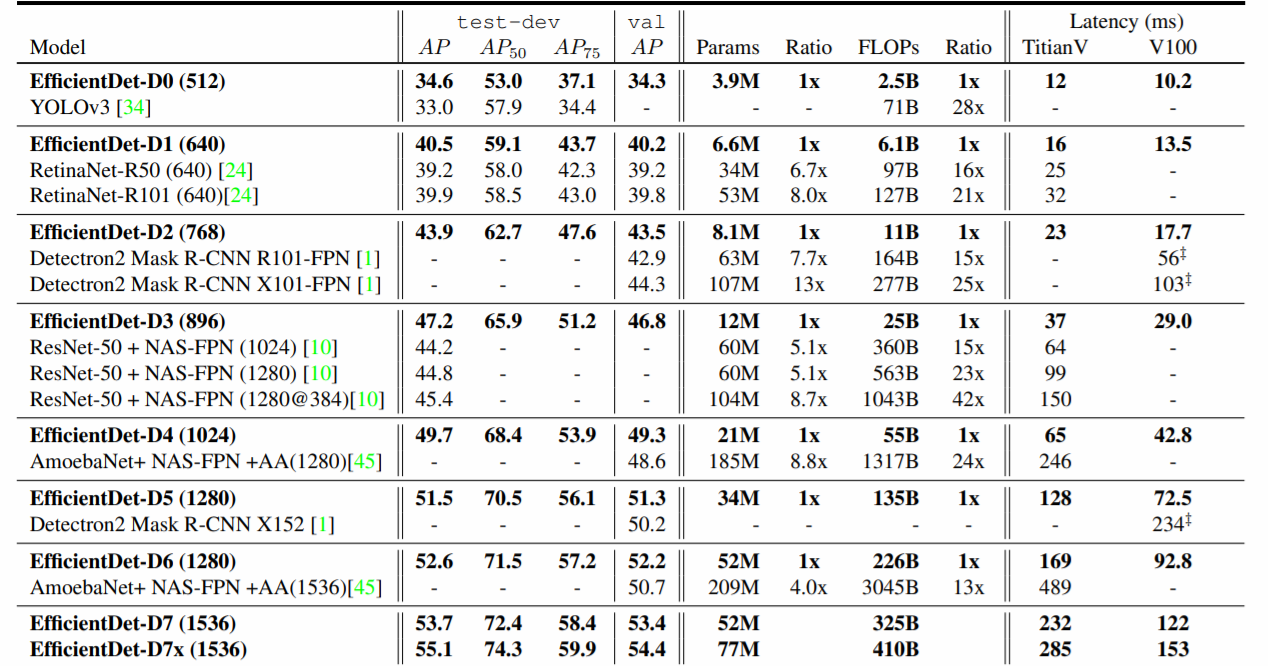
EfficientDet 성능
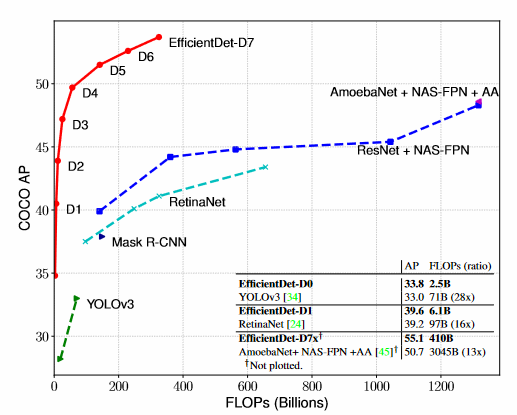
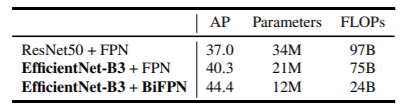
- 적은 연산 수, 적은 파라미터 수에 비해 상대적으로 타 모 델보다 높은 모델 예측 성능을 나타냄
- 논문의 Point는 BiFPN
EfficientNet 아키텍처 개요
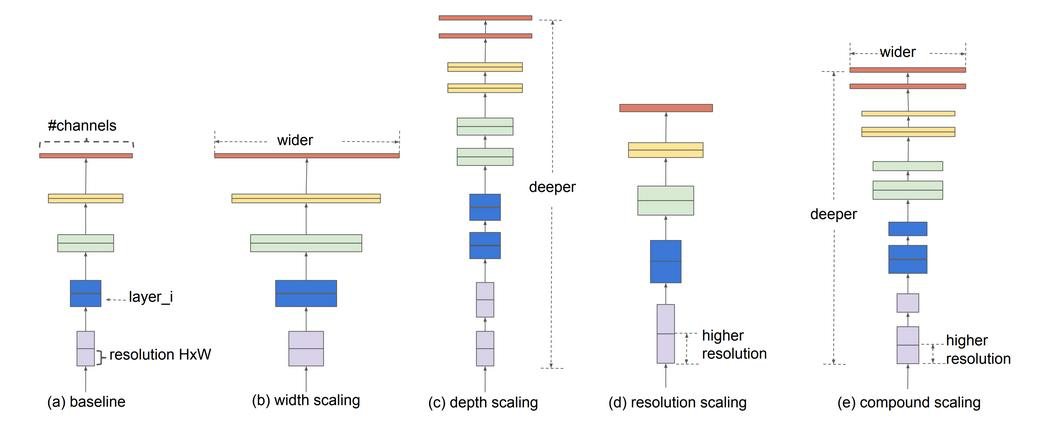
개별 Scaling 요소에 따른 성능 향상 테스트
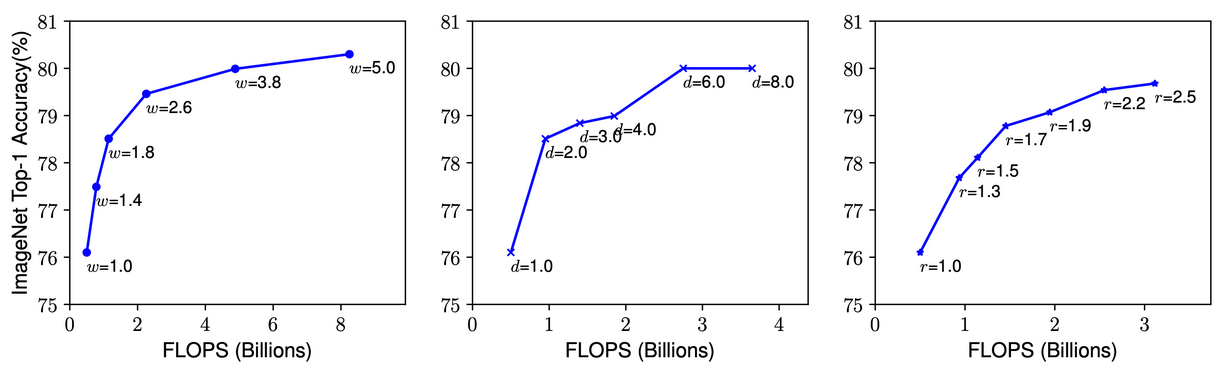
필터 수, 네트웍 깊이를 일정 수준 이상 늘려도 성능 향상 미비, 단 Resolution이 경우 어느 정도 약간씩 성능 향상 이 지속. ImageNet 데이터세트 기준 80% 정확도에서 개별 Scaling 요소를 증가 시키더라도 성능 향상이 어려움.
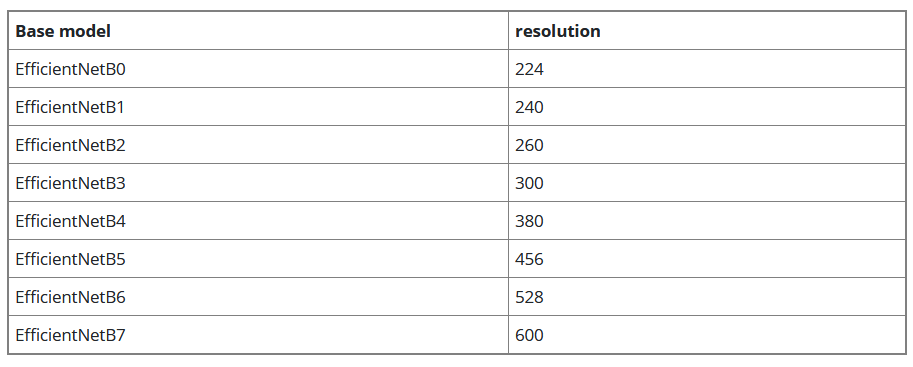
EfficientNet B0 ~ B7

최적 Scaling 도출 기반 식
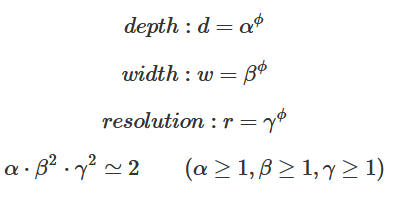
- 3가지 Scaling Factor를 동시 고려하는 Compound Scaling 적용
- 최초에는 𝝋 를 1로 고정하고 grid search 기반으로 𝛼, 𝛽, 𝛾 최적값을 찾아낸다.
- EfficientNetB의 경우 𝛼 =1.2, 𝛽 =1.1, 𝛾 =1.15
- 다음으로 𝛼, 𝜸 𝜷 를 고정하고 𝜑을 증가 시켜가면서 EfficientDetB1~ B7까 을 고정하지 Scale up 구성
비교 초기 FPN
BiFPN - Cross-Scale Connection
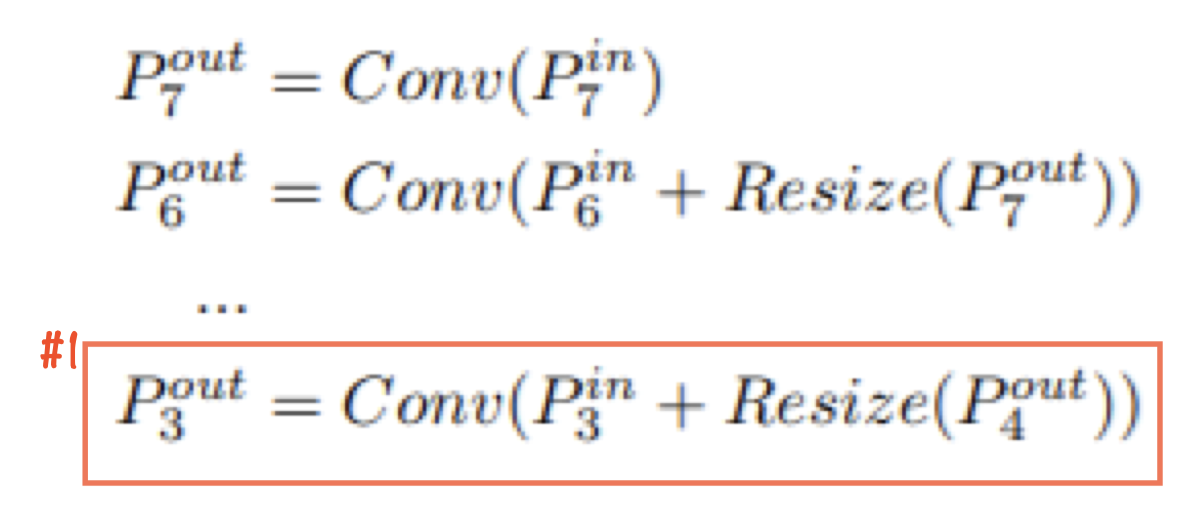
BiFPN – Weighted Feature Fusion
- 서로 다른 resolution(feature map size)를 가지는 input feature map들은 Output feature map을 생성하는 기여도가 다르기 때문에 서로 다른 가중치를 부여하여 합쳐질 수 있어야 한다.
Fast normalized fusion:
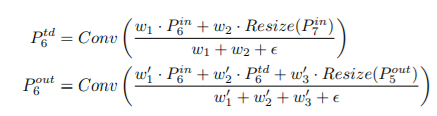
- Unbounded fusion :
(입력 feature map에 가중치를 곱해서 출력 feature map 생성. 여기서 𝑤 𝑖 는 정해진 값이 아니라 학습 시켜서 도출된 weigh임.)
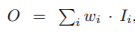
- Softmax-based fusion:
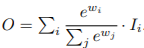
- Fast normalized fusion:
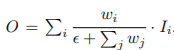
BiFPN 적용에 따른 성능 비교
- 연산량 감소를 위해 BiFPN Network 구현 시 Separable Convolution을 적용
EfficientDet Compound Scaling
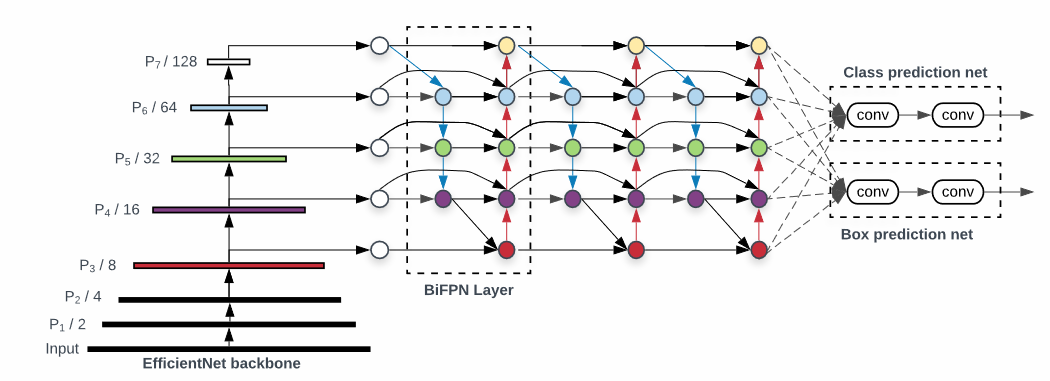
-
backbone network : EfficientNet B0~B6로 Scaling 그대로 적용
-
BiFPN network :Depth는 BiFPN 기본 반복 block을 3개로 설정하고 Scaling 적용
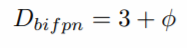
Width(채널수)는 {1.2, 1.25, 1.3, 1.35, 1.4, 1.45} 중 Grid Search를 통 해서 1.35로 Scaling 계수를 선택하고 이를 기반으로 Scaling 적용.
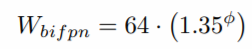
-
Prediction Network : Width(채널수)는 BiFPN 채널수와 동일.
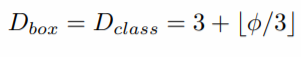
Depth는 아래식을 적용 -
입력 이미지 크기
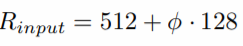
EfficientDet 기타 적용 요소 및 성능 평가
기타 적용 요소
• activation : SiLU(SWISH)
• Loss: Focal Loss
• Augmentation: horizontal flip과 scale jittering
• NMS: Soft NMS
EfficientDet Compound Scaling
너무 거대한 Backbone, 여러 겹의 FPN, 큰 입력 이미지의 크기 등의 개별적인 부분들에 집중하는 것은 비효율적. EfficientNet에서 개별 요소들을 함께 Scaling 하면서 최적 결합을 통한 성능 향상을 보여줌 EfficientDet에서도 Backbone, BiFPN, Prediction layer 그리고 입력 이미지 크기를 Scaling 기반으로 최적 결합하여 D0 ~ D7 모델 구성
AutoML EfficientDet 패키지 소개
AutoML EfficientDet 패키지의 특징
• Efficientdet 구현 모델 중 가장 예측 성능이 뛰어난 모델 보유
• GPU와 TPU 모두에서 구동 가능
• Tensorflow 2의 Native Tensorflow와 tf.keras 모두로 구현
• 약간(?)의 버그(소스코드 자체의 문제라기 보다는 tensorflow 자체의 문제로 보임)
• TFRECORD 형태로 입력 데이터 세트를 만들어야 하는 복잡함(?)
